
Tổng quan về Face Anti-Spoofing - Bài toán chống giả mạo khuôn mặt
Bài đăng này đã không được cập nhật trong 4 năm
Mình hi vọng bài viết này có thể cung cấp một cái nhìn toàn cảnh về bài toán Face Anti-spoofing.
Các phần mình sẽ giới thiệu lần lượt là:
- Giới thiệu tổng quan
- Các cách tấn công giả mạo - Attack methods
- Các phương pháp chống giả mạo - Anti-spoofing methods
- Cách đánh giá mô hình - Evaluate metrics
- Bốn loại giao thức đánh giá - Evaluation Protocols
- Tổng quan về Deep Learning based methods.
Let's go !!! 
1. Giới thiệu bài toán Face Anti-Spoofing
Những năm gần đây, hẳn bạn sẽ thấy sự xuất hiện ngày càng nhiều của bài toán nhận diện và xác thực khuôn mặt.
Ví dụ tiêu biểu nhất có thể kể đến các smartphone sử dụng khuôn mặt bạn để làm khóa mở điện thoại. Hoặc một số ngân hàng yêu cầu xác thực khuôn mặt khi đăng ký tài khoản online. Một số nước, như trung quốc, đã sử dụng quét khuôn mặt để thanh toán tiền.
Nói cách khác, việc xác thực người đứng trước màn hình có đúng là người chính chủ không, là một bài toán quan trọng.
Tuy nhiên, việc này có thể bị trick dễ dàng bằng cách in một cái ảnh của người đó ra và đưa ra trước màn hình, hoặc hơn nữa là quay một video cần mặt người đó rồi đưa ra trước màn hình, là dễ dàng qua mặt được hệ thống nhận diện khuôn mặt.
Bởi vì lẽ đó, sự cần thiết của bài toán Face Anti-spoofing ra đời.
(một bức ảnh vui vui lượm được từ google =))))

Hãy lưu ý rằng, bản thân thứ mà hệ thống nhận được, là các frame của video. Cách máy tính nhìn không giống với cách chúng ta nhìn.
Vậy, làm cách nào để phân biệt đâu là người thật đang đứng trước màn hình, hay chỉ là một ảnh? Vì lý do đó, bài toàn Face Anti Spoofing (FAS) - Bài toán chống giả mạo khuôn mặt ra đời.
Hình dưới đây cho thấy vị trí cả task face anti-spoofing trong toàn bộ hệ thống nhận diện khuôn mặt.
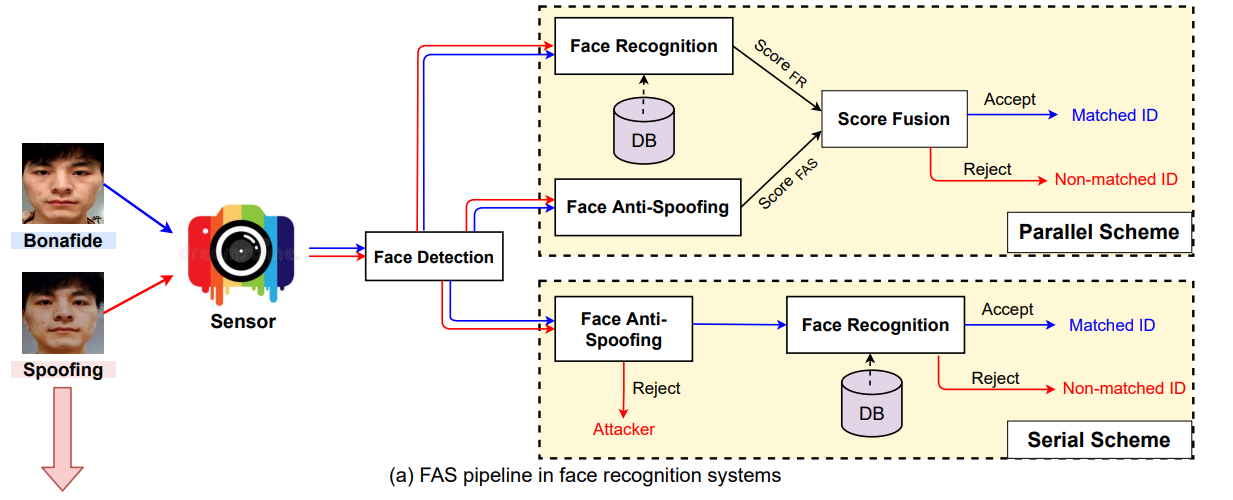
2. Một số phương pháp tấn công giả mạo
Có khá nhiều phương pháp để lừa một cái máy tính. Có thể phân ra thành, tấn công 2D và tấn công 3D.
-
2D attacks: một cái ảnh, một tấm hình in, một video chứa mặt người đó, những ảnh được thay liên tiếp để tạo sự chuyển động giả...
Trong đó, replay attack là kiểu tấn công sử dụng màn hình laptop, điện thoại, monitor in hình mặt người để giả mạo. Print attack là kiểu tấn công sử dụng giấy, bìa in mặt người tỉ lệ 1:1 để tấn công. Nếu bẻ công tờ giấy (hoặc có thể cắt phần mắt để chống detect nháy mắt), ta có một kiểu tấn công hơi hướng 3D.
-
3D attacks: đeo mặt nạ giả, hình in 3D, tượng mặt người, makeup hoặc thậm chí là một con robot có khuôn mặt được điều chỉnh mô phỏng khuôn mặt ai đó (hơi ảo một chút nhỉ, nhưng khó mà biết tội phạm có thể làm ra đến mức nào)
Trên thực tế, 2D diễn ra thường xuyên hơn, và chúng ta cũng sẽ tập trung xử lý những case phổ biến hơn. Vì vậy, các phương pháp mình đề cập trong bài này chủ yếu tập trung vào chống giả mạo cho 2D attacks.
3. Các phương pháp Face Anti-spoofing
Mình xin phép liệt kê ra năm phương pháp phổ biến.
3.1 Local binary pattern
Nếu chúng ta còn nhớ thời kỳ đầu của computer vision, khi CNN chưa phát triển lắm, người ta đã dùng một số phương pháp lấy đặc trưng ảnh như bộ mô tả hình ảnh (image descriptors - như HOG, Haralick, Zernike, etc.), phát hiện keypoints (keypoint detectors - FAST, DoG, GFTT, etc.), và bộ mô tả bất biến cục bộ (local invariant descriptors - SIFT, SURF, RootSIFT, etc.).
Ở đây, Local Binary Pattern (LBPs) tính toán biểu diễn cục bộ (Local representation). Local representation này được xây dựng bằng cách so sánh từng pixel với các pixel lân cận xung quanh của nó.
Bước đầu tiên trong việc xây dựng LBP là chuyển đổi hình ảnh sang thang độ xám(gray scale). Đối với mỗi pixel trong hình ảnh thang độ xám, ta chọn một vùng lân cận có kích thước bao quanh pixel trung tâm. Giá trị LBP sau đó được tính cho pixel trung tâm này và được lưu trữ trong mảng 2D đầu ra có cùng chiều rộng và chiều cao với hình ảnh đầu vào.
Ví dụ: LBP có thể hoạt động trên vùng lân cận pixel 3 x 3 cố định như sau:
pixel trung tâm được lấy làm ngưỡng cho giá trị 8 pixel xung quanh.
như sau:
pixel trung tâm được lấy làm ngưỡng cho giá trị 8 pixel xung quanh.
Vậy tính giá trị ở pixel trung tâm như thế nào? Các tính được thể hiện rõ trong hình dưới đây.
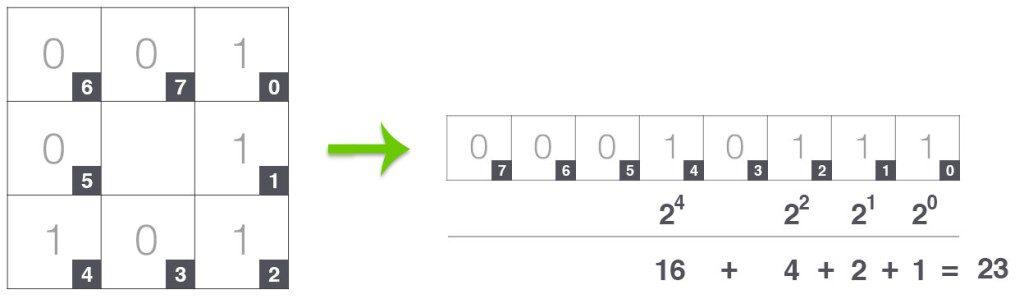
Cứ như vậy, chúng ta sẽ tính quy đổi được tất cả các giá trị pixel trong ảnh. Ta sẽ có một vector đặc trung của ảnh và có thể dùng SVM để phân loại.
 Tuy nhiên, đây là một phương pháp khá cũ rồi (nó được giới thiệu năm 2002 và ý tưởng thì từ 1993). Lợi ích duy nhất của nó là thời gian triển khai nhanh. Nhưng độ chính xác thấp, khả năng bị ảnh hưởng bởi nhiễu cao. Và nó không còn phù hợp nữa.
Tuy nhiên, đây là một phương pháp khá cũ rồi (nó được giới thiệu năm 2002 và ý tưởng thì từ 1993). Lợi ích duy nhất của nó là thời gian triển khai nhanh. Nhưng độ chính xác thấp, khả năng bị ảnh hưởng bởi nhiễu cao. Và nó không còn phù hợp nữa.
3.2 Eye Blink Detection
Detect nháy mắt.
Trung bình, con người nháy mắt từ 15 đến 30 lần trong một phút. Mỗi nháy mắt của con người, tức khoảng thời gian mí mắt sụp xuống, có thể chỉ diễn ra trong vài tích tắc (tầm 250 mm giây). Trong lúc đó, tốc độ camera bắt khung hình có thể lên tới 30fps (30 frame per second), tức mỗi frame chỉ mất tầm 50 mili giây. Có nghĩa là, ta hoàn toàn có thể bắt được khoảng khắc mí mắt sụp xuống. Nếu đủ điều kiện, phương pháp này có độ chính xác rất cao.
Tuy nhiên, nhược điểm của phương pháp này là gì?
Thứ nhất, phương pháp này chỉ phù hợp nếu đầu vào là một video. Nếu đầu vào là một ảnh tĩnh, phương pháp này không thể thực hiện được. Thứ hai, phương pháp này cần đến sự tham gia của người dùng. Nếu người dùng đứng quá xa, quá trình detect mắt trở nên khó khăn và detect nháy mắt càng khó. Đồng thời, nếu người dùng cố tình không chớp mắt, hoặc ảnh hưởng của một số điều kiện sức khỏe, khó chớp mắt, phương pháp này cũng không thể áp dụng.
Hoặc đơn giản là đeo kính râm, cắt bỏ phần ảnh mắt, thì phương pháp này fail =)).
3.3 Deep Learning Features: Convolutional Neural Network
Đúng vậy, sự ra đời của Convolutional Neural Network đã thống trị mảng computer vision suốt nhiều năm qua. Dù thời điểm này có thêm nhiều nghiên cứu mới đột phá, CNN vẫn luôn đóng vai trò cực kỳ quan trọng.
Về cơ bản, có thể coi bài toán Face Anti-Spoofing như một bài toán classification với hai nhãn. Dùng một mạng CNN để trích xuất đặc trưng rồi đưa ra output.
Tuy nhiên, làm sao để xây dựng một mạng CNN đủ tốt.
Có thể bạn chưa biết, nhưng 2 bức ảnh dưới đều là ảnh giả mạo.

Một bên là ảnh print, và một bên có lẽ là ảnh qua màn hình điện thoại. Với bức ảnh bên trái, mắt thường cũng khó phân biệt được.
Làm sao để đào tạo một model dêp learning đủ tốt để classify, đây là một hướng đi được rất nhiều paper nghiên cứu, mình sẽ đề cập rõ hơn ở phần bốn, bao gồm cả ưu nhược điển của nó.
3.4 Active Flash

Sử dụng đèn flash có sẵn của thiết bị, sau đó huấn luyện mô hình để nhận ra sự thay đổi trước và sau khi bật đèn flash, đó là ý tưởng của phương pháp này. Mình không có nhiều kinh nghiệm đối với phương pháp này, tuy nhiên một số báo cáo cho rằng đây là phương pháp có nhiều hứa hẹn. Nhìn chung, bài toán face anti-spoofing vẫn là bài toán còn nhiều vấn đề chưa được khai phá.
3.5 Challenge-response
Một số ứng dụng xác thực danh tính yêu cầu người dùng thực hiện một số thao tác không đoán trước (thường random) để xác minh trước màn hình có phải người sống thực sự hay không. Một số yêu cầu như là:
- Nghiêng đầu trái phải, di chuyển đầu lúc lắc
- Mỉm cười
- Biểu cảm vui buồn
Về cơ bản, cách này khá hiệu quả để xác thực vật thể sống. Nhưng điểm phiền toái nhất chính là trải nghiệm khách hàng. Thực sự rất phiền nếu cái máy chấm công ở cổng công ty bắt chúng ta làm đủ trò hề trước màn hình mới chấm công cho chúng ta phải không =)))))
3.6 3D camera
 Ý tưởng căn bản bắt đầu từ việc, khuôn mặt người thật là một khối 3D, nghĩa là nó có sự lồi lõm khác nhau, và khoảng cách từ camera tới vật thể có sự khác nhau giữa các điểm. Ta gọi nó là bản đồ độ sâu (depth map).
Ý tưởng căn bản bắt đầu từ việc, khuôn mặt người thật là một khối 3D, nghĩa là nó có sự lồi lõm khác nhau, và khoảng cách từ camera tới vật thể có sự khác nhau giữa các điểm. Ta gọi nó là bản đồ độ sâu (depth map).
Còn với giả mạo, là một màn hình phẳng.
Và camera 3D có thể thu được thông tin về độ sâu đó. Đây có thể coi là phương pháp hiệu quả nhất của bài toán face anti-spoofing.
Tuy nhiên, đưa 2 ảnh và bảo phân biệt đâu là ảnh giả mạo, trường hợp này 3D camera fail =))) Và vấn đề lớn nhất có lẽ là chi phí camera, cũng như một số ảnh hưởng môi trường.
Tạm kết
Và hình dưới đây tổng kết ưu nhược điểm của cả 6 phương pháp mà mình đã nêu trên. (màu xanh là phần pp đó có thể hold, màu đỏ là nhược điểm).
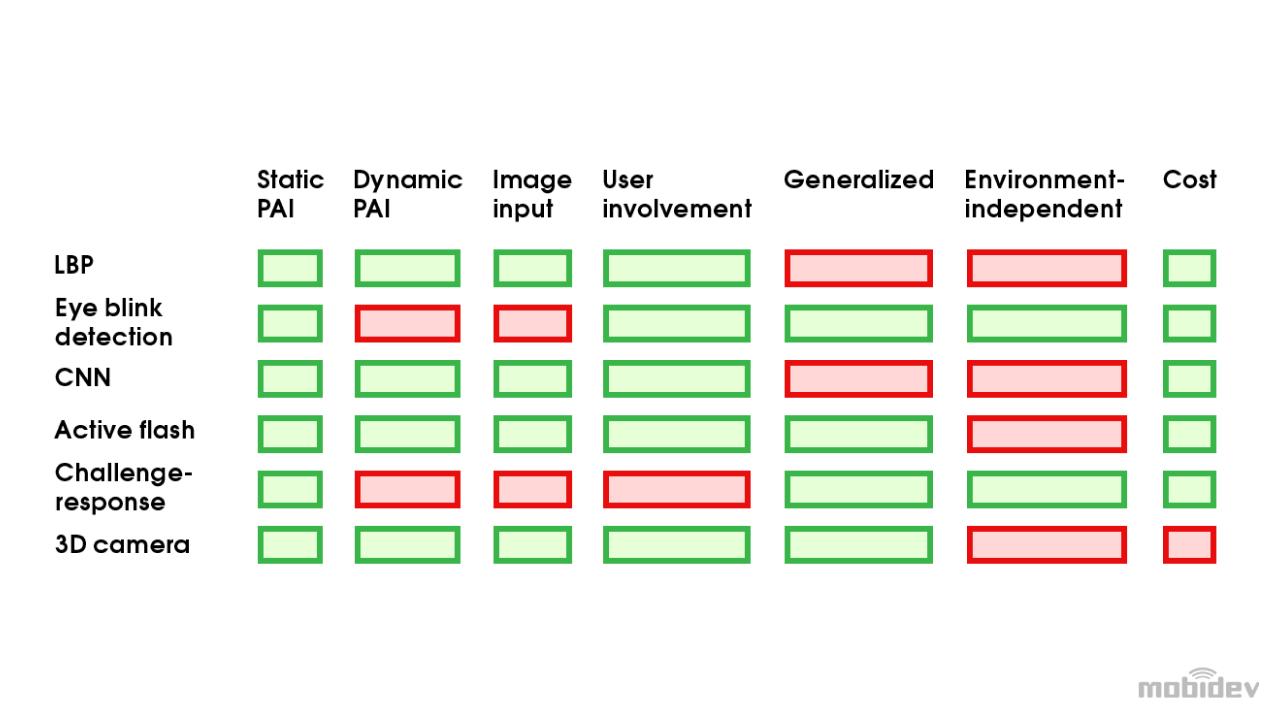
4. Evaluation Metrics
Về các phương pháp đánh giá mô hình, có thể kể đến được dùng phổ biến nhất là Tỉ lệ từ chối sai - False Rejection Rate (FRR) và Tỉ lệ chấp nhận sai - False Acceptance Rate (FAR). Hải chỉ số này thường được dùng trong xác minh sinh trắc học, nên cũng có thể dùng trong FAS.
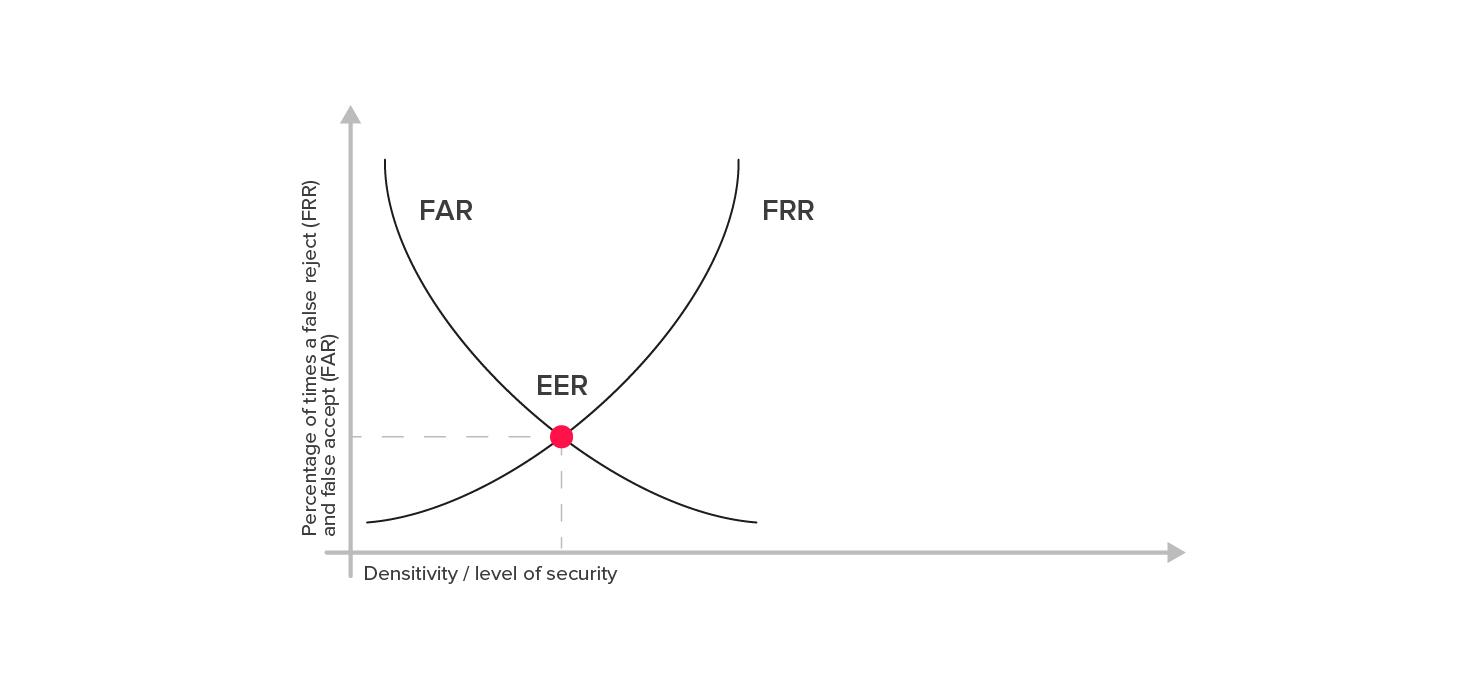
FRR: có bao nhiêu mẫu đúng bị từ chối. Ví dụ: nếu FRR là 0,2%, cứ 500 người dùng được ủy quyền sẽ có một người bị từ chối nhận dạng khi họ truy cập.
FAR: có bao nhiêu kể mạo danh vượt qua ngưỡng.
Lưu ý rằng, hai chỉ số này có tác động lẫn nhau.
Như vậy, nếu chúng ta ưu tiên người dùng, ta tập trung vào FAR, means nếu sai một chút vẫn có thể chấp nhận.
Ngược lại, nếu ta muốn loại bỏ mọi kẻ giả mạo nhiều nhất có thể, ta sẽ tập trung nâng cao chỉ số FRR.
Ngoài ra, khá nhiều paper sử dụng thêm các chỉ số đánh giá sau:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
- Attack Presentation Classification Error Rate (APCER ):
- Normal Presentation Classification Error Rate (NPCER ):
- Average Classification Error Rate (ACER):
5. Evaluation Protocols
Đến khi tìm hiểu về bài toán Face Anti-Spoofing mình mới gặp những khái niệm này, nên mình cũng muốn giới thiệu một chút.
Đối với các bài toán thông thường, hẳn bạn đã từng quen với việc chia dataset của chúng ta ra làm ba phần: train, validation và test. Trong đó, cả ba tập này đều có format tương tương nhau.
Vậy FAS có chia train, valid, test như thế không? Tại sao bài toán FAS lại cần đến nhiều giao thức đánh giá?
Như đã nêu trên, một trong những vấn đề của FAS là việc, có rất nhiều cách để tấn công giả mạo. Một số phương pháp phân biệt được tốt cách tấn công này, nhưng lại fail với cách tấn công khác. Thế nên, các nghiên cứu về FAS mới đưa thêm một số cách đánh giá chéo.
- Intra-Dataset Intra-Type Protocol: được sử dụng trong các tình huống chỉ có sự thay đổi nhỏ về domain. Ở đây, training data và testing data được lấy chung từ một bộ dữ liệu. (Fig.4 (a) in paper)
- Cross-Dataset Intra-Type Protocol: Giao thức này tập trung vào đo lường khả năng tổng quát hóa miền cấp độ tập dữ liệu chéo, thường huấn luyện các mô hình trên một hoặc một số tập dữ liệu (source domain) và sau đó kiểm tra trên các tập dữ liệu chưa nhìn thấy trước đó (thay đổi target domain). (Fig.4 (b) in paper)
- Intra-Dataset Cross-Type Protocol: ngược lại với giao thức phía trên, cách đánh giá này chỉ huấn luyện mô hình trên một tập data, sau đó đánh giá xem mô hình có mang tính tổng quát không bằng cách testing trên nhiều tập test ở nhiều domain khác nhau, chưa từng xuất hiện trong tập train. Được sử dụng nhiều nhất trong trường hợp này là dataset SiW-M, với hơn 13 loại tấn công khác nhau. (Fig.4 (c) in paper)
- Cross-Dataset Cross-Type Protocol: Sau ba loại đánh giá trên, mặc dù bắt được kha khá các vấn đề có thể xảy ra trong thực tế, nhưng có lẽ người ta vẫn thấy chưa đủ =))))) Ở giao thức này, chúng ta đo lường mô hình FAS tổng quát trên cả miền chưa từng nhìn thấy và các kiểu tấn công không xác định. Thường thì, hai datasets OULU-NPU và SiW được trộn lại để huấn luyện, trong khi HKBU-MARs và 3DMask được sử dụng trong testing. (Fig.4 (d) in paper)
6. Deep Learning for Face Anti-Spoofing
Phần viết này tham khảo từ paper:
- Deep Learning for Face Anti-Spoofing: A Survey (28 June 2021)
Về cơ bản, bài toán thật giả có thể được coi như là bài toán classification. Thậm chí, sử dụng các thuật toán ML như logistic regression hay SVM vẫn có thể giải quyết được bài toán ở một mức độ nào đó với kết quả không hề tệ.
Tiếp theo đây mình giới thiệu về các hướng tiếp cận sử dụng deep learning. Đây là hướng nghiên cứu được đào sâu nhất trong tất cả sáu hướng mình đã điểm qua ở phần ba, là hướng có nhiều paper nhất.
Về nhược điểm của việc sử dụng deep learning, có thể kể đến hai nhược điểm lớn:
-
Thứ nhất, là khả năng học tổng quát. Nếu chúng ta huấn luyện model deep learning cái gì, nó sẽ học mỗi thứ đó. Vấn đề là, có rất nhiều phương pháp tấn công giả mạo. Ta gọi đó là vấn đề domain. Hầu hết các mô hình giả quyết được domain này thì lại mắc lỗi với domain khác. Cân bằng nhiều domain thì lại giảm hiệu suất chung.
-
Thứ hai, là ảnh hưởng của môi trường. Lớn nhất có thể kể đến điều kiện ánh sáng thay đổi. Ảnh ở ánh sáng bình thường, ảnh bị chói sáng, ảnh bị ngược sáng, ảnh bị thiếu sáng.
![image.png]()
Làm sao để model của chúng ta có thể cân bằng hết những hạn chế đó. Trong các paper gần đây nhất, hai hướng tiếp cận chủ yếu là (1) xử lý vấn đề domain và (2) đề xuất các cải tiến model deep learning.

Hình ảnh dưới đây cho thấy gần như toàn bộ các hướng tiếp cận của phương pháp Deep Learning for Face Anti-Spoofing.
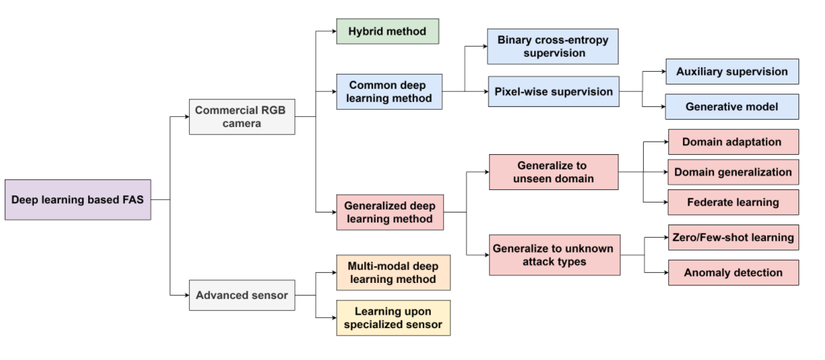
Trong đó, bạn có thể thấy:
- Commercial RGB camera: Hướng đầu tiên này nhận đầu vào là ảnh RGB. Điều này phổ biến hơn, vì mọi các camera thông thường hiện nay đều thu được ảnh RGB.
- Multiple modalities or specialized sensors: Hướng thứ hai là dữ liệu thu được từ một số loại sensor cammera đặc biệt, đơn cử như camera trích xuất độ sâu (Kinect, D435i), camera hồng ngoại, camera nhiệt, vân vân. Từ khóa Multiple modalities là để chỉ việc kết hợp nhiều dữ liệu đầu vào, ví dụ ta kết hợp cả ảnh RGB và ảnh depth thu được, với hi vọng cung cấp nhiều thông tin hữu ích hơn cho model của chúng ta.
6.1 Datasets
.
(Tất cả các link dưới đây là danh sách tổng hợp các paper cho đến năm 2021, đã được phân loại theo từng phương pháp)
6.2 Deep FAS methods with commercial RGB camera
1 Hyprid method
-
Phương pháp này kết hợp những ưu điểm của hand- crafted features (mục 3.1) và mô hình deep learning, bởi vậy nên nó mới đc gọi là hyprid (lai).
2 Common deep learning method
-
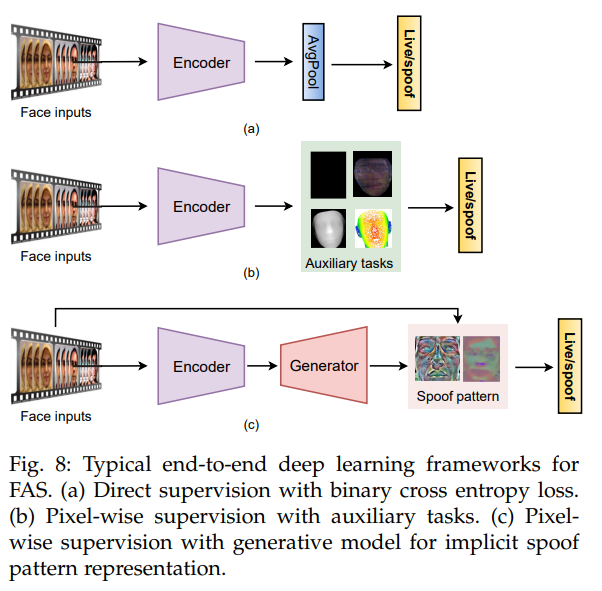
End-to-end binary cross-entropy supervision
Sử dụng end-to-end deep learning based method, vì xử lý bài toán như một bài classification 2 class, nên sử dụng cross entropy loss để giám sát việc huấn luyện model.
Tuy nhiên, sử dụng mỗi binary loss chưa thể hold được toàn bộ việc huấn luyện. Một số paper gần đây đề xuất bổ sung thêm một số Loss như: Contrastive Loss, Triplet Loss. Chi tiết mình sẽ cố gắng đề cập ở các bài viết sau.
Dạo gần đây, các hướng nghiên cứu tiếp cận theo hướng pixel-wise supervision thu hút nhiều sự chú ý hơn vì nó cung cấp nhiều tín hiệu giám sát nhận biết ngữ cảnh chi tiết hơn, có lợi cho mô hình học các intrinsic spoofing cues (dịch là tín hiệu giả mạo nội tại, mình cx không chắc nữa =)), phần này vẫn còn phải đọc lại nhiều).
-
Pixel-wise auxiliary supervision
Pseudo Depth labels, Eeflection maps, Binary Mask label và 3D Point cloud maps là các điển hình cho phương pháp pixel-wise auxiliary supervisions. Phương pháp này mô tả các dấu hiệu live/spoof cục bộ ở cấp độ pixel hoặc patch.
Nói thêm một chút về pseudo depth, ở phương pháp này, mô hình cố gắng tạo ra các feature maps là depth maps. Nói cách khác là cố dựng lại bản đồ độ sâu cho đối tượng. Bạn có thể tham khảo paper: Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing. là một ví dụ cho phương pháp sử dụng mạng CNN kết hợp RNN để cố gắng xây dựng lại bản đồ độ sâu. Đồng thời ở paper này giới thiệu Contrastive Depth Loss. Mình sẽ viết một bài phân tích chi tiết về paper này ở bài viết sau.
Một số hướng có thể suy nghĩ như là: (1) ảnh chúng ta thu được có thêm phần background dính vào (ví dụ khoảng trống ở cổ), liệu có thể loại bỏ phần này và chỉ tập trung vào khuôn mặt, có thể tham khảo ở đây, (2) sử dụng 3D point cloud map để giám sát các mô hình lightweight, (4) làm sao để tích hợp thêm một số thông tin phụ trợ khác, etc ...
-
Generative model with pixel-wise supervision
Sử dụng mạng GAN.
3. Generalized deep learning method
Như đã nói bên trên, đó là vấn đề domain và học tổng quát. Sẽ như thế nào nếu gặp phải một phương pháp tấn công chưa gặp bao giờ, sẽ như thế nào nếu mô hình của chúng ta tốt với cách tấn công này nhưng fail với cách tấn công khác.
Các phương pháp Domain Adaption cần dữ liệu của miền đích target domain (không được gắn nhãn) để tìm hiểu mô hình. Các phương pháp Domain Generalization học mô hình tổng quát mà không có kiến thức từ target domain. Cuối cùng, Few-shot Learning coi mỗi miền nguồn như một trung tâm dữ liệu riêng và tìm hiểu mô hình tổng quát hóa trong server thông qua tổng hợp các mô hình từ các trung tâm dữ liệu cục bộ.

Một paper mới published gần đây nhất nằm trong phương pháp Domain Generalization là paper D2AM, với ý tưởng chung là phân chia lặp đi lặp lại các miền hỗn hợp (mixture domain) thông qua biểu diễn các miền phân biệt và đào tạo các mô hình có thể tổng quát hóa với meta-learning mà không sử dụng nhãn miền. Bạn nên đọc:
6.3 Deep FAS methods with advanced sensor
- Learning upon specialized sensor
- Multi-modal learning: Phương pháp này bắt nguồn từ suy nghĩ rằng việc kết hợp các phương thức hoặc loại thông tin khác nhau có thể cải thiện hiệu suất (ví dụ kết hợp ảnh RGB do camnera thu được và bản đồ độ sâu depth map đc tính toán (hoặc cũng do các camera depth thu được)). Tuy nhiên, việc kết hợp mức độ nhiễu khác nhau và xung đột giữa các phương thức là một thách thức. Hơn nữa, các phương thức có ảnh hưởng định lượng khác nhau đối với kết quả dự đoán. Phương pháp phổ biến nhất trong thực tế là kết hợp các nhúng cấp cao từ các đầu vào khác nhau bằng cách nối chúng và sau đó áp dụng softmax.
Mình chưa có nhiều kinh nghiệm về phần này, mình sẽ cố gắng update vào các bài viết sau.
7. Kết
Bài đã dài rồi. Nhìn chung, trong hai năm trở lại đây, có lẽ do nhu cầu xã hội, các nghiên cứu lẫn paper của bài toán này tăng vọt một cách đáng kể. Bài toán vẫn chưa tìm ra giải pháp tối ưu tổng quát nhất và vẫn đang còn rất nhiều điều cần khai phá. Ở các bài viết tiếp theo, mình sẽ đi sâu vào phân tích chi tiết một số phương pháp giải quyết bài toán Face Anti-spoofing và cách triển khai nó trong thực tế. Có thể followđể đón đọc các bài viết tiếp theo nhé.
Nếu bài viết này hữu ích, có thể để lại một Upvote cho mình có thêm động lực nhé :vvv sankiu3000.

Reference
All rights reserved
