
Giới thiệu về học tăng cường và ứng dụng Deep Q-Learning chơi game CartPole
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Học tăng cường (Reinforcement Learning-RL) là một trong ba kiểu học máy chính bên cạnh học giám sát (Supervised Learning) và học không giám sát (Unsupervised Learning). Bản chất của RL là trial-and-error, nghĩa là thử đi thử lại và rút ra kinh nghiệm sau mỗi lần thử như vậy. Gần đây, RL đã đạt được những thành tựu đáng kể khi các thuật toán của DeepMind (AlphaGo, AlphaZero, AlphaStar,...) đã chiến thắng áp đảo các tuyển thủ thế giới trong những trò chơi mà con người đã từng nghĩ rằng máy móc sẽ không bao giờ có thể vượt mặt như cờ vây hay StarCraft. Vậy bên trong RL có gì mà khiến nó "kinh khủng" như vậy? Bài viết này mình xin được giới thiệu tổng quan về RL và huấn luyện một mạng Deep Q-Learning cơ bản để chơi trò CartPole.
1. Các khái niệm cơ bản
Gồm 7 khái niệm chính: Agent, Environment, State, Action, Reward, Episode, Policy. Để dễ hiểu hơn, mình sẽ lấy ví dụ về một con robot tìm đường như hình dưới:
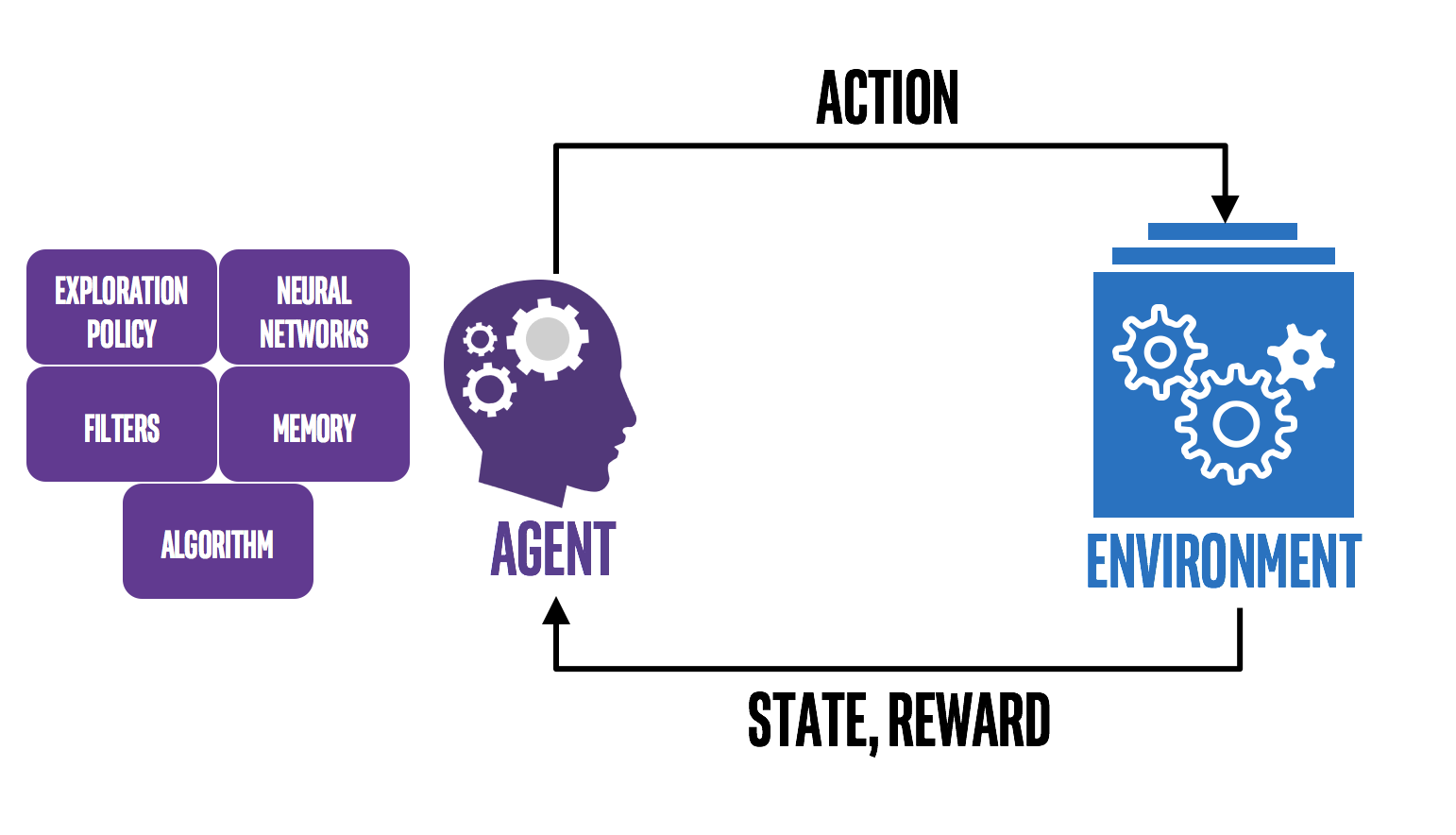
 Nhiệm vụ của con robot - Agent - là đi đến ô đích màu xanh, tránh ô phạt màu đỏ và ô xám là chướng ngại vật không được phép đi vào. Agent tương tác với Environment bằng các Actions trái/phải/lên/xuống. Sau mỗi action, environment trả lại cho agent một State (ở ví dụ này là vị trí của robot) và Reward tương ứng với state đó (+1 nếu đi vào xanh, -1 nếu đi vào ô đỏ và 0 nếu ở ô trắng). Khi agent đến ô xanh hoặc đỏ trò chơi kết thúc; một loạt các tương tác giữa agent và environment từ thời điểm bắt đầu đến lúc này được gọi là một Episode. Trong một episode, agent sẽ cố gắng chọn ra các actions tối ưu để tối đa hóa reward nhận được sau mỗi episode. Cách mà agent chọn những actions đó là Policy; ví dụ: "đi ngẫu nhiên", "đi men theo rìa" hoặc "hướng về ô đích". Có thể thấy policy cũng có policy này và policy kia; mục đích của RL là tìm ra policy tốt nhất. Hình dưới đây mô tả tương tác giữa Agent - Environment:
Nhiệm vụ của con robot - Agent - là đi đến ô đích màu xanh, tránh ô phạt màu đỏ và ô xám là chướng ngại vật không được phép đi vào. Agent tương tác với Environment bằng các Actions trái/phải/lên/xuống. Sau mỗi action, environment trả lại cho agent một State (ở ví dụ này là vị trí của robot) và Reward tương ứng với state đó (+1 nếu đi vào xanh, -1 nếu đi vào ô đỏ và 0 nếu ở ô trắng). Khi agent đến ô xanh hoặc đỏ trò chơi kết thúc; một loạt các tương tác giữa agent và environment từ thời điểm bắt đầu đến lúc này được gọi là một Episode. Trong một episode, agent sẽ cố gắng chọn ra các actions tối ưu để tối đa hóa reward nhận được sau mỗi episode. Cách mà agent chọn những actions đó là Policy; ví dụ: "đi ngẫu nhiên", "đi men theo rìa" hoặc "hướng về ô đích". Có thể thấy policy cũng có policy này và policy kia; mục đích của RL là tìm ra policy tốt nhất. Hình dưới đây mô tả tương tác giữa Agent - Environment:
2. Markov Decision Process (MDP)
MDP là một framework giúp agent đưa ra quyết định tại một state nào đó. Để áp dụng được framework này, ta giả sử các states có thuộc tính Markov (Markov Property): mỗi state chỉ phụ thuộc vào state trước nó vào xác suất chuyển đổi giữa 2 states này. Nghe hơi khó hiểu nhưng thực ra rất đơn giản. Đầu tiên, sao lại có "xác suất chuyển đổi giữa 2 states"? Trong một "thế giới hoàn hảo", nếu ta lặp lại một hành động thì sẽ cho ra 2 kết quả giống hệt nhau. Nhưng mọi việc không đơn giản như vậy vì hầu hết mọi sự việc đều là các tiến trình ngẫu nhiên (stochastic process)
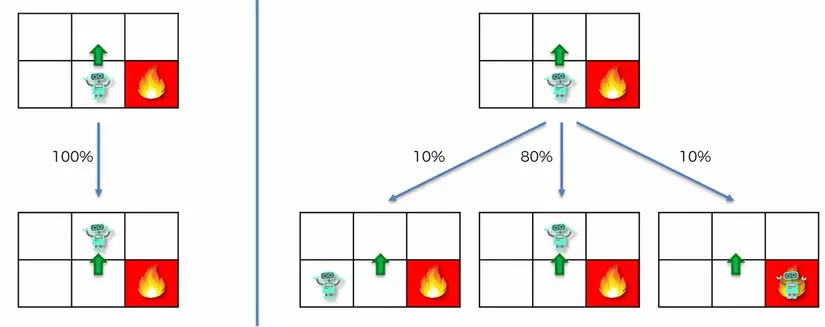
Ở hình trên, nếu như agent quyết định đi lên và environment trả lại state "ô trên" với xác suất 100% thì sẽ chẳng có gì để nói. Thay vào đó, kết quả agent nhận được lại là 80% state "ô trên", 10% state "ô trái" và 10% "ô phải". Hay một ví dụ khác ở game PUBG; khi bạn chọn hành động "ra ăn thính", sẽ chẳng bao giờ bạn đạt được 100% state "đã ăn thính" mà sẽ nhận được một phân bố xác suất như 70% "bị bắn chết", 20% "trắng tay" và 10% "ăn được thính".
Quay trở lại với Markov property, giả sử agent của bạn đang ở vị trí như hình dưới, việc nó đến đó bằng cách nào không quan trọng; nó có thể vòng từ trên bức tường xuống hoặc chui từ dưới lên hoặc thậm chí chạy sang trái sang phải 1000 lần trước khi đến nơi. Dù là cách nào thì khi agent đã ở đó, xác suất đi lên, sang trái/phải vẫn giống nhau. Có thể hiểu đơn giản Markov property là tính "không nhớ" (memoryless).
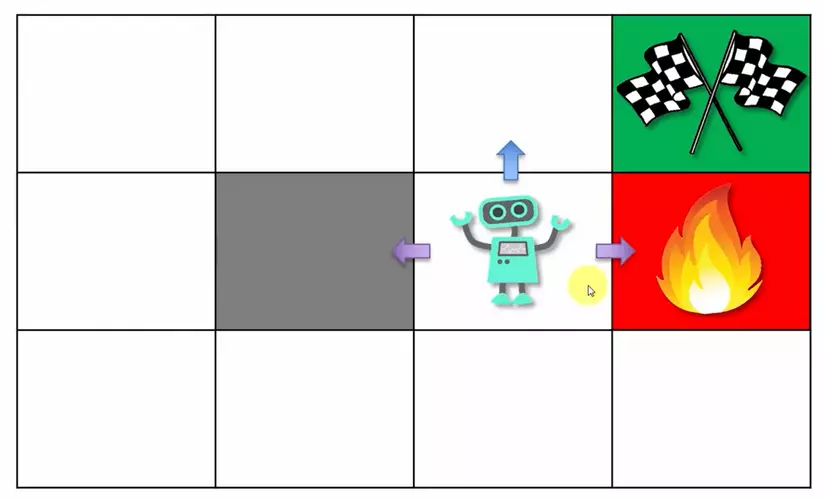
Với Markov property, chúng ta có thể áp dụng MDP để biểu diễn bài toán dưới dạng:
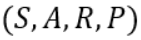
Trong đó: S là tập các states, A là tập các actions, R là reward nhận được khi chuyển state, P là phân bố xác suất chuyển đổi.
Việc biểu diễn này rất quan trọng, khi mà ta không phải lưu một chuỗi các states trước đó để biểu diễn state hiện tại khiến cho việc tính toán trở nên phức tạp và tiêu tốn bộ nhớ.
3. Q-Learning
Vậy là chúng ta đã biết được MDP, nhưng áp dụng vào RL learning như thế nào? Làm thế nào mà agent biết phải chọn action nào để đạt được reward lớn nhất? Câu trả lời là sử dụng một giá trị gọi là Q-value được tính bằng công thức:
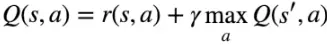
Trong đó Q(s, a) là Q-value khi thực hiện action a tại state s; r(s, a) là reward nhận được; s' là state kế tiếp. là hệ số discount, đảm bảo càng "xa" đích Q-value càng nhỏ
Công thức này cho thấy Q-value của action a tại state s bằng reward r(s,a) cộng với Q-value lớn nhất của các states s' tiếp theo khi thực hiện các action a. Vậy đó, chỉ với công thức đơn giản kia chúng ta có thể tạo ra một ma trận state-action như một lookup table. Từ đó với mỗi state agent chỉ cần tìm action nào có Q-value lớn nhất là xong. Tuy nhiên, như mình đã nói ở trên thì RL là một stochastic process nên Q-value ở thời điểm trước và sau khi thực hiện action sẽ khác nhau. Khác biệt này gọi là Temporal Difference:
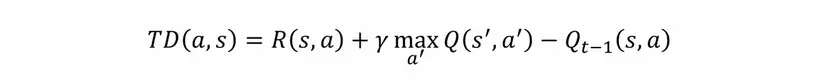
Như vậy, ma trận Q(s, a) cần phải cập nhật trọng số dựa trên TD:
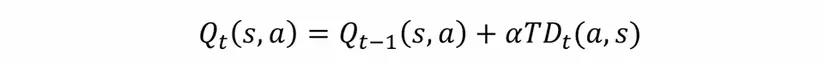
Trong đó là learning rate. Qua các lần agent thực hiện actions, Q(s, a) sẽ dần hội tụ. Quá trình này chính là Q-Learning
4. Deep Q-Learning
Bạn chán ngấy những công thức đệ quy ở trên? Hay đơn giản chỉ là bạn thích những gì liên quan đến Deep Learning? Chúc mừng, phần này dành cho bạn.
Tóm lại, mục đích của chúng ta là chọn ra action thích hợp cho một state nào đó; hay nói cách khác, chúng ta state làm input, output là một action. Đúng vậy đấy, không có gì thích hợp để giải quyết việc này hơn một Neural Network (NN). Những gì cần làm chỉ là bỏ đi lookup table Q(s,a) và thay thế bằng một NN đơn giản.
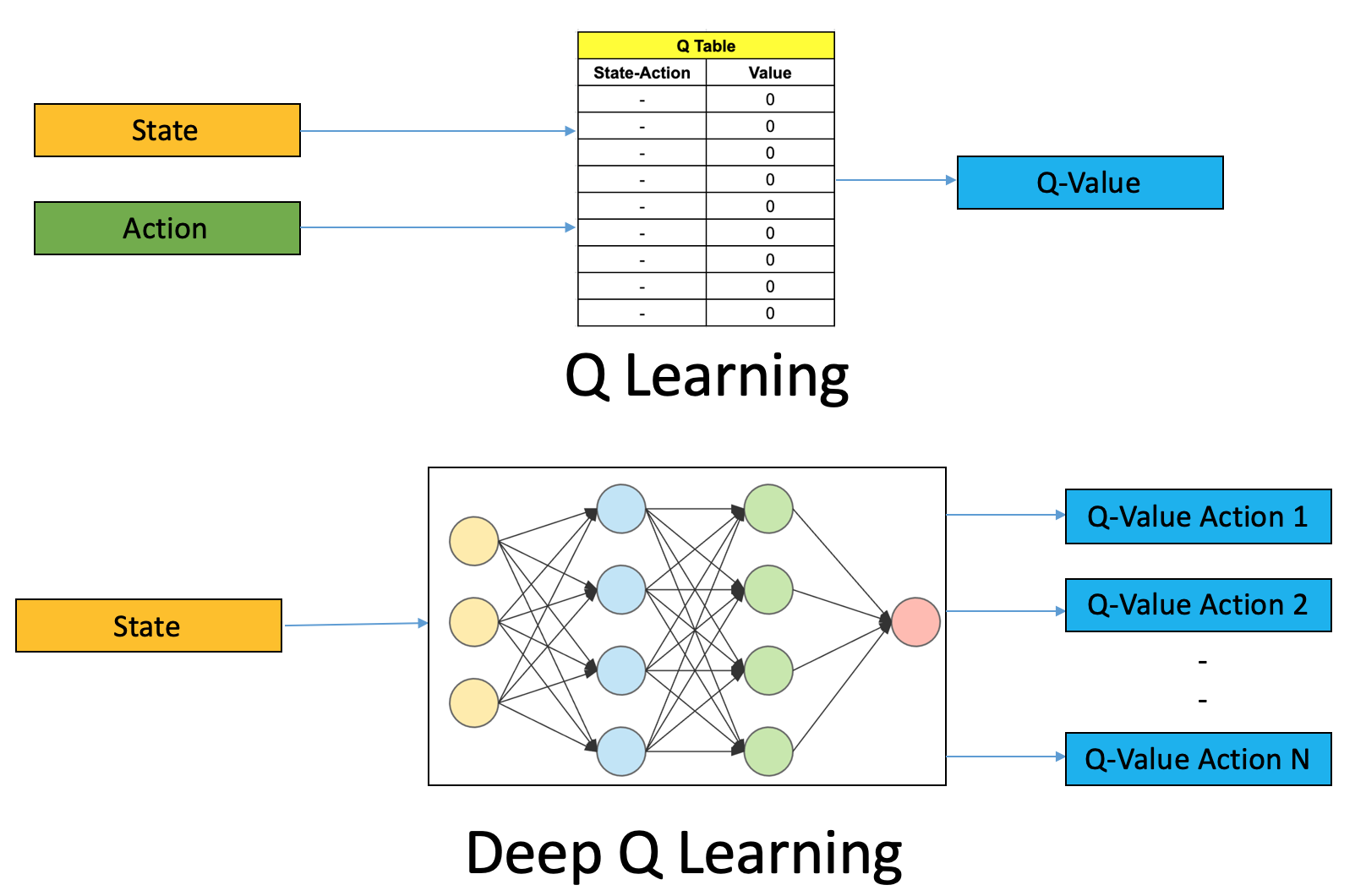
Tuy nhiên, vẫn còn thiếu phần quan trọng nhất của NN. Đó chính là hàm Loss. Mục đích của ta là bắt NN học được cách ước lượng Q-Value cho các actions một cách chính xác nên đương nhiên hàm Loss phải tính được sai số giữa Q-value thực tế và dự đoán. Hóa ra hàm Loss này ta đã định nghĩa từ trước rồi các bạn ạ. Nó chính là . Viết dưới dạng đầy đủ:
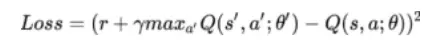
5. Experience replay
Phần trên ta đã định nghĩa một NN lấy input là state hiện tại và output các Q-value. Thế nhưng nếu NN cứ liên tục bị đẩy vào từng state một sẽ rất dễ bị overfitting vì các states liên tục thường giống nhau hoặc có tính tuyến tính (ví dụ: liên tục đi thẳng/sang trái/phải). Kỹ thuật Experience Replay được sử dụng để loại bỏ vấn đề này.
Thay vì mỗi state mạng update một lần, ta lưu lại các states vào bộ nhớ (memory). Sau đó thực hiện sampling thành các batch nhỏ đưa vào NN học. Việc này giúp đa dạng hóa input và tránh NN bị overfitting.
Nhìn lại toàn bộ mô hình
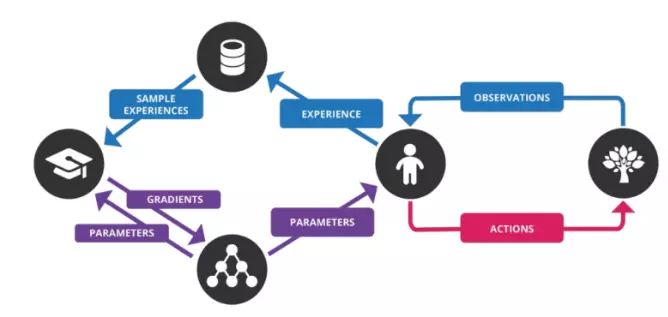
Tóm lại, Deep Q-Learning thực hiện các bước sau:
- Enviroment đưa vào mạng một state s; đầu ra là các Q-value của các actions tương ứng.
- Agent chọn action bằng một Policy và thực hiện action đó.
- Environment trả lại state s' và reward r là kết quả của action a và lưu experience tuple [s, a, r, s'] vào memory
- Thực hiện sample các experience thành một vài batches và tiến hành train NN
- Lặp lại đến khi kết thúc M episodes
Code thôi!
Đến đây, các bạn đã nắm được những lý thuyết cơ bản nhất trong RL nói chung và Deep Q-Learning nói riêng rồi. Chúng ta cùng code thử một ví dụ để xem nó hoạt động như thế nào nhé (mình giả sử các bạn đã có hiểu biết cơ bản về python và deep learning).
Ở phần này, ta sẽ sử dụng Deep Q-Learning để chinh phục game CartPole. Trong trò chơi này, nhiệm vụ của bạn rất đơn giản là di chuyển xe đẩy sang trái hoặc phải để giữ cây cột thăng bằng. Game kết thúc khi cây cột nghiêng quá 15 độ hoặc xe đẩy đi xa tâm quá 2.4 đơn vị. Agent giữ được cây cột càng lâu càng tốt nhưng chỉ cần đạt trung bình 195 điểm trong 100 episodes là coi như "chiến thắng".
Bước 1: Cài đặt các thư viện liên quan
Mình sẽ sử dụng keras-rl cho các module chính vì api của nó rất trực quan. Tiếp đến là gym, cung cấp cho ta Environment của rất nhiều bài toán khác nhau, trong đó có CartPole. Việc cài đặt rất đơn giản như sau:
pip install h5py
pip install gym
pip install keras-rl
Bước 2: Implement thuật toán
Import mudule liên quan:
import numpy as np
import gym
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
Khởi tạo environment:
ENV_NAME = 'CartPole-v0'
env = gym.make(ENV_NAME)
np.random.seed(123)
env.seed(123)
nb_actions = env.action_space.n #Trong game này nb_actions = 2 ứng với sang trái/phải
Xây dựng một Neural Network:
model = Sequential()
model.add(Flatten(input_shape=(10,) + env.observation_space.shape))
model.add(Dense(32))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
Vì bài toán này khá đơn giản nên NN của chúng ta không cần quá phức tạp; và mình thấy mạng trên cho kết quả tương đối tốt.
Phần chính: Agent, Policy và training
Mình chọn một policy đơn giản là -greedy. Policy này chọn ra action có Q-value lớn nhất với xác suất và chọn một action ngẫu nhiên với xác suất . Việc này đảm bảo agent có "mở rộng" (explorarion) bên cạnh "khai thác" (exploitation).
Với Experience Replay mình giới hạn số replays lưu lại là 50000 và mỗi lần lấy ra 10 replays liên tiếp để đưa vào training.
policy = EpsGreedyQPolicy()
memory = SequentialMemory(limit=50000, window_length=10) # window_length phải bằng input_shape ở trên nhé
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10, target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
dqn.fit(env, nb_steps=20000, visualize=True, verbose=2)
Thử nghiệm
Chúng ta cùng test thử xem reward trung bình là bao nhiêu, liệu có "thắng cuộc" (195 điểm) không nhé.
his = dqn.test(env, nb_episodes=100, visualize=True).history['episode_reward']
print("Average reward over", len(his), "episodes:", np.sum(his)/len(his))
 Ở 2 hàm fit và test mình set visualize=True để các bạn nhìn thấy kết quả một cách trực quan (và thú vị) nhưng đồng thời cũng làm quá trình training cũng như testing lâu hơn rất nhiều. Bạn có thể set False nếu muốn tiết kiệm thời gian.
Ở 2 hàm fit và test mình set visualize=True để các bạn nhìn thấy kết quả một cách trực quan (và thú vị) nhưng đồng thời cũng làm quá trình training cũng như testing lâu hơn rất nhiều. Bạn có thể set False nếu muốn tiết kiệm thời gian.
Và đây là kết quả:

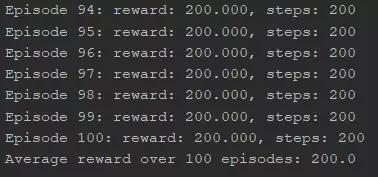
200 điểm!  Không tệ một chút nào!
Không tệ một chút nào!
Tổng kết
Trong bài này mình đã giới thiệu với các bạn tổng quan về Reinforcement Learning và cùng nhau xây dựng một thuật toán RL cơ bản nhưng rất phổ biến là Deep Q-Learning. Thông qua ví dụ này ta thấy được RL hữu dụng thế nào trong việc giải quyết bài toán điều khiển, khi mà Supervised learning tỏ ra bất lợi vì khó có thể tạo ra bộ dữ liệu thích hợp để mô hình hóa vấn đề. Đây là bài viblo đầu tiên của mình, nếu có sai sót gì mình xin được bỏ qua  . Còn nếu bạn thấy hay thì ngại ngần gì mà ko cho mình một upvote để mình có động lực viết bài sau
. Còn nếu bạn thấy hay thì ngại ngần gì mà ko cho mình một upvote để mình có động lực viết bài sau 

Tài liệu tham khảo: https://www.analyticsvidhya.com/blog/2019/04/introduction-deep-q-learning-python/
All rights reserved
