
Becoming master of SSD, deeply understand about Object Detection - SSD Paper Explain
Bài đăng này đã không được cập nhật trong 5 năm
Xin chào mọi người, có thể nói tính đến thời điểm hiện tại, AI nói chung và Computer Vision(CV) nói riêng đã thực sự có những thay đổi rất lớn trong những năm gần đây. Mình tin những ai tìm hiểu về CV đều biết và đều quen thuộc với bài toán Object Detection là gì và có vai trò như thế nào trong lĩnh vực Thị giác máy. HIện nay có thể thấy có rất nhiều những mô hình Object Detection mới ra đời đạt được độ chính xác cao như Faster RCNN, Detectron, EfficientNet hoặc những mô hình có sự cân bằng giữa độ chính xác và thời gian thực thi như YOLO, SSD, và chúng ta có thể dễ dàng tìm được những bộ source code có sẵn trên mạng và ứng dụng vào bài toán của mình. Nhưng mình vẫn quyết định viết bài này, vì SSD là một mô hình đặc thù phải custom khá nhiều, và nó sẽ có ích cho những ai mong muốn hiểu sâu hơn về mô hình SSD, hoặc có 1 nền tảng căn bản hơn để có thể đọc, hiểu và implement được những mô hình object detection sau này. Như title bài viết, bài viết này mình sẽ tập trung phân tích cấu trúc mô hình SSD, tác dụng của từng phần, và giải thích code cho từng phần chi tiết nhất có thể.
PS: Bài viết được viết dựa theo kiến thức, ý hiểu chủ quan của tác giả theo paper. Nếu có bất kỳ thắc mắc xin vui lòng comment bên dưới hoặc gửi vào mail @nguyen.van.dat@sun-asterisk.com.
I. Introduction
Cùng nói qua một chút về Object Detection và mô hình SSD nhé. Object Detection có thể coi là một trong những bài toán quan trọng trong CV, nhiệm vụ của nó là giải quyết việc xác định vị trí các vật thể (object: người, xe máy, ô tô, chó, mèo, ...) trong ảnh hoặc video và biễu diễn chúng bằng các bounding box (x, y, w, h) trong đó x, y thường là vị trí top-left của vật thể trong ảnh, video và w, h tương ứng là độ rộng và chiều cao của các bounding box này. Về ứng dụng của Object Detection, nổi bật có thể kể đến như: Facial Recognition, Industrial Quality check, Self driving cars, People Counting, Medical Support...
Trong đó, SSD là một thuật toán con của Object Detection, có tính đặc thù cao vì phải custom lại khá nhiều. Chi tiết chúng ta sẽ đi sâu hơn SSD ở các phần tiếp theo dưới đây nhé.
II. Single Shot Multibox Detetor (SSD)
1. Architecture

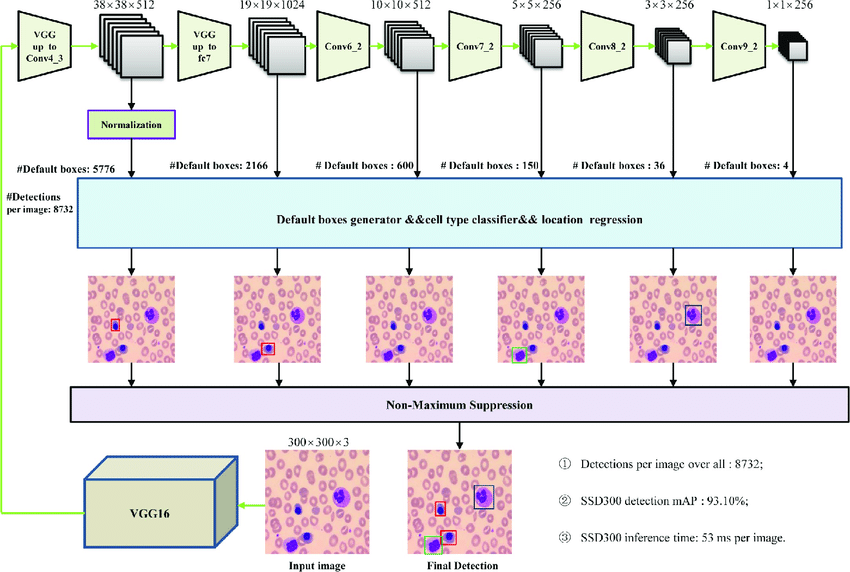
Hình : Kiến trúc chung của mô hình SSD (copy từ official paper)
Kiến trúc chung của một mô hình SSD sẽ gồm 2 phần chính, bao gồm: Backbone, Detector. Trong đó, backbone đóng vai trò trích xuất ra những đặc trưng của ảnh, từ high resolution features cho đến low-resolution features tương ứng với mức độ quan trọng của features. Các high-resolution features thường mang các đặc tính như các edge, boudary, còn low-resolution features thường mang các đặc tính như shape object, global context của ảnh. Nhiệm vụ của các backbone rất quan trọng, nó ảnh hưởng rất nhiều đến độ chính xác ở các layer detectors phía sau. Ở hình trên: tác giả sử dụng backbone là VGG-16, một mô hình rất sâu đủ khả năng trích xuất được các đặc trưng quan trọng, tuy nhiên chúng ta đều biết lượng tham số mô hình của VGG là rất lớn, do vậy trong một vài trường hợp, mang tính trade-off giữa độ chính xác và thời gian thực thi chúng ta hoàn toàn có thể thay đổi các backbone này như MobileNet (V1, V2, V3) .
2. Multiscale Detection
Sự khác biệt của SSD so với một số mô hình object detection khác là nó tận dụng các layers với từng size khác nhau ở tầng backbone để đưa ra dự đoán cho vị trí của vật thể ở các mức scale khác nhau. Các Detectors sẽ dựa vào các layers này để đưa ra các dự đoán như vị trí (loc), class confidence tại từng vị trí trong một feature map (m x n x p, p channels). Để làm được điều đó, chúng ta sẽ phải xác định những layers nào ở tầng backbone sẽ được dùng để trả về 1 tập các predictions bằng cách sử dụng các Convolution layers on top trên những layers này. Theo paper, những layers sẽ được dùng để make predictions là conv4_3_norm (L2Normalization) (38 x 38 x 512), fc_7 (19 x 19 x 1024), conv8_2 (10x10x512), conv9_2 (5 x 5 x 256), conv10_2 (3 x 3 x 256) và conv11_2 (1 x 1 x 256). Convolution được sử dụng ontop trên những layers backbone này là Conv2D với kernel_size sẽ là (3 x 3).
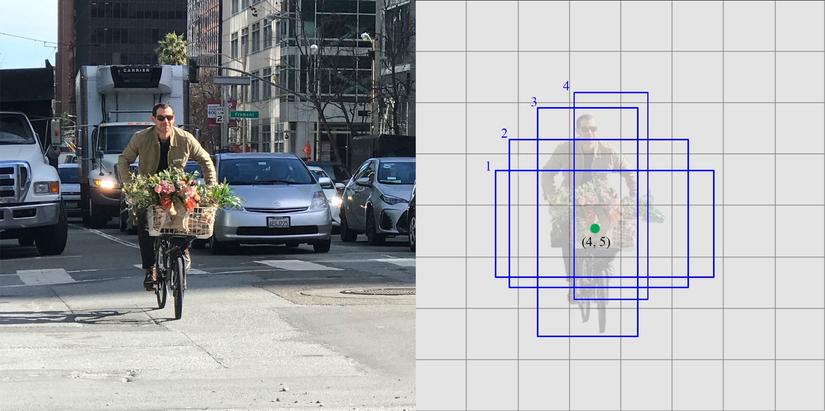
Đến đây là những bước ý tưởng đầu tiên của SSD, chúng ta đã nắm được ý tưởng tổng quát là SSD nó sẽ detect các object và sinh ra các bounding boxes dựa vào multiple scale của các layers dưới backbone. Vậy làm thế nào để biết được object này là thuộc class nào, bounding boxes của object này được tính như thế nào. Như phần trên đã nói, chúng ta sẽ đặt các conv prediction layers phía trên các backbone multi-scale layers phía dưới để trích xuất ra các đặc trưng cần thiết từ các tầng layers này. Vì vậy, ta cần 2 loại conv layers on top, 1 là conv để tính class confidence, 1 dùng để tính location của object, ta sẽ gọi chúng là conv_dtec_conf và conv_dtec_loc, những features tương ứng với những layers này sẽ là những thông tin về khả năng 1 class xuất hiện, vị trí (location) của vật thể trong ảnh. Cùng tham khảo ảnh sau để hiểu hơn nhé:
Code minh họa cho các layers này như sau:
# Confedence detection block
conv4_3_norm_dtec_conf = Conv2D(self.n_boxes[0]*self.num_classes, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv4_3_norm_dtec_conf")(conv4_3_norm)
fc_7_dtec_conf = Conv2D(self.n_boxes[1]*self.num_classes, (3, 3), strides=(1, 1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="fc_7_dtec_conf")(fc_7)
conv6_2_dtec_conf = Conv2D(self.n_boxes[2]*self.num_classes, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv6_2_dtec_conf")(conv6_2)
conv7_2_dtec_conf = Conv2D(self.n_boxes[3]*self.num_classes, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv7_2_dtec_conf")(conv7_2)
conv8_2_dtec_conf = Conv2D(self.n_boxes[4]*self.num_classes, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv8_2_dtec_conf")(conv8_2)
conv9_2_dtec_conf = Conv2D(self.n_boxes[5]*self.num_classes, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv9_2_dtec_conf")(conv9_2)
# Loc detection block
conv4_3_norm_dtec_loc = Conv2D(self.n_boxes[0]*4, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv4_3_norm_dtec_loc")(conv4_3_norm)
fc_7_dtec_loc = Conv2D(self.n_boxes[1]*4, (3, 3), strides=(1, 1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="fc_7_dtec_loc")(fc_7)
conv6_2_dtec_loc = Conv2D(self.n_boxes[2]*4, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv6_2_dtec_loc")(conv6_2)
conv7_2_dtec_loc = Conv2D(self.n_boxes[3]*4, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv7_2_dtec_loc")(conv7_2)
conv8_2_dtec_loc = Conv2D(self.n_boxes[4]*4, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv8_2_dtec_loc")(conv8_2)
conv9_2_dtec_loc = Conv2D(self.n_boxes[5]*4, (3, 3), strides=(1,1), activation="relu", padding="same", kernel_initializer="he_normal", kernel_regularizer=l2(reg), name="conv9_2_dtec_loc")(conv9_2)
Ok cùng phân tích code bên trên 1 chút, nhìn qua có thể hiểu các tham số của conv này như kernel_size, strides, kernel_regularizer, ... nên mình sẽ bỏ qua, có thể chúng ta sẽ thắc mắc 1 chút ở đoạn số lượng filters đầu ra chỗ self.n_boxes[i] * self.num_classes và self.n_boxes[i] * 4. Cùng tìm hiểu ở phần tiếp theo ngay sau đây nhé.
3. Default boxes and aspect ratio
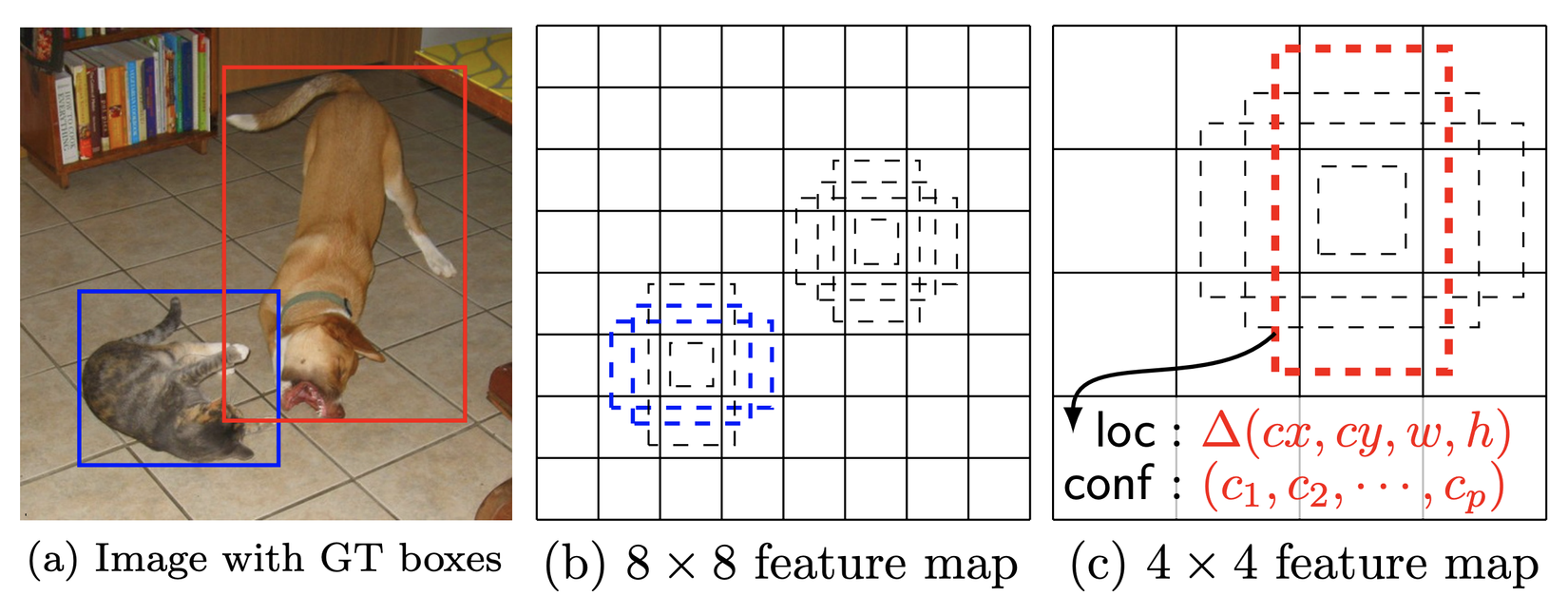
Hình : Mô tả các default boxes ở các tỉ lệ scale và aspect ratio khác nhau (copy từ official paper)
Default boxes là gì:
Ý tưởng default boxes của SSD tương tự với khái niệm Anchor Boxes trong Faster RCNN, chỉ có điều ở đây nó được apply ở multi-scale layers. Default boxes là các boxes cố định được implicitly tạo ra tại từng điểm trong 1 feature map (m x n), có width, height, và có tỉ lệ aspect ratio giữa w, h khác nhau. Số lượng default boxes tại từng điểm trong feature maps sẽ tương ứng với số lượng các phần tử aspect ratio được sử dụng cho mỗi layer backbone. Default aspect ratio cho 6 layers sẽ là:
ASPECT_RATIO_PER_LAYER=[
[1.0, 2.0, 0.5], #3
[1.0, 2.0, 0.5], #3
[1.0, 2.0, 0.5, 3.0, 1.0/3.0], #6
[1.0, 2.0, 0.5, 3.0, 1.0/3.0], #6
[1.0, 2.0, 0.5, 3.0, 1.0/3.0], #6
[1.0, 2.0, 0.5], #3
]
Lý do cho sự xuất hiện của các tỉ lệ aspect ratio là vì object sẽ có nhiều hình dạng, tròn, vuông, chữ nhật, elip, ... => việc tạo ra các default boxes sao cho fit với hình dạng của các object sẽ thu được các bounding boxes sau khi training có độ chính xác cao hơn. (bounding boxes đã giải thích phía trên)
Tại sao cần default boxes:
Tại mỗi cell trong feature map, với sự xuất hiện của các default boxes này, chúng ta có thể tính toán ra sự sai khác của các predicted locations của object từ các conv_dtec_loc so với các default boxes, và confidence score per-class từ conv_dtec_conf biểu thị sự xuất hiện của 1 class tại mỗi default box đó. Tổng kết lại, giả sử tại ta có k feature maps (mxn) chúng ta sẽ có: (c+4)kmn giá trị predictions.
Cách tính (w, h) cho các default boxes:
(w, h) của các default boxes sẽ phụ thuộc vào giá trị aspect ratio và giá trị scale tại mỗi scale feature map nhất định. Scale=[0.2, 0.9], trong đó 0.2 tương ứng với layer thấp nhấp, và 0.9 tương ứng với layers cao nhất. Với các layers khác, công thức tính giá trị scale như sau:
Với numpy: cách tính như sau:
scales = np.linsplace(s_min, smax, n_backbone_layers+1)
Ta tính các (w, h) của các default boxes này theo code như sau:
size = min(self.img_height, self.img_width)
boxes_list = []
for ar in self.aspect_ratio:
if ar == 1:
w_box = h_box = size * self.this_scale
boxes_list.append([w_box, h_box])
if self.two_boxes_per_1:
w_box = h_box = size * math.sqrt(self.this_scale*self.next_scale)
boxes_list.append([w_box, h_box])
else:
w_box = size * self.this_scale * math.sqrt(ar)
h_box = size * self.this_scale / math.sqrt(ar)
boxes_list.append([w_box, h_box])
boxes_list = np.array(boxes_list)
Phần code hàm này khá dễ hiểu nên mình sẽ bỏ qua luôn nhé. Ok đến đây chúng ta hiểu tạo ra các list default boxes như thế nào rồi, bây giờ nhiệm vụ là làm thế nào để liên kết nó với layers.
Tạo ra các AnchorBox Layer như thế nào:
Có thể nói đây là phần khá quan trọng trong mô hình SSD, ở đây mình sẽ implement với keras, và việc tạo ra 1 AnchorBox Layer, tương ứng với việc chúng ta phải đi custom, kế thừa từ base layer. Chúng ta sẽ build AnchorBox dựa vào các layers conv_dtec_loc vì các layers này chứa thông tin về vị trí các object.
def call(self, x, mask=None):
size = min(self.img_height, self.img_width)
boxes_list = []
for ar in self.aspect_ratio:
if ar == 1:
w_box = h_box = size * self.this_scale
boxes_list.append([w_box, h_box])
if self.two_boxes_per_1:
w_box = h_box = size * math.sqrt(self.this_scale*self.next_scale)
boxes_list.append([w_box, h_box])
else:
w_box = size * self.this_scale * math.sqrt(ar)
h_box = size * self.this_scale / math.sqrt(ar)
boxes_list.append([w_box, h_box])
boxes_list = np.array(boxes_list)
if K.image_data_format() == "channels_last":
batch_size, feature_height, feature_width, feature_channels = x._keras_shape
else:
batch_size, feature_channels, feature_height, feature_width = x._keras_shape
if self.this_steps is None:
height_step = self.img_height / feature_height
width_step = self.img_width / feature_width
else:
if isinstance(self.this_steps, (list, tuple)) and len(self.this_steps) == 2:
height_step = self.this_steps[0]
width_step = self.this_steps[1]
if isinstance(self.this_steps, (int, float)):
height_step = width_step = self.this_steps
if self.this_offsets is None:
height_offset = width_offset = 0.5
else:
if isinstance(self.this_offsets, (list, tuple)) and len(self.this_offsets) == 2:
height_offset = self.this_offsets[0]
width_offset = self.this_offsets[1]
if isinstance(self.this_offsets, (int, float)):
height_offset = width_offset = self.this_offsets
cx = np.linspace(width_step*width_offset, (feature_width-1+width_offset)*width_step, feature_width)
cy = np.linspace(height_step*height_offset, (feature_height-1+height_offset)*height_step, feature_height)
cx_grid, cy_grid = np.meshgrid(cx, cy)
cx_grid = np.expand_dims(cx_grid, axis=-1)
cy_grid = np.expand_dims(cy_grid, axis=-1)
# Create box_tensors with shape (feature_height, feature_width, n_boxes, 4)
# 4 is for x, y, w, h
box_tensors = np.zeros((feature_height, feature_width, self.n_boxes, 4))
box_tensors[:,:,:,0] = np.tile(cx_grid, (1, 1, self.n_boxes))
box_tensors[:,:,:,1] = np.tile(cy_grid, (1, 1, self.n_boxes))
box_tensors[:,:,:,2] = boxes_list[:, 0]
box_tensors[:,:,:,3] = boxes_list[:, 1]
if self.coords == "centroids":
box_tensors = convert_coordinate(box_tensors, convention="center2corner")
if self.limit_boxes:
x_coords = box_tensors[:,:,:,[0,2]]
x_coords[x_coords > self.img_width] = self.img_width - 1
x_coords[x_coords < 0] = 0
box_tensors[:,:,:,[0,2]] = x_coords
y_coords = box_tensors[:,:,:,[1,3]]
y_coords[y_coords > self.img_height] = self.img_height - 1
y_coords[y_coords < 0] = 0
box_tensors[:,:,:,[1,3]] = y_coords
if self.normalize_coords:
box_tensors[:,:,:,[0,2]] = box_tensors[:,:,:,[0,2]] / self.img_width
box_tensors[:,:,:,[1,3]] = box_tensors[:,:,:,[1,3]] / self.img_height
if self.coords == "centroids":
box_tensors = convert_coordinate(box_tensors, convention="corner2center")
elif self.coords == "minmax":
box_tensors = convert_coordinate(box_tensors, convention="corner2minmax")
variance_tensors = np.zeros_like(box_tensors)
variance_tensors += self.variances
box_tensors = np.concatenate([box_tensors, variance_tensors], axis=-1)
box_tensors = np.expand_dims(box_tensors, axis=0)
box_tensors = K.tile(K.constant(box_tensors, dtype=float), (K.shape(x)[0], 1, 1, 1, 1))
return box_tensors
Ở đây mình chỉ lấy ra hàm call, tức phần chứa logic của Layer, các hàm khác trong một custom layer mình xin phép bỏ qua. Giờ mình sẽ đi giải thích chi tiết cái layer này nó làm gì:
- Ở phần đầu tiên của hàm, đó là phần tính toán ra list các giá trị (w, h) của default boxes.
- Tiếp theo chúng ta cần tính ra các width_steps, weight_steps chứa khoảng cách giữa các tâm của default boxes theo chiều ngang, dọc, giá trị mặc định sẽ = img_size / feature_size
- Tiếp theo là width_offsets, height_offsets tương ứng vị trí của tâm default_boxes so với cạnh trên, dưới, giá trị mặc định sẽ là 0,5.
- Tạo ra box_tensors có shape = (feature_height, feature_width, self.n_boxes, 4) và gán tương ứng các giá trị box gồm: vị trí center (x, y), w, h.
- Tạo ra 1 ma trận variance có shape tương tự như box_tensors, các giá trị variances này đóng vai trò như các factor divisors. Variances < 1 => upscale các encoded predicted boxes, downscale khi > 1 và giữ nguyên khi = 1. Default: [0.1, 0.1, 0.2, 0.2].
- Đầu ra của layers sẽ là tensors có shape: (None, feature_height, feature_width, self.n_boxes, 8), là concatenate theo axis=-1 của box_tensors và variance_tensors. (None biểu thị cho batch)
Một ví dụ về AnchorBox trong mô hình, ở đây là layer conv9_2:
conv9_2_dtec_bbox = AnchorBox(this_scale=self.scales[5], next_scale=self.scales[6],
aspect_ratio=self.aspect_ratio[5], coords=self.coords,
img_height=self.height, img_width=self.width,
variances=self.variances, limit_boxes=self.limit_boxes,
this_steps=self.steps[5], this_offsets=self.offsets[5],
normalize_coords=self.normalize_coords)(conv9_2_dtec_loc)
Đến đây chúng ta đã có 1 cái nhìn tổng quát về default_boxes (anchor boxes), vì nội dung bài viết khá dài nếu có bất kỳ thiếu sót, thắc mắc nào xin vui lòng comment xuống bên dưới giúp mình nhé.
Output của mô hình:
Để có thể tận dụng được detector ở các tỉ lệ scale khác nhau, chúng ta cần tổng hợp chúng vào cùng 1 tensors để tính loss, do đó ta cần reshape các layers về cùng 1 shape như sau:
- Với layers conf: (-1, self.n_classes)
- Với layers loc: (-1, 4)
- Với layer anchor: (-1, 8)
Sau đó concatenate các multi-scale layers của từng loại với nhau. Code được biểu diễn như sau:
# Reshape class layers
conv4_3_norm_conf_reshape = Reshape((-1, self.num_classes), name="conv4_3_norm_conf_reshape")(conv4_3_norm_dtec_conf)
fc_7_dtec_conf_reshape = Reshape((-1, self.num_classes), name="fc_7_dtec_conf_reshape")(fc_7_dtec_conf)
conv6_2_dtec_conf_reshape = Reshape((-1, self.num_classes), name="conv6_2_dtec_conf_reshape")(conv6_2_dtec_conf)
conv7_2_dtec_conf_reshape = Reshape((-1, self.num_classes), name="conv7_2_dtec_conf_reshape")(conv7_2_dtec_conf)
conv8_2_dtec_conf_reshape = Reshape((-1, self.num_classes), name="conv8_2_dtec_conf_reshape")(conv8_2_dtec_conf)
conv9_2_dtec_conf_reshape = Reshape((-1, self.num_classes), name="conv9_2_dtec_conf_reshape")(conv9_2_dtec_conf)
# Reshape loc layers
conv4_3_norm_dtec_loc_reshape = Reshape((-1, 4), name="conv4_3_norm_dtec_loc_reshape")(conv4_3_norm_dtec_loc)
fc_7_dtec_loc_reshape = Reshape((-1, 4), name="fc_7_dtec_loc_reshape")(fc_7_dtec_loc)
conv6_2_dtec_loc_reshape = Reshape((-1, 4), name="conv6_2_dtec_loc_reshape")(conv6_2_dtec_loc)
conv7_2_dtec_loc_reshape = Reshape((-1, 4), name="conv7_2_dtec_loc_reshape")(conv7_2_dtec_loc)
conv8_2_dtec_loc_reshape = Reshape((-1, 4), name="conv8_2_dtec_loc_reshape")(conv8_2_dtec_loc)
conv9_2_dtec_loc_reshape = Reshape((-1, 4), name="conv9_2_dtec_loc_reshape")(conv9_2_dtec_loc)
# Reshape anchorbox layers
conv4_3_norm_dtec_bbox_reshape = Reshape((-1, 8), name="conv4_3_norm_dtec_bbox_reshape")(conv4_3_norm_dtec_bbox)
fc_7_dtec_bbox_reshape = Reshape((-1, 8), name="fc_7_dtec_bbox_reshape")(fc_7_dtec_bbox)
conv6_2_dtec_bbox_reshape = Reshape((-1, 8), name="conv6_2_dtec_bbox_reshape")(conv6_2_dtec_bbox)
conv7_2_dtec_bbox_reshape = Reshape((-1, 8), name="conv7_2_dtec_bbox_reshape")(conv7_2_dtec_bbox)
conv8_2_dtec_bbox_reshape = Reshape((-1, 8), name="conv8_2_dtec_bbox_reshape")(conv8_2_dtec_bbox)
conv9_2_dtec_bbox_reshape = Reshape((-1, 8), name="conv9_2_dtec_bbox_reshape")(conv9_2_dtec_bbox)
# concatenate for conf layers
conf_concat = Concatenate(axis=1, name="conf_concat")([conv4_3_norm_conf_reshape,
fc_7_dtec_conf_reshape,
conv6_2_dtec_conf_reshape,
conv7_2_dtec_conf_reshape,
conv8_2_dtec_conf_reshape,
conv9_2_dtec_conf_reshape])
# concatenate for loc layers
loc_concat = Concatenate(axis=1, name="loc_concat")([conv4_3_norm_dtec_loc_reshape,
fc_7_dtec_loc_reshape,
conv6_2_dtec_loc_reshape,
conv7_2_dtec_loc_reshape,
conv8_2_dtec_loc_reshape,
conv9_2_dtec_loc_reshape])
# concatenate for bbox layers
bbox_concat = Concatenate(axis=1, name="bbox_concat")([conv4_3_norm_dtec_bbox_reshape,
fc_7_dtec_bbox_reshape,
conv6_2_dtec_bbox_reshape,
conv7_2_dtec_bbox_reshape,
conv8_2_dtec_bbox_reshape,
conv9_2_dtec_bbox_reshape])
Giờ ta thu được 3 tensors có các shape như sau: (None, feature_h * feature_w, n_classes) , (None, feature_h * feature_w, 4), (None, feature_h * feature_w, 8). Concat chúng lại để có được tensors cuối cùng:
# Softmax for conf layers
conf_softmax = Activation("softmax")(conf_concat)
# Prediction layers
predictors = Concatenate(axis=-1, name="predictors")([conf_softmax, loc_concat, bbox_concat])
model = Model(inputs=inputs, outputs=predictors)
Chúng ta đã có model rồi. Tiếp theo, ta sẽ đi đến phần training.
4. Trainning
Để train được SSD, chúng ta cần có 1 bước assign các ground_truth boxes với các outputs cụ thể trong tập set các layers detectors. Hiểu đơn giản là để loss function và back propagation có thể hoạt động và apply end-to-end thì phải có bước encode các giá trị lại các gt boxes này khớp với tensors đầu ra của mô hình. Do vậy, chúng ta cần tạo ra 1 label template tương ứng, rồi sau đó matching các default boxes và các ground_truth boxes với nhau. Điều kiện để match giữa default boxes và gt_boxes chúng ta cùng tìm hiểu về khái niệm IOU (Intersection over Union). Cùng xem ảnh dưới đây:
 Hình : IOU
Hình : IOU
IOU được tính toán dựa theo tỉ lệ giữa và của 2 tập bất kì. Nếu giá trị IOU của gt-box và default-box vượt qua 1 ngưỡng threshold thì nó được coi là match với nhau. Default là 0.5, giá trị này có thể thay đổi phụ thuộc vào từng bài đoán, dataset, 0.6, 04...etc. Code tham khảo như sau:
def iou(boxes1, boxes2, coords="centroids"):
"""
minmax: (xmin, xmax, ymin, ymax)
centroids: (x_c, y_c, w, h)
corners: (xmin, ymin, xmax, ymax)
"""
if coords in {'minmax', 'centroids'}:
intersection = np.maximum(0, np.minimum(boxes1[:,1], boxes2[:,1]) - np.maximum(boxes1[:,0], boxes2[:,0])) * np.maximum(0, np.minimum(boxes1[:,3], boxes2[:,3]) - np.maximum(boxes1[:,2], boxes2[:,2]))
union = (boxes1[:,1] - boxes1[:,0]) * (boxes1[:,3] - boxes1[:,2]) + (boxes2[:,1] - boxes2[:,0]) * (boxes2[:,3] - boxes2[:,2]) - intersection
elif coords == 'corners':
intersection = np.maximum(0, np.minimum(boxes1[:,2], boxes2[:,2]) - np.maximum(boxes1[:,0], boxes2[:,0])) * np.maximum(0, np.minimum(boxes1[:,3], boxes2[:,3]) - np.maximum(boxes1[:,1], boxes2[:,1]))
union = (boxes1[:,2] - boxes1[:,0]) * (boxes1[:,3] - boxes1[:,1]) + (boxes2[:,2] - boxes2[:,0]) * (boxes2[:,3] - boxes2[:,1]) - intersection
return intersection / union
ok giờ có điều kiện match rồi, ta tạo ra 1 template cho label. Điều kiện đầu tiên là shape của template label phải giống với shape của model output. Cũng tương tự như lúc chúng ta build model, ta sẽ gen ra template cho anchorbox trước, sau đó rồi sẽ đến conf tensors, loc tensors và variance tensors. Bước gen ra anchor tensors template khá tương tự như trong model, sự khác biệt ở đây là ta tách variance tensors ra ở bước sau:
def generate_anchor_boxes_template(self,
predictor_size=None,
this_scale=None,
aspect_ratio=None,
next_scale=None,
offset=None,
step=None,
coords="centroids",
normalize_coords=False,
limit_box=True,
diagnose=False,
two_boxes_per_1=True,
variances=None):
img_size = min(self.img_width, self.img_height)
boxes_list = []
n_box = len(aspect_ratio)+1 if 1 in aspect_ratio else len(aspect_ratio)
for ar in aspect_ratio:
if ar == 1:
w_box = img_size * this_scale
h_box = img_size * this_scale
boxes_list.append((w_box, h_box))
if two_boxes_per_1:
w_box = img_size * math.sqrt(this_scale*next_scale)
h_box = img_size * math.sqrt(this_scale*next_scale)
boxes_list.append((w_box, h_box))
else:
w_box = img_size * this_scale * math.sqrt(ar)
h_box = (img_size * this_scale) / math.sqrt(ar)
boxes_list.append((w_box, h_box))
boxes_list = np.array(boxes_list)
feature_h, feature_w = predictor_size
if step is None:
step_w = self.img_width / feature_w
step_h = self.img_height / feature_h
else:
if isinstance(step, (list, tuple)):
step_h = step[0]
step_w = step[1]
if isinstance(step, (int, float)):
step_w = step
step_h = step
if offset is None:
offset_w = offset_h = 0.5
else:
if isinstance(offset, (list, tuple)):
offset_w = offset[0]
offset_h = offset[1]
if isinstance(offset, (int, float)):
offset_w = offset
offset_h = offset
cx = np.linspace(step_w*offset_w, (feature_w-1+offset_w)*step_w, feature_w)
cy = np.linspace(step_h*offset_h, (feature_h-1+offset_h)*step_h, feature_h)
cx, cy = np.meshgrid(cx, cy)
cx = np.expand_dims(cx, axis=-1)
cy = np.expand_dims(cy, axis=-1)
box_tensors = np.zeros((feature_h, feature_w, n_box, 4))
box_tensors[:,:,:,0] = np.tile(cx, (1,1,n_box))
box_tensors[:,:,:,1] = np.tile(cy, (1,1,n_box))
box_tensors[:,:,:,2] = boxes_list[:, 0]
box_tensors[:,:,:,3] = boxes_list[:, 1]
box_tensors = convert_coordinate(box_tensors, convention="center2corner")
if limit_box:
x_coords = box_tensors[...,[0,2]]
y_coords = box_tensors[...,[1,3]]
x_coords[x_coords > self.img_width] = self.img_width - 1
x_coords[x_coords < 0] = 0
y_coords[y_coords > self.img_height] = self.img_height - 1
y_coords[y_coords < 0] = 0
box_tensors[...,[0,2]] = x_coords
box_tensors[...,[1,3]] = y_coords
if normalize_coords:
box_tensors[:,:,:,[0,2]] = box_tensors[:,:,:,[0,2]] / self.img_width
box_tensors[:,:,:,[1,3]] = box_tensors[:,:,:,[1,3]] / self.img_height
if coords == "centroids":
box_tensors = convert_coordinate(box_tensors, convention="corner2center")
if coords == "minmax":
box_tensors = convert_coordinate(box_tensors, convention="corner2minmax")
return box_tensors
Tổng hợp tất cả các loại template layers vào, ta có label template như sau:
def generate_label_template(self):
batch_boxes = []
for box in self.boxes:
box = np.expand_dims(box, axis=0)
box = np.tile(box, (self.batch_size, 1, 1, 1, 1))
box = np.reshape(box, (self.batch_size, -1, 4))
batch_boxes.append(box)
batch_boxes = np.concatenate(batch_boxes, axis=1)
batch_classes = np.zeros((self.batch_size, batch_boxes.shape[1], len(self.classes)))
batch_variances = np.zeros_like(batch_boxes)
batch_variances += self.variances
template_label = np.concatenate([batch_classes, batch_boxes, batch_boxes, batch_variances], axis=-1)
return template_label
Ok ngon rồi, có template rồi, giờ là lúc match các ground truth boxes và default boxes với nhau để train. Ta có code như sau:
def encode_y(self, groud_truth_boxes):
batch_labels = self.generate_label_template()
y_encoded = np.copy(batch_labels)
n_classes = len(self.classes)
encoded_class = np.eye(n_classes)
for i in range(len(batch_labels)):
label = batch_labels[i]
available_boxes = np.ones(batch_labels.shape[1])
negative_boxes = np.ones(batch_labels.shape[1])
for gt in groud_truth_boxes[i]:
gt = gt.astype("float")
if abs(gt[3] - gt[1] < 1e-3) or abs(gt[4] - gt[2] < 1e-3): continue
if self.normalize_coords:
gt[[1,3]] = gt[[1,3]] / self.img_width
gt[[2,4]] = gt[[2,4]] / self.img_height
if self.coords == "centroids":
gt = convert_coordinate(gt, start_index=1 ,convention="corner2center")
if self.coords == "minmax":
gt = convert_coordinate(gt, start_index=1, convention="corner2minmax")
similarities = iou(gt[1:5], label[:, -12:-8], coords="centroids")
negative_boxes[similarities > self.neg_iou_threshold] = 0
similarities *= available_boxes
iou_match_thresh = np.copy(similarities)
iou_match_thresh[iou_match_thresh < self.pos_iou_threshold] = 0
assign_indices = np.nonzero(iou_match_thresh)[0]
if len(assign_indices):
y_encoded[i, assign_indices, :-8] = np.concatenate([encoded_class[int(gt[0])], gt[1:5]], axis=0)
available_boxes[assign_indices] = 0
else:
best_matched = np.argmax(similarities)
y_encoded[i, best_matched, :-8] = np.concatenate([encoded_class[int(gt[0])], gt[1:5]], axis=0)
available_boxes[best_matched] = 0
negative_boxes[best_matched] = 0
bg_indices = np.nonzero(negative_boxes)[0]
y_encoded[i, bg_indices, 0] = 1
if self.coords == "centroids":
y_encoded[:, :, [-12, -11]] -= batch_labels[:, :, [-12, -11]]
y_encoded[:, :, [-12, -11]] /= batch_labels[:, :, [-10, -9]] * batch_labels[:, :, [-4, -3]]
y_encoded[:, :, [-10, -9]] /= batch_labels[:, :, [-10, -9]]
y_encoded[:, :, [-10, -9]] = np.log(y_encoded[:,:,[-10,-9]]) / batch_labels[:, :, [-2,-1]]
return y_encoded
Trước tiên ta cần chú ý đến 2 giá trị pos_iou_threshold và neg_iou_threshold, với pos_iou_threshold được coi là threshold min của IOU giữa gt-box và default-box nhằm mục đích quyết định 2 box này có match nhau hay không, còn neg_iou_threshold được coi là giá trị threshold max của IOU giữa gt_box và default_box để quyết định xem box này có là negative hay không. Những box không là negative, cũng không là positive sẽ bị ignore trong quá trình training.
Âu kay, au kây. Ngon rồi, giờ chúng ta sẽ quan tâm đến hàm Loss. Nhưng trước tiên chúng ta cần quan tâm đến Hard negative mining đã.
Hard negative mining
Sau quá trình matching step phía trên, chúng ta nhận thấy rằng là hầu hết các default boxes sẽ bị coi là negative box, trong khi số lượng default box là rất lớn. Điều này gây ra 1 vấn đề rất lớn là có 1 sự mất cân bằng đáng kể giữa positive và negative example.
Để giải quyết điều này, thay vì dùng toàn bộ số negative boxes này. Chúng ta sẽ sắp xếp chúng dựa vào confidence loss cho từng default box và picks ra những box tốt nhất thoả mãn điều kiện negative và positive xấp xỉ tỉ lệ 1:3. Thực nghiệm đã chứng minh rằng, Hard negative mining giúp ổn định quá trình training và optimization nhanh hơn.
Loss Function
Giá trị loss của SSD được tính toán dựa trên 2 hàm loss: Confidence Loss và Localization Loss
Trong đó, N là số lượng các default boxes matchs với gt_boxes, : predicted boxes, : ground_truth boxes. Confidence Loss và hàm softmax cho multi class, còn Localization Loss được tính như sau (theo paper):
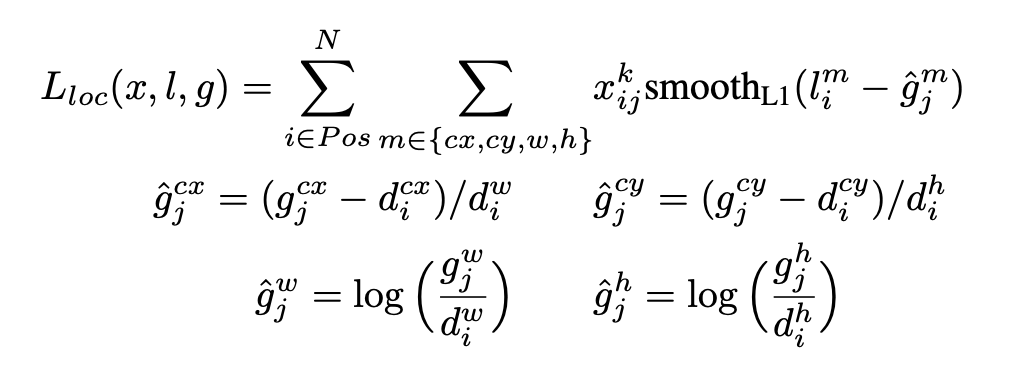
Hình: Loc Loss (copy từ official paper)
Phần code cho confidence loss như sau:
def log_loss(self, y_true, y_pred):
#Compute loss for class prediction
y_pred = tf.maximum(y_pred, 1e-15)
log_loss = -tf.reduce_sum(y_true * tf.log(y_pred), axis=-1)
và SmoothL1 Loss như sau:
def smooth_l1_loss(self, y_true, y_pred):
#Compute loss for location prediction
absolute_loss = abs(y_true - y_pred)
square_loss = 0.5*(y_true - y_pred)**2
l1_loss = tf.where(tf.less(absolute_loss, 1.0), square_loss, absolute_loss - 0.5)
PS: Trên đây chỉ là code minh họa cho 2 function chính của hàm loss, và để có được hàm loss cuối cùng ta cần xử lý thêm 1 số logic nữa.
Để ý kĩ ta có thể thấy, công thức này giải thích cho phần cuối cùng của công thức encodey phía trên.
Đến đây chúng ta đã hiểu tư tưởng tổng quan của hàm loss. Nếu có bất cứ điều gì thắc mắc, mọi người có thể comment phía dưới cho mình.
Prediction step
Ok tại thời điểm này sau khi model đã được training sau một số epoch nhất định, nó sẽ có khả năng predict ra những proposed bounding boxes cho những vật thể trong ảnh. Nếu model là đủ tốt, với mỗi vật thể, nó sẽ nhận được nhiều hơn 1 các potential bboxes, các giá trị về location của bounding boxes này cũng đã được encode. Vì vậy ta cần một bước nữa gọi là bước decode, tại đây ta có 2 việc chính cần làm, 1 là sử dụng thuật Non-maximum suppression, ý tưởng chính của thuật toán này tương tự với thuật toán tham lam, nhiệm vụ của nó là tìm ra cái bounding box tốt nhất của vật thể so với ground_truth box. Và thứ 2 là đưa các giá trị encoded location về cùng khoảng giá trị với các giá trị ban đầu của ảnh.
 Ảnh minh họa cho Non-maximum suppression
Ảnh minh họa cho Non-maximum suppression
III. Using SSD for Face Detection
Ý tưởng chính về SSD chúng ta đã nắm được rồi, vậy ở phần này mình sẽ ứng dụng mô hình SSD vào bài toán Face Detection xem sao. Với bài toán này, mình có thay đổi 1 chút so với tác giả, thay vì sử dụng VGG-16 làm backbone model thì mình sử dụng kiến trúc mô hình MobileNet, lý do là bởi vì mình muốn mô hình predict nhanh hơn ở khâu detect face do một bài toán Face Recognition thường có rất nhiều bước, nên mình muốn tối ưu từng phần, và Face Detection là một trong số đó.
Mình đã train mô hình này như thế nào:
Tất cả những gì cần biết về mô hình SSD mình đã nêu phía trên, điều mình cần làm thêm đó là chuẩn bị dữ liệu, tiền xử lý dữ liệu, và viết một class DataGenerator nữa rồi ném vào train với 150 epochs. Mình xin phép không đi chi tiết vào các phần này nữa vì phạm vi bài này mình chỉ muốn nói về SSD. Mình sẽ viết chi tiết hơn về Face Detection với SSD nếu nhận được sự quan tâm.
Dưới đây là một vài kết quả mình thu được:


Cảm ơn mọi người đã đọc bài
IV. References
https://arxiv.org/pdf/1512.02325.pdf
https://arxiv.org/pdf/1506.01497.pdf
https://github.com/pierluigiferrari/ssd_keras
https://www.coursera.org/lecture/convolutional-neural-networks/anchor-boxes-yNwO0
https://www.coursera.org/lecture/convolutional-neural-networks/intersection-over-union-p9gxz
All rights reserved
