
Ứng dụng AI tự động chuyển màn hình code khi phát hiện sếp đến gần
Bài đăng này đã không được cập nhật trong 7 năm
Xin chào các bạn. Có lẽ sợ sếp là một bệnh thâm niên ở mỗi người làm văn phòng nói chung và đặc biệt là anh em IT nói riêng. Đã bao giờ bạn gặp phải tình huống rất oái oăm khi mà ngồi code cả buổi thì sếp chả ghé thăm, đến lúc vừa rảnh tay lên Youtube nghe nhạc một tý xíu thì sếp đến nhẹ nhàng vỗ vai và thủ thỉ vào tai bạn một câu nói 2 giây nhưng dài như thế kỉ ARE YOU CODING?.  Thấu hiểu nỗi đau đó của anh em, hôm nay mình mạn phép hướng dẫn các bạn làm một ứng dụng rất hay ho đó là xử dụng AI và các mô hình Deep Learning để qua camera sẽ tự động phát hiện sếp sắp đến lại gần và rồi tự động chuyển ngay màn hình sang chế độ coding rất hữu dụng đặc biệt là cho anh em IT. Xin lưu ý mục đích của bài viết chỉ mang tính chất vui vẻ, giúp anh em cảm thấy đỡ áp lực sau những giờ làm việc căng thẳng. Hoàn toàn không cổ vũ cho việc mọi người làm việc riêng trong giờ làm.. OK chúng ta sẽ bắt đầu ngay thôi. Tuy nhiên trước tiên mời bạn xem thử demo dưới đây.
Thấu hiểu nỗi đau đó của anh em, hôm nay mình mạn phép hướng dẫn các bạn làm một ứng dụng rất hay ho đó là xử dụng AI và các mô hình Deep Learning để qua camera sẽ tự động phát hiện sếp sắp đến lại gần và rồi tự động chuyển ngay màn hình sang chế độ coding rất hữu dụng đặc biệt là cho anh em IT. Xin lưu ý mục đích của bài viết chỉ mang tính chất vui vẻ, giúp anh em cảm thấy đỡ áp lực sau những giờ làm việc căng thẳng. Hoàn toàn không cổ vũ cho việc mọi người làm việc riêng trong giờ làm.. OK chúng ta sẽ bắt đầu ngay thôi. Tuy nhiên trước tiên mời bạn xem thử demo dưới đây.
Bước 1: Cách tiếp cận bài toán
Đối với một bài toán mới chúng ta cần phải phân tích bài toán để tìm ra cách tiếp cận sao cho phù hợp. Tức là phân tích ra input và output của vấn đề. Đối với bài toán đã nêu ra, mục đích của chúng ta là phát hiện xem khi nào sếp đến (tất nhiên là dựa trên hình ảnh) vậy chắc chắn đầu vào của chúng ta sẽ từ một ảnh khuôn mặt, đầu ra cần phải xác định đó có phải là sếp hay không và nếu chúng ta xác định được đó là sếp thì thực hiện một xử lý nào đó (ví dụ như bật màn hình code lên thay vì màn hình đọc báo chẳng hạn). Vậy tựu chung lại chúng ta có thể tổng quát hóa các bước lại như sau:
- Khoanh vùng được các khuôn mặt
- Nhận ra xem khuôn mặt đó có giống sếp hay không
- Nếu giống sếp thì bật màn hình code lên (như đang làm việc bình thường)
- Nếu không phải sếp thì cứ đọc báo tiếp.
Hai bước sau thì đơn giản rồi phải không, bây giờ chúng ta sẽ bàn luận đến hai bước đầu tiên nhé. Tạm gác lại việc làm sao để khoanh vùng được mặt trong một bức ảnh bởi vì chúng ta không có quà nhiều thời gian. Hơn nữa bài toán này cũng khá quen thuộc nếu như các bạn chịu khó follow các topic về Deep Learning trên Viblo. Chuyển sang bước thứ hai, làm sao để biết được khuôn mặt được khoanh vùng có phải là sếp của mình hay không? Chúng ta cùng tìm hiểu hai cách tiếp cận cho vấn đề này nhé
Cách tiếp cận theo Face Verificiation
Hiểu đơn giản thì cách tiếp cận này sẽ đi trả lời câu hỏi:
Với một khuôn mặt này có giống với sếp mình hay không và nếu giống thì giống bao nhiêu phần trăm.
Ở đây chúng ta đơn thuần đi so sánh (compare) khuôn mặt mới với một khuôn mặt cũ đã có trong cơ sở dữ liệu (ví dụ các ảnh của sếp) xem hai bức ảnh này giống nhau bao nhiêu phần trăm. Thông thường bài toán này dẫn chúng ta đến một bài toán khác là làm thế nào để xác định được hai khuôn mặt này có giống nhau hay không. Như chúng ta đã biết máy tính chỉ hoạt động trên số, và tất cả cá giải thuật về Deep Learning cũng đều quy về việc xử lý trên không gian ma trận thực. Chính vì thế chúng ta cần một cách nào đó để mã hóa một ảnh của chúng ta thành vector gọi là embeding. Chúng ta có thể xem sơ đồ xử lý như sau:

Trên hình chúng ta thấy nhiệm vụ của Face Embedding Model chính là chuyển đổi từ hình ảnh sang một vector số thực. Để làm được điều này thường người ta sử dụng mạng nơ ron với hàm loss là một Triplet loss. Mọi người có thể tìm hiểu thêm về kĩ thuật này trong các bài viết khác trên Viblo
Hiểu đơn giản đó là việc chúng ta đưa những ảnh có nội dung giống nhau lại gần nhau và ảnh có nội dung khác nhau ra xa nhau. Mọi người có thể tìm hiểu thêm về phương pháp này trên các bài viết về Deep Learning trên Viblo. Giờ chúng ta sẽ cùng tìm hiểu phương pháp tiếp theo.
Cách tiếp cận theo Face Recognition
Thay vì việc phải tính toán một độ tương tự và so sánh như cách tiếp cận đầu tiên, chúng ta sẽ định nghĩa một mô hình và câu trả lời output của nó chính là xác suất của khuôn mặt có phải là sếp hay không. Việc này được giải quyết khá đơn giản và hiệu quả bởi mạng nơ ron tích chập (CNN) chúng ta có thể thấy trong mô hình sau:
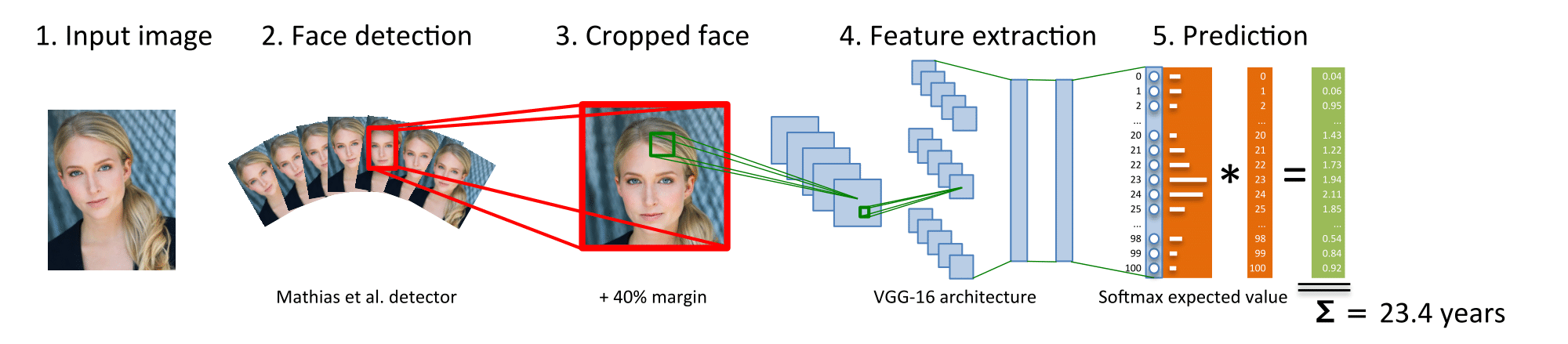
Lúc này mạng của chúng ta có thể trả lời luôn câu hỏi rằng
Đây là ai? - Output là sếp hoặc không phải là sếp OK sau khi đã hiểu một vấn đề chúng ta sẽ tiến hành lựa chọn một trong hai phương pháp để tính toán. Trong bài viết này mình sẽ sử dụng phương pháp thứ hai và các bạn có thể thử cài đặt phương pháp thứ nhất xem sao. Mình nghĩ là không có nhiều khó khăn lắm đâu. OK chúng ta bắt đầu nhé
Bước 2: Chuẩn bị dữ liệu.
Đối với mỗi một bài toán Machine Learning nào đều cần phải chuẩn bị về mặt dữ liệu. Nếu không có dữ liệu thì sẽ không có gì cả  Các bạn hãy thu thập các dữ liệu mặt của sếp mình, càng nhiều càng đa dạng càng tốt, Kiểu đa sắc thái như thế này là một nguồn dữ liệu rất quý giá.
Các bạn hãy thu thập các dữ liệu mặt của sếp mình, càng nhiều càng đa dạng càng tốt, Kiểu đa sắc thái như thế này là một nguồn dữ liệu rất quý giá.

Sau đó thu thập dữ liệu của các loại mặt khác không phải là mặt của sếp mình cho tất cả vào một folder chẳng hạn. Lúc này chúng ta sẽ có hai folder có tổ chức như sau:
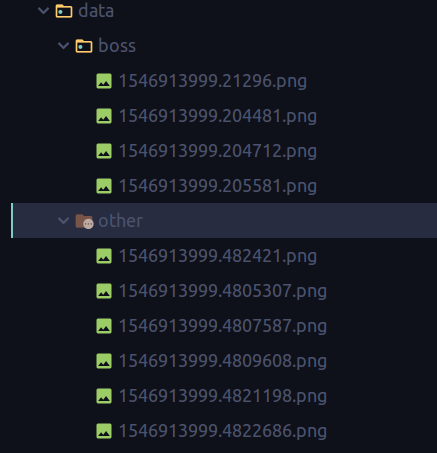
Càng bạn lưu ý rằng nên thu thập nhiều ảnh một chút model sẽ chính xác hơn
Bước 3: Tiền xử lý dữ liệu
Đây là một bước khá quan trọng trong khi thực hiện một bài toán Deep Learning nào. Chúng ta đã biết rằng Garbage in - Garbage out chính vì thế nên việc đưa dữ liệu vào trong mô hình cũng cần phải được xử lý một cách kĩ lưỡng. Chúng ta có một vài thao tác xử lý dữ liệu như sau:
- Resize image
- Chuyển về gray scale (nếu cần)
- Normalization image - chuẩn hóa ảnh giúp cho việc training được cải thiện về tốc độ và độ chính xác
- Augumentation image - giúp sinh thêm các dữ liệu mới, làm giàu hơn tập dữ liệu đã có
- Loại bỏ các dữ liệu nhiễu giúp mô hình không bị lệch
- Cân bằng lại dữ liệu giúp cho mô hình học được tổng quát hơn
Trong bài viết này chúng ta sử dụng Keras và model Mobilenet để training nên các bước tiền xử lý dữ liệu này chúng ta sử dụng trực tiếp của Keras luôn. Tiến hành import các thư viện cần thiết:
# Import dependency
import os
import cv2
import keras
import numpy as np
from keras import backend as K
from keras.layers.core import Dense, Activation
from keras.optimizers import Adam
from keras.metrics import categorical_crossentropy
from keras.preprocessing.image import ImageDataGenerator
from keras.preprocessing import image
from keras.models import Model
from keras.applications import imagenet_utils
from keras.layers import Dense, GlobalAveragePooling2D
from keras.applications import MobileNet
from keras.applications.mobilenet import preprocess_input
from IPython.display import Image
from keras.optimizers import Adam
Và định nghĩa các tham số
# Define parameters
IMAGE_SIZE = 224
IMAGE_DATA = './data'
images = []
labels = []
Sau đó chúng ta định nghĩa hàm preprocess như sau:
def prepare_image(file):
img_path = ''
img = image.load_img(img_path + file, target_size=(IMAGE_SIZE, IMAGE_SIZE))
img_array = image.img_to_array(img)
img_array_expanded_dims = np.expand_dims(img_array, axis=0)
return keras.applications.mobilenet.preprocess_input(img_array_expanded_dims)
Và đoạn code để sinh dữ liệu mẫu dùng cho việc training như sau:
# Generate dataset
for path, subdirs, files in os.walk(IMAGE_DATA):
for name in files:
img_path = os.path.join(path, name)
images.append(prepare_image(img_path))
labels.append(path.split('/')[-1])
Bước 4: Định nghĩa mô hình
Giống như đã mô tả ở trên chúng ta sử dụng mô hình Mobilenet để dự đoán mặt vào có phải là sếp hay không. Mình sẽ không nhắc lại lý thuyết về CNN nữa vì nó đã xuất hiện quá nhiều trên Viblo cũng như các diễn đàn khác. Các bạn có thể tìm hiểu nhé.
Khai báo mô hình đơn giản với Keras như sau:
model = keras.applications.mobilenet.MobileNet(classes=2, weights=None)
Mọi người có thể sử dụng model.summary() để hiển thị số lượng các tham số của mô hình
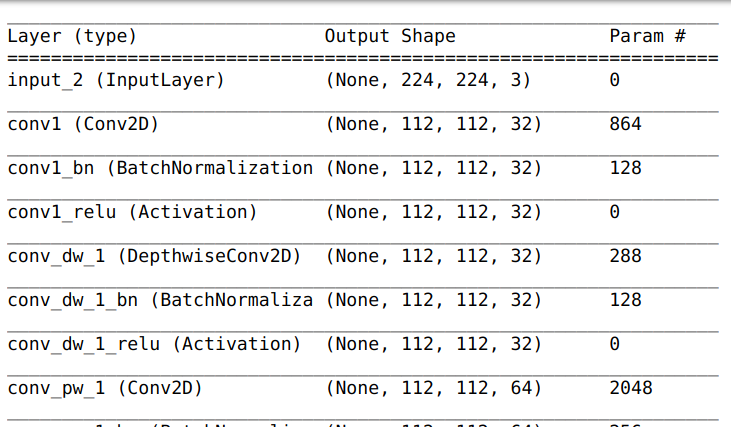
Mapping label
Vì mô hình của chúng ta là mô hình phân loại nên chúng ta sẽ cần sử dụng hàm loss là cross_entropy để tính toán. Chính vì thế nên việc đầu tiên là chuyển các class từ boss thành 1 và other thành 0. Chúng ta thực hiện như sau
# Mapping label
mapped_labels = list(map(lambda x: 1 if x == 'boss' else 0, labels))
from keras.utils import np_utils
y_data = np_utils.to_categorical(mapped_labels)
Bước 5: Phân chia dữ liệu
Chúng ta sử dụng thư viện train_test_split để tiến hành phân chia dữ liệu thành hai tập training và testing. Giống như bao bài toán khác 
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(images, y_data, test_size=0.2)
Bước 6: Training thuật toán
Giờ là lúc chúng ta dạy cho mô hình biết được đâu là boss và đâu không phải là boss rồi đấy. Có một lưu ý là do mạng Mobilenet là một hàm khá lớn dù là 2 classs nhưng số lượng tham số cũng lên đến 3,230,914 nên chúng ta cần sử dụng nhiều dữ liệu hơn để tránh bị Overfiting khiến cho mô hình kém hiệu quả. Dù sao thì dữ liệu vẫn là yếu tố quan trọng nhất phải không các bạn. Tiếp theo chúng ta cần complie mô hình
Complie mô hình
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
Đặt checkpoint
Việc đặt checkpoint rất quan trọng trong quá trình training mô hình. Giúp chúng ta lưu lại được mô hình tốt nhất theo một tiêu chí nào đó ví dụ như val_loss hay val_accuracy cũng là cách để chúng ta phòng tránh trường hợp đang training thì mất điện hay muốn training tiếp trong lần sau mà không cần training lại từ đâu. Tóm lại là phải viết checkpoint vào không mất mô hình đừng kêu 
from keras.callbacks import ModelCheckpoint
model_file = "boss_model/model_mobilenet.hdf5"
checkpoint = ModelCheckpoint(model_file, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
Training
Sau cùng là bước training
model.fit(x=X_train, y=y_train, batch_size=16, epochs=100, verbose=1, validation_data=(X_test, y_test), callbacks=callbacks_list)
Các bạn cứ đợi và theo dõi thôi nhé. Do tập dữ liệu của mình nhỏ khoảng 750 ảnh nên việc training cũng sẽ diễn ra rất nhanh thôi. Đây là kết quả training trên máy của mình sau vài epochs
Epoch 1/100
750/750 [==============================] - 5s 37ms/step - loss: 0.3298 - acc: 0.8667 - val_loss: 0.0221 - val_acc: 1.0000
Epoch 00001: val_loss improved from inf to 0.02205, saving model to boss_model/model_mobilenet.hdf5
Epoch 2/100
750/750 [==============================] - 3s 7ms/step - loss: 0.0143 - acc: 0.9600 - val_loss: 0.0159 - val_acc: 0.9465
Epoch 00002: val_loss improved from 0.02205 to 0.01592, saving model to boss_model/model_mobilenet.hdf5
Epoch 3/100
750/750 [==============================] - 3s 7ms/step - loss: 0.0017 - acc: 0.9952 - val_loss: 0.0027 - val_acc: 0.9815
Bước 7: Chuẩn bị mô hình cho deploy
Lưu mô hình
Sau khi tiến hành traininig lại mô hình nhiều lần chúng ta sẽ thu được một mô hình tốt nhất và sử dụng nó để deploy lên hệ thống thực. Việc này được thực hiện như sau:
model.save('boss_model/final_model.h5')
Load lại mô hình
Và sau đó các bạn thử load lại mô hình này và predict một vài mẫu dữ liệu xem sao nhé:
from keras.models import load_model
import keras
from keras.utils.generic_utils import CustomObjectScope
# Load pretrained model
with CustomObjectScope({'relu6': keras.applications.mobilenet.relu6,'DepthwiseConv2D': keras.applications.mobilenet.DepthwiseConv2D}):
model = load_model('./boss_model/final_model.h5')
Một lưu ý là chúng ta cần phải chạy qua các bước tiền xử lý khi dự đoán, giống hệt lúc chúng ta training.
Bước 8: Deploy bằng OpenCV
Xử lý model để dự đoán
Việc đầu tiên cần làm là Tạo file boss_model.py. Chúng ta sử dụng file này để load model đã được lưu từ các bước trên bao gồm cả các hàm về xử lý dữ liệu và dự đoán kết quả
import cv2
import keras
import numpy as np
from keras.models import load_model
from keras.preprocessing import image
from keras.utils.generic_utils import CustomObjectScope
# Load pretrained model
with CustomObjectScope({'relu6': keras.applications.mobilenet.relu6,'DepthwiseConv2D': keras.applications.mobilenet.DepthwiseConv2D}):
model = load_model('./model/model.h5')
IMAGE_SIZE=224
def prepare_image(img):
img_array = image.img_to_array(img)
img_array_expanded_dims = np.expand_dims(img_array, axis=0)
return keras.applications.mobilenet.preprocess_input(img_array_expanded_dims)
def predict(img):
"""
Predict face crop from frame
:param img:
:return: If boss is appear when open the code IDE
"""
try:
img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE), interpolation=cv2.INTER_AREA)
probs = model.predict(prepare_image(img))
is_boss = np.argmax(probs[0])
return is_boss
except:
return False
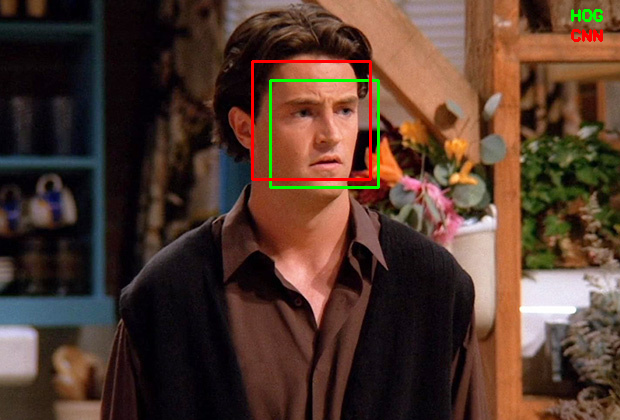
Detect khuôn mặt bằng dlib
Giống như mô tả ở phái đầu tiên của bài viết, trong quá trình dự đoán chúng ta cần phải detect khuôn mặt và sử dụng một thư viện rất nổi tiếng đó là dlib. Quá trình xử lý của nó như sau:
import dlib
hog_face_detector = dlib.get_frontal_face_detector()
faces_hog = hog_face_detector(image)
Kết quả của nó như sau:
Sử dụng OpenCV để stream dữ liệu từ Webcam
Chúng ta cần sử dụng dữ liệu stream từ webcam để theo dõi sếp và phát hiện ra khi nào sếp đến gần một cách tức thời. Việc này có thể thực hiện bằng cách sử dụng webcam và OpenCV để stream dữ liệu. Về cơ bản chúng ta có thể thực hiện nó như sau :
import cv2
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if ret:
# Excute frame here
cv2.imshow("frame", frame)
key = cv2.waitKey(1)
if key == 27:
break
cap.release()
cv2.destroyAllWindows()
Xử lý crop mặt và dự đoán
Chúng ta sẽ crop từng khuôn mặt trong từng frame và dự đoán kết quả. Nếu là boss thì thực hiện mở ngay cửa sổ code
if ret:
# Resize window
cv2.namedWindow('frame', cv2.WINDOW_NORMAL)
cv2.resizeWindow('frame', 400, 400)
# Resize frame for decrease predict time
scale = 0.5
resize_frame = cv2.resize(frame, (int(frame.shape[1]*scale), int(frame.shape[0]*scale)))
faces_hog = hog_face_detector(resize_frame)
frame_h, frame_w, _ = frame.shape
reindex_x = lambda x: max(min(x, frame_w), 1)
reindex_y = lambda x: max(min(x, frame_h), 1)
# loop over detected faces
for face in faces_hog:
x = reindex_x(int(face.left() / scale))
y = reindex_y(int(face.top() / scale))
r = reindex_x(int(face.right() / scale))
b = reindex_y(int(face.bottom() / scale))
# draw box over face
crop_face = frame[x: r, y: b]
is_boss = predict(crop_face)
if is_boss:
cv2.putText(frame, "BOSS", (10, 100), cv2.FONT_HERSHEY_SIMPLEX, 2,
(0, 0, 255), 4)
cv2.rectangle(frame, (x, y), (r, b), (0, 0, 255), 2)
boss_count += 1
# Open your IDE application for coding
if boss_count > 3:
os.system('open -a "PyCharm CE"')
boss_count = 0
else:
cv2.putText(frame, "NORMAL", (10, 100), cv2.FONT_HERSHEY_SIMPLEX, 2,
(0, 255, 0), 4)
cv2.rectangle(frame, (x, y), (r, b), (0, 255, 0), 2)
Mọi người có thể tham khảo kĩ hơn source code trong file này tại đây
Source code
Các bạn có thể tham khảo source code của bài viết tại đây
Cảm ơn các bạn đã theo dõi bài viết hẹn gặp lại trong những bài viết tiếp theo.
All rights reserved
