
YOLOV5 - Detect lúa mì chỉ trong vài phút
Bài đăng này đã không được cập nhật trong 6 năm
 Bài viết tại series SOTA trong vòng 5 phút?
Bài viết tại series SOTA trong vòng 5 phút?
I. Introduction
Tối hôm trước khi mình đang ngồi viết bài phân tích paper yolov4 thì nhận được tin nhắn của một bạn có nhờ mình fix hộ bug khi training model yolov5 trong quá trình tham gia cuộc thi Global Wheat Detection trên kaggle và nó chính là lý do ra đời cho bài viết này của mình. Bài viết mang tính chất chia sẻ về phương pháp chứ mình thì tham gia kaglle toàn nát thôi (buonthiu). Cuộc thi với chủ đề là nhận dạng bông lúa mì trong các bức ảnh và sau khi search search trên viblo và google thì mình có thấy một bài viết Nhận dạng lúa mì với Faster RCNN của anh Nguyễn Thành Trung các bạn có thể tham khảo thêm về các phương pháp cho bài toán này nhé.
YOLO-"You Only Look Once" một phương pháp phổ biến và được yêu thích cho các mới tìm hiểu về AI cũng như đang làm về AI. Nó luôn là ưu tiên hàng đầu khi giải quyết các bài toán về detection. Các bạn có thể tham khảo bài viết Tìm hiểu về YOLO trong bài toán real-time object detection của mình.
II. Lịch sử họ nhà YOLO
YOLOv1 được ra mắt vào tháng 5 năm 2016 bởi Joseph Redmon với paper "You Only Look Once: Unified, Real-Time Object Detection". Nó là sự phát triển rất lớn cho các bài toán real-time object detection .
Tới tháng 12 năm 2017 thì Joseph introduced tiếp tục công bố một version khác của YOLO với paper "YOLO9000: Better, Faster, Stronger" nó được biết đến với tên gọi là YOLO9000.
Sau đó chưa đầu một năm đến tháng 4 năm 2018, một phiên bản mong đợi nhất của YOLO đã được ra mắt với tên gọi YOLOv3 với paper “YOLOv3: An Incremental Improvement”.
Đúng 2 năm sau Alexey Bochkovskiy đã giới thiệu YOLOv4 với paper “YOLOv4: Optimal Speed and Accuracy of Object Detection”. YOLOV4 được giới thiệu với những điều vô cùng đánh kinh ngạc , nó vượt trội hơn YOLOv3 với tốc độ cũng như độ chính xác trung bình một cách đáng kể. Mình sẽ sớm ra mắt các bạn bài viết phân tích về YOLOv4 để chúng ta cùng thảo luận nhé, mọi người hãy follow mình để đón chờ bài viết mới nhất nhé  ).
).
Sau đó vài ngày thì Glenn Jocher đã phát hành YOLOv5, có rất nhiều những tranh cãi xảy ra với cái tên YOLOv5 này. Glenn đã trình làng PyTorch based version of YOLOv5 với những sự cải tiến đáng kể. Nhưng cho tới tận bây giờ cũng chưa có một paper nào nói về điều này. Phiên bản này khá tuyệt vời và vượt trội hơn tất cả các đàn anh trước đó. Bạn có thể nhìn thấy qua biểu đồ dưới đây 
Các bạn có thể xem thêm về các so sánh này theo đường link dưới đây :
https://blog.roboflow.ai/yolov4-versus-yolov5/
III. Training YOLOv5 với bài toán Global Wheat Detection
- Preparing Dataset
- Environment Setup
- Configure/modify files and directory structure
- Training
- Inference
- Result
3.1 Preparing Dataset
Thông tin về Dataset:
- Bộ dataset bao gồm train.zip, test.zip, sample_submission.csv, train.csv
- Folder train gồm có tất cả 3373 images có kích thước như nhau: 1024*1024
- File train csv bao gồm thông tin về toạ độ của bông lúa mì :
- image_id: tên file
- width, height: chiều rộng và chiều cao của hình ảnh
- bbox: là 1list python bao gồm 4 toạ độ theo format [xmin, ymin, width, height]
Các bạn có thể tải về hoặc tham gia cuộc thi theo link dưới đây :
https://www.kaggle.com/c/global-wheat-detection/data
Dữ liệu đầu vào ảnh của YOLOv5 theo format darknet với mỗi 1 file .txt sẽ cho 1 ảnh có chứa đối tượng ta label, còn với những ảnh không có đối tượng thì thôi. File .txt sẽ có format như sau :
- Mỗi hàng sẽ là một đối tượng
- Mỗi hàng sẽ có format như sau: class x_center y_center width height
- Toạ độ của các box sẽ được normalized (từ 0-1) theo format xywh
- Class sẽ bắt đầu từ 0
Lưu ý rằng khác với Faster RCNN thì YOLO sẽ không tính lớp Background
Ví dụ:

Cấu trúc thư mục file images và labels mình đang lưu như sau :

Implement code
Như các bạn có thể thấy thì format dữ liệu đầu vào của yolov5 đang khác với dữ liệu mà ban tổ chức cuộc thi cũng cấp nên chúng mình cần cấu trúc lại một cho phù hợp :
- Import các thư viện cần thiết :
import numpy as np
import pandas as pd
import shutil
import tqdm.auto as tqdm
import os
Sau đó thì:
df = pd.read_csv('/content/gdrive/My Drive/global-wheat-detection/train.csv')
bbox = np.stack(df['bbox'].apply(lambda x:np.fromstring(x[1:-1], sep=',')))
for i, column in enumerate(['x', 'y', 'w', 'h']):
df[column] = bbox[:,i]
df['x_center'] = df['x'] + df['w']/2
df['y_center'] = df['y'] + df['h']/2
df['classes'] = 0
df = df[['image_id', 'x', 'y', 'w', 'h', 'x_center', 'y_center', 'classes']]
index = list(set(df['image_id']))
Trước tin chúng ta cần đọc file train.csv sau đó dùng hàm dùng hàm np.stack để chuyển df thành 1 mảng bao gồm các phần tử trong mảng là 1 string và các string đó là 1 mảng, sau đó string sẽ app vào hàm np.fromstring để chuyển string thành 1 mảng và được tách dấu ",". Sau đó múa may vài dòng code để chuyển theo các toạ độ mong muốn và được kết quả đầu ra như sau:

source = 'train'
for fold in [0]:
val_index = index[len(index)*fold//5:len(index)*(fold+1)//5]
for name, data in df.groupby('image_id'):
if name in val_index:
path2save = 'val/'
else:
path2save = 'train/'
if not os.path.exists('/content/gdrive/My Drive/global-wheat-detection/fold{}/labels/'.format(fold)+path2save):
os.makedirs('/content/gdrive/My Drive/global-wheat-detection/fold{}/labels/'.format(fold)+path2save)
with open('/content/gdrive/My Drive/global-wheat-detection/fold{}/labels/'.format(fold)+path2save+name+".txt", '+w') as f:
row = data[['classes', 'x_center', 'y_center', 'w', 'h']].astype(float).values
row = row/1024
row = row.astype(str)
for j in range(len(row)):
text = ' '.join(row[j])
f.write(text)
f.write("\n")
if not os.path.exists('/content/gdrive/My Drive/global-wheat-detection/fold{}/image/'.format(fold)+path2save):
os.makedirs('/content/gdrive/My Drive/global-wheat-detection/fold{}/image/'.format(fold)+path2save)
shutil.copy('/content/gdrive/My Drive/global-wheat-detection/{}/{}.jpg'.format(source,name), '/content/gdrive/My Drive/global-wheat-detection/fold{}/image/{}/{}.jpg'.format(fold,path2save,name))
Chúng ta sẽ chia dữ liệu thành 5 phần và sẽ lấy 1 phần trong đó để validation còn lại sẽ để training, tiếp theo tạo ra các folder để lưu images và labels chung trong folder fold0. Mỗi images sẽ tương ứng với 1 file .txt, trong file .txt thì mỗi objects sẽ là 1 hàng. Và việc đơn giản là chỉ cần đợi nó chạy xong, mình chạy trên colab và đợi cũng khá lâu )
3.2 Environment Setup
Điều quan trọng cần lưu ý là yêu cầu Pytorch ≥ 1.5, Python version 3.7 và CUDA version 10.2.

Trước tiên cần
git clone https://github.com/ultralytics/yolov5
Sau đó install các thư viện trên trong requirments đơn giản chỉ với dòng lệnh sau:
pip install -U -r requirements.txt
3.3 Configure/modify files and directory structure
Tạo ra 1 file yaml như sau :
# parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [116,90, 156,198, 373,326] # P5/32
- [30,61, 62,45, 59,119] # P4/16
- [10,13, 16,30, 33,23] # P3/8
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
]
# YOLOv5 head
head:
[[-1, 3, BottleneckCSP, [1024, False]], # 9
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 18 (P3/8-small)
[-2, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 22 (P4/16-medium)
[-2, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 26 (P5/32-large)
[[], 1, Detect, [nc, anchors]], # Detect(P5, P4, P3)
]
Như mình mình sẽ lưu file này trong thư mục models. Thêm 1 file yaml nữa:
train: /content/gdrive/My Drive/global-wheat-detection/fold0/images/train # 128 images
val: /content/gdrive/My Drive/global-wheat-detection/fold0/images/val # 128 images
# number of classes
nc: 1
# class names
names: ['wheat']
Các bạn nên để đường dẫn chi tiết tới thư mục train và trong bài toán này chỉ bao gồm 1 class đó là wheat, mình sẽ lưu vào trong thư mục data.
3.4 Training
YOLOv5 đề xuất 4 versions:
- yolov5-s which is a small version
- yolov5-m which is a medium version
- yolov5-l which is a large version
- yolov5-x which is an extra-large version

Bạn có thể đọc so sánh chi tiết hơn tại đây
# Train YOLOv5s on coco128 for 5 epochs
!python train.py --img 640 --batch 16 --epochs 100 --data ./data/wheat_detection.yaml --cfg ./models/yolov5_wheat.yaml --weights yolov5s.pt --name tutorial --nosave --cache --device 0
— img: size of the input image
— batch: batch size
— epochs: number of epochs
— data: YAML file which was created in step 3
— cfg: model selection YAML file. I have chosen “s” for this tutorial.
— weights: weights file to apply transfer learning, you can find them here.
— device: to select the training device, “0” for GPU, and “cpu” for CPU.
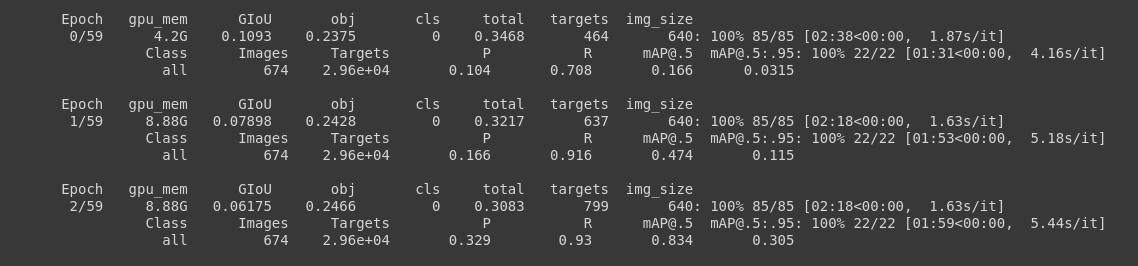
3.5 Inference
Quá trình training đã hoàn thành bây giờ các bạn có thể đánh giá mô hình training có hiệu quả hay không bằng cách nhìn các tham gia đánh giá qua tensorboard hoặc bạn có thể sử dụng utils.plot_results và lưu kết quả như một result.png.
from utils.utils import plot_results; plot_results() # plot results.txt files as results.png
Image(filename='./result.png', width=1000)
3.6 Result
!python detect.py --weights weights/last_yolov5s_custom.pt --img 416 --conf 0.4 --source ../test_infer
Sau khi quá trình training hoàn tất bạn có thể đánh giá mô hình trên hình ảnh và weights được lưu tại weights.

Các bạn có thể sử dụng thêm các phương pháp để cải thiện thêm về chất lượng mô hình nhé
Bài viết của mình tới đây là kết thúc cảm ơn các bạn đã theo dõi bài viết của mình. Nếu thấy hữu ích đừng quên cho mình xin 1 lượt upvote vf follow mình nhé để mình có thể động lực ra nhiều bài hơn nữa. (tym)(tym)(tym)
IV. Tài liệu tham khảo
All rights reserved
