
Modern Recommendation Systems in Real Application
Bài đăng này đã không được cập nhật trong 6 năm
"Vấn đề" của các hệ thống lớn hiện nay
Chúng ta đang sống trong những ngày tháng mà thông tin người dùng và các vấn đề liên quan đến nó luôn được chú ý tới một cách vô cùng đặc biệt. Khi mà trí tuệ nhân tạo đang ngày một thông minh, nó giúp cho chúng ta có khả năng hiểu rõ người dùng hơn bất cứ ai. Hãy nghĩ lại một chút về vấn đề này, ngay cả những người thân với bạn nhất có lẽ cũng đang gặp khó khăn khi nghĩ đến việc "Bạn thích nghe thể loại nhạc nào? Thích nghe ca sỹ nào? Các bài đăng và tin tức mà bạn quan tâm tới là gì?.." và quan trọng nhất "BẠN ĐANG CẦN GÌ". Thế nhưng giờ đây, bạn không cần phải nghĩ quá nhiều xem nên nghe bài hát nào khi vào Youtube, bởi chúng đã gợi ý ra được cho bạn rất nhiều nội dung. Facebook, Instagram thường xuyên update cho bạn những bài đăng mà khả năng rất cao là bạn cũng quan tâm tới thông tin này. Netflix biết rõ bạn thích xem loại phim nào để đưa ra gợi ý hay Tiki thường xuyên quảng cáo đúng những thứ mà bạn đang cần tìm mua. Tất cả những khả năng "vi diệu ấy" đều xuất hiện chỉ sau 1 vài lần chúng ta sử dụng các hệ thống này. Chính vì vậy, giờ đây mỗi thông tin dù là nhỏ nhất lại càng có giá trị hơn, điều này được chứng minh qua sự quan tâm lớn của thế giới dành cho những vụ lùm xum, kiện tụng về việc để lộ thông tin cá nhân của một số tổ chức.
Mọi thông tin giờ đây đều quý như vàng, thế nhưng quá nhiều thông tin lại khiến cho chúng ta thật sự phải đau đầu. Hãy nhìn vào 1 vài thông số thông kê tính tới đầu năm 2019 của một số hệ thống sau đây.

Hãy lấy ví dụ với Youtube, giờ đây, khi một bản MV của một ca sỹ nào đó được tung lên, làm sao để người ta có thể tiếp cận được với video này khi mà cùng thời điểm đó, có tới 300 giờ video khác cũng được đăng tải mỗi phút. Không người dùng nào có thể xem hết được toàn bộ thời lượng của các video này và trong số hàng tỷ người dùng kia, mỗi người sẽ có những sở thích khác nhau và đối với mỗi người, 99,99% nội dung ở trên đó là không phù hợp với họ. Tương tự là vấn đề của Amazon, một người dùng không thể lướt qua toàn bộ cả trăm triệu sản phẩm khi mua sắm. Việc này có lẽ sẽ tiêu tốn của họ cả ... vài năm.
Việc người dùng bị "bội thực" thông tin như trên đã dẫn đến sự quan trọng của các hệ thống gợi ý (Recommendation System) trong các hệ thống/ ứng dụng hiện nay.
Recommendation System
Cụm từ Recommendation System chắc hẳn cũng không còn quá "lạ tai" với đa phần mọi người hiện nay nữa. Để nói một cách đơn giản, ý tưởng và nhiệm vụ chính của một Recommendation System là tối ưu hóa lượng thông tin khổng lồ nhằm đưa đến cho người dùng những thứ phù hợp nhất với họ. Điểm mấu chốt ở đâu, là nó sẽ phải tìm ra được mối quan hệ của từng người dùng với từng sản phẩm (item) dựa trên những thói quen, lựa chọn của họ trong quá khứ, thuộc tính của sản phẩm đó,.. để có thể gợi ý cho họ những thứ phù hợp trong tương lai. Ví dụ như một người dùng có sở thích là về các video lịch sử sẽ có khả năng cao rằng sẽ thích thú với một video về lịch sử khác hoặc một video về nội dung giáo dục hơn là một bộ phim hành động. Những điều tương tự như thế đều sẽ là kết quả của một hệ thống gợi ý.
Mục tiêu của một hệ thống gợi ý
Đọc đến đây, thì có lẽ ai cũng sẽ hiểu rằng mục đích cơ bản nhất của hệ thống gợi ý đó là giúp tăng doanh thu cho trang web, tăng trải nghiệm của người dùng.. cuối cùng vẫn quy về vấn đề tăng lợi nhuận. Bằng việc gợi ý hiệu quả những sản phẩm (item) cho tuỳ từng người dùng, nó sẽ giúp người dùng cảm thấy thuận tiện, thích thú hơn. Tuy nhiên, mục đích lợi nhuận thường sẽ là kết quả của việc mang lại cho người dùng những điều sau:
- Sự liên quan: Đây chắc chắn là mục đích dễ thấy nhất của một hệ gợi ý. Người dùng sẽ truy cập/ sử dụng/ mua những thứ liên quan tới sở thích, thói quen của họ.
- Sự mới lạ: Một hệ gợi ý hiệu quả sẽ đưa ra được những sản phẩm liên quan tới người dùng mà họ chưa từng thấy bao giờ trong quá khứ. Việc gợi ý những sản phẩm hot, trending sẽ ít mang lại cảm giác mới lạ cho người sử dụng và dẫn tới việc mất cân bằng và sự phong phú về mặt sản phẩm của hệ thống.
- Sự bất ngờ: Một mức độ cao hơn của mới lạ, khi mà sản phẩm được gợi ý không chỉ chưa từng được người dùng biết đến mà còn gây bất ngờ cho họ. Có thể hiểu đơn giản hơn là những sự liên quan mà người dùng không hề biết tới. Ví dụ như đối với một người thích và thường xuyên ăn đồ ăn Trung Quốc, việc hệ thống gợi ý cho họ một cửa hàng đồ ăn Trung Quốc mà họ chưa từng tới được đánh giá là mới lạ nhưng sẽ không có bất ngờ. Trong trường hợp nếu hệ thống gợi ý có thể đưa ra đề xuất về một cửa hàng chuyên về các món ăn truyền thống của Việt Nam sẽ được gọi là có sự bất ngờ. Tất nhiên, sự bất ngờ ở đây cũng phải được tính toán rất cẩn thận thông qua các thông tin để đảm bảo rằng người dùng sẽ có khả năng cao có hứng thú với sản phẩm này.
- Sự phong phú: Trước đây, các hệ thống gợi ý thường sẽ đưa ra một danh sách top-k các sản phẩm rất liên quan tới nhau để gợi ý cho người dùng. Điều này có nguy cơ dẫn tới một khả năng là người dùng sẽ không thích bất cứ một cái nào ở trong danh sách trên. Nói cách khác, sự phong phú tăng xác suất trong việc người dùng chắc chắn sẽ thích ít nhất một sản phẩm từ danh sách đó, không gây nhàm chán cho họ bởi những sản phẩm giống nhau lặp đi lặp lại.
Không phải hệ thống nào cũng giống nhau
Trong bài viết này, cụm từ "sản phẩm hay item" được xuất hiện khá nhiều. Tuy nhiên đối với từng hệ thống mà sản phẩm ở đây sẽ có thể được hiểu theo một nghĩa khác nhau, tùy vào mục đích. Có thể kể ra như Amazon hay Tiki hay một số trang web thương mại điện tử, thì sản phẩm ở đây chính là những hàng hóa mà họ cần bán. Tuy nhiên đối với Youtube hay Netflix, đó lại là những video. Hay đối với Google News thì đó lại là các tin tức. Còn với Spotify thì đó là các bản nhạc.
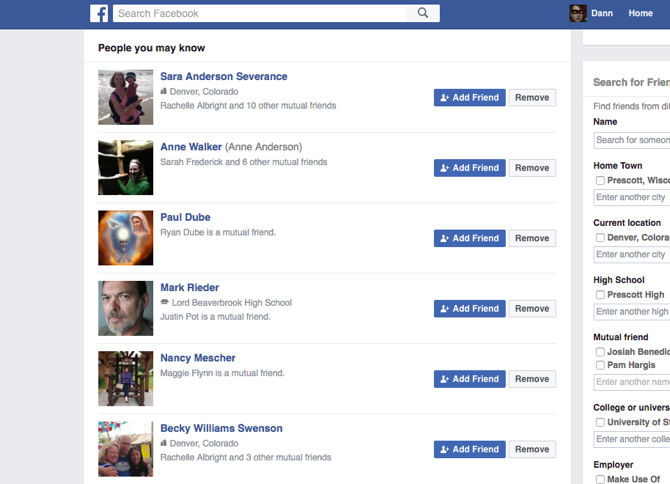
Facebook hay một số trang mạng xã hội khác lại thường đưa ra gợi ý cho người dùng về "những người bạn có thể biết" nhằm tăng số lượng kết nối mạng xã hội của mình. (Đây là một dạng gợi ý mà mục đích của nó không phải trực tiếp mang lại lợi nhuận như những trang web khác, tuy nhiên sự thành công của một mạng xã hội phụ thuộc rất nhiều vào số lượng kết nối của các người dùng).
Làm sao để có được một hệ thống gợi ý
Một cách tổng quan nhất, hệ thống gợi ý thông thường sẽ được xây dựng dựa trên các bước sau
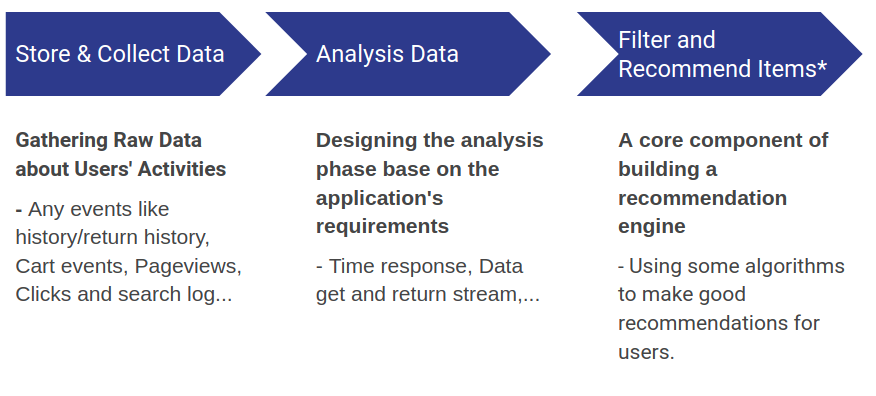
Lưu trữ và thu thập thông tin/ dữ liệu
Một hệ thống gợi ý cần các thông tin để trở nên hiệu quả. Thông tin ở đây là mọi thứ liên quan tới người dùng và sản phẩm ví dụ như lịch sử truy cập/ mua sắm người dùng, thời lượng truy cập, thời gian truy cập, các event khác như click hay tìm kiếm cũng đều là thông tin quý giá. Vậy nên bước đầu tiên luôn là thu thập và lưu trữ lại toàn bộ những dữ liệu này.
Phân tích dữ liệu
Tại bước này, tùy vào tình hình tình tế của lượng dữ liệu ta đã thu thập được, cũng như dựa vào mong muốn, mục đích của hệ thống, chúng ta sẽ cần phân tích thật kỹ để có thể thiết kế ra một luồng xử lý hiệu quả dành riêng cho hệ gợi ý của mình.
Thuật toán lọc và đưa ra gợi ý
Để có được một hệ gợi ý hiệu quả, sẽ cần phải có rất nhiều thành phần và các kỹ thuật khác (gửi nhận dữ liệu, lấy các thông tin có sẵn,..), tuy nhiên phần lõi của chúng luôn là một vài thuật toán nhằm xử lý tốt nhất được các dữ liệu đó. Trong phần tiếp theo, chúng ta sẽ cùng tìm hiểu kỹ lưỡng một vài phương pháp phổ biến nhất hiện nay đang được sử dụng bởi các hệ thống lớn trên thế giới.
Hiệu quả của việc sử dụng các hệ thống gợi ý
Một vài thông số do chính các hệ thống công bố vào nửa đầu năm nay có thể sẽ nói lên mức độ hiệu quả của việc áp dụng hệ thống này

Ngoài ra, các bạn quan tâm có thể dễ dàng đọc được những thông số này ở trên các phương tiện truyền thông, thông tin đại chúng. Những con số đang nói lên tầm quan trọng tới mức không thể thiếu của các hệ gợi ý vào thời điểm này.
Một vài phương pháp đang sử dụng trong các hệ thống hiện nay
Đây được coi là phần quan trọng nhất của một hệ thống gợi ý. Là một người nghiên cứu về học máy và trí tuệ nhân tạo, mình cũng rất tò mò về cách mà các hệ thống có thể thấu hiểu được người dùng, vậy nên recommendation system cũng là một trong những phần mình đã bỏ kha khá thời gian để tìm tòi và đọc về chúng. Trong lĩnh vực trí tuệ nhân tạo bây giờ, có khá nhiều phương pháp được đề xuất ra dành cho việc gợi ý này, tuy nhiên hôm nay chúng ta hãy cùng xem qua 4 thuật toán mà mình cho là phổ biến nhất, được áp dụng nhiều nhất trong các hệ thống lớn trên thế giới.
Content - Based Recommendation System (Gợi ý dựa vào nội dung)
Đây là một trong những thuật toán cơ bản và dễ áp dụng nhất của hệ gợi ý. Cụm từ "nội dung" ở đây được hiểu là "mô tả về sản phẩm". Hệ thống sẽ cố gắng tìm và gợi ý những sản phẩm có độ tương đồng với những thứ đã được sử dụng trong quá khứ. Ví dụ, một người dùng đã mua một vài quyển sách "Sherlock Holmes" - cùng thể loại sách trinh thám với "Mật mã Davinci" và "Sự im lặng của bầy cừu". Trong trường hợp này, thuật toán sẽ đưa ra gợi ý là những quyển sách trên cho người dùng đó.
Nói đến đây, có lẽ chúng ta sẽ quan tâm hơn tới việc làm thế nào để hệ thống có thể hiểu được sự tương đồng giữa các sản phẩm nhau.
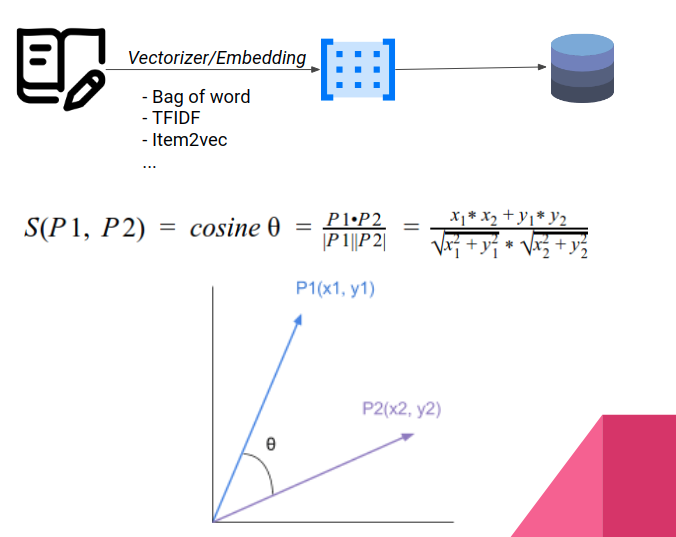
Trong học máy, có thể nói rằng mọi thứ đều sẽ cần được ma trận hóa để phục vụ cho các công đoạn tính toán, tối ưu ở sau và trong bài toán này cũng không phải là ngoại lệ. Việc so sánh sự tương đồng giữa các sản phẩm sẽ được đưa về việc so sánh khoảng cách giữa 2 vector.
Để làm được điều này, có một vài thuật toán nhằm giúp chúng ta vector hóa các mô tả sản phẩm có thể nói là kinh điển như "Bag of words", "TFIDF" hay một số thuật toán Deep Learning phức tạp hơn "Item2vec". Mọi sản phẩm sẽ cần phải được chuyển sang dạng vector rồi lưu lại vào trong cơ sở dữ liệu. Với mỗi một nội dung mới cần được gợi ý, chúng ta sẽ so sánh để lấy ra những sản phẩm tương đồng nhất dựa trên khoảng cách vector rồi gợi ý ra cho người dùng.
- Ưu điểm: Có thể hoạt động tốt với những hệ thống có ít thông tin, dữ liệu của người dùng
- Nhược điểm: Cần phải hiểu về các thuật toán vector hóa các sản phẩm và áp dụng một cách chính xác
Clusting User (Phân cụm người dùng)
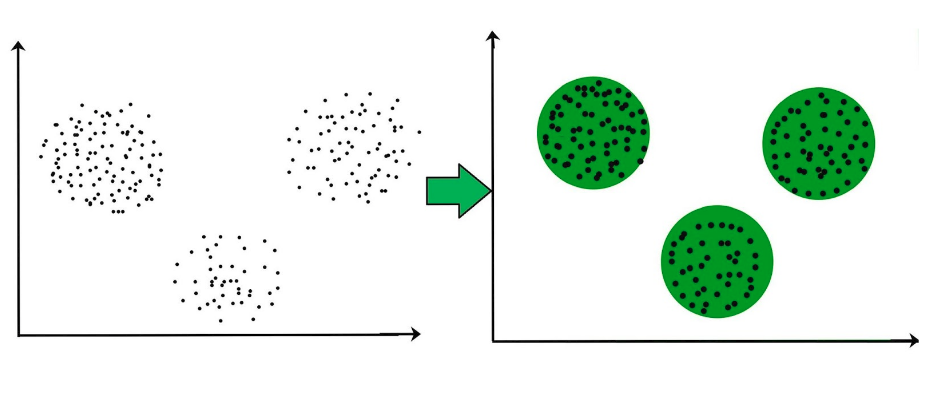
Thuật toán này được xây dựng dựa trên sự tương đồng trong sở thích của chúng ta. Đơn giản là số người dùng thì rất nhiều, nhưng số lượng sở thích thì có lẽ sẽ ít hơn rất rất nhiều. Với số lượng người dùng lớn, việc hệ thống gợi ý phải chạy lần lượt rồi đưa gợi ý cho từng người dùng là một công việc rất nặng nhọc. Nếu dựa vào nhận xét trên, thay vì gợi ý cho từng người, hệ thống sẽ cố gắng phân nhóm người dùng trên hệ thống, rồi có những gợi ý chung cho toàn bộ nhóm người này. Việc phân nhóm tất nhiên cũng sẽ phải được làm rất cẩn thận dựa trên các thông tin và dữ liệu của họ. Một số thuật toán phân cụm cơ bản có thể dùng một cách hiệu quả trong bài toán này.
- Ưu điểm: Dễ dàng áp dụng, hệ thống hoạt động nhanh
- Nhược điểm: Thuật toán không hoạt động với những người mới hay những sản phẩm mới được đưa vào hệ thống (Phải tiến hành phân cụm lại)
Collaborative Filtering (Lọc cộng tác)
Thuật toán tạo ra và sử dụng một ma trận về "đánh giá" của toàn bộ người dùng đối với toàn bộ sản phẩm để đưa ra gợi ý. Trên một hệ thống, mỗi người dùng sẽ đánh giá rất cao một vài sản phẩm và đánh giá thấp một số sản phẩm khác. Phương pháp này muốn làm một việc cơ bản đó là tính ra điểm đánh giá của từng người dùng đối với những sản phẩm chưa có thông tin đánh giá (chưa từng xem) của họ.
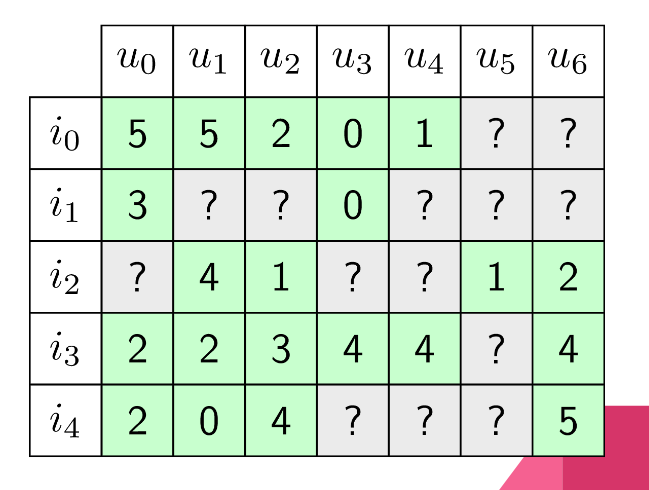
Trên là một ví dụ về một ma trận sử dụng cho thuật toán lọc cộng tác của một hệ thống gồm 7 người dùng (u0 -> u6) và có 5 sản phẩm (i0 -> i4). Người dùng sẽ cho đánh giá từ 0 -> 5 với một sản phẩm mà họ đã sử dụng (0 được coi là trải nghiệm tệ nhất, 5 là tuyệt vời nhất). Những dấu "?" thể hiện cho việc chưa có thông tin đánh giá của người dùng về sản phẩm đó và đây cũng là những chỗ mà thuật toán cần phải tính ra để đưa ra gợi ý. Trong ví dụ trên, nếu như hệ thống tính toán ra rằng điểm đánh giá của u3 dành cho i2 sẽ ở mức 1 hoặc 2 còn đánh giá của u3 dành cho i4 lại có thể là 4 hoặc 5 thì việc hệ thống đề xuất cho u3 sản phẩm i4 sẽ là hợp lý hơn rất nhiều.
Có nhiều công thức để tính ra những điểm trống này, tuy nhiên nó dựa nhiều vào số lượng các ô đã được điền. Càng nhiều ô đã được điền, tỷ lệ tính toán chính xác sẽ càng cao. Tuy nhiên việc này lại là thách thức lớn nhất với lọc cộng tác, khi mà giờ đây, các hệ thống lớn thường có cả trăm triệu sản phẩm, trăm triệu người dùng, tuy nhiên mỗi sản phẩm lại chỉ được đánh giá bởi vài người cũng như số lượng đánh giá của mỗi người cũng là không đáng kể cho với số lượng sản phẩm hệ thống đang có.
- Ưu điểm: Một trong những thuật toán dễ hiểu nhất nhưng lại mang lại hiểu quả cao nhờ vào tính logic của nó
- Nhược điểm: Cần quá nhiều dữ liệu đánh giá của người dùng
Session - Based Recommendation System (Gợi ý theo chuỗi hoạt động)
Session ở đây được định nghĩa là chuỗi hoạt động của người dùng. Thuật toán này chứng minh rằng thói quen cũng mỗi người có vẻ như sẽ giống nhau. Ví dụ như khi hệ thống quan sát thấy và ghi nhận được có rất nhiều người sau khi xem hai bộ phim là "Người phán xử" và "Sống chung với mẹ chồng" thì sẽ tiếp tục xem bộ phim "Về nhà đi con" (giả sử như chúng ta không sử dụng bất cứ thông tin nào về bộ phim như thể loại, diễn viên...). Từ đó, nếu có một người dùng khác vào hệ thống và xem xong 2 bộ phim này, việc hệ thống gợi ý ra "Về nhà đi con" gần như đạt được hiệu quả vô cùng cao.

Đây là một trong những cách mà Netflix hay Youtube hay Alibaba đang sử dụng cho hệ gợi ý của mình. Việc "học hỏi này" có thể dựa vào một số thuật toán cơ bản như thuật toán Markov hay áp dụng những mạng Deep Learning như** Recurrent Neuron Network** vào đây. Hiện nay, Session-base vẫn đang là một bài toán thu hút được rất nhiều sự quan tâm của các nhà khoa học và lập trình viên bởi tính hữu dụng của chúng. Hằng năm vẫn có rất nhiều nghiên cứu, cuộc thi được tổ chức ra liên quan tới vấn đề này.
- Ưu điểm: Không cần xác định danh tính người dùng (Chỉ cần lưu lại các chuỗi hoạt động của cùng 1 người) - Điều làm nên sự khác biệt, do người dùng đăng nhập hầu như chiếm số lượng rất ít trong các trang web.
- Nhược điểm: Không chạy được với một sản phẩm mới được đưa vào hệ thống.
Kết luận
Hy vọng bài chia sẻ đã giúp các bạn có một cái nhìn khác, cụ thể hơn về sự thần kỳ của các hệ thống thấu hiểu con người hiện nay. Trên đây chỉ là 4 trong số rất nhiều các phương pháp gợi ý.
Slide Vietnam Mobile Day 2019: https://docs.google.com/presentation/d/1-B0v1lJ6pgoVIXESlChtyfbRRphr7ZmnA0vZJayLQwI/edit#slide=id.g5acb3c4841_5_19
All rights reserved
