
[Kaggle competition] Wheat detection - Nhận dạng lúa mì với FasterRCNN
Bài đăng này đã không được cập nhật trong 6 năm
1. Introduction
1.1 Competition

Trước tiên mình mình giới thiệu qua về cuộc thi "Global wheat detection" trên kaggle. Hiện tại kaggle đang tổ chức 1 cuộc thi với chủ đề nhận dạng bông lúa mì trong các bức ảnh. Link cuộc thi: global-wheat-detection. Việc nhận dạng lúa mì có ý nghĩa rất lớn đối với các nghiên cứu trong nông nghiệp. Người ta có thể xác định được số lượng, mật độ, kích thước bông lúa, khoảng cách giữa các bông (xác định đang trồng thưa hay trồng dày) trong từng thời kì. Dựa trên những số liệu đó người ta phân tích độ ảnh hưởng của những yếu tố: giống lúa, nhiệt độ, ánh sáng, dinh dưỡng trong từng thời kì phát triển của cây...
Thông tin về Dataset:
- Dataset được tổng hợp từ nhiều bộ dataset của 9 trường đại học trên thế giới
- Folder train gồm 3373 image, có kích thước như nhau:
- File train.csv: Mỗi 1 hàng trong file này chứa thông tin về toạ độ bounding box của 1 bông lúa mì. Các trường thông tin bao gồm: image_id, image_width, image_height, bbox (4 toạ độ x, y, w, h)
1.2 Faster RCNN
Do cuộc thi đòi hỏi độ chính xác nên mình sẽ sử dụng Faster RCNN - 1 model điển hình trong các 2-stage detector. Để tránh lạc đề nên mình sẽ chỉ mô tả qua về thuật toán này, nếu chưa hiểu rõ bạn có thể đọc thêm ở đây: Faster RCNN for object detection
Input đầu vào được đưa qua 1 CNN backbone (VGG, ResNet... ) để trích xuất ra FeatureMap. Tại đây, feature map được đưa qua 1 lớp Convolution để sinh ra các Proposal regions. Đây là các vùng có khả năng chứa object. Dựa vào các Proposal regions này, ta tiến hành tách/cắt FeatureMap để thu được 1 tập các sub-feature tương ứng với từng vùng này. Các sub-feature này có kích thước khác nhau, ta cần bước ROI Pooling để thu được các sub-feature có kích thước như nhau
Với từng sub-feature, ta đưa qua 1 Fully-connected network để thu được output gồm Class distribution và Bounding Box
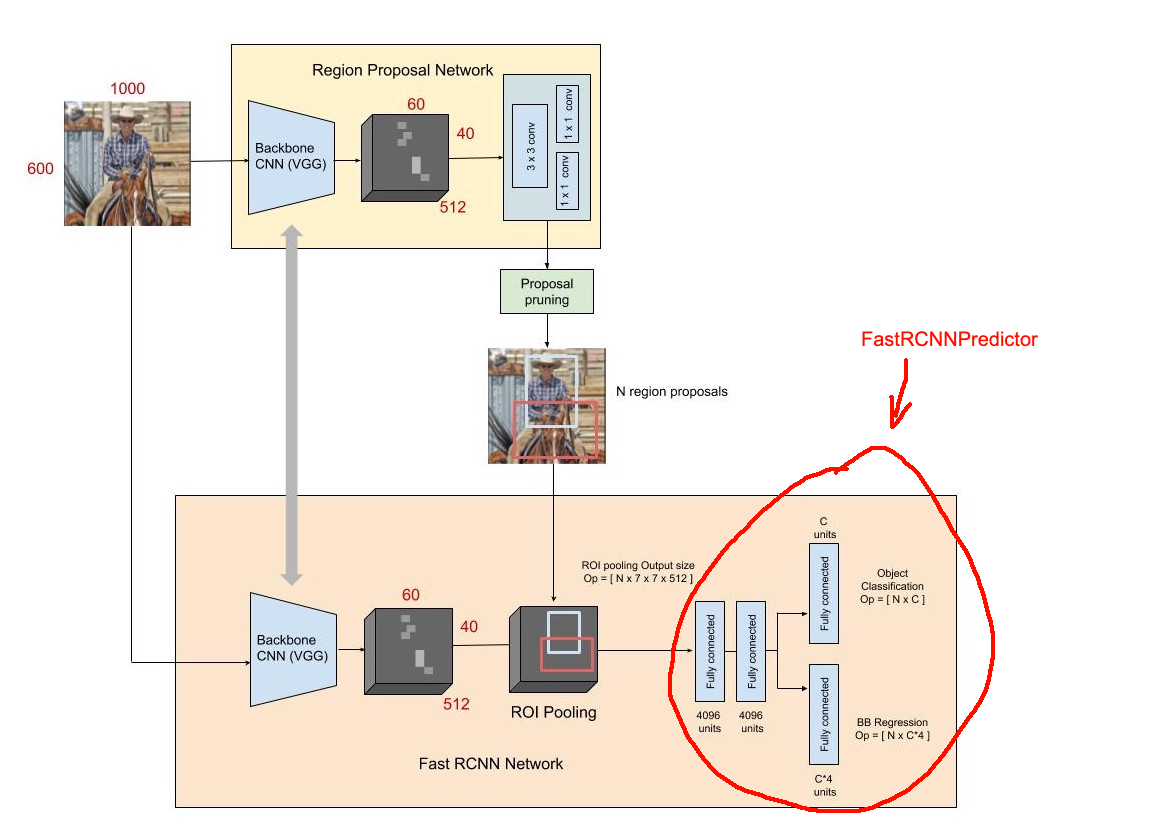
Như vậy mình đã nói qua ý tưởng của Faster RCNN. Trong bài toán này, thay vì code lại hoàn toàn 1 Faster RCNN, mình sẽ dùng Faster-RCNN pretrain-model của torchvision. Thông tin hướng dẫn chi tiết tại: TORCHVISION OBJECT DETECTION FINETUNING TUTORIAL
Khi load 1 pre-define model của torchvision, do số lượng class của chúng ta chỉ là 1 nên ta cần custom lại phần predictor (phần khoanh đỏ trong hình)
Dưới đây là cách khởi tạo 1 pre-defined FasterRCNN model trong torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
# FastRCNNPredictor là đoạn model cuối, tương ứng với phần khoanh đỏ
# do bài toán chỉ có 2 class là wheat và non-wheat nên num_classes = 2
num_classes = 2
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True, progress=False)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
Model này nhận cặp (x_train, y_train) theo định dạng (image, target) với target gồm các trường thông tin như dưới đây.

Để dễ hiểu hơn, ta hãy bắt đầu code trong phần dưới đây.
2. Code and train model
Trong phần này, để tập trung vào nội dung chính, các function phụ mình sẽ không viết mà chỉ mô tả chức năng. Bạn có thể xem chi tiết trong link github của mình: https://github.com/trungthanhnguyen0502. Bạn nên đọc từ Main để hiểu được ý tưởng và luồng xử lí của bài toán rồi sau đó mới đọc chi tiết từng hàm.
Import các thư viện cần thiết
# import cv2, numpy....
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSampler
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
import albumentations as A
from albumentations.pytorch.transforms import ToTensor, ToTensorV2
Định nghĩa các hằng số:
BOX_COLOR = (0, 0, 255)
TEXT_COLOR = (255, 255, 255)
TRAIN_IMG_DIR = "./wheat-dataset/train"
Các hàm phụ để load, show, visualize bounding box:
#show 1 ảnh
def plot_img(img, size=(7,7), is_rgb=False):
....
#show nhiều ảnh
def plot_imgs(imgs, cols=5, size=7, is_rgb=False):
.....
# vẽ bounding box lên ảnh
def visualize_bbox(img, boxes, thickness=3, color=BOX_COLOR):
...
return img_copy
#load và tiền xử lí ảnh
def load_img(img_id, folder=TRAIN_IMG_DIR):
...
return img
Data utils - các function xử lí data
#chuyển đổi cặp [imgs, targets] sang dạng tensor
def data_to_device(images, targets, device=torch.device("cuda")):
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
return images, targets
def expand_bbox(x):
r = np.array(re.findall("([0-9]+[.]?[0-9]*)", x))
if len(r) == 0:
r = [-1, -1, -1, -1]
return r
# đọc data từ file csv
# output là 1 list chứa thông tin về các ảnh
# mỗi phần tử bao gồm 1 image_id và 1 list các bounding box
def read_data_in_csv(csv_path="./wheat-dataset/train.csv"):
df = pd.read_csv(csv_path)
df['x'], df['y'], df['w'], df['h'] = -1, -1, -1, -1
df[['x', 'y', 'w', 'h']] = np.stack(df['bbox'].apply(lambda x: expand_bbox(x)))
df.drop(columns=['bbox'], inplace=True)
df['x'] = df['x'].astype(np.float)
df['y'] = df['y'].astype(np.float)
df['w'] = df['w'].astype(np.float)
df['h'] = df['h'].astype(np.float)
objs = []
img_ids = set(df["image_id"])
for img_id in tqdm(img_ids):
records = df[df["image_id"] == img_id]
boxes = records[['x', 'y', 'w', 'h']].values
area = boxes[:,2]*boxes[:,3]
boxes[:,2] = boxes[:,0] + boxes[:,2]
boxes[:,3] = boxes[:,1] + boxes[:,3]
obj = {
"img_id": img_id,
"boxes": boxes,
"area":area
}
objs.append(obj)
return objs
class WheatDataset(Dataset):
def __init__(self, data, img_dir ,transform=None):
self.data = data
self.img_dir = img_dir
self.transform = transform
def __getitem__(self, idx):
img_data = self.data[idx]
bboxes = img_data["boxes"]
box_nb = len(bboxes)
labels = torch.ones((box_nb,), dtype=torch.int64)
iscrowd = torch.zeros((box_nb,), dtype=torch.int64)
img = load_img(img_data["img_id"], self.img_dir)
area = img_data["area"]
if self.transform is not None:
sample = {
"image":img,
"bboxes": bboxes,
"labels": labels,
"area": area
}
sample = self.transform(**sample)
img = sample['image']
area = sample["area"]
bboxes = torch.stack(tuple(map(torch.tensor, zip(*sample['bboxes'])))).permute(1, 0)
target = {}
target['boxes'] = bboxes.type(torch.float32)
target['labels'] = labels
target['area'] = torch.as_tensor(area, dtype=torch.float32)
target['iscrowd'] = iscrowd
target["image_id"] = torch.tensor([idx])
return img, target
def __len__(self):
return len(self.data)
def collate_fn(batch):
return tuple(zip(*batch))
Main function - luồng xử lí của thuật toán
#load data form csv file
data = read_data_in_csv()
shuffle(data)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# tạo transform cho dataset - các biến đổi để augmentation data
train_transform = A.Compose(
[A.Flip(0.5), ToTensorV2(p=1.0)],
bbox_params={
"format":"pascal_voc",
'label_fields': ['labels']
})
# khởi tạo Dataset và Dataloader
train_dataset = WheatDataset(train_data, img_dir=TRAIN_IMG_DIR, transform=train_transform)
train_loader = DataLoader(
train_dataset,
batch_size=8,
shuffle=True,
num_workers=2,
collate_fn=collate_fn)
# Khởi tạo model
num_classes = 2
num_epochs = 5
iters = 1
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True, progress=False)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0, weight_decay=0.0005)
model.to(device)
# tiến hành train model
for epoch in range(num_epochs):
for images, targets in train_loader:
images, targets = data_to_device(images, targets)
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
optimizer.zero_grad()
losses.backward()
optimizer.step()
iters += 1
# show loss per 30 iteration
if iters%30 == 0:
print(f"Iteration #{iters} loss: {loss_value}")
# để đơn giản, ta save model mỗi 90 iteration
if iters%90 == 0:
evaluate(model, val_loader, device=device)
model_path = f"./saved_model/model_{iters}_{round(loss_value, 2)}.pth"
torch.save(model.state_dict(), model_path)
model.train()
Sau 3 tiếng train thì đây là kết qủa tốt nhất mình thu được:
Như vậy mình đã hướng dẫn sử dụng 1 predefine-detector của FasterRCNN. Thực ra để đạt được kết quả tốt, ta cần phải thực hiện nhiều kĩ thuật về augmentation, pseudo label, validate ...Tuy nhiên trong bài này mình chỉ hướng dẫn đơn giản nhất có thể để các bạn làm quen thôi. Cảm ơn các bạn đã đọc.
All rights reserved
