
State-of-the-art Instance Segmentation Chỉ Vài Dòng Code Với Detectron2
Bài đăng này đã không được cập nhật trong 6 năm
Giới Thiệu
Bạn muốn xây dựng nhanh một model cho bài toán Instance Segmentation nhưng việc implement các State-of-the-art lại quá phức tạp và tốn thời gian debugging? Thì đây, Detectron2 của Facebook là giải pháp cho bạn  . Mà hàng của Facebook thì bạn biết rồi đấy, xịn xò khỏi phải bàn
. Mà hàng của Facebook thì bạn biết rồi đấy, xịn xò khỏi phải bàn  . Thư viện này đủ gọn để tạo một bản mẫu nhanh nhưng cũng đủ linh hoạt để bạn custom model cho riêng mình. Hơn nữa, model zoo của Detectron2 lại cực phong phú, toàn là SOTA, có thể kể đến như Mask R-CNN, RetinaNet, Faster R-CNN, RPN, R-FCN,... với các backbones ResNeXt{50,101,152}, ResNet{50,101,152}, Feature Pyramid Networks,... Để hiểu hơn về Mask R-CNN cho bài toán segmentation hay Faster R-CNN cho bài toán object detection, bạn có thể tham khảo 2 bài viết này của tác giả Việt Hoàng [MaskRCNN] Các bước triển khai Mask R-CNN cho bài toán Image Segmentation và tác giả Huy Hoàng [Deep Learning] - Thuật toán Faster-RCNN với bài toán phát hiện đường lưỡi bò - Faster-RCNN object detection algorithm for Nine-dash-line detection!.
. Thư viện này đủ gọn để tạo một bản mẫu nhanh nhưng cũng đủ linh hoạt để bạn custom model cho riêng mình. Hơn nữa, model zoo của Detectron2 lại cực phong phú, toàn là SOTA, có thể kể đến như Mask R-CNN, RetinaNet, Faster R-CNN, RPN, R-FCN,... với các backbones ResNeXt{50,101,152}, ResNet{50,101,152}, Feature Pyramid Networks,... Để hiểu hơn về Mask R-CNN cho bài toán segmentation hay Faster R-CNN cho bài toán object detection, bạn có thể tham khảo 2 bài viết này của tác giả Việt Hoàng [MaskRCNN] Các bước triển khai Mask R-CNN cho bài toán Image Segmentation và tác giả Huy Hoàng [Deep Learning] - Thuật toán Faster-RCNN với bài toán phát hiện đường lưỡi bò - Faster-RCNN object detection algorithm for Nine-dash-line detection!.
Trong bài này mình sẽ sử dụng Mask R-CNN với backbone ResNeXt-101 cho bài toán Cat/Dog Instance Segmentation. Tổng quan các bước sử dụng Detectron như sau:
- Chuyển đổi dataset annotations về format của COCO
- Register dataset vào Detectron
- Load pretrained model, config và set hyperparameters
- Huấn luyện model
- Đánh giá model
Full code bạn có thể tham khảo trên Github của mình.
Dataset
Mình sử dụng dataset chó/mèo The Oxford-IIIT Pet Dataset bao gồm 4978 dog instances và 2371 cat instances. Bộ data này rất đa dạng về kích thước, tư thế instance cũng như các điều kiện ánh sáng khác nhau.
Cài môi trường cần thiết
pip install -U torch torchvision
pip install git+https://github.com/facebookresearch/fvcore.git
pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
git clone https://github.com/facebookresearch/detectron2 detectron2_repo
pip install -e detectron2_repo
pip install numpy==1.17
Chuyển annotations về COCO format
Nếu dataset của bạn đã ở định dạng COCO sẵn rồi thì có thể bỏ qua bước này. Vì annotations của dataset này ở Pascal VOC format

trong khi Detectron chỉ nhận COCO format
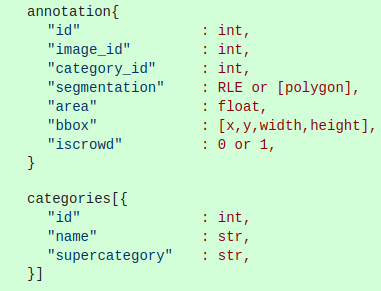
nên bước đầu tiên phải chuyển về format COCO. Hàm chuyển đổi format như sau (credit QuangPham):
import os
import json
import cv2
import numpy as np
import xml.etree.ElementTree as ET
import xmltodict
import json
from pycocotools import mask
from xml.dom import minidom
from collections import OrderedDict
def mask_to_bbox(img):
rows = np.any(img == 1, axis=1)
cols = np.any(img == 1, axis=0)
ymin, ymax = np.where(rows)[0][[0, -1]]
xmin, xmax = np.where(cols)[0][[0, -1]]
return max(xmin - 15, 0), min(xmax + 15, img.shape[1]), max(ymin - 15, 0), min(ymax + 15, img.shape[0])
def generateVOC2Json(rootDir,xmlFiles):
attrDict = dict()
attrDict["categories"]=[{"supercategory":"none","id":0,"name":"cat"},
{"supercategory":"none","id":1,"name":"dog"}
]
images = list()
annotations = list()
for root, dirs, files in os.walk(rootDir):
image_id = 0
for file in xmlFiles:
image_id = image_id + 1
if file in files:
try:
annotation_path = os.path.abspath(os.path.join(root, file))
image = dict()
doc = xmltodict.parse(open(annotation_path).read())
image['file_name'] = str(doc['annotation']['filename'])
image['height'] = int(doc['annotation']['size']['height'])
image['width'] = int(doc['annotation']['size']['width'])
image['sem_seg_file_name'] = 'trimaps/' + file[:-4] + '.png'
image['id'] = image_id
print("File Name: {} and image_id {}".format(file, image_id))
images.append(image)
id1 = 1
if 'object' in doc['annotation']:
obj = doc['annotation']['object']
for value in attrDict["categories"]:
annotation = dict()
if str(obj['name']) == value["name"]:
annotation["iscrowd"] = 0
annotation["image_id"] = image_id
x1 = int(obj["bndbox"]["xmin"]) - 1
y1 = int(obj["bndbox"]["ymin"]) - 1
x2 = int(obj["bndbox"]["xmax"]) - x1
y2 = int(obj["bndbox"]["ymax"]) - y1
annotation["bbox"] = [x1, y1, x2, y2]
annotation["area"] = float(x2 * y2)
annotation["category_id"] = value["id"]
annotation["ignore"] = 0
annotation["id"] = image_id
image_mask = cv2.imread(os.path.join(root[:-5], "trimaps/") + file[:-4] + ".png")
xmin, xmax, ymin, ymax = mask_to_bbox(image_mask[:, :, 0])
image_mask = np.where(image_mask==3, 1, image_mask)
image_mask = np.where(image_mask==2, 0, image_mask)
image_mask = image_mask.astype('uint8')
segmask = mask.encode(np.asarray(image_mask, order="F"))
for seg in segmask:
seg['counts'] = seg['counts'].decode('utf-8')
x1 = int(xmin)
y1 = int(ymin)
x2 = int(xmax - x1)
y2 = int(ymax - y1)
annotation["bbox"] = [x1, y1, x2, y2]
annotation["area"] = float(x2 * y2)
annotation["segmentation"] = segmask[0]
id1 +=1
annotations.append(annotation)
else:
print("File: {} doesn't have any object".format(file))
except:
pass
else:
print("File: {} not found".format(file))
attrDict["images"] = images
attrDict["annotations"] = annotations
attrDict['info'] = {
'contributor': 'QuangPham',
'date_created': '2020/05/05',
'description': 'Pets',
'url': 'https://viblo.asia/u/QuangPH',
'version': '1.1',
'year': 2020
}
attrDict['licenses'] = [{'id': 1, 'name': 'QuangPham', 'url': 'https://viblo.asia/u/QuangPH'}]
jsonString = json.dumps(attrDict)
return jsonString
Hàm mask_to_bbox() mình +/- 15 pixel ở các tọa độ x/y để bounding box rộng hơn instance một chút. Trong hàm generateVOC2Json() mình không set giá trị cho 1 element là box_mode thì Detectron sẽ mặc định là BoxMode.XYXYABS (biểu diễn bounding box dưới dạng [x, y, h, w]), vậy nên bạn cần chú ý biểu diễn đúng tọa độ bounding box. Một chú ý quan trọng nữa, do segmentation annotation của mình dạng mask (pixel-level annotations) nên element segmentation trong hàm generateVOC2Json() mình encode dưới dạng Run Length Encoder (RLE) bitmask. Nếu dataset của bạn annotate dưới dạng polygon thì segmentation là một list các tọa độ của polygon. Tiếp theo ta chia thành 2 tập train và test với tỷ lệ 80:20:
from sklearn.model_selection import train_test_split
trainFile = "./annotations/trainval.txt"
XMLFiles = list()
with open(trainFile, "r") as f:
for line in f:
fileName = line.strip().split()[0]
XMLFiles.append(fileName + ".xml")
trainXMLFiles, testXMLFiles = train_test_split(XMLFiles, test_size=0.2, random_state=24)
print(len(trainXMLFiles), len(testXMLFiles))
Lưu 2 file train/test annotations này dưới định dạng json:
rootDir = "annotations/xmls"
train_attrDict = generateVOC2Json(rootDir, trainXMLFiles)
with open("./train_segmentation.json", "w") as f:
f.write(train_attrDict)
test_attrDict = generateVOC2Json(rootDir, testXMLFiles)
with open("./test_segmentation.json", "w") as f:
f.write(test_attrDict)
Vậy là xong, data của bạn đã đúng định dạng và có thể register vào Detectron rồi. 
Register dataset
Để Detectron hiểu được dataset của bạn và sử dụng nó trong quá trình training cũng như evaluation, bạn phải đăng ký dataset bằng hàm register_coco_instances().
from detectron2.data.datasets import register_coco_instances
# datasets' unique names to register
train_name = "pets_train"
test_name = "pets_test"
image_root = "/dataset/image"
instances_json = "/dataset/annotations/train_pets.json"
instances_test_json = "/dataset/annotations/test_pets.json"
register_coco_instances(train, {}, instances_json, image_root)
register_coco_instances(test, {}, instances_test_json, image_root)
meta_train = MetadataCatalog.get(train)
dicts_train = DatasetCatalog.get(train)
Lưu ý tên của dataset khi register không được trùng nhau.
Huấn luyện mô hình
"Khoan đã, nhưng mô hình đâu?". Không cần phải code mô hình đâu, tất cả những gì bạn cần làm là lên Detectron2 Model Zoo và chọn một mô hình. Trên trang này đề cập rất rõ ràng thông tin về kích thước, độ chính xác, tốc độ train/inference cho từng model. Khi bạn clone repo detectron về sẽ có hàng loạt các file config cho những model này (đường dẫn có dạng detectron2_repo/configs/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml) hãy chọn model phù hợp nhất với nhu cầu của mình nhé  . Ở đây mình chọn model "xịn xò" nhất: Mask R-CNN với backbone Feature Pyramid Network ResNeXt-101.
. Ở đây mình chọn model "xịn xò" nhất: Mask R-CNN với backbone Feature Pyramid Network ResNeXt-101.
from detectron2.engine import DefaultTrainer
from detectron2.config import get_cfg
import os
# set hyper parameters
cfg = get_cfg()
cfg.merge_from_file("/detectron2_repo/configs/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml")
cfg.DATASETS.TRAIN = (train,)
cfg.DATASETS.TEST = (test, )
cfg.DATALOADER.NUM_WORKERS = 2
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.CHECKPOINT_PERIOD = 500
cfg.SOLVER.BASE_LR = 0.0001
cfg.SOLVER.MAX_ITER = 5000
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 2
cfg.OUTPUT_DIR = "weights/resnext101"
cfg.INPUT.MASK_FORMAT = 'bitmask'
Hàm cfg.merge_from_file() nhận đường dẫn file config bạn chọn bên trên. Một số hyperparams quan trọng cần khai báo như:
- cfg.DATASETS.TRAIN: (tên tập train đã register, )
- cfg.DATASETS.TEST: (tên tập test đã register, )
- cfg.SOLVER.BASE_LR : learning rate
- cfg.SOLVER.MAX_ITER: số vòng lặp training
- cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE: batch size
- cfg.MODEL.ROI_HEADS.NUM_CLASSES: số lượng class, ở bài toán này là 2
- cfg.INPUT.MASK_FORMAT: như đã nói ở bước chuyển đổi định dạng annotations, mình sử dụng bitmask RLE nên hyperparam này BẮT BUỘC phải set
'bitmask'.
Việc training rất đơn giản, chỉ 4 dòng code sau:
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
Khi quá trình training kết thúc, model của bạn sẽ được lưu vào đường dẫn cfg.OUTPUT_DIR.
Đánh giá mô hình
Để đánh giá mô hình trên tập test, ta thực hiện như sau.
Cài đặt config model:
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
# set config
cfg = get_cfg()
cfg.merge_from_file("/content/detectron2_repo/configs/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml")
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 2 # 3 classes (data, fig, hazelnut)
cfg.OUTPUT_DIR = "/content/drive/My Drive/VietAnh/weights"
cfg.INPUT.MASK_FORMAT = 'bitmask'
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
Load model đã train:
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(True)
Load data và thực hiện evaluate:
predictor = DefaultPredictor(cfg)
meta_test = MetadataCatalog.get(test)
dicts_test = DatasetCatalog.get(test)
evaluator = COCOEvaluator(test, cfg, False, output_dir="./output/")
test_loader = build_detection_test_loader(cfg, test)
inference_on_dataset(trainer.model, test_loader, evaluator)
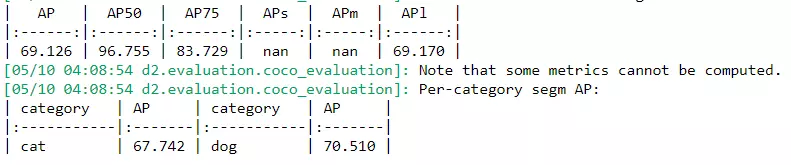
Và đây là kết quả cho bài toán instance segmentation:
Cuối cùng, ta thực hiện visualize 3 ảnh bất kỳ trong tập test xem model học có tốt hay không. Detectron có sẵn một module Visualizer giúp thực hiện điều này rất dễ dàng.
import random
from detectron2.utils.visualizer import Visualizer
import cv2
from google.colab.patches import cv2_imshow
meta_test = MetadataCatalog.get(test)
dicts_test = DatasetCatalog.get(test)
for d in random.sample(dicts_test, 3):
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=meta_test, scale=0.5)
vis = visualizer.draw_dataset_dict(d)
cv2_imshow(vis.get_image()[:, :, ::-1])
Kết quả như sau:



Cũng tốt đấy chứ .
Kết Luận
Trên đây là một pipeline cơ bản cho bài toán instance segmentation sử dụng thư viện Detectron2. Ngoài ra thư viện này còn rất nhiều phần hữu ích nữa như customize model hay deployment. Mình thấy đây là một thư viện rất hay, hữu dụng, hỗ trợ bạn xây dựng nhanh một sản phẩm với chất lượng cực tốt. Bài viết của mình kết thúc tại đây, nếu thấy hay ngại gì 1 upvote, clip hay follow đúng không nào  .
.
All rights reserved
