
Lựa chọn những thuộc tính quan trọng nhất trong một tập dữ liệu
Bài đăng này đã không được cập nhật trong 6 năm
Việc áp dụng Machine Learning vào kinh doanh đang trở nên rất phổ biến. Với các lĩnh vực như ngân hàng hay dịch vụ, bên cạnh đưa ra dự đoán hay phân loại vào các lớp, một mô hình có thể diễn giải được (interpretable) cũng rất quan trọng. Ví dụ, đối với một ngân hàng, ngoài việc dự đoán khả năng khách hàng A mở tài khoản tiết kiệm, ngân hàng này sẽ muốn mô hình đưa ra những yếu tố quan trọng nhất tác động đến quyết định mở tài khoản của khách hàng để từ đó cải thiện chất lượng dịch vụ.
Một trong những phương pháp xác định độ quan trọng của đặc trưng trong một tập dữ liệu là thuật toán Random Forest. Random forest đơn giản là tập hợp của các cây quyết định Decision Trees.
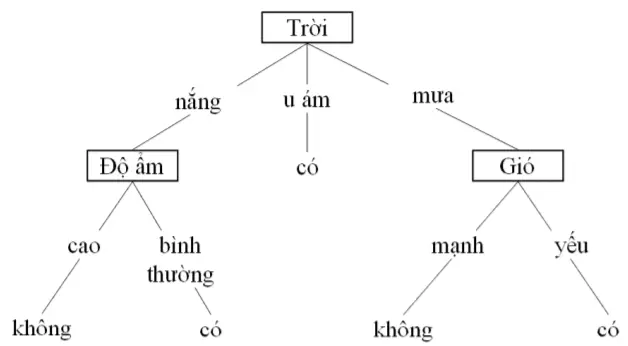
Đối với bất kỳ cây quyết định nào, các đặc trưng được chọn bằng cách chúng phân vùng tập huấn thành các tập con thuần túy (cross entropy nhỏ nhất). Sau đó, một cây quyết định sẽ tạo một danh sách các bước để phân vùng dữ liệu hiệu quản nhất và theo số bước nhanh nhất. Vì vậy, các đặc trưng cao nhất trong cây (gần node gốc nhất) có thể được coi là quan trọng nhất. Ví dụ một cây cho quyết định "Đi chơi tennis".
Trong Random forest, mỗi cây thực hiện phân loại trên một tập con dữ liệu và đặc trưng khác nhau. Điều này giúp tránh dữ liệu ngoại lệ (outliers), đồng thời ngăn overfitting và giảm sự phụ thuộc lẫn nhau giữa các đặc trưng. Cuối cùng, việc lựa chọn đặc trưng có thể được thực hiện bằng cách lấy trung bình mức độ quan trọng trên tất cả các cây.
Trong bài này, mình sẽ sử dụng Random forest để tìm ra nhân tố ảnh hưởng nhiều nhất đến sự nghỉ việc của nhân viên trong một công ty.
Data
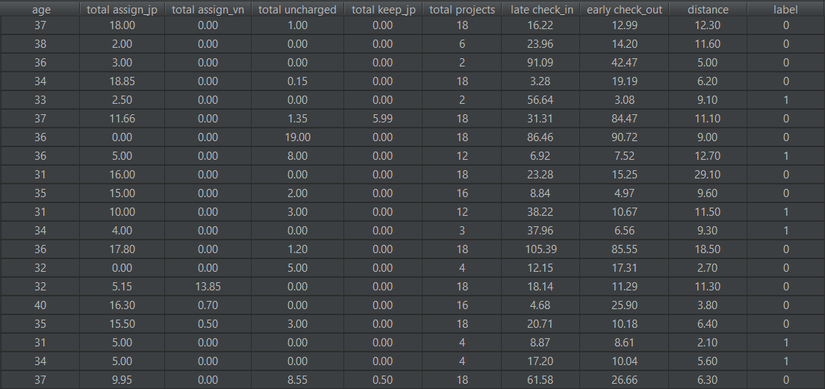
Dữ liệu mình sử dụng bao gồm 534 bản ghi tương ứng với 534 nhân viên của một công ty. Mỗi nhân viên được biểu diễn bằng 9 đặc trưng và 1 nhãn:
- age: tuổi
- total assign_jp: tổng số giờ làm việc với khách hàng Nhật Bản
- total assign_vn: tổng số giờ làm việc với khách hàng Nhật Bản
- total uncharged: tổng số giờ làm những task không được trả lương
- total keep_jp: tổng số giờ làm công việc quản lý
- total projects: tổng số dự án đã làm
- late check_in: trung bình số phút check-in muộn
- early check_out: trung bình số phút check-out sớm
- distance: khoảng cách (km) từ nhà đến công ty
- label: nhãn 0 (chưa nghỉ việc) hoặc 1 (đã nghỉ việc)
Huấn luyện Random forest
Ta thực hiện huấn luyện Random forest như bình thường, sử dụng thư viện Sklearn cho Python. Object RandomForestClassifier của Sklearn có thuộc tính feature_importances_ là một list độ quan trọng của từng đặc trưng. Hàm get_feature_importance() dưới đây thực hiện huấn luyện Random forest và trả về score cho từng đặc trưng.
def get_feature_importance(X_train, y_train, feat_labels):
clf = GridSearchCV(estimator=RandomForestClassifier(n_jobs=-1), param_grid={
'n_estimators': [200, 500, 1000, 5000, 10000],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth': [4, 5, 6, 7, 8],
'criterion': ['gini', 'entropy']
}, n_jobs=-1)
clf.fit(X_train, y_train)
clf = clf.best_estimator_
imp_dict = dict()
for feature in zip(feat_labels, clf.feature_importances_):
imp_dict[feature[0]] = feature[1]
imp_dict = {k: v for k, v in sorted(imp_dict.items(), key=lambda item: item[1], reverse=True)}
return imp_dict
Bắt đầu huấn luyện mô hình:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)
feat_labels = ['age', 'total assign_jp', 'total assign_vn', 'total uncharged', 'total keep_jp', 'total projects',
'late check_in', 'early check_out', 'distance']
imp_dict = get_feature_importance(X_train, y_train, feat_labels)
print(imp_dict)
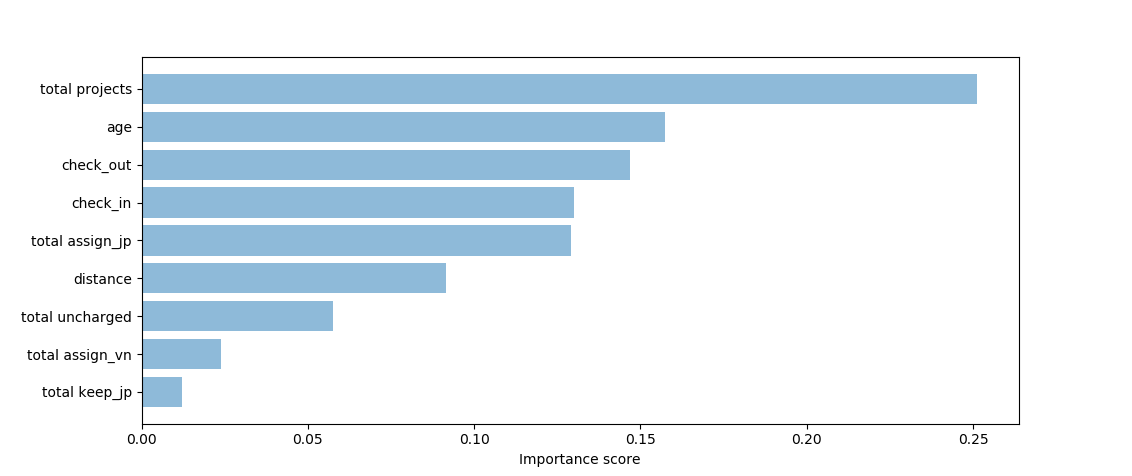
Kết quả nhận được:
total projects : 0.2595223137264566
age : 0.15616940708087929
check_out : 0.14865229572567062
total assign_jp : 0.13605541357374484
check_in : 0.11808778401647094
distance : 0.07406924376350689
total uncharged : 0.05777907643832159
total assign_vn : 0.03960290541738376
total keep_jp : 0.010061560257564075
Kết quả sau khi visualize bằng bar chart:
Kiểm chứng lại kết quả
Okay, khá ổn. Tuy nhiên câu hỏi lúc này là Bảng xếp hạng kia có đáng tin cậy?. Để trả lời cho câu hỏi này, ta sẽ verify kết quả bằng cách chọn ra top-k đặc trưng quan trọng nhất (ở đây mình chọn k = 3) và tách tập dữ liệu ban đầu thành 2 tập mới: Important set gồm 3 đặc trưng quan trọng nhất (total projects, age, check_out) và The rest gồm 6 đặc trưng "không quan trọng" còn lại. Cùng với tập dữ liệu ban đầu (Full set), ta tiến hành train 3 tập dữ liệu này trên các thuật toán phân loại khác nhau. Nếu độ chính xác của các thuật toán trên "Important set" xấp xỉ trên "Full set" và độ chính xác trên "The rest" thấp hơn hẳn 2 tập còn lại thì có thể kết luận kết quả trên đáng tin cậy!
Ở đây mình sẽ sử dụng 5 thuật toán phân loại sau: KNeighborsClassifier, SVC, RandomForestClassifier, MLPClassifier, AdaBoostClassifier
classifiers = [
[GridSearchCV(estimator=KNeighborsClassifier(n_jobs=-1), param_grid={
'n_neighbors': [1, 3, 5, 7, 9, 11, 15, 20]
}, n_jobs=-1), "KNN"],
[GridSearchCV(estimator=SVC(), param_grid={
'kernel': ['linear', 'rbf'],
'C': [0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000, 10000],
'gamma': [0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000, 10000]
}, n_jobs=-1), "SVM"],
[GridSearchCV(estimator=RandomForestClassifier(n_jobs=-1), param_grid={
'n_estimators': [200, 500, 1000, 5000, 10000],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth': [4, 5, 6, 7, 8],
'criterion': ['gini', 'entropy']
}, n_jobs=-1), "RF"],
[GridSearchCV(estimator=MLPClassifier(), param_grid={
'solver': ['lbfgs'],
'max_iter': [1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700,
1800, 1900, 2000],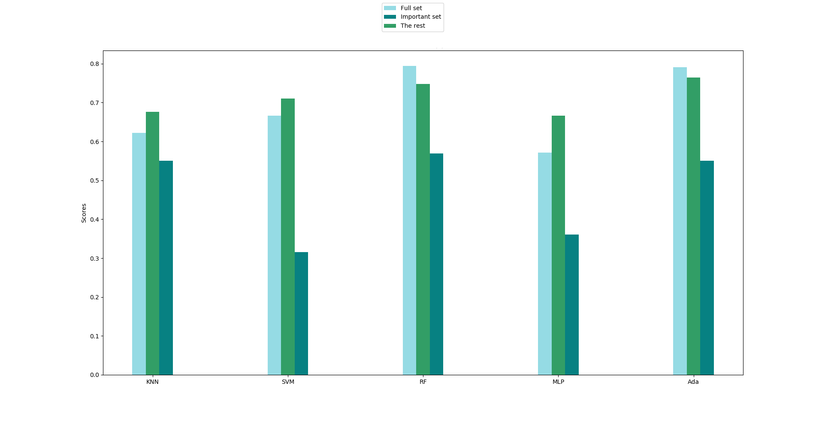
'alpha': 10.0 ** -np.arange(1, 10),
'hidden_layer_sizes': np.arange(10, 15),
'random_state': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
}, n_jobs=-1), "MLP"],
[GridSearchCV(estimator=AdaBoostClassifier(base_estimator=DecisionTreeClassifier()), param_grid={
'n_estimators': (1, 2, 5, 10),
'base_estimator__max_depth': (1, 2, 5, 8),
'algorithm': ('SAMME', 'SAMME.R')
}, n_jobs=-1), "Ada"]
]
Sau khi huấn luyện các mô hình trên, ta được kết quả sau:
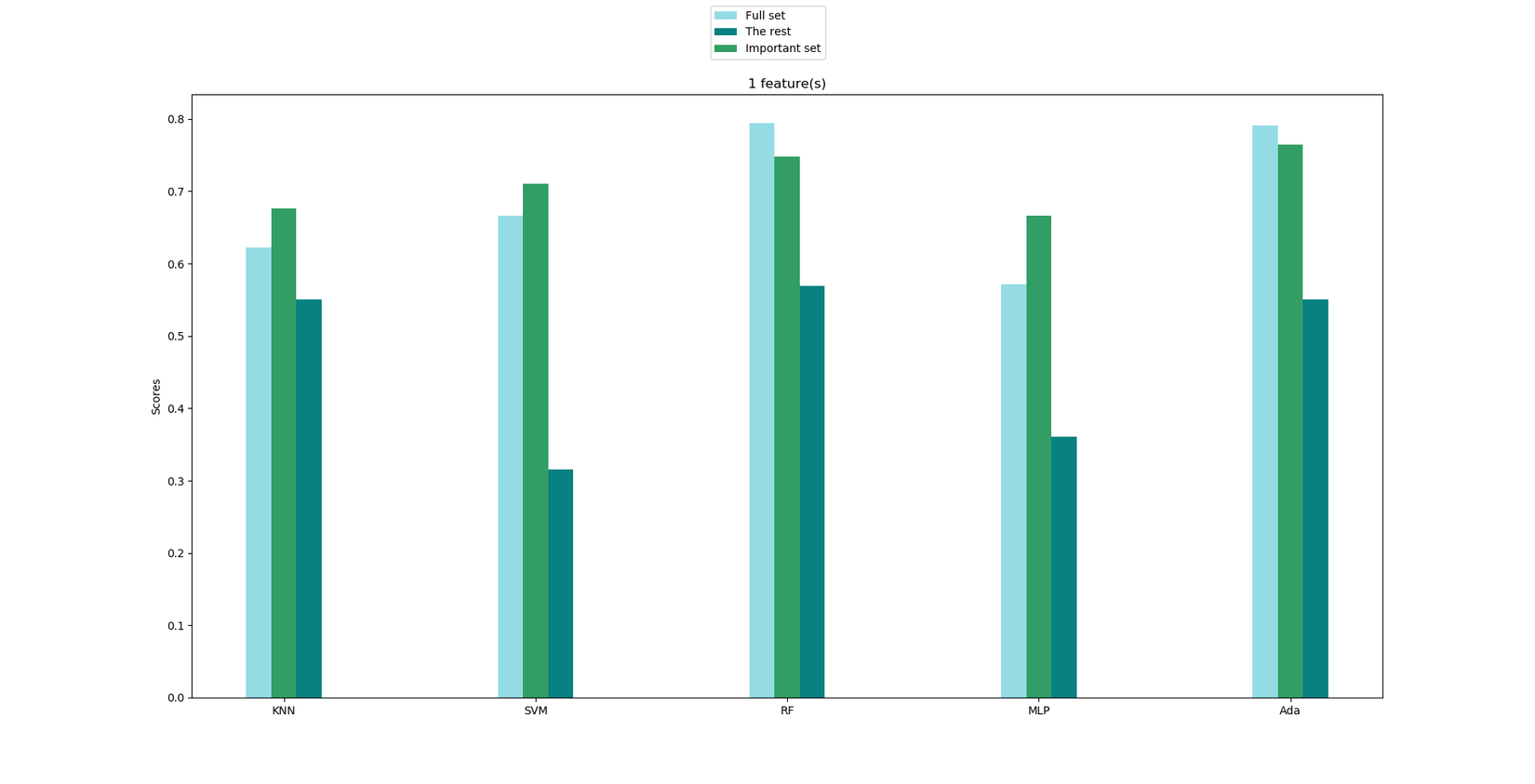
Có thể thấy, đúng như điều giả sử trên, các thuật toán khác nhau đều cho độ chính xác trên "Important set" xấp xỉ (thậm chí cao hơn vì được loại bỏ những đặc trưng phụ thuộc) "Full set"; trong khi độ chính xác sử dụng những đặc trưng không quan trọng thấp hơn hẳn. Vậy ta có thể kết luận 3 đặc trưng: total projects, age và early check_out ảnh hưởng đến quyết định nghỉ việc của nhân viên nhất.
Tuy nhiên, câu hỏi cuối cùng và quan trọng nhất là Những yếu tố này ảnh hưởng như thế nào?. Visualize dữ liệu ban đầu trên không gian 3 trục (total projects, age và early check_out) ta sẽ tìm thấy những câu trả lời thú vị cho câu hỏi này 
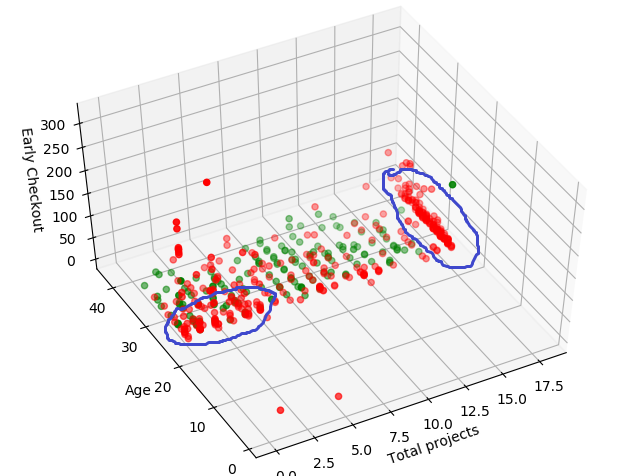
Và đây (những chấm màu đỏ là nghỉ việc, chấm màu xanh là chưa nghỉ), có 2 cụm chin chít đỏ: cụm 1 gồm những nhân viên làm trên 17 projects, trải dài mọi độ tuổi và cụm 2 gồm những nhân viên tuổi từ 25 đến dưới 30, tham gia vào dưới 5 projects. Điều này nói lên rằng ở cụm 1, nhân viên sẽ nghỉ việc nếu như họ phải làm quá nhiều projects, bất kể độ tuổi nào trong khi cụm 2 - chủ yếu là những người mới vào, tuổi đời trẻ - sẽ nghỉ việc vì chưa đủ gắn bó với công ty.
Kết luận
Việc chọn ra một vài đặc trưng trong tập những đặc trưng ban đầu mà không làm ảnh hưởng nhiều đến độ chính xác của mô hình là rất cần thiết trong Data Mining. Một phần vì nó giúp thu gọn kích thước khối dữ liệu, một phần giúp ta suy diễn nhiều hơn từ tập dữ liệu đó. Random forest là một thuật toán mạnh mẽ, thông minh và tương đối đơn giản, giúp ta thực hiện lựa chọn đặc trưng một cách dễ dàng.
All rights reserved
