
Building CNN model, Layer Patterns and Rules!
Bài đăng này đã không được cập nhật trong 7 năm
Introduction
Xin chào mọi người, hiện nay với sự phát triển không ngừng của Deep Learning cùng sự xuất hiện của rất nhiều thư viện hỗ trợ như Keras, TensorFlow... đã giúp cho việc xây dựng các mô hình Deep Learning trở lên thuận tiện hơn, có thể kể đến các mô hình kinh điển như CNN trong các bài toán Computer Vision, RNN, LSTM trong NLP... Ở bài viết này mình sẽ chia sẻ về kinh nghiệm của mình trong việc xây dựng một mô hình CNN cũng như một số kiến thức mình lấy từ quyển Deep Learning for Computer Vision của Adrian Rosebrock để chia sẻ tới mọi người. Để có được một mô hình tốt, chúng ta sẽ cần biết thêm về các yếu tố ảnh hưởng đến mô hình cũng như các kỹ thuật để làm tăng độ chính xác (accuracy), tối ưu hàm mất mát (loss), các kỹ thuật tránh overfitting (regularlization), không những vậy để có kết quả tốt và cũng là điều kiện cần vô cùng là khâu tiền xử lý dữ liệu (Data Preprocessing), nếu dữ liệu đầu vào tốt thì với một mô hình chưa phải ở mức tối ưu nhất vẫn có khả năng cho ra một kết quả tương đối tối. Nhưng ở bài này mình sẽ chỉ tập trung để hướng dẫn các bạn cách xây dựng một mô hình CNN, cách sắp xếp layers sao cho hợp lý, những kỹ thuật khác có thể mình sẽ chia sẻ ở các bài sau.
CNN Building Blocks
Đầu tiên để xây dựng được mô hình CNN, chúng ta cần biết về các loại layers của một mô hình CNN. Ở đây mình sẽ không đi giới thiệu lại vai trò của từng layers nữa, mỗi layers có một vai trò, cách thức hoạt động riêng vì vậy nếu chưa có kinh nghiệm về các layers, các bạn có thể tham khảo thêm ở các course trên mạng như CS231N,... nhé.
I. Layer Types
Có rất nhiều loại layers có thể dùng để xây dựng mô hình CNN, nhưng sau đây là những layers phổ biến nhất mà chúng ta hay sử dụng:
- Convolutional (CONV)
- Activation (ACT or RELU)
- Pooling (POOL)
- Fully-connected (FC)
- Batch Normalization (BN)
- Dropout (DO)
Stacking một tập các layers này theo một cách thức xác định chúng ta sẽ có được một mô hình CNN, một mô hình CNN có thể là từ đơn giản đến phức tạp tuỳ thuộc vào bao nhiêu tham số mà mô hình sử dụng. Sau đây sẽ là diagram cho một mô hình CNN đơn giản: INPUT => CONV => RELU => FC => SOFTMAX
Một điều quan trọng chúng ta cần phải nhớ đó là trong tập các layers này thì CONV, FC và BN là những layers sẽ chứa tham số, những tham số này chúng sẽ được học trong quá trình training, nhờ đó chúng ta có thể biết được các vị trí nào trong mô hình dẫn đến việc quá nhiều tham số để điều chỉnh lại. Activation và dropout không thực sự được coi là các layers, nhưng chúng vẫn được thêm vào mô hình để chúng ta thấy được kiến trúc mô hình rõ ràng và mạch lạc hơn.
II. Common Architectures and Training Patterns
1. Layers Patterns
Cho đến nay, có thể nói khuôn mẫu chung nhất cho các mô hình CNN là stack một vài CONV, RELU (Activation) layers và kèm theo một POOL layer ở cuối, sau đó lặp mẫu thứ tự này cho đến khi thu được height và width của dữ liệu (image) đủ nhỏ rồi áp dụng FC layers. Vì vậy, chúng ta có thể thu được kiến trúc chung cho một mô hình CNN như sau:
INPUT => [[CONV => RELU] * N => POOL?] * M => [FC => RELU] * K => FC
Ở đây, * ngụ ý có thể nhiều hơn hoặc bằng 1, ? là một optional operation. Trong đó, N, M, K được xác định như sau:
- 0 <= N <= 3
- M >= 0
- 0 <= K <= 2
Dưới đây, mình sẽ show một vài ví dụ về các kiến trúc CNN theo kiến trúc mẫu bên trên:
- INPUT => FC
- INPUT => [CONV => RELU => POOL] * 2 => FC => RELU => FC
- INPUT => [CONV => RELU => CONV => RELU => POOL] * 3 => [FC => RELU] * 2 => FC
Hoặc một ví dụ khác là kiến trúc mô hình ALexNet, cũng theo kiến trúc bên trên:
- INPUT => [CONV => RELU => POOL] * 2 => [CONV => RELU] * 3 => POOL => [FC => RELU => DO] * 2 => SOFTMAX
Một kiến trúc sâu hơn, VGGNet:
INPUT => [CONV => RELU] * 2 => POOL => [CONV => RELU] * 2 => POOL => [CONV => RELU] * 3 => POOL => [CONV => RELU] * 3 => POOL => [FC => RELU => DO] * 2 => SOFTMAX
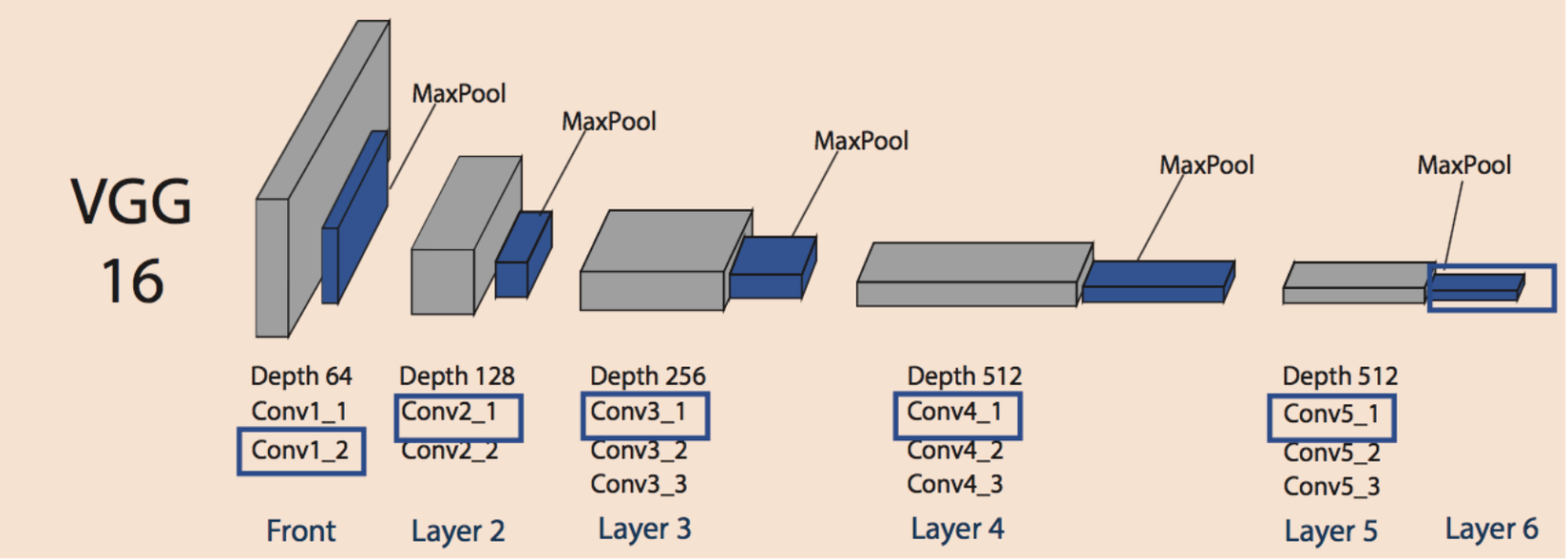
Nhìn chung, độ sâu của mô hình chúng ta sẽ dựa vào số lượng data, đặc điểm của dữ liệu cũng như vấn đề bài toán gặp phải. Việc xếp nhiều CONV layers trước khi áp dụng POOL layer cho phép mô hình học được các complex features hơn trước khi áp dụng POOL để giảm chiều dữ liệu cũng như filter được các features chính.
Tất nhiên sẽ có một vài kiến trúc lạ, không theo mẫu kiến trúc này như Inception, Xception..., hoặc một vài kiểu kiến trúc loại bỏ toàn bộ POOL layer giữa các CONV layer, dựa vào CONV để làm giảm chiều dữ liệu rồi cuối cùng áp dụng một Average Pooling Layer thay vì FC để đưa Input vào Softmax Classifier.
Các kiến trúc kinh điển như GoogleNet, ResNet và SqueezeNet là những ví dụ cho kiểu kiến trúc bên trên, mô tả cho việc loại bỏ FC sẽ giúp cho giảm số lượng params giúp quá trình training nhanh hơn mà vẫn thu được accuracy cao. Tuy nhiên để làm được điều đó đòi hỏi phải có kinh nghiệm nhất định trong việc xây dựng mô hình.
Dưới đây là ví dụ về kiểu kiến trúc XceptionNet:
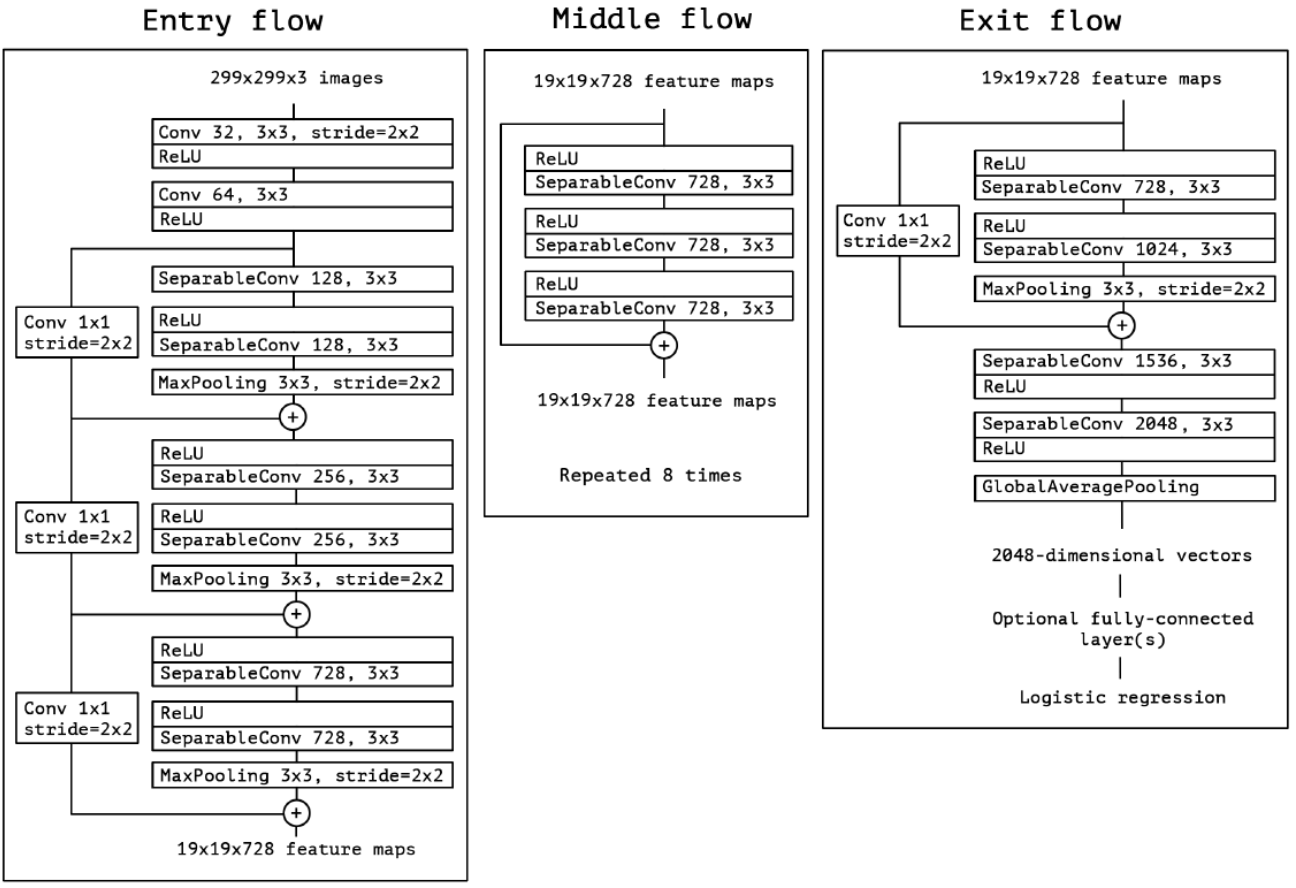
2. Rules of building CNN model
Ở phần này, mình sẽ nói về một số kinh nghiệm khi xây dựng một mô hình CNN. Thì...
Nhìn chung, các CONV layers chúng ta nên sử dụng filter_size=3x3 hoặc 5x5, tiny filter 1x1 có thể được sử dụng để học các local features nhưng chỉ nên sử dụng chúng trong các kiểu kiến trúc nâng cao hơn, ví dụ như Xception hoặc Inception... Các filter_size cỡ 7x7 hoặc 11x11 chúng ta cực kì hạn chế nên sử dụng hoặc có sử dụng thì chỉ dùng cho CONV layer tầng đầu tiên với mục đích để giảm chiều không gian của ảnh với những input layer cỡ lớn, rồi từ các filter_size sau chúng ta chỉ sử dụng các filter_size với kích thước nhỏ thôi vì sau CONV layer đầu tiên dimension của input layer đã giảm đáng kể rồi.
Tiếp theo, cái mình muốn đề cập đó là chúng ta sẽ có 2 cách để giảm chiều dữ liệu, 1 là dựa vào tầng POOL layer, 2 là dựa vào CONV layer. Downsampling dựa vào CONV layer đòi hòi chúng ta phải có khả năng tính toán tham số, input deminsion qua từng layer mà model vẫn có thể học được những features đặc trưng nhất của ảnh để cho ra kết quả tốt, vì vậy với những bạn mới tiếp xúc với CNN thì hãy dùng POOL layer để giảm chiều dimension của input bằng cách apply zero-padding qua các tầng CONV, mục đích là vẫn giữ nguyên được dimension size của input mà vẫn thu được các features của ảnh, rồi sau đó áp dụng MAXPOOL(nên 2x2 hoặc 3x3 với stride = 2) để giảm dimension size.
Tiếp theo, mình sẽ đề cập đến Batch Normalization (BN), với BN nó có thể gây ra x2 hoặc thậm chí x3 lần lượng thời gian training model của chúng ta. Tuy nhiên, chúng ta nên sử dụng BN trong hầu như tất cả các kiến trúc mà chúng ta build nên, lý do là bởi ví nó giúp cho ổn định quá trình training, dễ dàng hơn trong việc tune các hyper params khác. Chúng ta nên đặt BN layer sau mỗi ACT layer, ví dụ:
- INPUT => CONV => RELU => BN => FC
- INPUT => [CONV => RELU => BN => POOL] * 2 => FC => RELU => BN => FC
- INPUT => [CONV => RELU => BN => CONV => RELU => BN => POOL] * 3 => [FC => RELU => BN] * 2 => FC
Lưu ý, chúng ta không áp dụng BN trước tầng softmax layer, vì tại vị trí này chúng ta giả sử gần như model đã học được những features đặc trưng nhất của ảnh cho nhiệm vụ classify.
Một phương pháp đơn giản nhưng lại hiệu quả giúp giảm overfitting đó là áp dụng Dropout(DO) giữa các tầng FC layersayers với dropout probability là 50%, chúng ta cũng có thể áp dụng dropout giữa các CONV layers và POOL layers với probability là 10-25%, do tính local connectivity của CONV layers thì dropout có thể coi là không có quá nhiều hiệu quả khi đặt ở vị trí này, tuy nhiên thực nghiệm lại chứng minh nó vô cùng hiệu quả trong việc chống lại overfitting.
PRACTICAL WITH MiniVGGNet
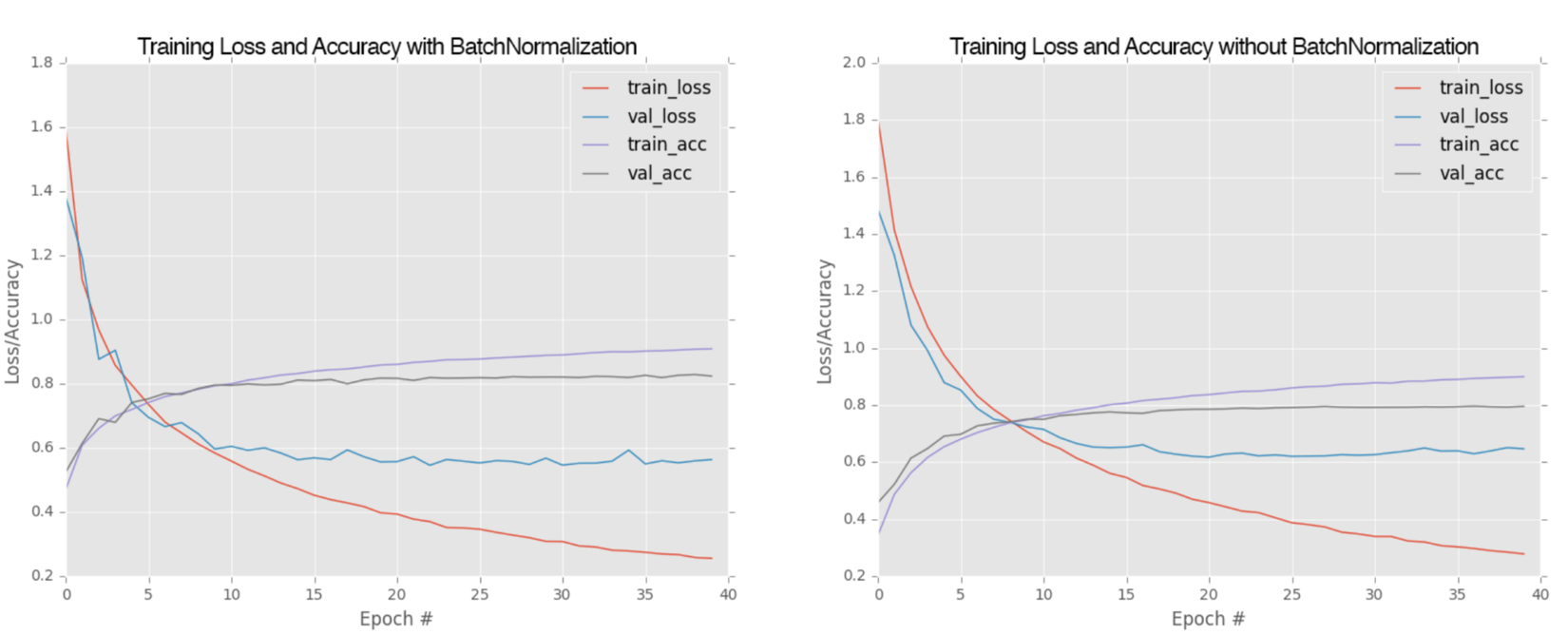
Ở phần này, mình sẽ thực hành làm một ví dụ nhỏ bằng việc xây dựng mô hình MiniVGGNet để phân loại với bộ dữ liệu CIFA-10. Mình sẽ thực nghiệm với việc mô hình dùng BN và không dùng BN. Mình sẽ có ảnh so sánh kết quả ở dưới cùng để các bạn tiện theo dõi.
Đầu tiên import các thư viện cần thiết.
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.datasets import cifar10
from keras.utils import to_categorical
from keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Dense, Flatten
import numpy as np
import cv2
from keras import backend as K
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from keras.optimizers import SGD
Load data và tiền xử lý dữ liệu
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype('float') / 255.0
trainY = trainY.astype('float') / 255.0
trainY = LabelBinarizer().fit_transform(trainY)
testY = LabelBinarizer().transform(testY)
Tiếp theo chúng ta sẽ build 1 mô hình MiniVGGNet:
class MiniVGGNet:
@staticmethod
def build(width, height, depth, classes):
model = Sequential()
input_shape = (height, width, depth)
model.add(Conv2D(32, (3, 3), padding='same', input_shape=input_shape))
model.add(Activation('relu'))
model.add(BatchNormalization(axis=-1))
model.add(Conv2D(32, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=-1))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=-1))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=-1))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
model = MiniVGGNet.build(width=32, height=32, depth=3, classes=10)
model.summary()
Compile model và training:
opt = SGD(lr=0.01, decay=0.01 / 40, momentum=0.9, nesterov=True)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=['accuracy']
H = model.fit(trainX, trainY, validation_data=(testX, testY), batch_size=64, epochs=40, verbose=1)
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 40), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 40), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 40), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 40), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Acc on CIFAR-10")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
Ở đây chúng ta sẽ có kết quả so sánh giữa việc dùng BN và không dùng BN, rõ ràng BN mặc dù làm tăng time training nhưng lại cho kết quả tốt hơn.
Summary
Trên đây mình đã chia sẻ những kinh nghiệm của mình trong việc xây dựng một model CNN, để có thể có được một model tốt, chúng ta cần học thêm rất nhiều các kỹ thuật khác nữa, từ việc tối ưu hàm loss, schedule learning rate, các kỹ thuật regularization, custom các model CNN phổ biến hiện nay để phù hợp với từng bài toán... Mình sẽ chia sẻ nhiều hơn ở những bài viết sau, cảm ơn mọi người đã đọc bài.
All rights reserved
