
Multi Task Learning - Một Số Điều Bạn Nên Biết
Bài đăng này đã không được cập nhật trong 5 năm
Multi Task Learning ( MTL) là một phương pháp không mới, tuy nhiên mức độ hiệu quả mà nó đem lại thì đã được một số đông những nhà nghiên cứu công nhận. Trong bài viết này, tôi sẽ giới thiệu khái quát về học đa nhiệm vụ bao gồm những động lực đằng sau việc sử dụng, lợi ích và một số phương pháp sử dụng Multi Task Learning trong Deep Learning trong đó chúng ta sẽ chỉ tập trung chủ yếu vào các nhiệm vụ phụ trợ - Auxiliary task.
I. Giới Thiệu:
Các phương pháp học máy truyền thống thường tập trung giải quyết một nhiệm vụ với một mô hình duy nhất. Điều này có thể khiến chúng ta bỏ qua những thông tin có thể giúp chúng ta thực hiện tốt hơn trên nhiệm vụ chúng ta quan tâm, đến từ những nhiệm vụ khác có liên quan tới nó. Lấy một ví dụ đơn giản khi bạn muốn dự đoán giá của một căn nhà dựa vào một số đặc trưng như diện tích, số lượng phòng, số tầng, có gần với các trung tầm thương mại nào hay không,.v..v.. thì rõ ràng việc thêm vào một vài nhiệm vụ như dự đoán căn nhà này thuộc vùng nội thành hay ngoại thành hoặc là biệt thự hay là chung cư sẽ đem lại chúng ta rất nhiều thông tin cho việc dự đoán giá của nó.

Figure 1: Thay vì chỉ dự đoán giá nhà, chúng ta có thể dự đoán những thông tin khác đem lại cho chúng ta những lợi ích cho việc dự đoán giá.
Xét về góc độ chuyên ngành, Multi Task Learning cho phép các nhiệm vụ cùng chia sẻ chung representation của dữ liệu, nhờ vậy mà chúng ta có thể thu được một mô hình có khả năng tổng quát hơn trên nhiệm vụ ban đầu mà chúng ta quan tâm.
Multi Task Learning còn được biết đến với một số tên gọi như Joint Learning, Learning to Learn, Learning with Auxiriary Task, mỗi khi chúng ta làm việc với một bài toán tối ưu có nhiều hơn một hàm mất mát, chúng ta ngầm định rằng chúng ta đang giải quyết một bài toán liên quan tới Multi Task Learning.
II. Động Lực:
Về mặt sinh học, học đa nhiệm vụ lấy cảm hứng từ cách con người học hỏi, khi chúng ta cần học để thực hiện một nhiệm vụ mới nào đó, chúng ta thông thường áp dụng những tri thức mà chúng ta đã thu được thông qua việc học từ các nhiệm vụ liên quan. Ví dụ như một đứa trẻ sẽ học cách nhận biết đâu là khuôn mặt và sau đó có thể áp dụng những tri thức đó cho việc nhận dạng vật thể.
Ở góc độ sư phạm, chúng ta thường học những kỹ năng mà từ đó cung cấp nền tàng để chúng ta học hỏi những kỹ thuật phức tạp hơn. Cuối cùng ở dưới góc độ của học máy, Multi Task Learning cung cấp một inductive bias trong đó sẽ thiên vị những mô hình có thể giải quyết nhiều hơn môt nhiệm vụ.
III. Lợi Ích:
Hãy giả sử rằng chúng ta có 2 nhiệm vụ có liên quan tới và , tôi sẽ đưa ra một số lợi ích của Multi Task Learning khi học đồng thời cả và .
III.1. Data Augmentation
Học đa nhiệm một cách hiệu quả tăng kích thước tập mẫu chúng ta dùng cho quá trình huấn luyện. Bởi vì mỗi nhiệm vụ đều chứa nhiễu ( noise ) ở một mức độ nào đó. Khi huấn luyện mô hình trên nhiệm vụ , mục tiêu của chúng ta là tìm một representation cho A, thứ một cách lý tưởng sẽ là tốt nếu nó tổng quát và độc lập với nhiễu. Bởi vì các nhiệm vụ đều có chứa các noise paterns khác nhau, một mô hình học 2 nhiệm vụ đồng thời sẽ có khả năng học được một representation tổng quát hơn. Việc học sẽ có rủi ro overfitting A, trong khi đó việc học đồng thời cả và cho phép mô hình học được một biểu diễn tốt hơn thông qua việc lấy trung bình các noise paterns cũng mỗi nhiệm vụ.
III.2. Attention Focusing
Nếu một nhiệm vụ chứa rất nhiều noise, hoặc dữ liệu bị giới hạn và nằm trong không gian có số chiều cao. Sẽ là rất khó để mô hình của chúng ta phân biệt được đâu là những đặc trưng liên quan và không liên quan. Học đa nhiệm có thể giúp mô hình tập trung sự chú ý của nó vào những đặc trưng quan trọng thật sự, bởi vì các nhiệm vụ khác sẽ cung cấp những thông tin hữu ích cho việc phát hiện đâu là đặc trưng quan trọng và đâu là không quan trọng,
III.3. Eavesdropping
Một số đặc trưng có thể rất dễ để được học bởi nhiệm vụ trong khi lại rất khó để có thể học được nó, điều này sẽ xa khi tương tác với những đặc trưng đó theo một cách rất phức tạp, hoặc việc học những đặc trưng khác đang ngăn cản khả năng học đặc trưng đó của . Thông qua MTL, chúng ta có thể học những đặc trưng rất khó để học với , thông qua . Một cách hữu hiệu để thực hiện đó là chúng ta sẽ trực tiếp huấn luyện mô hinh để dự đoán những đặc trưng quan trọng.
III.4 Representation bias
MTL thiên vị những representation không chỉ hữu ích trên một nhiệm vụ cụ thể, mà là trên nhiều nhiệm vụ khác nhau. Điều này cho phép chúng ta tổng quát hóa trên một lớp các nhiệm vụ, thực hiện tốt trên một tập hợp nhiều nhiệm vụ sẽ cho chúng ta khả năng thực hiện tốt cả trên cả một nhiệm vụ mới trong tương lai, chừng nào các nhiệm vụ này còn chia sẽ chung môi trường.
III.5 Regularization
MTL có khả năng giảm overfitting nhờ thiên vị các biểu diễn hữu ích trên nhiều nhiều nhiệm vụ, vì vậy khả năng mô hình quá fit vào một nhiệm vụ nào đó sẽ giảm đi.
IV. Multi Task Learning trong Neural Network:
MTL có rất nhiều cách sử dụng khác nhau, tuy nhiên trong context của Deep Learning, tôi chỉ xin phép giới thiệu 2 phương pháp đó là: Hard Parameter Sharing và Soft Parameter Sharing.
IV.1. Hard Parameter Sharing.
Hard Sharing là một phương pháp được sử dụng rất nhiều trong Neural Network. Nó được thực hiện bằng cách chia sẽ các lớp hidden ở trên tất cả các nhiệm vụ, trong khi chỉ giữ các lớp output layer là khác nhau.
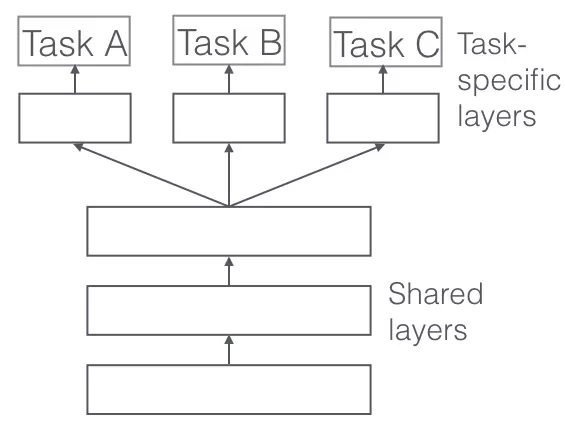
Figure 2: Hard Parameter Sharing.
Hard parameter sharing giảm overfitting rất tốt. việc chia sẽ các hidden layer giữa các nhiệm vụ sẽ ép buộc mô hình của chúng ta phải học những biểu diễn tổng quát thích hợp ở trên nhiều nhiệm vụ, nhờ vậy mà khả năng overfitting vào một nhiệm vụ cụ thể nào đó sẽ giảm đi rất nhiều.
IV.2. Soft Parameter Sharing.
Soft Parameter Sharing thì khác biệt hoàn toàn, mỗi nhiệm vụ sẽ có mô hình riêng, cũng như tham số riêng của nó, tuy nhiên khoảng cách của các tham số giữa các nhiệm vụ sau đó sẽ được ràng buộc để khiến các tham số này có mức độ tương đồng cao giữa các nhiệm vụ. Ở đây chúng ta có thể sử dụng các Norm để constraint.
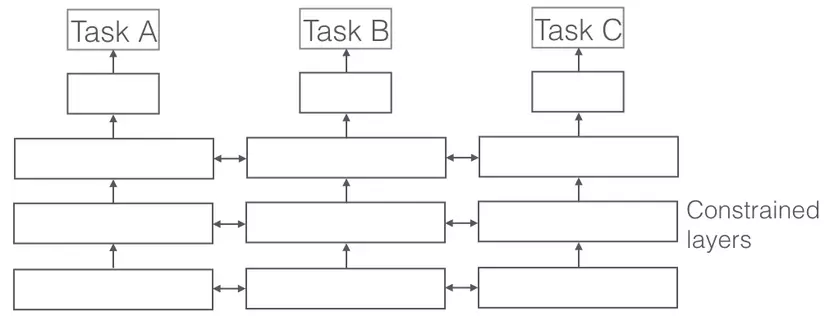
Figure 3: Soft Parameter Sharing.
Nếu các bạn đã nghe tới Ridge Regression thì phương pháp này có khá nhiều điểm tương đồng với nó, chỉ khác rằng Ridge Regression ràng buộc cường độ tham số, còn Soft Parameter Sharing sẽ ràng buộc khoảng cách.
V. Auxiliary task:
Trong nhiều trường hợp, chúng ta chỉ quan tâm tới hiệu suất của một nhiệm vụ cụ thể, tuy nhiên chúng ta lại muốn tận dụng được những lợi ích mà MTL mang lại, những trường hợp thế này chúng ta có thể thêm vào một số nhiệm vụ liên quan tới nhiệm vụ chính mà chúng ta quan tâm với mục đích là cải thiện thêm hiệu suất trên nhiệm vụ chính . Các nhiệm vụ này được gọi là các nhiệm vụ phụ trợ - Auxiliary task.
Việc sử dụng các Auxiliary task như thế nào so với Main task là vấn đề đã được nghiên cứu từ lâu, tuy nhiên không có bằng chứng lý thuyết chắc chắn việc sử dụng các Auxiliary task nào sẽ đem lại sự cải thiện cho Main task. Dưới đây tôi sẽ chỉ ra một vài gợi ý có từ thực nghiệm của các nghiên cứu trước đó liên quan tới cách sử dụng các Auxilirary task như thế nào cho hiệu quả.
V.1. Share Layers. But Share What ?
Đây là một câu hỏi đã được đặt ra từ lâu, các nghiên cứu trước đó chỉ ra rằng, các low-level task ( như là POS Tagging hay NER) nên được sử dụng tại các layer thấp nhất, ngược lại các high-level task yêu cầu nhiều thông tin hơn có thể được sử dụng ở các layer cao nhất ( như là Chunking, Dependency Parsing hay Relation Extraction).
Cụ thể là Sogaard, A. and Goldberg 2016 chỉ ra rằng việc sử dụng POS ở những layer thấp hơn sẽ đem đến những cải thiện trong hiệu suất của Chunking ( cái này mình đã làm để confirm và thấy nó chính xác). Trong khi đó Hashimoto et al. 2017 xây dựng một mô hình phân tầng theo cấp độ ngôn ngữ học cho một tập hợp các nhiệm vụ NLP khác nhau.
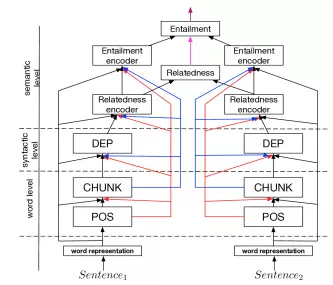
Figure 3: Kiến trúc phân tầng do Hashimoto đề xuất.
V.2. Weighted Loss
Khi chúng ta làm việc với MTL, tức là khi chúng ta đang làm việc vơi nhiều hơn một loss function, vì hàm mất mát cuối cùng là một weighted sum của các loss function thành phần.
Trong đó là trọng số của mỗi loss function. Việc chọn trọng số như thế nào là một công việc quan trọng, đơn giản nhất là các bạn có thể chọn với là một hằng số bất kỳ náo đó có thể được tìm kiếm bằng cross validation.
V.3. Một số loại Auxiliary Task thường dùng.
Các nhiêm vụ phụ trợ cụ thê có thể tùy biến khác nhau, tuy nhiên nhìn chung thì tất cả các Auxiliary Task có thể được phân nhóm thành 4 loại sau đây.
Statistical: Đây là các nhiệm vụ phụ trợ đơn giản nhất, chúng ta sẽ sử dụng các nhiệm vụ dự đoán các tính chất thống kê của dữ liệu như là Auxiliary Task. ví dụ như dụ đoán Log Freqency của một từ, Pos Tag, v..v
Selective Unsupervised:: Đây là những nhiệm vụ yêu cầu chúng ta dự đoán một phần của đầu vào, cụ thể như trong Sentiment Analysis ta có thể dự đoán xem khi nào câu chứa một từ Positive Sentiment hay Negative Sentiment Word.
Supervised: Các nhiệm vụ này có thể là các nhiệm vụ kiểu đối đầu ( Adversarial Task ) hoặc các nhiệm vụ nghịch đảo (Inverse Task) hoặc là các nhiệm vụ giám sát có liên quan tới dữ liệu (ví dụ Predict Inputs chảng hạn).
Unsupervised: Đây là những nhiệm vụ liên quan tới dự đoán tất cả các phần của dữ liệu đầu vào.
VI. Kết Luận:
Multi Task Learning là một phương pháp không mới, tuy nhiên hiệu quả mà nó đem lại thì thật sự không cần phải bàn cãi. Trên đây chỉ là một chút giới thiệu của mình về MTL, các bạn muốn hiểu sâu hơn có thể tham khảo Phd Thesis dưới đây để có thêm những thông tin cụ thể hơn. Lần tới có lẽ mình sẽ giới thiệu về một phương pháp khá gần với MTL đó là Sequential Learning, hi vọng các bạn sẽ ủng hộ và theo dõi.
VII. Tham Khảo.
https://ruder.io/thesis/neural_transfer_learning_for_nlp.pdf
All rights reserved
