
[MaskRCNN] Các bước triển khai Mask R-CNN cho bài toán Image Segmentation
Bài đăng này đã không được cập nhật trong 6 năm
I.Overview
- Mask RCNN là một state-of-the-art cho bài toán về segmentation và object detection
- Chúng ta sẽ cùng tìm hiểu cách mà MaskRCNN hoạt động như thế nào
- Cùng nhau thực hiện các bước triển khai MaskRCNN cho bài toán segmatation
II.Introduction
Kết thúc chuỗi bài về RASA chatbot với các bài viết về Tập tành làm Rasa chatbot hay viết hàm custom action trong xử lý hội thoại chuỗi của chatbot (các bạn có thể xem bài viết trên trang của mình), thì hôm nay mình xin chia sẻ một chút hiểu biết mình về MaskRCNN trong chuỗi bài viết về segmentation. Trong bài viết này mình sẽ cùng các bạn tìm hiểu về cách mà MaskRCNN hoạt động và các bước triển khai MaskRCNN một cách đơn giản mà dễ hiểu nhất và bài viết sau chúng mình sẽ cùng nhau thực hiện training model mask RCNN cho bài toán cụ thể của các bạn sẽ triển khai như thế nào. 
III.Phân loại bài toán image segmentation
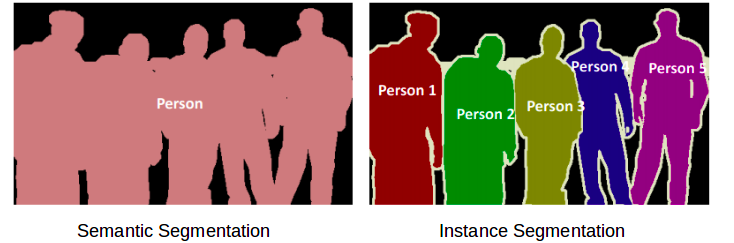
Bài toán image segmentation được chia ra làm 2 loại:
- Semantic segmentation : Thực hiện segment với việc phân chia từng lớp khác nhau: ví dụ trong một ảnh đang xuất hiện 3 class bao gồm: người, đèn giao thông, ô tô thì sẽ thực hiện segment với tất cả người vào 1 lớp, ô tô vào 1 lớp và đèn giao thông 1 lớp.
- Instance segmentation: Thực hiện segment với từng đối tượng riêng biệt trong cùng 1 lớp. Ví dụ: ảnh có 3 người thì sẽ thực hiện segment riêng biệt 3 người này thành 3 vùng khác nhau.
![]() Cần áp dụng kiểu segmentation nào thì còn phụ thuộc vào yêu cầu bài toán của bạn. Ví dụ cho bài toán xe ô tô tự lái thì chúng ta chỉ cần dùng semantic segmentation để nhóm class người, đèn... nhưng khi dùng cho bài toán theo dõi hành động của người trong siêu thị thì phải dùng tới instance segmentation để segment rõ từng người để theo dõi họ.
Cần áp dụng kiểu segmentation nào thì còn phụ thuộc vào yêu cầu bài toán của bạn. Ví dụ cho bài toán xe ô tô tự lái thì chúng ta chỉ cần dùng semantic segmentation để nhóm class người, đèn... nhưng khi dùng cho bài toán theo dõi hành động của người trong siêu thị thì phải dùng tới instance segmentation để segment rõ từng người để theo dõi họ.
IV. Mask R-CNN
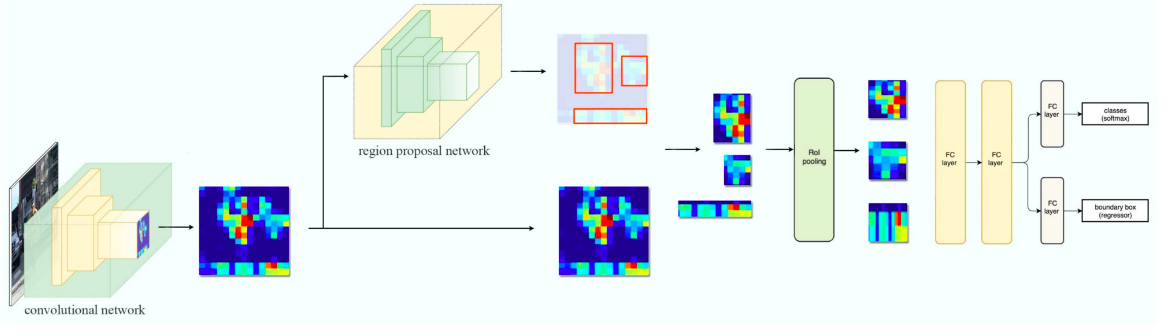
Mask R-CNN về cơ bản là phần mở rộng của Faster R-CNN. Faster R-CNN được sử dụng rất nhiều trong các bài toán phát hiện đối tượng. Khi chúng ta cho một hình ảnh vào Faster R-CNN sẽ trả ra nhãn và bounding box của từng đối tượng cụ thể trong một hình ảnh. 
Trong paper gốc của tác giả có nói và mình xin trích xuất đầy đủ như sau : "The Mask R-CNN framework is built on top of Faster R-CNN". MÌnh có thể nói một cách đơn giản như sau để cho các bạn dễ hình dung, khi bạn cho một hình ảnh vào ngoài việc trả ra label và bouding box của từng object trong một hình ảnh thì nó sẽ thêm cho chúng ta các object mask.
 Cũng có khá nhiều bài viết về Faster R-CNN nên nếu các bạn muốn hiểu thêm thì có thể tìm đọc nhé trong phạm vi bài viết này mình xin nói nhanh về cách mà Faster R-CNN hoạt động:
Cũng có khá nhiều bài viết về Faster R-CNN nên nếu các bạn muốn hiểu thêm thì có thể tìm đọc nhé trong phạm vi bài viết này mình xin nói nhanh về cách mà Faster R-CNN hoạt động:
- Trước tiên nó sẽ sử dụng ConvNet để trích xuất các đặc trưng từ hình ảnh đầu vào
- Các tính này sau đó sẽ được chuyển qua một Region Proposal Network (RPN) sau đó sẽ trả về các bounding box tại các vùng có thể có đối tượng với các kích thước khác nhau.
- Sau đó thêm vào lớp RoI pooling layer với mục đích gộp tất các bouding box trên cùng 1 đối tượng với các kích thước khác nhau về cùng 1 kích cỡ.
- Và cuối cùng được chuyển tới một fully connected layer để phân loại và đầu ra là 1 bouding box cho từng đối tượng.
![]()
Backbone Model
Tương tự như ConvNet trong Faster R-CNN thì trong MaskRCNN được tác giả sử dụng kiến trúc Resnet101 để trích xuất thông tin từ hình ảnh đầu vào.
Region Proposal Network (RPN)
Trong bước này model sử dụng tính năng được trích xuất áp dụng vào mạng RPN để dự đoán đối tượng có trong khi vực đó hay không. Sau bước này chúng ta sẽ thu được bounding box tại các vùng có thể có đối tượng từ mô hình dự đoán.
Region of Interest (RoI)
Các bounding box từ các khu vực phát hiện đối tượng sẽ có những kích thước khác nhau nên qua bước này sẽ gộp toàn bộ các bouding box đó về 1 kích thước nhất định tại 1 đối tượng. iếp theo, các vùng này được chuyển qua một fully connected layer để dự đoán nhãn lớp và hộp giới hạn. Như mình đã nói 1 đối tượng sẽ có rất nhiều bounding box với các kích thước khác nhau sau đó nó sẽ được loại bỏ dần qua việc tính toán IOU như sau:
IoU = Area of the intersection / Area of the union
hay là vùng giao nhau giữa bouding box dự đoán và bounding box thực tế chia cho bouding box thực tế. Nếu IOU lớn hơn hoặc bằng 0.5 thì sẽ quan tâm còn nhỏ hơn thì sẽ loại bỏ. Ví dụ dươí đây bạn có thể hiểu thêm như sau:
 Ta có thể thấy box1 và box2 sẽ IOU nhỏ hơn 0.5 nên nó sẽ là vùng loại bỏ còn box3 và box4 là vùng lớn hơn hoặc bằng 0.5 nên nó sẽ gọi là vùaidng quan tâm.
Ta có thể thấy box1 và box2 sẽ IOU nhỏ hơn 0.5 nên nó sẽ là vùng loại bỏ còn box3 và box4 là vùng lớn hơn hoặc bằng 0.5 nên nó sẽ gọi là vùaidng quan tâm.
Segmentation Mask
Chúng ta có ROI dựa trên những giá trị IOU qua việc tính toán nên tác giả đã thêm một nhánh mask vào trong kiến trúc hiện tại. 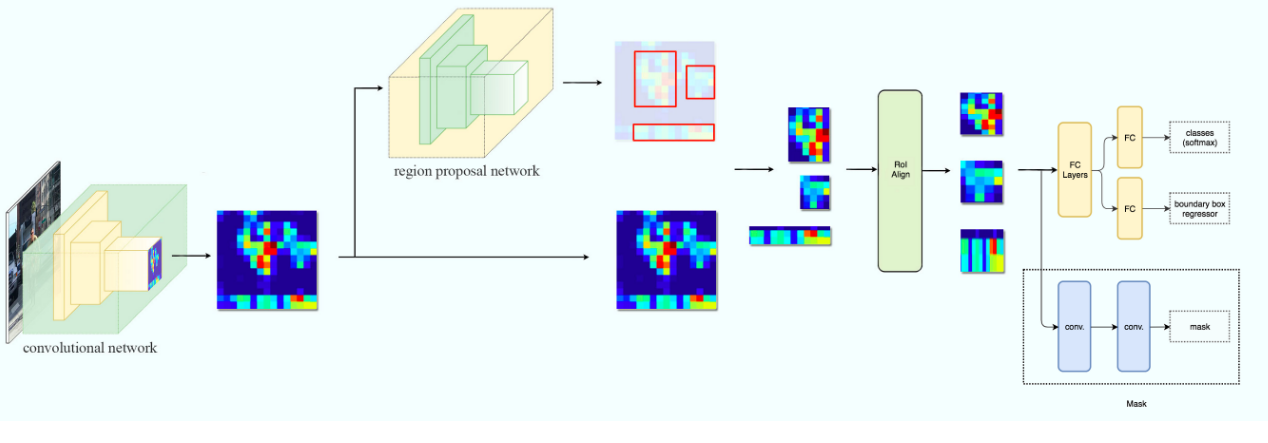
Ở đây, mô hình của chúng tôi đã phân đoạn tất cả các đối tượng trong hình ảnh. Đây là bước cuối cùng trong Mask R-CNN nơi chúng tôi dự đoán mask cho tất cả các đối tượng trong ảnh như hình dưới đây: 
V. Các bước triển khai Mask R-CNN
Trong phần này mình sẽ cùng các bạn thực hiện các bước triển khai Mask R-CNN như thế nào nhé:
Bước 1: Clone the repository
git clone https://github.com/matterport/Mask_RCNN.git
Bước 2: Cài đặt các thư viện liên quan dưới đây
numpy
scipy
Pillow
cython
matplotlib
scikit-image
tensorflow>=1.3.0
keras>=2.0.8
opencv-python
h5py
imgaug
IPython
Bước 3: Download the pre-trained weights (trained on MS COCO)
Các bạn dowload pretrain coco theo link dưới đây nhé :
https://github.com/matterport/Mask_RCNN/releases
Bước 4: Predicting for our image
Cuối cùng chúng ta sử dụng Mask R-CNN với các weight để dự đoán và tạo mask cho hình ảnh chúng ta cho vào nhé.
Chúng ta cùng nhau bắt đầu thôi nhé:
import os
import sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
# Root directory of the project
ROOT_DIR = os.path.abspath("../")
import warnings
warnings.filterwarnings("ignore")
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/")) # To find local version
import coco
%matplotlib inline
Tiếp theo chúng ta sẽ định nghĩa đường dẫn cho pretrained weight và hình ảnh qua đoạn code dưới đây nhé:
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join('', "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
class InferenceConfig(coco.CocoConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
config.display()
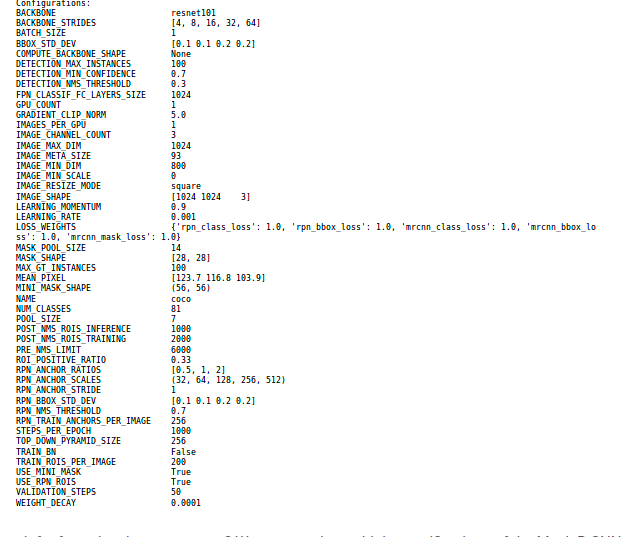
Chúng ta có thể nhìn thấy từ hình ảnh trên với model Mask R- CNN sử dung resnet101 với kích thước mask trả về là 28x28 được training trên bộ dữ liệu Coco và có tổng cộng 81 class bao gồm cả background. Tiếp theo chúng ta sẽ tạo ra model và load pretrain weight
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir='mask_rcnn_coco.hy', config=config)
# Load weights trained on MS-COCO
model.load_weights('mask_rcnn_coco.h5', by_name=True)
Định nghĩa các lớp của bộ dữ liệu coco
# COCO Class names
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
Chúng ta cùng load hình ảnh lên và show xem ảnh nhé :
# Load a random image from the images folder
image = skimage.io.imread('sample.jpg')
# original image
plt.figure(figsize=(12,10))
skimage.io.imshow(image)

Chúng ta cùng đưa hình ảnh vào model và tận hưởng thành quả thôi nào:
# Run detection
results = model.detect([image], verbose=1)
# Visualize results
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'], class_names, r['scores'])

Vậy là bài viết về Mask R-CNN cho bài toán image segmentation phần 1 của mình đến đây là kết thúc. Phần 2 mình sẽ cùng các bạn thực hiện training model Mask R-CNN cho 1 bài toán cụ thể nhé. Nếu các bạn thấy hay hoặc hơi hay hay thì xin bố thí cho mình xin 1 lượt upvote và hãy follow để đón chờ những bài viết mới nhé  ) (ahihi). Bài viết còn nhiều thiếu xót mong các bạn bỏ qua hoặc có thể comment góp ý bên dưới bài viết để mình hoàn thiện thêm. Cảm ơn các đã theo dõi bài viết của mình (tym)(tym)(tym)
) (ahihi). Bài viết còn nhiều thiếu xót mong các bạn bỏ qua hoặc có thể comment góp ý bên dưới bài viết để mình hoàn thiện thêm. Cảm ơn các đã theo dõi bài viết của mình (tym)(tym)(tym)
Tài liệu tham khảo
https://arxiv.org/pdf/1703.06870.pdf https://medium.com/@jonathan_hui/image-segmentation-with-mask-r-cnn-ebe6d793272 https://engineering.matterport.com/splash-of-color-instance-segmentation-with-mask-r-cnn-and-tensorflow-7c761e238b46 https://github.com/matterport/Mask_RCNN
All rights reserved
