
SemEval 2021 Task 5: Toxic Span Detection
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu bài toán
Toxic Span Detection là bài toán phát hiện các từ/cụm từ độc hại trong văn bản, cụ thể là các bình luận, bài đăng trên mạng xã hội. Mặc dù một số bộ dữ liệu và mô hình phát hiện toxic đã được nghiên cứu nhưng hầu hết chúng đều phân loại toàn bộ văn bản và không xác định được các dấu hiệu khiến một văn bản trở nên độc hại. Trong khi đó, việc phát hiện ra những span mang lại hiệu quả cao hơn khi nó hỗ trợ người kiểm duyệt nội dung highlight những từ ngữ thô tục thay vì chỉ đưa ra một điểm số mức độ độc hại như phương pháp trên. Do đó, toxic span detection là một bước quan trọng trong kiểm duyệt bán tự động.
SemEval 2021 Task 5 cung cấp bộ dữ liệu cũng như hệ thống đánh giá cho bài toán Toxic Span Detection. Bài toán này có thể được giải quyết bằng sequence tagging, tức là ta sẽ dự đoán nhãn (toxic/non-toxic) cho từng từ trong câu. Trong bài này mình sẽ đưa về dạng Named Entity Recognition trong đó mỗi toxic span được coi là một thực thể. Thư viện được sử dụng là Flair - một thư viện cực tiện lợi cho các bài toán NLP, đặc biệt là NER.
Chuẩn bị dữ liệu
Dữ liệu có thể tải tại official page của của cuộc thi. Các toxic span được annotate bằng các offset của ký tự trong span đó. Ví dụ:
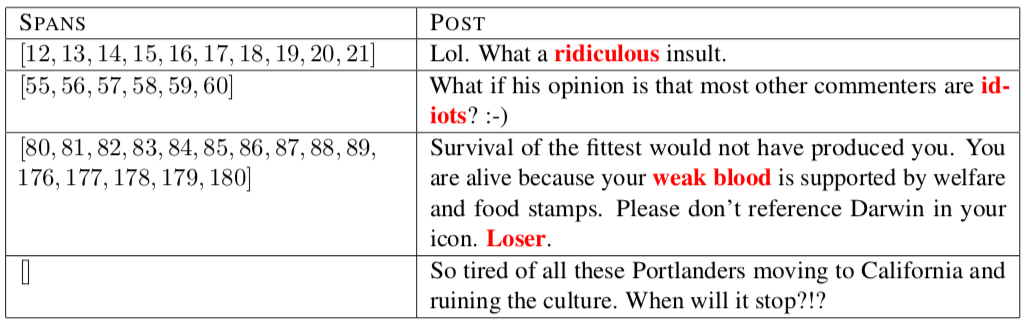
Đầu tiên mình sẽ load data, bóc tách toxic spans từ offset groundtruth và lưu dưới dạng dictionary:
def normalize(text):
text = re.sub('`|‘|’', "'", text)
text = re.sub('”|“', '"', text)
text = re.sub('\n|…|[^\x00-\x7F]|\[|\]', ' ', text)
return text
# group continuous offset sequence
def group_sequence(l):
temp_list = cycle(l)
next(temp_list)
groups = groupby(l, key=lambda j: j + 1 == next(temp_list))
for k, v in groups:
if k:
yield tuple(v) + (next((next(groups)[1])),)
def load_data(path):
tsd = pd.read_csv(path)
tsd.spans = tsd.spans.apply(literal_eval)
data = []
for row in tsd.iterrows():
span = row[1]['spans']
text = normalize(row[1]['text'])
temp = []
text_spans = []
if span:
segments = group_sequence(span)
for seg in segments:
temp.append([seg[0], seg[-1]])
text_spans.append(text[seg[0]: seg[-1] + 1])
if len(temp) == 1 and temp[0][1] - temp[0][0] >= 60:
continue
data.append({'text': text, 'spans': temp, 'text_spans': text_spans})
return data
[{'text': 'Another violent and aggressive immigrant killing a innocent and intelligent US Citizen.... Sarcasm', 'spans': [[8, 39]], 'text_spans': ['violent and aggressive immigrant']},
{'text': 'Damn, a whole family. Sad indeed.', 'spans': [[0, 3]], 'text_spans': ['Damn']}]
Vì dữ liệu được annotate theo offset của từng ký tự nên các bước tiền xử lý tiếp theo phải đặc biệt thận trọng với offset nếu không sẽ làm lệch label của dữ liệu. Mình implement hàm replace() là extension của re.sub() để replace pattern mà vẫn giữ lại offset của các ký tự khác.
from ast import literal_eval
import pandas as pd
from itertools import groupby, cycle
import numpy as np
import re
from nltk.tokenize.api import TokenizerI
def replace(text, pattern, replacement, pos):
matches = [0]
def capture_and_replace(match, ret):
matches.extend([match.start() + 1, match.end()])
return ret
l = len(text)
text = re.sub(pattern, lambda match: capture_and_replace(match, replacement), text, flags=re.IGNORECASE)
matches.append(l)
slices = np.array_split(matches, int(len(matches) / 2))
res = []
for s in slices:
res += pos[s[0]:s[1]]
assert len(text) == len(res)
return text, res
Tiếp đó là preprocess dữ liệu bao gồm loại bỏ URLs, merge các chuỗi ký tự lặp lại thành 1 ký tự duy nhất (ví dụ ?????? -> ?) và strip dấu câu ở đầu, cuối text.
def preprocess(text, pos):
# remove urls
text, pos = replace(text, r'http\S+', ' ', pos)
text, pos = replace(text, r'www.\S+', ' ', pos)
# collapse duplicated punctuations
punc = ',. !?\"\''
for c in punc:
pat = '([' + c + ']{2,})'
text, pos = replace(text, pat, c, pos)
# strip text
text = text.lstrip(' |.|,|!|?')
pos = pos[len(pos)-len(text):]
text = text.rstrip(' |.|,|!|?')
pos = pos[:len(text)]
assert len(text) == len(pos)
return text, pos
Bước tiếp theo là tokenize text. Ở đây mình customize lại tokenizer của NLTK để phù hợp hơn với một số đặc điểm của comment/post (ví dụ những từ như a$$, f**k thì nên giữ nguyên thay vì vì tokenize thành ['a', '$', '$'] hay ['f', '*', '*', 'k'])
class MacIntyreContractions:
"""
List of contractions adapted from Robert MacIntyre's tokenizer.
"""
CONTRACTIONS2 = [
r"(?i)\b(can)(?#X)(not)\b",
r"(?i)\b(d)(?#X)('ye)\b",
r"(?i)\b(gim)(?#X)(me)\b",
r"(?i)\b(gon)(?#X)(na)\b",
r"(?i)\b(got)(?#X)(ta)\b",
r"(?i)\b(lem)(?#X)(me)\b",
r"(?i)\b(mor)(?#X)('n)\b",
r"(?i)\b(wan)(?#X)(na)\s",
]
CONTRACTIONS3 = [r"(?i) ('t)(?#X)(is)\b", r"(?i) ('t)(?#X)(was)\b"]
CONTRACTIONS4 = [r"(?i)\b(whad)(dd)(ya)\b", r"(?i)\b(wha)(t)(cha)\b"]
class NLTKWordTokenizer(TokenizerI):
# Starting quotes.
STARTING_QUOTES = [
(re.compile(u"([«“‘„]|[`]+)", re.U), r" \1 "),
(re.compile(r"(\")"), r" \1 "),
(re.compile(r"([ \(\[{<])(\"|\'{2})"), r'\1 " '),
(re.compile(r"(?i)(\')(?!re|ve|ll|m|t|s|d)(\w)\b", re.U), r"\1 \2"),
]
# Ending quotes.
ENDING_QUOTES = [
(re.compile(u"( ')", re.U), r" \1 "),
(re.compile(r'"'), ' " '),
(re.compile(r"(\S)(\")"), r"\1 \2 "),
(re.compile(r"([^' ]['ll|'LL|'re|'RE|'ve|'VE|n't|N'T]) "), r"\1 "),
]
PUNCTUATION = [
(re.compile(r'([^\.])(\.)([\]\)}>"\'' u"»”’ " r"]*)\s*$", re.U), r"\1 \2 \3 "),
(re.compile(r"([:])([^\d])"), r" \1 \2"),
(re.compile(r"([:,])$"), r" \1 "),
(re.compile(r"\.{2,}", re.U), r" \g<0> "), # See https://github.com/nltk/nltk/pull/2322
(re.compile(r"([\w;@*#$%?!&\^\'\"])+"), r" \g<0> "),
(
re.compile(r'([^\.])(\.)([\]\)}>"\']*)\s*$'),
r"\1 \2\3 ",
), # Handles the final period.
(re.compile(r"([,])+"), r" \g<0> "),
(re.compile(r"([^'])' "), r"\1 ' "),
]
# Pads parentheses
PARENS_BRACKETS = (re.compile(r"[\]\[\(\)\{\}\<\>]"), r" \g<0> ")
# Optionally: Convert parentheses, brackets and converts them to PTB symbols.
CONVERT_PARENTHESES = [
(re.compile(r"\("), "-LRB-"),
(re.compile(r"\)"), "-RRB-"),
(re.compile(r"\["), "-LSB-"),
(re.compile(r"\]"), "-RSB-"),
(re.compile(r"\{"), "-LCB-"),
(re.compile(r"\}"), "-RCB-"),
]
DOUBLE_DASHES = (re.compile(r"--"), r" -- ")
# List of contractions adapted from Robert MacIntyre's tokenizer.
_contractions = MacIntyreContractions()
CONTRACTIONS2 = list(map(re.compile, _contractions.CONTRACTIONS2))
CONTRACTIONS3 = list(map(re.compile, _contractions.CONTRACTIONS3))
def tokenize(self, text, convert_parentheses=False, return_str=False):
for regexp, substitution in self.STARTING_QUOTES:
text = regexp.sub(substitution, text)
for regexp, substitution in self.PUNCTUATION:
text = regexp.sub(substitution, text)
# Handles parentheses.
regexp, substitution = self.PARENS_BRACKETS
text = regexp.sub(substitution, text)
# Optionally convert parentheses
if convert_parentheses:
for regexp, substitution in self.CONVERT_PARENTHESES:
text = regexp.sub(substitution, text)
# Handles double dash.
regexp, substitution = self.DOUBLE_DASHES
text = regexp.sub(substitution, text)
# add extra space to make things easier
text = " " + text + " "
for regexp, substitution in self.ENDING_QUOTES:
text = regexp.sub(substitution, text)
for regexp in self.CONTRACTIONS2:
text = regexp.sub(r" \1 \2 ", text)
for regexp in self.CONTRACTIONS3:
text = regexp.sub(r" \1 \2 ", text)
return text if return_str else text.split()
Thử xem tokenizer có hoạt động không....
tokenizer = NLTKWordTokenizer()
print(tokenizer.tokenize("Trump is a pu*ssy"))
['Trump', 'is', 'a', 'pu*ssy']
Tokenize text cùng thông tin offset:
def tokenize(text, pos):
tokens = tokenizer.tokenize(text)
alignment = []
start = 0
for t in tokens:
res = text.find(t, start)
alignment.append(pos[res:res + len(t)])
start = res + len(t)
assert len(tokens) == len(alignment)
return tokens, alignment
Cuối cùng, chúng ta biểu diễn span dưới dạng IOB (Inside-Outside-Beginning). Trên thực tế, vì bài toán chỉ có một loại thực thể nên chỉ cần biểu diễn nhị phân là đủ. Tuy nhiên trong quá trình thực nghiệm mình nhận thấy biểu diễn IOB cho kết quả tốt hơn.
def annotate(spans, alignment, tokens):
i = 0
annotations = []
for span in spans:
while i < len(alignment):
if alignment[i][-1] <= span[0]:
annotations.append('O')
i += 1
elif alignment[i][0] <= span[0] < alignment[i][-1]:
annotations.append('B-T')
i += 1
elif span[0] < alignment[i][0] < span[-1]:
annotations.append('I-T')
i += 1
elif alignment[i][0] >= span[-1]:
annotations.append('O')
i += 1
break
annotations.extend(['O'] * (len(tokens) - len(annotations)))
return annotations
Tổng hợp lại, ta load dữ liệu, tiền xử lý, tokenize và annotate span dưới dạng IOB. Lưu ý xuyên suốt quá trình trên offset ban đầu của ký tự phải được giữ nguyên.
def prepare_data(data):
idx = 0
formated_data = []
for d in data:
text = d['text']
pos = [i for i in range(len(text))]
text, pos = preprocess(text, pos)
tokens, alignment = tokenize(text, pos)
annotations = annotate(d['spans'], alignment, tokens)
ls = [[tokens[i], annotations[i]] for i in range(len(tokens))]
formated_data.extend(ls)
formated_data.append([None])
idx += 1
return formated_data
train = load_data("toxic_spans/data/tsd_train.csv")
train = prepare_data(train)
train = pd.DataFrame(train)
train.to_csv('train_flair.txt', index=False, columns=None, header=False, sep=' ')
test = load_data("toxic_spans/data/tsd_trial.csv")
test = prepare_data(test)
test = pd.DataFrame(test)
test.to_csv('dev_flair.txt', index=False, columns=None, header=False, sep=' ')
Dữ liệu được lưu thành hai files train_flair.txt phục vụ training và dev_flair.txt phục vụ quá trình tối ưu model.
Mô hình và huấn luyện
Mô hình học sâu mình sử dụng có kiến trúc khá đơn giản. Input features là sự kết hợp của các embedding khác nhau, sau đó đi qua một lớp Reproject Embeddings (thực chất là một lớp Dense) rồi cuối cùng là phần mạng nơ-ron hồi quy BiLSTM-CRF.
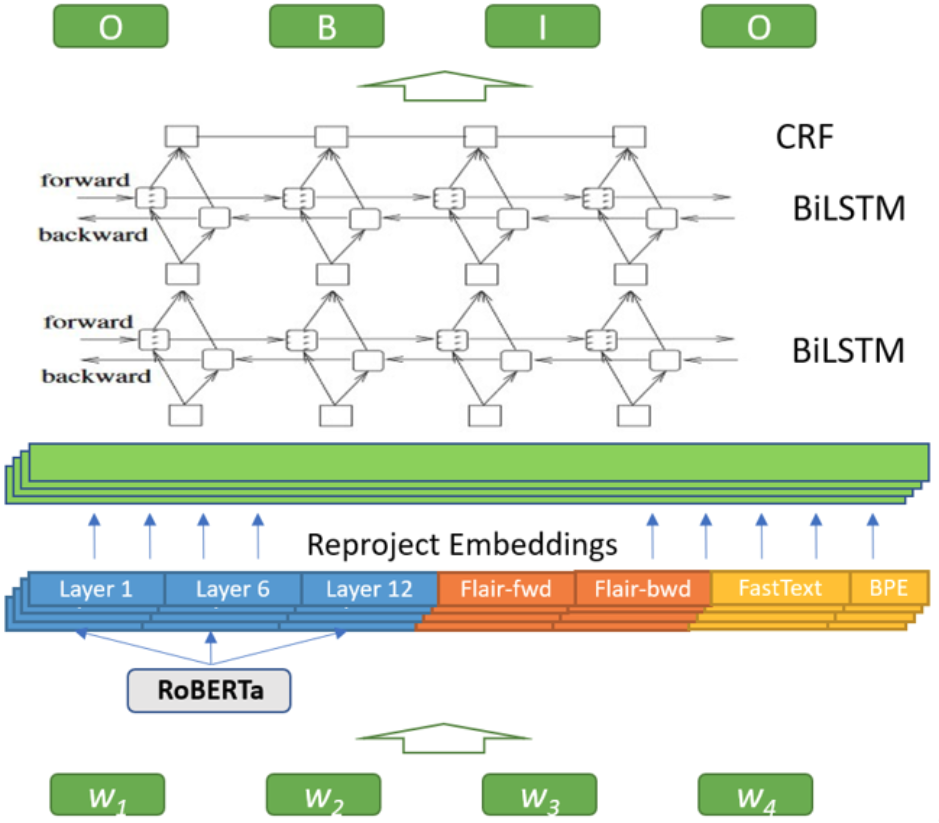
Trong hầu hết các bài toán NLP, word embedding là phần quan trọng nhất. Việc kết hợp các embedding khác nhau giúp mô hình trích xuất được cả thông tin về cú pháp lẫn ngữ nghĩa của một từ. Những embedding này tăng cường điểm mạnh lẫn nhau trong làm giảm những điểm yếu của nhau. Cụ thể những embedding mình sử dụng là:
- Flair: là mô hình ngôn ngữ ngữ cảnh hoạt động ở mức ký tự, mang thông tin về hình thái từ. Flair có hai loại mô hình ngôn ngữ là
forwardvàbackward. Mình fine-tune hai pre-trained models của Flair (news-forwardvànews-backward) trên tập dữ liệu toxic này để mô hình adapt tốt hơn vào miền dữ liệu. Link download: forward và backward (link đã không còn khả dụng do mình lỡ tay xoá mất models trên Drive 🥲). - Toxic RoBERTa: mô hình ngôn ngữ RoBERTa được cộng đồng huggingface fine-tune trên tập dữ liệu gốc của tập dữ liệu này - Civil Comment Dataset. Mô hình RoBERTa thì khỏi phải nói rồi, state-of-the-art, lại được fine-tune trên miền dữ liệu toxic nên embedding của nó thực sự hiệu quả trong bài toán này. Vì các lớp transformer trong RoBERTa biểu diễn mức độ ngữ cảnh khác nhau nên mình trích xuất embedding từ 3 lớp trong RoBERTa: lớp đầu, lớp giữa (#6) và lớp cuối.
- Word2Vec: Tuy hơi cũ và được cho là kém hiệu quả so với các mô hình ngôn ngữ ngữ cảnh hiện nay nhưng mình vẫn cho thêm embedding này và nó cũng cải thiện hiệu năng mô hình thêm một chút. Ở đây mình sử dụng vectơ từ của mô hình fastText để trích xuất embedding kết hợp với Byte Pair Embedding để biểu diễn cho các từ out-of-vocabulary. Sự kết hợp này hoạt động tốt như fastText gốc trong khi giảm mức sử dụng bộ nhớ một cách hiệu quả.
Import các thư viện cần thiết:
from flair.data import Corpus, Token, Sentence
from flair.datasets import ColumnCorpus
from utils import *
from torch.optim.adamw import AdamW
import pandas as pd
from flair.embeddings import *
from flair.models import SequenceTagger
from flair.trainers import ModelTrainer
from flair.training_utils import AnnealOnPlateau
Load corpus bằng Flair:
# define columns
columns = {0: 'text', 1: 'ner'}
# this is the folder in which train, test and dev files reside
data_folder = ''
# init a corpus using column format, data folder and the names of the train, dev and test files
corpus: Corpus = ColumnCorpus(data_folder, columns,
train_file='train_flair.txt',
dev_file='dev_flair.txt')
Sau đó, ta khởi tạo các embeddings và concat chúng lại thành một vectơ dài biểu diễn cho từ. Flair hỗ trợ rất nhiều embeddings khác nhau, ta chỉ cần khởi tạo các embedding mong muốn vào một list và truyền list đó vào StackedEmbeddings là xong. Với TransformerWordEmbeddings mình sẽ sử dụng layer 0 (đầu), layer -6 (giữa) và layer -1 (cuối) như đã nói ở trên, đồng thời set fine_tune=False để freeze toxic RoBERTa. Mình nhận thấy điều này không những giúp quá trình training nhanh hơn mà còn ổn định hơn.
embedding_types = [
TransformerWordEmbeddings('unitary/unbiased-toxic-roberta', layers="-1, -6, 0", fine_tune=False, allow_long_sentences=True, pooling_operation='mean'),
WordEmbeddings('crawl'),
BytePairEmbeddings('en'),
FlairEmbeddings('forward.pt'),
FlairEmbeddings('backward.pt'),
]
embeddings: StackedEmbeddings = StackedEmbeddings(embeddings=embedding_types)
Tiếp theo ta build model (tagger) và trainer. Việc này đối với Flair cực kỳ đơn giản như sau:
tag_type = 'ner'
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
tagger: SequenceTagger = SequenceTagger(hidden_size=256,
rnn_layers=2,
dropout=0.39951586265227385,
locked_dropout=0.4413066564103566,
word_dropout=0.06774606445713507,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
train_initial_hidden_state=True,
use_crf=True)
trainer: ModelTrainer = ModelTrainer(tagger, corpus, optimizer=AdamW)
Và cuối cùng là train model:
trainer.train('output',
learning_rate=0.0005,
embeddings_storage_mode='cpu',
min_learning_rate=0.0000001,
mini_batch_size=32,
max_epochs=50,
scheduler = AnnealOnPlateau,
)
2021-02-22 08:40:08,739 ----------------------------------------------------------------------------------------------------
2021-02-22 08:40:43,913 epoch 1 - iter 21/219 - loss 14.28931536 - samples/sec: 19.11 - lr: 0.000500
2021-02-22 08:41:17,078 epoch 1 - iter 42/219 - loss 11.51475904 - samples/sec: 20.26 - lr: 0.000500
2021-02-22 08:41:51,011 epoch 1 - iter 63/219 - loss 10.56218508 - samples/sec: 19.80 - lr: 0.000500
2021-02-22 08:42:23,469 epoch 1 - iter 84/219 - loss 10.08471138 - samples/sec: 20.70 - lr: 0.000500
2021-02-22 08:42:57,697 epoch 1 - iter 105/219 - loss 9.58165464 - samples/sec: 19.63 - lr: 0.000500
2021-02-22 08:43:31,524 epoch 1 - iter 126/219 - loss 9.26009862 - samples/sec: 19.87 - lr: 0.000500
2021-02-22 08:44:06,541 epoch 1 - iter 147/219 - loss 9.18564796 - samples/sec: 19.19 - lr: 0.000500
2021-02-22 08:44:41,786 epoch 1 - iter 168/219 - loss 8.81589066 - samples/sec: 19.07 - lr: 0.000500
2021-02-22 08:45:15,839 epoch 1 - iter 189/219 - loss 8.55171940 - samples/sec: 19.73 - lr: 0.000500
2021-02-22 08:45:49,743 epoch 1 - iter 210/219 - loss 8.43762823 - samples/sec: 19.82 - lr: 0.000500
2021-02-22 08:46:03,925 ----------------------------------------------------------------------------------------------------
2021-02-22 08:46:03,925 EPOCH 1 done: loss 8.4037 - lr 0.0005000
2021-02-22 08:46:33,552 DEV : loss 8.37681770324707 - score 0.5564
2021-02-22 08:46:33,683 BAD EPOCHS (no improvement): 0
2021-02-22 08:46:41,367 ----------------------------------------------------------------------------------------------------
2021-02-22 08:46:50,622 epoch 2 - iter 21/219 - loss 7.97614507 - samples/sec: 72.63 - lr: 0.000500
2021-02-22 08:46:59,075 epoch 2 - iter 42/219 - loss 7.76867146 - samples/sec: 79.51 - lr: 0.000500
2021-02-22 08:47:07,467 epoch 2 - iter 63/219 - loss 7.33009972 - samples/sec: 80.09 - lr: 0.000500
2021-02-22 08:47:15,520 epoch 2 - iter 84/219 - loss 7.38141656 - samples/sec: 83.46 - lr: 0.000500
2021-02-22 08:47:24,430 epoch 2 - iter 105/219 - loss 7.21088008 - samples/sec: 75.44 - lr: 0.000500
2021-02-22 08:47:32,693 epoch 2 - iter 126/219 - loss 7.61673441 - samples/sec: 81.34 - lr: 0.000500
2021-02-22 08:47:40,978 epoch 2 - iter 147/219 - loss 7.45866577 - samples/sec: 81.12 - lr: 0.000500
2021-02-22 08:47:49,173 epoch 2 - iter 168/219 - loss 7.25671026 - samples/sec: 82.02 - lr: 0.000500
2021-02-22 08:47:58,407 epoch 2 - iter 189/219 - loss 7.12561822 - samples/sec: 72.79 - lr: 0.000500
2021-02-22 08:48:07,609 epoch 2 - iter 210/219 - loss 6.97803578 - samples/sec: 73.04 - lr: 0.000500
2021-02-22 08:48:10,952 ----------------------------------------------------------------------------------------------------
2021-02-22 08:48:10,952 EPOCH 2 done: loss 6.9765 - lr 0.0005000
2021-02-22 08:48:15,613 DEV : loss 7.445516109466553 - score 0.5716
2021-02-22 08:48:15,737 BAD EPOCHS (no improvement): 0
2021-02-22 08:48:23,522 ----------------------------------------------------------------------------------------------------
2021-02-22 08:48:32,302 epoch 3 - iter 21/219 - loss 8.60981764 - samples/sec: 76.55 - lr: 0.000500
2021-02-22 08:48:40,087 epoch 3 - iter 42/219 - loss 7.09732554 - samples/sec: 86.33 - lr: 0.000500
2021-02-22 08:48:48,280 epoch 3 - iter 63/219 - loss 6.86162996 - samples/sec: 82.04 - lr: 0.000500
2021-02-22 08:48:57,734 epoch 3 - iter 84/219 - loss 6.89683542 - samples/sec: 71.10 - lr: 0.000500
2021-02-22 08:49:06,968 epoch 3 - iter 105/219 - loss 6.81617200 - samples/sec: 72.78 - lr: 0.000500
2021-02-22 08:49:16,236 epoch 3 - iter 126/219 - loss 6.80960591 - samples/sec: 72.52 - lr: 0.000500
2021-02-22 08:49:23,976 epoch 3 - iter 147/219 - loss 6.77141035 - samples/sec: 86.84 - lr: 0.000500
2021-02-22 08:49:32,838 epoch 3 - iter 168/219 - loss 6.67913532 - samples/sec: 75.84 - lr: 0.000500
2021-02-22 08:49:40,967 epoch 3 - iter 189/219 - loss 6.55790764 - samples/sec: 82.67 - lr: 0.000500
2021-02-22 08:49:50,167 epoch 3 - iter 210/219 - loss 6.54964189 - samples/sec: 73.06 - lr: 0.000500
2021-02-22 08:49:54,542 ----------------------------------------------------------------------------------------------------
2021-02-22 08:49:54,542 EPOCH 3 done: loss 6.4866 - lr 0.0005000
2021-02-22 08:49:59,195 DEV : loss 7.138552665710449 - score 0.5883
2021-02-22 08:49:59,318 BAD EPOCHS (no improvement): 0
2021-02-22 08:50:07,225 ----------------------------------------------------------------------------------------------------
2021-02-22 08:50:15,322 epoch 4 - iter 21/219 - loss 5.59429038 - samples/sec: 83.02 - lr: 0.000500
2021-02-22 08:50:24,630 epoch 4 - iter 42/219 - loss 5.68623964 - samples/sec: 72.21 - lr: 0.000500
2021-02-22 08:50:33,023 epoch 4 - iter 63/219 - loss 5.78819111 - samples/sec: 80.08 - lr: 0.000500
2021-02-22 08:50:41,336 epoch 4 - iter 84/219 - loss 5.96195083 - samples/sec: 80.85 - lr: 0.000500
2021-02-22 08:50:50,367 epoch 4 - iter 105/219 - loss 5.96660735 - samples/sec: 74.42 - lr: 0.000500
2021-02-22 08:50:59,163 epoch 4 - iter 126/219 - loss 6.26441736 - samples/sec: 76.42 - lr: 0.000500
2021-02-22 08:51:07,049 epoch 4 - iter 147/219 - loss 6.15406115 - samples/sec: 85.23 - lr: 0.000500
2021-02-22 08:51:15,161 epoch 4 - iter 168/219 - loss 6.22897461 - samples/sec: 82.85 - lr: 0.000500
2021-02-22 08:51:24,139 epoch 4 - iter 189/219 - loss 6.16187050 - samples/sec: 74.86 - lr: 0.000500
2021-02-22 08:51:33,240 epoch 4 - iter 210/219 - loss 6.11923879 - samples/sec: 73.85 - lr: 0.000500
2021-02-22 08:51:37,001 ----------------------------------------------------------------------------------------------------
2021-02-22 08:51:37,002 EPOCH 4 done: loss 6.1315 - lr 0.0005000
2021-02-22 08:51:41,718 DEV : loss 6.522727966308594 - score 0.6082
2021-02-22 08:51:41,845 BAD EPOCHS (no improvement): 0
2021-02-22 08:51:49,728 ----------------------------------------------------------------------------------------------------
2021-02-22 08:51:58,504 epoch 5 - iter 21/219 - loss 5.58368506 - samples/sec: 76.62 - lr: 0.000500
2021-02-22 08:52:07,493 epoch 5 - iter 42/219 - loss 5.46633082 - samples/sec: 74.77 - lr: 0.000500
.
.
.
2021-02-22 10:06:04,808 EPOCH 50 done: loss 3.2447 - lr 0.0000020
2021-02-22 10:06:09,542 DEV : loss 3.4154860973358154 - score 0.6238
2021-02-22 10:06:09,668 BAD EPOCHS (no improvement): 3
2021-02-22 10:06:17,481 ----------------------------------------------------------------------------------------------------
2021-02-22 10:06:17,482 Testing using best model ...
2021-02-22 10:06:17,482 loading file output/best-model.pt
2021-02-22 10:06:54,445 0.6881 0.5904 0.6355
2021-02-22 10:06:54,446
Results:
- F1-score (micro) 0.6355
- F1-score (macro) 0.6355
By class:
T tp: 578 - fp: 262 - fn: 401 - precision: 0.6881 - recall: 0.5904 - f1-score: 0.6355
2021-02-22 10:06:54,446 ----------------------------------------------------------------------------------------------------
Model của chúng ta đạt 0.6355 F1-score trên tập dev. Tuy nhiên đây chỉ là F1-score ở mức từ trong khi benchmark của task này sử dụng F1-score ở mức ký tự. Phần tiếp theo ta sẽ tính F1-score mức ký tự trên tập private test.
Evaluate trên tập test
Metric F1 mình sử dụng trực tiếp từ code của BTC cuộc thi như sau:
def f1(predictions, gold):
"""
F1 (a.k.a. DICE) operating on two lists of offsets (e.g., character).
assert f1([0, 1, 4, 5], [0, 1, 6]) == 0.5714285714285714
:param predictions: a list of predicted offsets
:param gold: a list of offsets serving as the ground truth
:return: a score between 0 and 1
"""
if len(gold) == 0:
return 1. if len(predictions) == 0 else 0.
if len(predictions) == 0:
return 0.
predictions_set = set(predictions)
gold_set = set(gold)
nom = 2 * len(predictions_set.intersection(gold_set))
denom = len(predictions_set) + len(gold_set)
return float(nom)/float(denom)
Hàm evaluate model cho một list văn bản:
from tqdm import tqdm
def eval(model, sents, alignments):
preds = []
for idx, sent in tqdm(enumerate(sents)):
model.predict(sent)
pred = []
for span in sent.get_spans():
for tok in span.tokens:
pred.extend(alignments[idx][tok.idx-1])
preds.append(pred)
return preds
Tiếp theo ta load dữ liệu trong tập private test, thực hiện các bước xử lý dữ liệu như với tập train, và predict từng văn bản bằng model đã train:
df = pd.read_csv('tsd_test.csv', index_col=False)[['text']]
sents, alignments = [], []
for text in df['text']:
pos = [i for i in range(len(text))]
text, pos = preprocess(text, pos)
tokens, alignment = tokenize(text, pos)
sents.append(Sentence(tokens))
alignments.append(alignment)
model = SequenceTagger.load('output/best-model.pt')
preds = eval(model, sents, alignments)
Cuối cùng, ta tính F1 mức ký tự cho các predictions của model:
from ast import literal_eval
df = pd.read_csv('data/tsd_test.csv', index_col=False)['spans']
df = df.tolist()
gt = [literal_eval(x) for x in df]
score = 0
for i in range(len(preds)):
score += f1(preds[i], gt[i])
score /= len(preds)
print(score)
0.702659023493706
F1-score 0.7026! Đây là một điểm số khá cao khi top 1 đạt 0.7083 và top 2 đạt 0.7077.
Kết
Trên đây mình đã giới thiệu bài toán Toxic Span Detection và NER implementation cho task 5 SemEval 2021 - một trong những Workshop uy tín nhất trong NLP. Implementation này cho kết quả rất đáng hài lòng, điều này cũng nhờ một phần lớn từ thư viện Flair với hàng loạt các tools, modules cho bài toán NER. Nếu thấy bài viết hữu ích hãy cho mình một upvote nhé 
All rights reserved
