
Sau khi bỏ được anchor, trong tương lai object detection sẽ bỏ được hoàn toàn NMS?
Bài đăng này đã không được cập nhật trong 4 năm
Tóm tắt
Thời gian gần đây, object detection đã có nhiều thay đổi về kiến trúc mô hình và các thành phần trong pipeline để hoạt động hiệu quả và bớt cồng kềnh hơn. Có thể kể đến một số thay đổi như: loại bỏ anchors, sử dụng đầu tách (decoupled head), kiến thức tiềm ẩn (implicit knowledge), các chiến lược gán nhãn (label assignment) ... và loại bỏ thành phần Non-maximum suppression (NMS). NMS có lẽ là thành phần khá quen thuộc trong các phương pháp cho bài toán object detection. Nhiều nhóm nghiên cứu nhận thấy nhược điểm NMS và những ảnh hưởng tiêu cực của nó đã nỗ lực loại bỏ thành phần này. Những phương pháp được đề xuất trong một số nghiên cứu đã thu được kết quả tương đương(hoặc thậm chí là có cải thiện) so với việc sử dụng NMS.
Bài viết này sẽ bàn về:
- Sự cần thiết của NMS trong bài toán object detection
- Tại sao cần phải loại bỏ NMS để đạt được end-to-end object detection
- Việc dự đoán dư thừa đến từ đâu?
- Một số phương pháp đề xuất để loại bỏ NMS hiệu quả.
Nội dung
Tác dụng của NMS.

Một vấn đề mà các phương pháp thường gặp phải là mô hình tạo ra các box dư thừa trong quá trình dự đoán. Cụ thể, mô hình thường predict nhiều box cho một object (duplicate predictions). Nếu không xử lý thì điều này sẽ làm giảm độ chính xác của mô hình. Kết quả mong đợi của bài toán là mỗi object chỉ được predict một lần. NMS có lẽ là một trong những phương pháp đầu tiên được sinh ra để giải quyết vấn đề này. Hình 1 minh hoạ kết quả của mô hình trước và sau xử lý NMS. Từ hình ta có thể thấy mỗi object người và ván trượt đều được predict hai lần. Sau khi đưa kết quả của mô hình qua NMS, dựa vào độ tin cậy/độ tự tin của từng box và IoU (Intersection over Union, tỷ lệ phần giao cho phần hợp của hai box) giữa các box, NMS giúp mô hình loại bỏ hai box kém chính xác.
Tại sao cần phải loại bỏ NMS?
Đầu tiên, hãy cùng nhìn lại một số đặc điểm thường thấy của NMS:
- NMS là biến đổi không khả vi, cần xác định ngưỡng (threshold) thích hợp dựa vào kết quả thử nghiệm trên tập dữ liệu
- Ngưỡng sau khi được xác định sẽ hoạt động như nhau với mọi loại object, kích thước của object, mật độ của các đối tượng, v.v.
Trong phần này, bài viết sẽ chỉ ra những hạn chế của các phương pháp sử dụng hậu xử lý NMS, những hạn chế này liên quan trực tiếp tới hai tính chất kể trên của NMS.
Tính chất đầu tiên làm các phương pháp sử dụng NMS trở nên phức tạp hơn so với end-to-end object detection. NMS yêu cầu một quá trình xác định ngưỡng độc lập với quá trình training, quá trình này thông thường sẽ thử các giá trị ngưỡng trên toàn bộ tập dữ liệu test và chọn ra ngưỡng phù hợp. Dễ thấy rằng, quá trình xác định ngưỡng này đặt ra thêm chi phí tính toán. Để hướng tới end-to-end object detection đòi hỏi tất cả các thành phần trong training pipeline đều khả vi. Do đó, để đạt được end-to-end trainable thì cần phải loại bỏ NMS trong training pipeline. Trong những năm trở lại đây, một thành phần khác trong pipeline là anchor đã có thể được loại bỏ mà không làm giảm (và thậm chí là tăng) performance của phương pháp [4, 5]. Điều này dẫn đến NMS là thành phần cuối cùng còn lại trong pipeline không khả vi, ngan cản việc đạt được end-to-end. Vì vậy, những nghiên cứu về việc loại bỏ NMS một cách hiệu quả ngày càng được đẩy mạnh trong thời gian gần đây.
Tính chất thứ hai sẽ khiến NMS hoạt động tốt trên tập dữ liệu này nhưng có thể không hoạt động tốt với tập dữ liệu khác. Đặc biệt, NMS hoạt động không tốt trong trường hợp cảnh đông đúc (crowded scenes) ví dụ như các tập dữ liệu CrowdHuman, CityPersons. Đây là yếu tố quan trọng để bạn lựa chọn sử dụng mô hình object detection có NMS hay không, phụ thuộc vào đặc điểm tập dữ liệu mà bạn hướng đến. Một số bài báo [1] đã công bố kết quả quả sử dụng end-to-end thu được cao hơn nhiều so với phương pháp sử dụng NMS.
Duplicate preditions đến từ đâu?
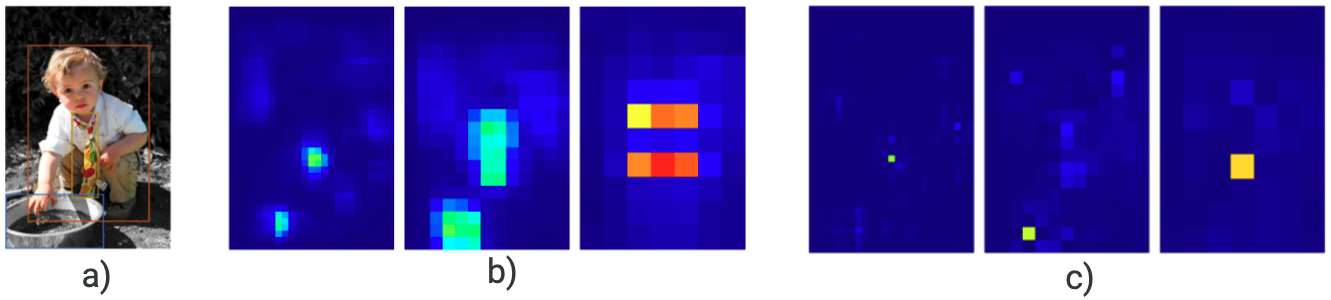
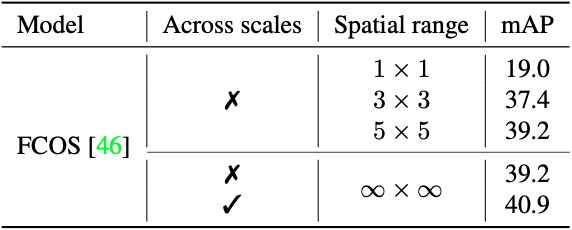
Bài báo [2] đã làm thí nghiệm để chỉ ra các nguồn gây ra duplicate predictions và đâu là nguồn chính. Hình 2b) minh hoạ kết quả đầu ra của một mạng Fully Convolutional Network (FCN). Trong trường hợp này, với mỗi object cả ba head của mạng đều xung phong detect, và trong từng head cũng có nhiều anchor (hay grid cell trong YOLO) xung phong detect. Việc nhiều anchor cùng detect được object gây ra sự dư thừa box (duplicate predictions). Duplicate predictions xuất hiện ở cả giữa các head và trong cùng một head. Để xác định xem duplicate predictions diễn ra chủ yếu ở đâu nhóm tác giả [2] đã làm 2 thí nghiệm: 1) sử dụng NMS riêng rẽ với từng đầu và tăng dần phạm vị kiểm tra duplicate, 2) sử dụng NMS với phạm vi tối đa và với toàn predictions giữa các đầu. Kết quả của thí nghiệm thể hiện ở hình 3 cho thấy duplicate predictions chủ yếu đến từ những anchor xung quanh anchor có tự tin cao (confident) nhất.
Làm thế nào để loại bỏ NMS
Nhiều phương pháp end-to-end được đề xuất qua các bài báo. Dù những phương pháp này tương đối khác nhau, hầu hết chúng vẫn cần đáp ứng chung một số điều kiện cần để hoạt động hoạt quả mà không dùng NMS. Những điều kiện này cũng được chỉ ra trong bài báo [3], đó là:
- Sử dụng cả classification cost và localization cost để thực hiện label assignment, thay vì một số phương pháp chỉ sử dụng localization cost
- Sử dụng one-to-one (OTO) label assignment, thay vì sử dụng one-to-many (OTM) label assignment
Điều kiện cần đầu tiên khá dễ đáp ứng với các phương pháp mới nhất hiện nay. Cụ thể, nhiều phương pháp đã vốn sử dụng cả classification cost và localization cost để lựa chọn các anchor (grid cell) cho từng ground truth box. Có thể kể đến một số phương pháp vẫn sử dụng NMS đã thoả mãn điều kiện này như OTA[6], YOLOX[5], TOOD[7], PP-YOLOE[8].
Trái với điều kiện cần đầu tiên, để đáp ứng được điều kiện cần thứ hai chúng ta có thể phải đánh đổi bằng độ chính xác của mô hình. OTM vốn được sử dụng để cung cấp nhiều hơn sự giám sát (supervision) từ đó đem lại lợi ích về gradient trong quá trình huấn luyện. Nhưng cũng chính OTM assignment gây ra OTM prediction. Việc chuyển từ OTM sang OTO trong nhiều trường hợp sẽ làm giảm độ chính xác của mô hình. Do đó, chúng ta cần có cách giải quyết phù hợp ứng phó sự suy giảm độ chính xác này . Trong phần tiếp theo bài viết sẽ nêu một vài phương pháp để giải quyết vấn đề này.
Việc thoả mãn cả hai điều kiện trên, nếu được thiết đặt phù hợp có thể thu được end-to-end object, việc sử dụng hay không sử dụng NMS không làm thay đổi nhiều performance. Tuy nhiên, như đã nói ở trên cần phải giải quyết vấn đề lượng supervision bị mất khi sử dụng OTO label assignment. Trong phần tiếp theo, bài viết sẽ giới thiệu một số phương pháp end-to-end object detection hiệu quả.
Một số phương pháp End-to-End Object Detection hiệu quả
Object Detection Made Simpler by Eliminating Heuristic NMS
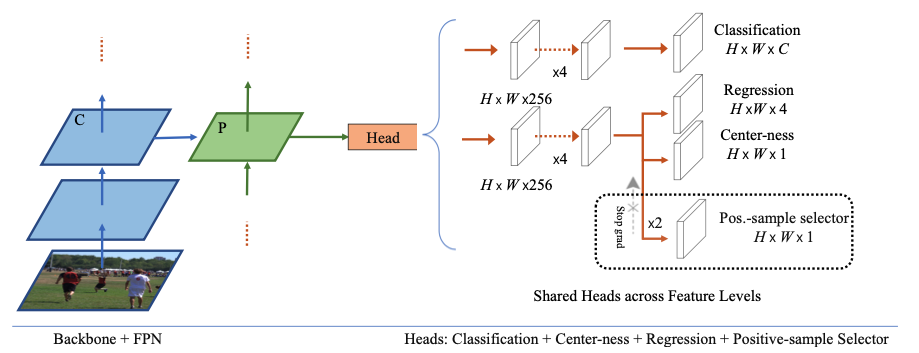
Từ hình 4 ta có thể thấy phương pháp đề xuất thêm một nhánh mới là Positives-sample selector (PSS). Nhánh này làm thay nhiệm vụ của NMS, có thể coi nó là một dạng learnable NMS. Trong khi, nhánh classification và regression vẫn có thể sử dụng one-to-many label assignment thì nhánh PSS tuân theo hai điều kiện cần như đã bàn đến ở phần trước. Khi training, PSS sử dụng kỹ thuật stop gradient, do đó không ảnh hưởng đến gradient của phần mạng còn lại. Khi inference, nhánh PSS làm tăng rất ít thời gian chạy và tài nguyên bộ nhớ, PSS lúc này cũng hoàn toàn có thể loại bỏ để sử dụng NMS nếu muốn mà không cần traning lại.
End-to-End Object Detection with Fully Convolutional Network
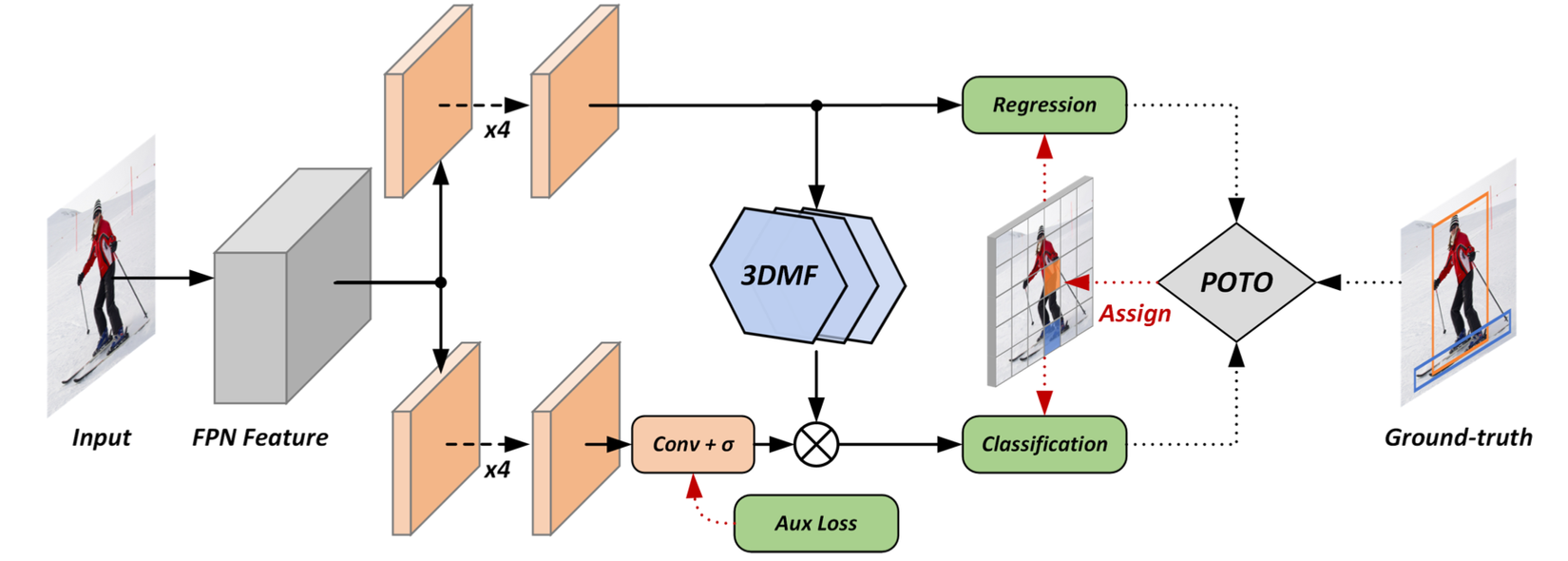
Tương tự như phương pháp trên, phương pháp này cũng sử dụng một thành phần dạng learnable NMS đó là 3D Max Filtering (3DMF) và đáp ứng cả hai điều kiện cần đã nêu. Để bù cải thiện hiệu năng do sử dụng OTO label assignment, phương pháp sử dụng OTM để tạo ra loss phụ (aux loss) ở một nhánh khác, cung cấp thêm supervision cho mô hình. Nhánh này có thể được bỏ đi trong quá trình inference.
Lời kết
Trên đây là những gì mình rút ra trong quá trình tìm hiểu và tổng hợp lại được thông qua việc đọc các paper. Rất mong được trao đổi thêm và nhận các góp ý từ các bạn với các bạn về chủ đề này trong phần comment hoặc qua hòm thư nguyen.tung.thanh@sun-asterisk.com. Hy vọng bài viết này có ích với bạn. Cảm ơn các bạn đã ủng hộ bài viết. Đừng quên cho mình 1 upvote nếu thấy bài viết có ích với bạn và cũng là để ủng hộ mình ra những bài viết chất lượng hơn nhé.
Tài liệu tham khảo
[1] Object Detection Made Simpler by Eliminating Heuristic NMS
[2] End-to-End Object Detection with Fully Convolutional Network
[3] What Makes for End-to-End Object Detection
[4] Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
[5] YOLOX: Exceeding YOLO Series in 2021
[6] OTA: Optimal Transport Assignment for Object Detection
[7] TOOD: Task-aligned One-stage Object Detection
[8] PP-YOLOE: An evolved version of YOLO
All rights reserved
