
Object detection: Speed and Accuracy (Faster R-CNN, R-FCN, SSD, FPN, RetinaNet and YOLOv3)
Bài đăng này đã không được cập nhật trong 5 năm
I. Introduction
Xin chào các bạn mình lại ngóc lên đây, sau một vài bài viết thảo luận về các mô hình object detection như YOLOV3, YOLOV5, FasterRCNN,.. thì hôm nay mình lại ngoi lên để chia sẻ tới các bạn đọc bài viết với mục đích so sánh về tốc độ và độ chính xác của các mô hình với mong muốn qua đó sẽ giúp các bạn có thêm kiến thức khi lựa chọn các mô hình qua việc cân bằng giữa speed/memory/accuracy. Nếu các bạn chưa đọc các bài viết phân tích về các mô hình detection của mình mà muốn tham khảo có thể vào series bài viết của mình nhé. Đừng tiếc gì 1 lượt upvote để mình có thêm động lực viết các bài viết chất lượng hơn. Cảm ơn các bạn  ).
).
II. Discussion
Bài viết được mình tham khảo từ paper Speed/accuracy trade-offs for modern convolutional object detectors được viết bởi Jonathan Huang cùng các cộng sự. Bài viết được submit và published tại IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Những đóng góp chính của nhóm tác giả bao gồm các phần sau:
- Nhóm tác giả cung cấp một bản khảo sát ngắn gọn về các hệ thống phát hiện tích chập hiện đại và mô tả cách các hệ thống hàng đầu làm theo các thiết kế rất giống nhau.
- Họ mô tả các triển khai linh hoạt và thống nhất của các kiến trúc (Faster R-CNN, R-FCN and SSD) trong Tensorflow mà họ sử dụng để thử nghiệm cho việc theo dõi accuracy/speed qua feature extractor, image resolution, etc.
- Nghiên cứu chỉ ra rằng với mô hình Faster RCNN khi dùng ít proposal hơn có thể tăng đáng kể tốc độ mà không làm thay đổi quá nhiều tới độ chính xác giúp nó có thể cạnh tranh với RFCN và SSD.
- Một số kiến trúc meta và trích xuất tính năng các kết hợp mà họ báo cáo chưa từng xuất hiện trước đây trong tài liệu. Nhóm tác giả thảo luận về cách họ sử dụng một số những sự kết hợp mới lạ này để đào tạo mục nhập chiến thắng của thách thức phát hiện đối tượng COCO 2016.
Rất khó để có một sự so sánh công bằng giữa các mô hình phát hiện đối tượng. Không có câu trả lời chính xác nào về mô hình nào là mô hình tốt nhất. Đối với các ứng dụng khi các bạn sử dụng lựa chọn các mô hình thì sẽ xét theo các yêu cầu của bài toán đặt ra, chúng ta sẽ đưa ra các lựa chọn để cân bằng giữa độ chính xác và tốc độ. Bên cạnh lựa chọn các mô hình detect thì chúng ta cũng cần biết các lựa chọn có ảnh hưởng tới độ chính xác mô hình.
Mình xin phép được liệt kê các thuật ngữ chuyên ngành bằng tiếng anh vì thật ra mình cũng chả biết dịch làm sao cho đúng các thuật ngữ này cả, mong các bạn thông cảm.
- Feature extractors (VGG16, ResNet, Inception, MobileNet).
- Output strides for the extractor.
- Input image resolutions.
- Matching strategy and IoU threshold (how predictions are excluded in calculating loss).
- Non-max suppression IoU threshold.
- Hard example mining ratio (positive v.s. negative anchor ratio).
- The number of proposals or predictions.
- Boundary box encoding.
- Data augmentation.
- Training dataset.
- Use of multi-scale images in training or testing (with cropping).
- Which feature map layer(s) for object detection.
- Localization loss function.
- Deep learning software platform used.
- Training configurations including batch size, input image resize, learning rate, and learning rate decay.
III. Performance results
Trong phần này tác giả thống kê độ chính xác của các mô hình trong các bài báo được đề xuất.
FasterRCNN
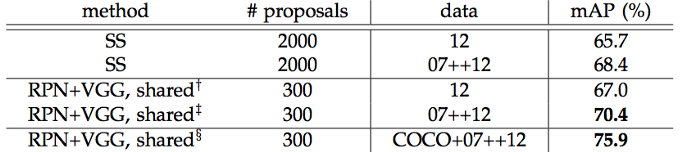
Đây là kết quả của mô hình được đánh giá trên bộ thử nghiệm PASCAL VOC 2012. Chúng ta quan tâm đến 3 hàng cuối cùng đại diện cho performance Faster R-CNN. Cột thứ hai đại diện cho số lượng RoI được thực hiện bởi mạng đề xuất khu vực. Cột thứ ba đại diện cho tập dữ liệu đào tạo được sử dụng. Cột thứ tư là độ chính xác trung bình trung bình ( mAP ) để đo độ chính xác.
Kết quả trên bộ dữ liệu PASCAL VOC 2012.
Kết qủa đánh giá trên MS COCO.
 Định thời gian trên GPU K40 tính bằng mili giây với bộ thử nghiệm PASCAL VOC 2007.
Định thời gian trên GPU K40 tính bằng mili giây với bộ thử nghiệm PASCAL VOC 2007.

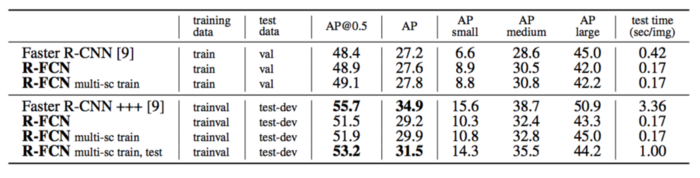
R-FCN
Kết quả đánh giá trên tập PASCAL VOC 2012.
 Kết quả đánh giá trên MS COCO
Kết quả đánh giá trên MS COCO
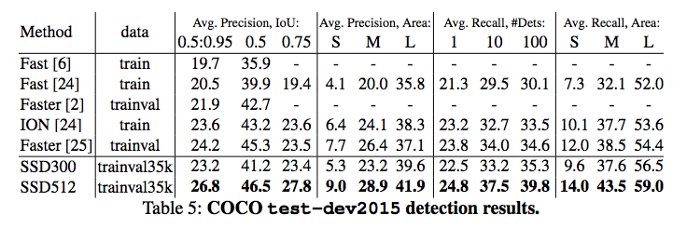
SSD
Dưới đây là kết quả mô hình dựa trên các tập dữ liệu đánh giá PASCAL VOC 2007, 2012 and MS COCO với kích thước đầu vào ảnh là 300x300 và 512x512.
 (SSD300* và SSD512* áp dụng thêm augmentation cho những object nhỏ để cải thiện mAP).
Ta có một kết quả so sánh các mô hình trên bộ dữ liệu về COCO như sau:
(SSD300* và SSD512* áp dụng thêm augmentation cho những object nhỏ để cải thiện mAP).
Ta có một kết quả so sánh các mô hình trên bộ dữ liệu về COCO như sau:
YOLOv3
Kết quả dựa trên COCO
 Performance for YOLOv3
Performance for YOLOv3
FPN
Kết quả trên COCO

RetinaNet
Kết quả trên COCO
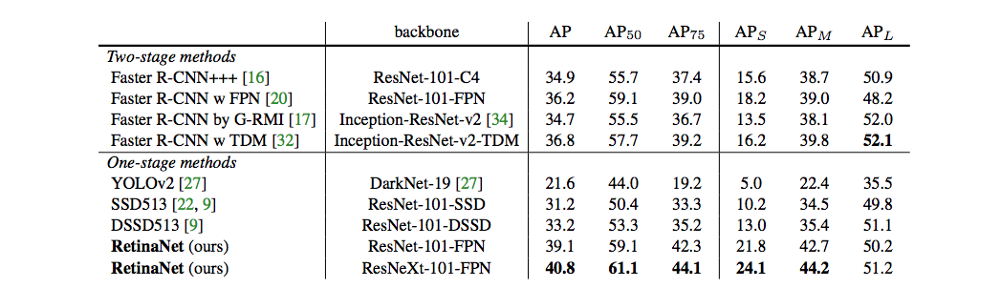
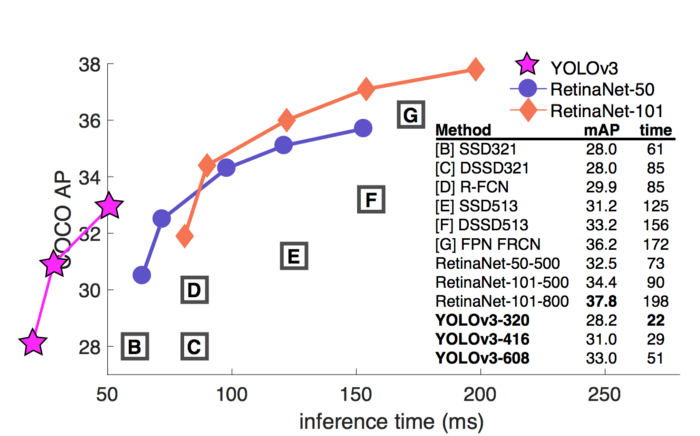
Ta có so sánh tốc độ(mili giây) với độ chính xác trên COCO dataset.
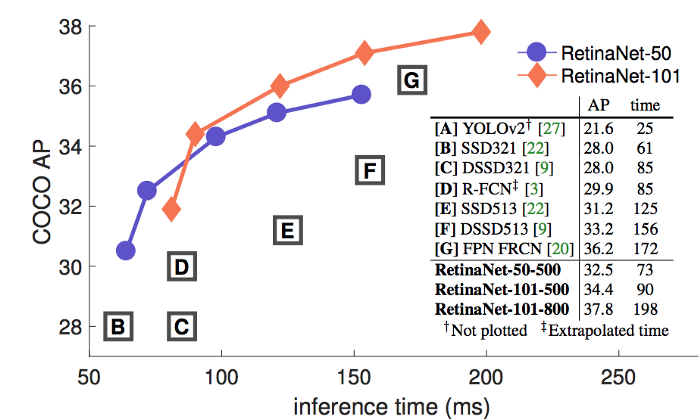
IV. Comparing paper results
Sẽ không hợp lý nếu chúng ta so sánh các mô hình trên với nhau qua các paper khác nhau vì chúng được thực hiện trên các điều kiện, bối cảnh khác nhau. Tuy nhiên trong paper tác giả có nói rằng họ sẽ vẽ chúng lại với nhau để chúng ta có một cái nhìn tổng quát về vị trí gần đúng của chúng.
Đối với kết quả được trình bày dưới đây, các mô hình phát hiện đối tượng được đào tạo với các bộ dữ liệu PASCAL VOC 2007 và 2012. Sau đó thì MAP được đo bằng bộ thử nghiệm PASCAL VOC 2012. Đối với SSD, biểu đồ hiển thị kết quả cho hình ảnh đầu vào 300 × 300 và 512 × 512. Đối với YOLO, nó có kết quả cho các hình ảnh 288 × 288, 416 × 461 và 544 × 544. Hình ảnh có độ phân giải cao hơn cho cùng một mô hìn sẽ cho kết quả mAP tốt hơn nhưng xử lý chậm hơn.
 Với: * biểu thị việc augumentation đối với dữ liệu đối tượng nhỏ. Còn ** cho biết kết quả được đo trên bộ thử nghiệm VOC 2007. Tác giả bài báo phải thêm những điều đó vì bài báo YOLO bỏ sót nhiều kết quả kiểm tra VOC 2012. Do kết quả VOC 2007 nói chung hoạt động tốt hơn năm 2012, nên nhóm tác giả thêm kết quả R-FCN trên bộ VOC 2007 làm tham chiếu chéo.
Với: * biểu thị việc augumentation đối với dữ liệu đối tượng nhỏ. Còn ** cho biết kết quả được đo trên bộ thử nghiệm VOC 2007. Tác giả bài báo phải thêm những điều đó vì bài báo YOLO bỏ sót nhiều kết quả kiểm tra VOC 2012. Do kết quả VOC 2007 nói chung hoạt động tốt hơn năm 2012, nên nhóm tác giả thêm kết quả R-FCN trên bộ VOC 2007 làm tham chiếu chéo.
Input image resolutions and feature extractors sẽ ảnh hưởng đến tốc độ. Dưới đây là FPS cao nhất và thấp nhất được báo cáo bởi các bài báo tương ứng. Tuy nhiên, kết quả dưới đây có thể rất sai lệch đặc biệt là chúng được đo ở các mAP khác nhau.
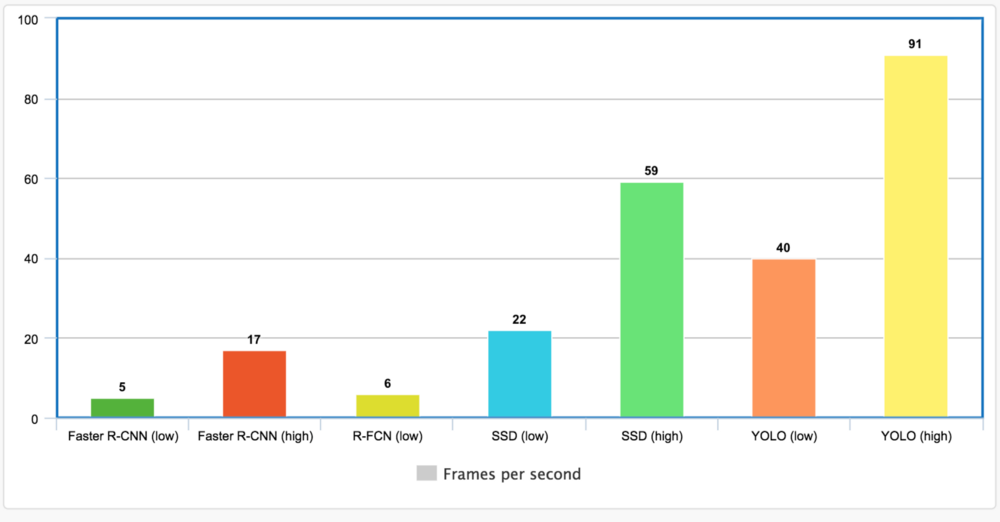
V. Result on COCO
FPN và Faster R-CNN * (sử dụng ResNet làm trình trích xuất tính năng) có độ chính xác cao nhất (mAP @ [. 5: .95]). RetinaNet xây dựng dựa trên FPN bằng cách sử dụng ResNet. Vì vậy, mAP cao mà RetinaNet đạt được là kết quả tổng hợp của các tính năng kim tự tháp.
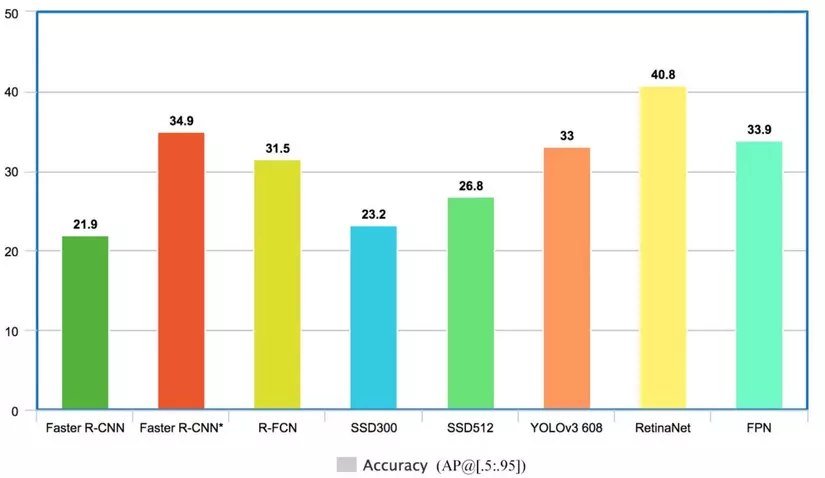
Single shot detectors có kết quả ấn tượng frame per seconds (FPS) sử dụng hình ảnh có độ phân giải thấp hơn vẫn đạt độ chính xác. Các mô hình này luôn cố gắng chứng mình chúng hiệu quả hơn các mô hình the region based detectors. Ta có một số kết luận nho nhỏ sau:
- Region based detectors like Faster R-CNN cho thấy lợi thế về độ chính xác nhỏ nếu không cần tốc độ thời gian thực.
- Single shot detectors cho các đáp ứng về tốc độ thời gian thực tuy nhiên chúng ta cần xem xét về độ chính xác của mô hình có đáp ứng được hay không.
VI. Report by Google Research
Google Research đưa ra một bài khảo sát để nghiên cứu sự cân bằng giữa tốc độ và độ chính xác cho Faster R-CNN, R-FCN và SSD. (YOLO không được đề cập trong bài báo.) Thực hiện lại các mô hình đó trong TensorFLow bằng cách sử dụng bộ dữ liệu MS COCO để đào tạo. Nó thiết lập một môi trường được kiểm soát tốt hơn và làm cho việc so sánh cân bằng trở nên dễ dàng hơn. Nó cũng giới thiệu MobileNet đạt được độ chính xác cao với độ phức tạp thấp hơn nhiều.
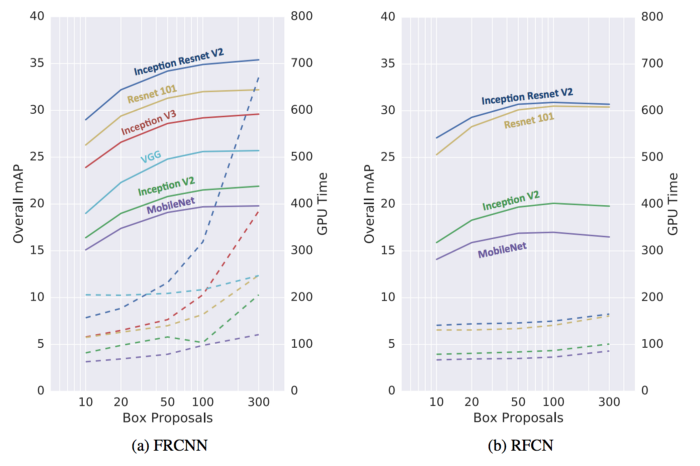
Speed v.s. accuracy
Câu hỏi quan trọng nhất không phải là mô hình phát hiện đối tượng nào là tốt nhất. Nó có thể không có câu trả lời. Câu hỏi thực sự là mô hình phát hiện đối tượng nào và cấu hình nào cung cấp cho chúng ta sự cân bằng tốt nhất về tốc độ và độ chính xác mà ứng dụng của chúng ta sẽ cần. Dưới đây là so sánh sự cân bằng giữa độ chính xác và tốc độ (thời gian được tính bằng mili giây).
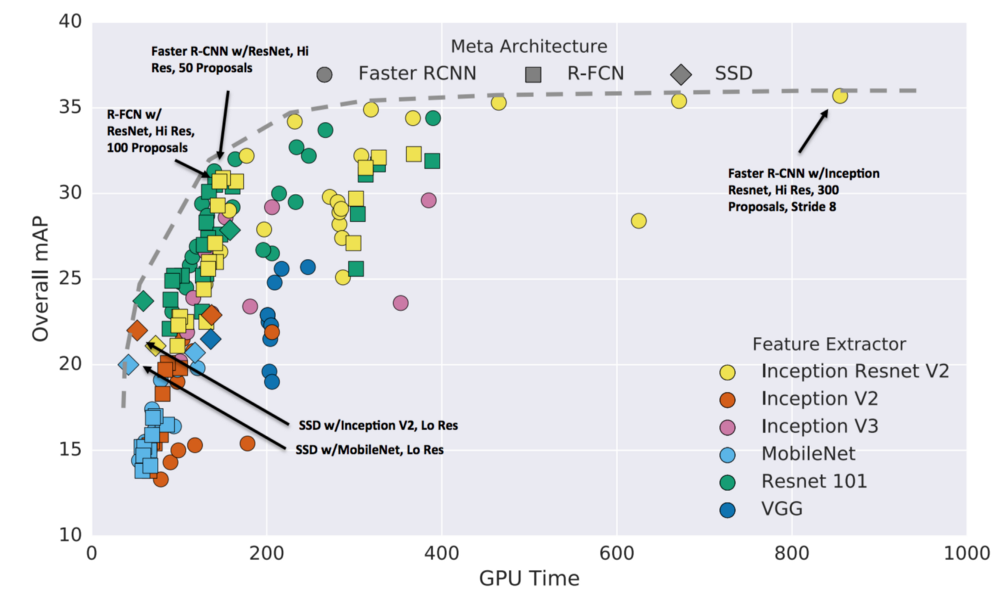 Nói chung, Faster R-CNN chính xác hơn trong khi R-FCN và SSD nhanh hơn.
Nói chung, Faster R-CNN chính xác hơn trong khi R-FCN và SSD nhanh hơn.
- Faster R-CNN bằng cách sử dụng Inception Resnet với 300 đề xuất (proposals) mang lại độ chính xác cao nhất ở 1 FPS cho tất cả các trường hợp được thử nghiệm.
- SSD trên MobileNet có mAP cao nhất trong số các mô hình được nhắm mục tiêu để xử lý thời gian thực.
Biểu đồ này cũng giúp cho chúng ta xác định được vị trí cân bằng tốt nhất giữa tốc độ và độ chính xác. - R-FCN sử dụng Residual Network để tạo ra sự cân bằng tốt nhất giữa tốc độ và độ chính xác.
- Faster R-CNN với Resnet có thể đạt performance tương tự nếu chúng ta hạn chế số lượng proposals xuống còn 50.
![]()

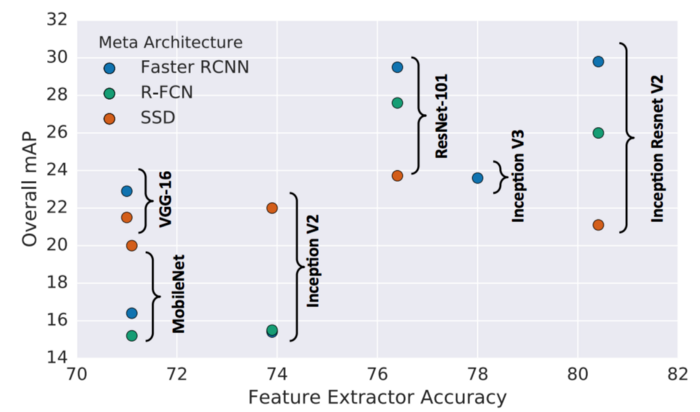
Feature extractor
Trong paper tác giả có nêu ra thử nghiệm của các feature extractor ảnh hưởng tới độ chính xác của các mô hình phát hiện đối tượng. Đối với Faster R-CNN and R-FCN thì có thể tận dụng feature extractor để cải thiện còn với SSD thì thay đổi này không đáng kể.
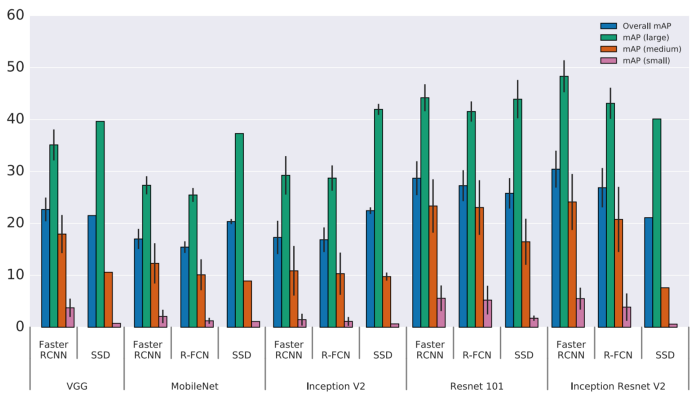
Object size
Đối với các đối tượng lớn, SSD hoạt động khá tốt ngay cả với một extractor đơn giản. Nhưng SSD hoạt động kém hơn nhiều trên các đối tượng nhỏ so với các phương pháp khác.
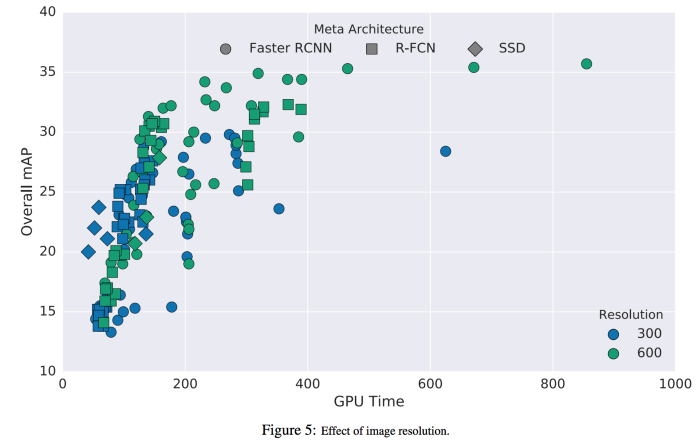
Input image resolution
Độ phân giải cao hơn cải thiện đáng kể khả năng phát hiện đối tượng đối với các đối tượng nhỏ trong khi cũng giúp các đối tượng lớn. Khi giảm độ phân giải theo hệ số hai ở cả hai chiều, độ chính xác trung bình giảm 15,88% nhưng thời gian suy luận cũng giảm trung bình 27,4%.
Number of proposals
Số lượng đề xuất được tạo có thể ảnh hưởng đáng kể đến Faster R-CNN (FRCNN) mà không làm giảm độ chính xác đáng kể. Ví dụ: với Inception Resnet, Faster R-CNN có thể cải thiện tốc độ gấp 3 lần khi sử dụng 50 đề xuất thay vì 300. Độ chính xác giảm chỉ là 4%.
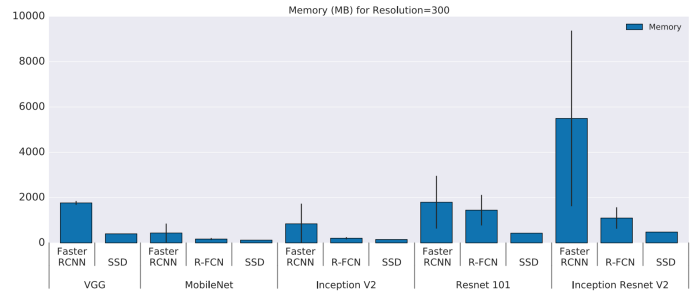
Memory
VII. Lessons learned
- Các mô hình R-FCN và SSD trung bình nhanh hơn nhưng không thể đánh bại Faster R-CNN về độ chính xác nếu tốc độ không phải là vấn đề đáng lo ngại.
- Faster R-CNN yêu cầu ít nhất 100 ms cho mỗi ảnh
- Khi sử dụng low-resolution feature maps để phát hiện đối tượng sẽ làm ảnh hưởng nghiêm trọng tới độ chính xác mô hình.
- Độ phân giải hình ảnh đầu vào (Input image resolution) ảnh hưởng đáng kể đến độ chính xác. Giảm kích thước hình ảnh xuống một nửa chiều rộng và chiều cao làm giảm độ chính xác trung bình 15,88% nhưng cũng làm giảm trung bình 27,4% thời gian suy luận.
- Lựa chọn một feature extractors sẽ làm ảnh hưởng tới độ chính xác của Faster RCNN và R-FCN tuy nhiên không làm thay đổi nhiều với SSD
- Nếu mAP chỉ được tính bằng một IoU duy nhất, hãy sử dụng mAP@IoU=0.75
- Với mạng Inception ResNet như một công cụ trích xuất tính năng, việc sử dụng bước 8 thay vì 16 cải thiện mAP lên 5%, nhưng tăng thời gian chạy lên 63%.
Most accurate
- Mô hình đơn chính xác nhất sử dụng Faster R-CNN bằng cách sử dụng Inception ResNet với 300 đề xuất. Nó chạy ở tốc độ 1 giây trên mỗi hình ảnh.
Fastest
- SSD với MobileNet cung cấp sự cân bằng độ chính xác tốt nhất trong các mô hình nhanh nhất.
- SSD nhanh nhưng hoạt động kém hơn đối với các đối tượng nhỏ so với các đối tượng khác.
- Đối với các vật thể lớn, SSD có thể vượt trội hơn Faster R-CNN và R-FCN về độ chính xác với bộ giải nén nhẹ hơn và nhanh hơn.
VIII. Conclusion
Bài viết của mình tới đây là kết thúc rồi. Hi vọng qua bài viết chia sẻ này của mình có thể giúp các bạn có cái nhìn tổng quan hơn khi lựa chọn các mô hình sao cho phù hợp với yêu cầu bài toán của mình. Các bạn có tìm hiểu thêm về các mô hình như YOLOV4 hay YOLOV5 trong series bài viết của mình nhé. Cảm ơn các bạn đã theo dõi bài viết của mình. Đừng tiếc gì một lượt upvote cho mình các bạn nhé.
All rights reserved
