
Chấm phiếu điền trắc nghiệm bằng OpenCV và Deep Learning
Bài đăng này đã không được cập nhật trong 8 năm
Phiếu trắc nghiệm không phải lúc nào cũng có dạng chuẩn..?
Thi trắc nghiệm đã và đang trở thành xu hướng bởi tính khách quan (Không phụ thuộc người chấm) của nó. Tuy nhiên, việc chấm một số lượng lớn bài thi trắc nghiệm đôi khi lại là một công việc không hề "hứng thú  " chút nào bởi đơn giản không phải ở đâu chúng ta cũng có được những máy chấm trắc nghiệm tự động để khiến cho công việc này trở nên nhanh chóng.Thông thường, một phiếu điền trắc nghiệm sẽ có dạng như sau:
" chút nào bởi đơn giản không phải ở đâu chúng ta cũng có được những máy chấm trắc nghiệm tự động để khiến cho công việc này trở nên nhanh chóng.Thông thường, một phiếu điền trắc nghiệm sẽ có dạng như sau:
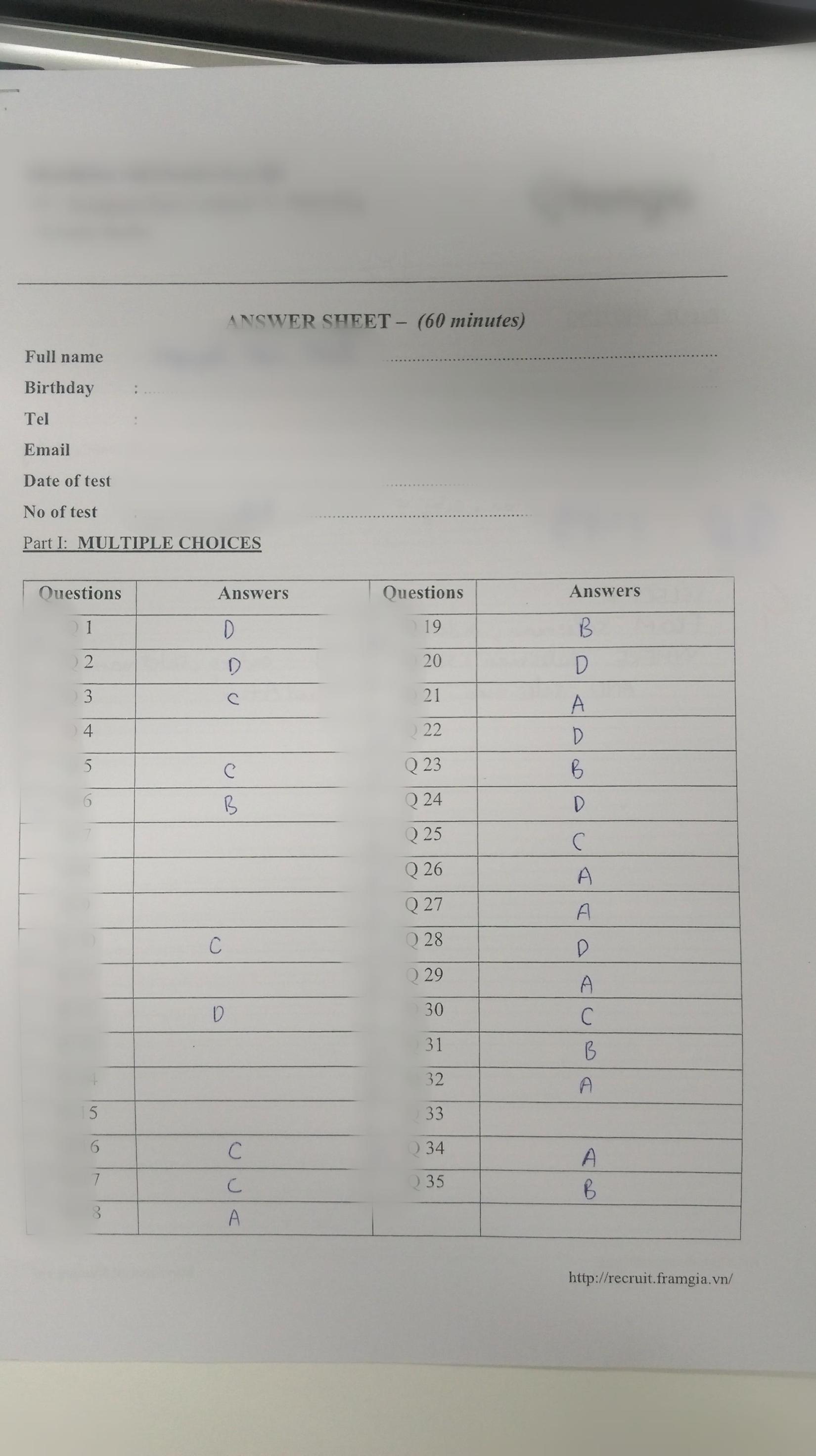
Người đọc được khuyến khích tìm hiểu về mô hình Deep Learning đơn giản thông qua bài viết sau trước khi đọc bài viết: https://viblo.asia/p/nhan-dang-chu-cai-viet-tay-su-dung-deep-learning-GrLZDwNJKk0
Mục tiêu
Có lẽ với tờ phiếu trắc nghiệm như trên, rất nhiều người sẽ chọn giải pháp là ngồi so đáp án và .. chấm thủ công bằng tay, tuy nhiên khi số lượng là không ít, thì đây có lẽ là phương án tồi nhất . Vậy ngày hôm nay, mình muốn viết bài này với mong muốn đưa ra 1 giải pháp giúp các bạn có thể giải quyết được vấn đề nêu trên bằng cách thử xây dựng một mô hình Deep Learning kết hợp với các phương pháp xác định đối tượng rất đơn giản.
Phương pháp tiếp cận bài toán
Đối với nhưng bài toán thực tế dạng này (Nhận diện biển báo giao thông cho xe không người lái, nhận diện chướng ngại vật, xác định vật thể, ..) bài toán của chúng ta sẽ được chia làm 2 bài toán nhỏ hơn:
- Bài toán xác định (Detection): Thực hiện các phương pháp xử lý ảnh (Resize, Threshold, ..) để có thể xác định được các vị trí của vật thể cần tìm trong ảnh/ video nhằm làm đầu vào cho bài toán Nhận dạng tiếp theo.
- Bài toán nhận dạng (Classification): Sử dụng các mô hình deep learning hoặc SVM để xác định/ nhận dạng các vật thể vừa xác định được nhằm đưa ra được kết quả.
Trong bài viết lần này, chúng ta sẽ sử dụng thư viện OpenCV để thực hiện bài toán đầu tiên, và sử dụng tflearn (1 thư viện xây dựng trên tensorflow) để xây dựng mạng deeplearning cho bài toán thứ hai.
Xây dựng mô hình thực tế
Sử dụng OpenCV cho bài toán Object Detection
Mục tiêu của phần này như đã nói ở trên, chúng ta sẽ xử lý ảnh qua các phương pháp thông thường để có thể xác định được chính xác vị trí của các đáp án trắc nghiệm mà thí sinh đã ghi lại.
Với bức ảnh như ở đầu bài viết, chúng ta có thể dễ thấy, các đáp án nằm gọn trong 1 ô của 1 bảng điền, mỗi dòng sẽ có 2 ô đặt cách khá đều nhau (kích thước cố định) và có 19 dòng kích thước như nhau ở trong bảng.
Nói đến đây, chắc hẳn chúng ta đã có phương án làm bài toán trở nên đơn giản hơn rất nhiều. Từ việc xác định vị trí của 36 ô đáp án, giờ chúng ta chỉ cần cố gắng xác định được tọa độ chính xác của bảng điền trong ảnh, sau đó chia tỷ lệ ra làm 19 lần theo chiều dọc là sẽ lấy được dòng và các đáp án! Một bài toán đơn giản hơn rất nhiều!
Và với bài toán xác định ví trí bảng như thế này, việc tìm ra các đường kẻ thẳng và ngang ở trong ảnh được cho là 1 phương án rất hiệu quả.
Hãy bắt đầu với việc đưa ảnh về binary bằng cách sử dụng hàm threshold của openCV
img = cv2.imread("./multiple_choice.jpg", 0)
blur = cv2.GaussianBlur(img,(5,5),0)
thresh = cv2.adaptiveThreshold(blur,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY_INV,11,2)
Ở đây, trước khi đưa vào hàm binary, mình có sử dụng thêm 1 hàm làm mờ, việc này giúp ảnh của chúng ta giảm được rất nhiều nhiễu, và khiến cho ảnh qua threshold được mịn hơn rất nhiều. Các hằng số mình truyền vào ở đây có ý nghĩa là làm cho ảnh đầu ra của mình đưa về dạng đen-trắng (nền đen, chữ trắng). Và đây là kết quả thu được

Đây là ảnh sẽ giúp cho những đoạn xử lý sau của chúng ta được đơn giản và độ chính xác cao hơn rất nhiều.
Giờ sẽ là lúc để xác định vị trí của các đường ngang và đường dọc trong ảnh
horizal = thresh
vertical = thresh
scale_height = 20 #Scale này để càng cao thì số dòng dọc xác định sẽ càng nhiều
scale_long = 15
long = int(img.shape[1]/scale_long)
height = int(img.shape[0]/scale_height)
horizalStructure = cv2.getStructuringElement(cv2.MORPH_RECT, (long, 1))
horizal = cv2.erode(horizal, horizalStructure, (-1, -1))
horizal = cv2.dilate(horizal, horizalStructure, (-1, -1))
verticalStructure = cv2.getStructuringElement(cv2.MORPH_RECT, (1, height))
vertical = cv2.erode(vertical, verticalStructure, (-1, -1))
vertical = cv2.dilate(vertical, verticalStructure, (-1, -1))
mask = vertical + horizal
Cùng nhìn qua một chút, ban đầu, chúng ta sẽ lấy ra 2 ảnh từ ảnh thresh gốc, sau đó, xác định cấu trúc của các ảnh với hàm getStructuringElement của OpenCV trước khi đưa nó vào 2 bước erode(làm mỏng) và dilate(làm dày). Ở đây, với cấu trúc lấy được, sau khi đưa qua bước erode, ảnh của chúng ta sẽ chỉ còn lại các đường thẳng hoặc ngang, bước dilate giúp chúng ta làm rõ hơn các đường này. Và đây là kết quả:

Khá thành công! Giờ là lúc chúng ta sẽ xác định ra vị trí của bảng thông qua bức hình trên. Để làm được điều này, chúng ta cần sử dụng hàm findCountours của OpenCV
_, contours, hierarchy = cv2.findContours(mask,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
max = -1
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
if cv2.contourArea(cnt) > max:
x_max, y_max, w_max, h_max = x, y, w, h
max = cv2.contourArea(cnt)
Hàm findCountours sẽ giúp chúng ta lấy vị trí của các vật thể kín trong 1 bức hình. Ở đây, nó có thể sẽ lấy ra được rất nhiều vị trí của các vật thể (Mỗi dòng là 1 vật thể, mỗi ô là 1 vật thể). Tuy nhiên chúng ta sẽ chỉ cần lấy vật thể lớn nhất đó chính là bảng điền! OKKK, thử in kết quả vừa xác định được ra xem nào!
table = img[y_max:y_max+h_max, x_max:x_max+w_max]
Gần như hoàn hảo phải không  ) Vậy là bài toán 1 của chúng ta đã được giải quyết ...GẦN xong. OpenCV giúp chúng ta cắt được bảng điền ra trong 1 ảnh với những bước xử lý rất đơn giản!
) Vậy là bài toán 1 của chúng ta đã được giải quyết ...GẦN xong. OpenCV giúp chúng ta cắt được bảng điền ra trong 1 ảnh với những bước xử lý rất đơn giản!
Cuối cùng ở bước này, chúng ta sẽ chia bảng ra theo các tỷ lệ nhằm cắt được các ô đáp án một cách gần chính xác nhất, sau đó, mỗi ô đáp án cần, chúng ta sẽ lại sử dụng hàm findCountours để xác định ra ký tự được viết ở ô đó.
cropped_thresh_img = []
cropped_origin_img = []
countours_img = []
NUM_ROWS = 19
START_ROW = 1
for i in range(START_ROW, NUM_ROWS):
thresh1 = thresh[y_max + round(i*h_max/NUM_ROWS):y_max + round((i+1)*h_max/NUM_ROWS), x_max + round(w_max/6):x_max +round(w_max/2)]
_, contours_thresh1, hierarchy_thresh1 = cv2.findContours(thresh1,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
origin1 = img[y_max + round(i*h_max/NUM_ROWS):y_max + round((i+1)*h_max/NUM_ROWS), x_max + round(w_max/6):x_max +round(w_max/2)]
cropped_thresh_img.append(thresh1)
cropped_origin_img.append(origin1)
countours_img.append(contours_thresh1)
for i in range(START_ROW, NUM_ROWS):
thresh1 = thresh[y_max + round(i*h_max/NUM_ROWS):y_max + round((i+1)*h_max/NUM_ROWS), x_max + round(2*w_max/3):x_max +round(w_max)]
_, contours_thresh1, hierarchy_thresh1 = cv2.findContours(thresh1,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
origin1 = img[y_max + round(i*h_max/NUM_ROWS):y_max + round((i+1)*h_max/NUM_ROWS), x_max + round(2*w_max/3):x_max +round(w_max)]
cropped_thresh_img.append(thresh1)
cropped_origin_img.append(origin1)
countours_img.append(contours_thresh1)
Trong đoạn code trên, ta nhận thấy bảng có 19 hàng, vậy nên chiều dọc sẽ được chia ra làm 19 phần, ta sẽ thu được 1/19 chiều dọc của bức ảnh chính là 1 dòng. Ở mỗi dòng, ta có thể ước lượng, ô câu hỏi có kích thước bằng khoảng 1/2 ô đáp án, vậy nên ta sẽ chia chiều ngang ra làm 6 phần. Áp dụng findCountours chỉ cho những ô đáp án ta thu được toàn bộ vật thể nhận ra ở trong các ô đáp án (Dữ liệu được ghi vào mảng nên sẽ đảm bảo việc đúng thứ tự)
Và giờ thêm một vài điều kiện nhằm đảm bảo tính chính xác của đầu ra ta thu được các đáp án ghi lại một cách tuyệt đối.
for i, countour_img in enumerate(countours_img):
for cnt in countour_img:
if cv2.contourArea(cnt) > 30:
x,y,w,h = cv2.boundingRect(cnt)
if x > cropped_origin_img[i].shape[1]*0.1 and x < cropped_origin_img[i].shape[1]*0.9:
answer = cropped_origin_img[i][y:y+h, x:x+w]
answer = cv2.threshold(answer, 160, 255, cv2.THRESH_BINARY_INV)[1]
Với điều kiện này, contours sẽ chỉ được TÍNH nếu có kích thước lớn hơn 30 (Nhằm loại bỏ các vật thể NHIỄU) và với các countours tìm được, để không lấy phải 2 viền ô, ta sẽ chỉ khoanh vùng vào khoảng giữa của ô đáp án (vị trí >0.1*độ dài ô hoặc <0.9 *độ dài ô). Kết quả thu được như sau:

Và đây cũng chính là ảnh đầu vào mà chúng ta sẽ đưa vào mô hình để có thể thực hiện bài toán tiếp theo. Với ảnh các đáp án đã thu được ở trên, chúng ta có thể lưu lại vào mảng kết quả để tiện sử dụng sau này.
Sử dụng tflearn cho bài toán Classification
Mục tiêu của phần này chính ra từ những ảnh trên, xác định ra kết quả A, B, C, D tương ứng với từng ảnh nhằm lưu lại và so sánh với đáp án chính xác sau này.
Với bài toán này, có rất nhiều các model có sẵn trên mạng nhằm phục vụ cho việc classification, ở đây mình chỉ thực hiện việc xây dựng lại đồ thị bằng tflearn, sau đó load lại weight từ model có sẵn nhằm tiết kiệm thời gian training. Đồ thị có dạng như sau:
network = input_data(shape=[None, IMG_SIZE, IMG_SIZE, 1])
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 32, 3, activation='relu')
network = max_pool_2d(network, 2)
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2)
network = fully_connected(network, 1024, activation='relu')
network = dropout(network, 0.8)
network = fully_connected(network, N_CLASSES, activation='softmax')
network = regression(network)
model = tflearn.DNN(network)
model.load("./model/letter.tflearn")
Hoàn toàn dễ hiểu và ngắn gọn. Nếu muốn tìm hiểu sâu hơn về cách thức hoạt động, cách training model nêu trên các bạn có thể tìm hiểu ở bài viết tại phần mở đầu
Và giờ đây, cho toàn bộ ảnh thu được từ các đáp án trên đi qua model, chúng ta sẽ thu được kết quả như mong muốn.
Với những ô không tìm thấy vật thể, đó chính là những ô không được ghi đáp án, ta sẽ đánh dấu X. Với những ô mà ta xác định được 2 vật thể trở lên, tạm thời chúng ta sẽ đánh O - không chắc chắn. Còn lại sẽ được đánh dấu đúng như bình thường.
...
res.append(np.argmax(model.predict(answer), axis=-1))
letter = ['A', 'B', 'C', 'D']
result = []
for r in res:
if len(r) == 0:
result.append("X")
elif len(r) > 1:
result.append("O")
else:
result.append(letter[int(r[0])])
print(result)
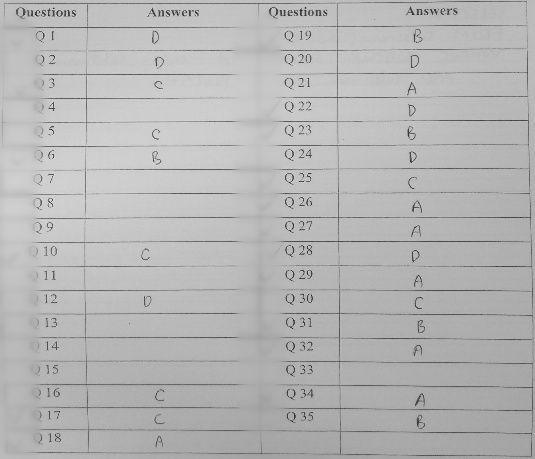
#Result: ['D', 'D', 'C', 'X', 'C', 'B', 'X', 'X', 'X', 'C', 'X', 'D', 'X', 'X', 'X', 'C', 'C', 'A', 'B', 'D', 'A', 'D', 'B', 'D', 'C', 'A', 'A', 'D', 'A', 'C', 'B', 'A', 'X', 'A', 'B', 'X']
Result: ['D', 'D', 'C', 'X', 'C', 'B', 'X', 'X', 'X', 'C', 'X', 'D', 'X', 'X', 'X', 'C', 'C', 'A', 'B', 'D', 'A', 'D', 'B', 'D', 'C', 'A', 'A', 'D', 'A', 'C', 'B', 'A', 'X', 'A', 'B', 'X']
Kết quả chính xác 100% so với bức ảnh trên! Và giờ mọi công đoạn so đáp án, thống kê hay lưu trữ số hóa ở sau đây đều có thể được thực hiện chỉ trong một vài câu lệnh đơn giản! Quá tuyệt vời phải không nào!
Các ngoại lệ
Với các bài toán thực tế mà ảnh đầu vào của chúng ta không được quy chuẩn như thế này, việc chọn các tham số cho các hàm của OpenCV là vô cùng quan trọng. Người viết khuyến cáo các bạn hãy dành thời gian để thử thật nhiều để tìm ra được các tham số phù hợp nhất cho bài toán của riêng mình. Chúc các bạn thành công!
Các nguồn có thể tham khảo về các hàm được sử dụng:
- findCountours: https://docs.opencv.org/ref/master/d9/d8b/tutorial_py_contours_hierarchy.html
- Các hàm điều chỉnh hình thái ảnh: https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html
- numpypad: https://docs.scipy.org/doc/numpy-1.12.0/reference/generated/numpy.pad.html
- threshold: https://docs.opencv.org/3.4.0/d7/d4d/tutorial_py_thresholding.html
All rights reserved
