Chương 6: TREES - 8.AVL Trees:Problems & Solutions(76-86)
Bài đăng này đã không được cập nhật trong 3 năm
Problem-76
Cho chiều cao h, đưa ra một thuật toán để tạo Hb (0).
Solution: Như chúng ta đã thảo luận, HB (0) không là gì ngoài việc tạo ra cây nhị phân đầy đủ. Trong cây nhị phân đầy đủ số lượng node có chiều cao h là: (chúng ta hãy giả sử rằng chiều cao của một cây có một node là 0). Kết quả là các node có thể được đánh số là: 1 đến .
public BinarySearchTreeNode buildHB0(int h){
BinarySearchTreeNode temp;
if(h == 0){
return null;
}
temp = new BinarySearchTreeNode();
temp.setLeft(buildHB0(h-1));
temp.setData(count++); //assume count is a global variable
temp.setRight(buildHB0(h-1));
return temp;
}
Đây là code của tác giả, cá nhân mình thấy chưa chuẩn lắm, vì với h = 1, ta sẽ chỉ có 1 node duy nhất với right và left đều là null. Đúng công thức thì với h = 1 ta phải có được 3 node
Time Complexity: O(n). Space Complexity: O(logn), trong đó logn chỉ ra kích thước ngăn xếp tối đa bằng chiều cao của cây.
Problem-77
Có cách nào thay thế để giải quyết Problem-76 không?
Solution: Vâng, chúng ta có thể giải quyết nó theo logic Mergesort. Điều đó có nghĩa là, thay vì làm việc với chiều cao, chúng ta có thể có phạm vi. Với cách tiếp cận này, chúng ta không cần bất kỳ global counter nào được duy trì.
public BinarySearchTreeNode buildHB0ver2(int l, int r){
BinarySearchTreeNode temp;
int mid = l + (r-l)/2;
if(l > r){
return null;
}
temp = new BinarySearchTreeNode();
temp.setLeft(buildHB0ver2(l, mid - 1));
temp.setData(mid); //assume count is a global variable
temp.setRight(buildHB0ver2(mid + 1, r));
return temp;
}
Lần call đầu tiên có thể là:
MergeSort là một trong nhiều thuật toán sắp xếp được sử dụng phổ biến trong các chương trình. Mình sẽ nói chi tiết khi trình bày tới chương về Sorting.
Problem-78
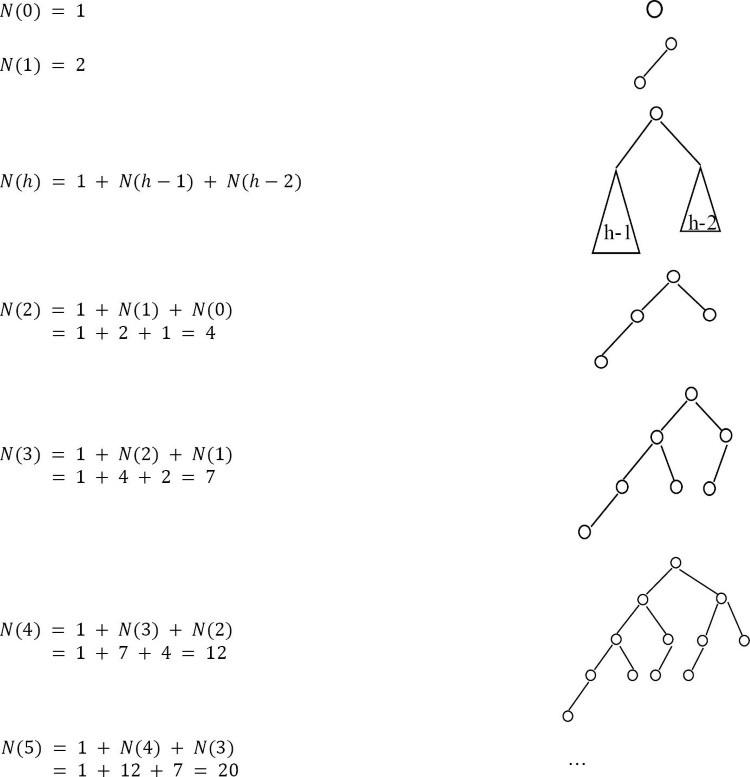
Xây dựng các cây AVL tối thiểu có chiều cao 0,1,2,3,4 và 5. Số lượng node trong một cây AVL tối thiểu có chiều cao 6 là bao nhiêu?
Solution: Đặt n(h) là số lượng node trong một cây AVL tối thiểu có chiều cao h.
Problem-79
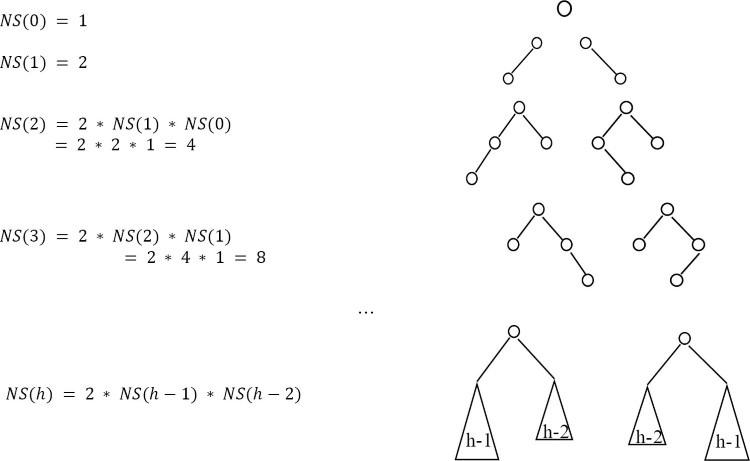
Đối với Problem-78, có bao nhiêu hình dạng khác nhau có thể có một cây AVL có chiều cao tối thiểu H?
Solution: Đặt NS(h) là số lượng các hình dạng khác nhau của một cây AVL tối thiểu h.
Problem-80
Cho một cây tìm kiếm nhị phân, hãy kiểm tra xem nó có phải là cây AVL hay không?
Solution: Giả sử rằng IsAVL là hàm kiểm tra xem cây tìm kiếm nhị phân đã cho có phải là cây AVL hay không. IsAVL trả về –1 nếu cây không phải là cây AVL. Trong quá trình kiểm tra, mỗi node sẽ gửi chiều cao của nó cho node cha của nó.
public boolean isAVL(BinarySearchTreeNode root){
if (root == null) {
return true;
}
return isAVL(root.getLeft()) && isAVL(root.getRight())
&& (Math.abs(getHeight(root.getLeft()) - getHeight(root.getRight())) <= 1);
}
public int getHeight(BinarySearchTreeNode root){
int leftHeight, rightHeight;
if(root == null){
return 0;
} else{
leftHeight = getHeight(root.getLeft());
rightHeight = getHeight(root.getRight());
if (leftHeight > rightHeight) {
return leftHeight + 1;
} else{
return rightHeight + 1;
}
}
}
Time Complexity: O(n). Space Complexity: O(n).
Problem-81
Cho chiều cao h, hãy đưa ra thuật toán tạo cây AVL với số node tối thiểu.
Solution: Để có số lượng node tối thiểu, tạo cây có một level bằng h – 1 và level kia bằng h – 2.
public AVLTreeNode GenerateAVLTree(int h){
AVLTreeNode temp;
if(h == 0){
return null;
}
temp = new AVLTreeNode();
temp.setLeft(GenerateAVLTree(h-1));
temp.setData(count++); //assume count is a global variable
temp.setRight(GenerateAVLTree(h-2));
temp.setHeight(temp.getLeft().getHeight() + 1); // or temp.setHeight(h)
return temp;
}
Problem-82
Cho một cây AVL có n node và hai số nguyên a và b, trong đó a và b có thể là bất kỳ số nguyên nào với a <= b. Thực hiện thuật toán đếm số node trong khoảng [a, b].
Solution:
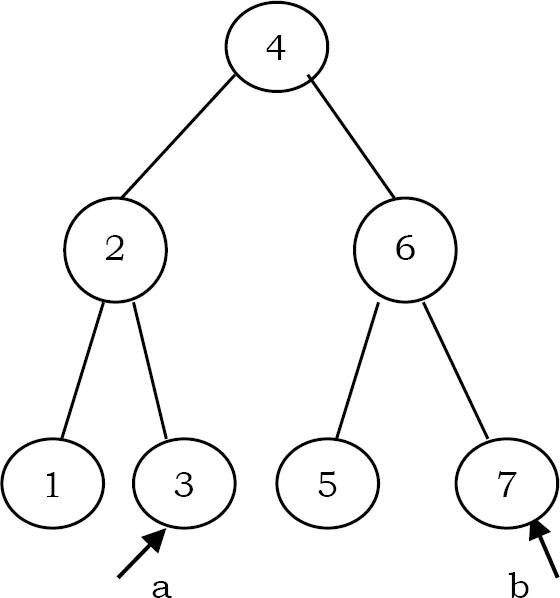
Ý tưởng là sử dụng thuộc tính đệ quy của cây tìm kiếm nhị phân. Có ba trường hợp cần xem xét: node hiện tại nằm trong phạm vi [a, b], ở phía bên trái của phạm vi [a, b] hay ở phía bên phải của phạm vi [a, b]. Chỉ những cây con có khả năng chứa các node mới được xử lý theo từng trường hợp trong ba trường hợp.
public int RangeCount(AVLTreeNode root, int a, int b){
if(root == null){
return 0;
} else if (root.getData() > b) {
return RangeCount(root.getLeft(), a, b);
} else if (root.getData() < a) {
return RangeCount(root.getRight(), a, b);
}
return RangeCount(root.getLeft(), a, b) + RangeCount(root.getRight(), a, b);
}
Độ phức tạp tương tự như duyệt in–order traversal nhưng bỏ qua các cây con bên trái hoặc bên phải khi chúng không chứa bất kỳ câu trả lời nào. Vì vậy, trong trường hợp xấu nhất, nếu phạm vi bao gồm tất cả các node trong cây, chúng ta cần duyệt qua tất cả n node để có câu trả lời. Do đó, worst time complexity là O(n).
Nếu phạm vi nhỏ, chỉ bao gồm một vài phần tử trong một cây con nhỏ ở dưới cùng của cây, thì độ phức tạp thời gian sẽ là O(h) = O(logn), trong đó h là chiều cao của cây. Điều này là do chỉ có một đường dẫn duy nhất được đi qua để đến cây con nhỏ ở dưới cùng và nhiều cây con cấp cao hơn đã bị cắt tỉa trên đường đi.
Problem-83
Median(Trung vị) trong một dãy số nguyên vô hạn
Solution: Trung vị là số ở giữa trong một danh sách các số đã được sắp xếp (nếu chúng ta có số phần tử lẻ). Nếu chúng ta có số phần tử chẵn thì trung vị là trung bình cộng của hai số đứng giữa trong một danh sách các số đã được sắp xếp.
Để giải quyết vấn đề này, chúng ta có thể sử dụng cây tìm kiếm nhị phân với thông tin bổ sung tại mỗi node và số node con trên các cây con bên trái và bên phải. chúng ta cũng giữ tổng số node trong cây. Sử dụng thông tin bổ sung này, chúng ta có thể tìm thấy trung vị trong thời gian O(logn), chọn nhánh thích hợp trong cây dựa trên số node con ở bên trái và bên phải của node hiện tại. Tuy nhiên, độ phức tạp của phép chèn là O(n) vì cây tìm kiếm nhị phân tiêu chuẩn có thể suy biến thành danh sách liên kết nếu chúng ta tình cờ nhận được các số theo thứ tự đã sắp xếp.
Vì vậy, hãy sử dụng cây tìm kiếm nhị phân cân bằng(balanced binary search tree) để tránh trường hợp xấu nhất xảy ra với cây tìm kiếm nhị phân tiêu chuẩn. Đối với vấn đề này, hệ số cân bằng là số node trong cây con bên trái trừ đi số node trong cây con bên phải. Và chỉ những node có hệ số cân bằng +1 hoặc 0 mới được coi là cân bằng. Vì vậy, số node trên cây con bên trái bằng hoặc nhiều hơn 1 node so với số node trên cây con bên phải, nhưng không được ít hơn. Nếu ta đảm bảo hệ số cân bằng này trên mọi node của cây thì gốc của cây là trung vị, nếu số phần tử là số lẻ. Trong số phần tử chẵn, trung vị là trung bình cộng của gốc và cây kế theo thứ tự của nó, là cây con ngoài cùng bên trái của cây con bên phải của nó. Vì vậy, độ phức tạp của phép chèn duy trì điều kiện cân bằng là O(logn) và việc tìm phép toán trung bình là O(1) giả sử chúng ta đã tính toán inorder successorcủa gốc ở mỗi lần chèn nếu số node là chẵn.
Chèn và cân bằng rất giống với cây AVL. Thay vì cập nhật độ cao, chúng ta cập nhật thông tin số lượng node. Cây tìm kiếm nhị phân cân bằng dường như là giải pháp tối ưu nhất, phần chèn là O(logn) và tìm trung vị là O(1).
Note: Bài toán này mình sẽ trình bày chi tiết thêm trong chương về Priority Queues and Heaps.
Problem-84
Cho một cây nhị phân, làm cách nào để loại bỏ tất cả các half nodes( node mà chỉ có một node con)? Lưu ý rằng chúng ta không nên chạm vào node lá.
Solution: Bằng cách sử dụng duyệt post-order traversal, chúng ta có thể giải quyết vấn đề này một cách hiệu quả. Đầu tiên chúng ta xử lý các node con bên trái, sau đó là các node con bên phải và cuối cùng là chính node đó. Vì vậy, chúng ta tạo thành cây mới từ dưới lên, bắt đầu từ lá về phía gốc. Vào thời điểm chúng ta xử lý node hiện tại, cả hai cây con bên trái và bên phải của nó đã được xử lý.
public BinaryTreeNode removeHalfNodes(BinaryTreeNode root){
if(root == null){
return null;
}
root.setLeft(removeHalfNodes((root.getLeft())));
root.setRight(removeHalfNodes((root.getRight())));
if(root.getLeft() == null && root.getRight() == null){
return root;
}
if(root.getLeft() == null){
return root.getRight();
}
if(root.getRight() == null){
return root.getLeft();
}
return root;
}
Time Complexity: O(n).
Problem-85
Cho một cây nhị phân, làm cách nào để loại bỏ các node lá của nó?
Solution: Bằng cách sử dụng duyệt post-order traversal, chúng ta có thể giải quyết vấn đề này (các cách duyệt khác cũng sẽ hoạt động).
public BinaryTreeNode removeLeaves(BinaryTreeNode root){
if(root != null){
if(root.getLeft() == null && root.getRight() == null){
root = null;
} else {
root.setLeft(removeLeaves(root.getLeft()));
root.setRight(removeLeaves(root.getRight()));
}
}
return root;
}
Time Complexity: O(n).
Problem-86
Đưa ra một BST và hai số nguyên (số nguyên tối thiểu và tối đa) làm tham số, làm cách nào để bạn loại bỏ (cắt tỉa) các phần tử không nằm trong phạm vi đó?
Solution:
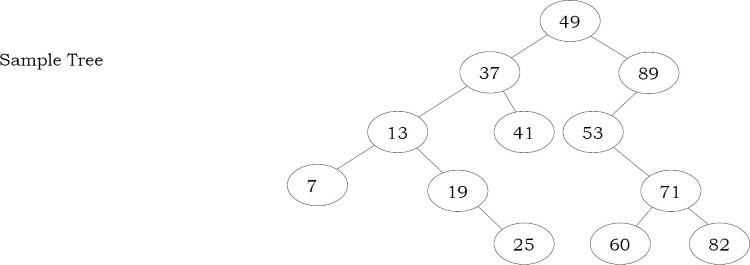
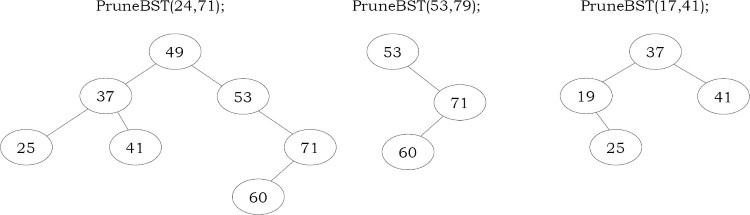
Quan sát: Vì chúng ta cần kiểm tra từng phần tử trong cây và các thay đổi của cây con sẽ được phản ánh trong node cha của nó, chúng ta có thể nghĩ đến việc sử dụng duyệt theo post order traversal. Vì vậy, chúng ta xử lý các node bắt đầu từ lá về phía gốc. Kết quả là, trong khi xử lý chính node đó, cả cây con bên trái và bên phải của nó đều là các BST đã được cắt tỉa hợp lệ. Tại mỗi node, chúng ta sẽ trả về một con trỏ dựa trên giá trị của nó, sau đó giá trị này sẽ được gán cho con trỏ con bên trái hoặc bên phải của node cha, tùy thuộc vào việc node hiện tại là con bên trái hay bên phải của node cha. Nếu giá trị của node hiện tại nằm trong khoảng từ A đến B (A <= dữ liệu của node <= B) thì không cần thực hiện hành động nào, vì vậy chúng ta trả lại tham chiếu cho chính node đó.
Nếu giá trị của node hiện tại nhỏ hơn A, thì chúng ta trả lại tham chiếu cho cây con bên phải của nó và loại bỏ cây con bên trái. Bởi vì nếu giá trị của một node nhỏ hơn A, thì các node con bên trái của nó chắc chắn nhỏ hơn A vì đây là cây tìm kiếm nhị phân. Nhưng các con bên phải của nó có thể nhỏ hơn hoặc không nhỏ hơn A; chúng ta không thể chắc chắn, vì vậy chúng ta trả lại tham chiếu cho nó. Vì chúng ta đang thực hiện duyệt theo thứ tự từ dưới lên, nên cây con bên phải của nó đã là cây tìm kiếm nhị phân hợp lệ được cắt bớt (có thể là NULL) và cây con bên trái của nó chắc chắn là NULL vì các node đó chắc chắn nhỏ hơn A và chúng đã bị loại bỏ trong quá trình duyệt post-order traversal. Tình huống tương tự xảy ra khi giá trị của node lớn hơn B, vì vậy bây giờ chúng ta trả lại tham chiếu cho cây con bên trái của nó. Bởi vì nếu giá trị của một node lớn hơn B, thì con bên phải của nó chắc chắn lớn hơn B. Nhưng các con bên trái của nó có thể lớn hơn hoặc không lớn hơn B; Vì vậy, chúng ta loại bỏ cây con bên phải và trả lại tham chiếu cho cây con bên trái đã hợp lệ.
public BinarySearchTreeNode PruneBST(BinarySearchTreeNode root, int A, int B) {
if (root == null) {
return null;
}
root.setLeft(PruneBST(root.getLeft(), A, B));
root.setRight(PruneBST(root.getRight(), A, B));
if (A <= root.getData() && root.getData() <= B) {
return root;
} else if (root.getData() < A) {
return root.getRight();
} else { //(root.getData() > B)
return root.getLeft();
}
}
Time Complexity: O(n) trong trường hợp xấu nhất và trong trường hợp trung bình là O(logn).
All rights reserved
