
Xây dựng chương trình tóm tắt văn bản (tiếng Việt) đơn giản với Machine Learning
Bài đăng này đã không được cập nhật trong 7 năm
Việc tóm tắt văn bản ngày càng trở nên cần thiết!
Trong một thời đại mà mỗi ngày, mỗi giờ , mỗi phút đều có một lượng thông tin khổng lồ được sinh ra, nhưng giới hạn về thời gian, về khả năng đọc và tiếp thu của con người là có hạn, việc hiểu và nắm bắt thật nhiều thông tin một cách nhanh chóng không phải là vấn đề đơn giản với bất kỳ ai.
Đã bao giờ bạn tìm kiếm các kiến thức trên internet, hay đọc một cuốn sách mà nội dung của nó dài "lê thê", khiến cho bạn cảm thấy một chút khó khăn để có thể nắm bắt được nó chưa?

Đứng trước xu hướng con người ngày càng mất nhiều thời gian đọc email, báo điện tử và mạng xã hội, các thuật toán sử dụng machine learning để tự động tóm tắt các văn bản dài một cách gãy gọn và chính xác ngày càng trở nên cần thiết và có vai trò to lớn đối trong bất kỳ lĩnh vực nào.
Tự động tóm tắt sẽ là một trong những công nghệ quan trọng có thể giúp con người giảm thiểu thời gian đọc email và thông tin, kiến thức mới để dành thời gian cho các công việc khác, mà vẫn có thể nắm bắt được gãy gọn những nội dung của nó.
Mục tiêu
Hiện nay, rất nhiều thuật toán cho việc tóm tắt đã và đang được các công ty, các nhà nghiên cứu phát triển. Tuy nhiên, hôm nay mình muốn giới thiệu cho các bạn một trong số những cách đơn giản nhất mà mình đã tìm hiểu được. Với việc áp dụng những phương pháp cơ bản nhất của học máy (Machine Learning) hay xử lý ngôn ngữ tự nhiên (Natural Language Processing), cá nhân mình thấy đây là một phương pháp cực kỳ đơn giản và có thể dễ dàng nắm bắt. Chúng ta hãy cùng nhau xây dựng mô hình này với nhau trong bài viết hôm nay! 
Link github: https://github.com/hoanganhpham1006/Vietnamese_doc_summarization_basic
Các bước xử lý
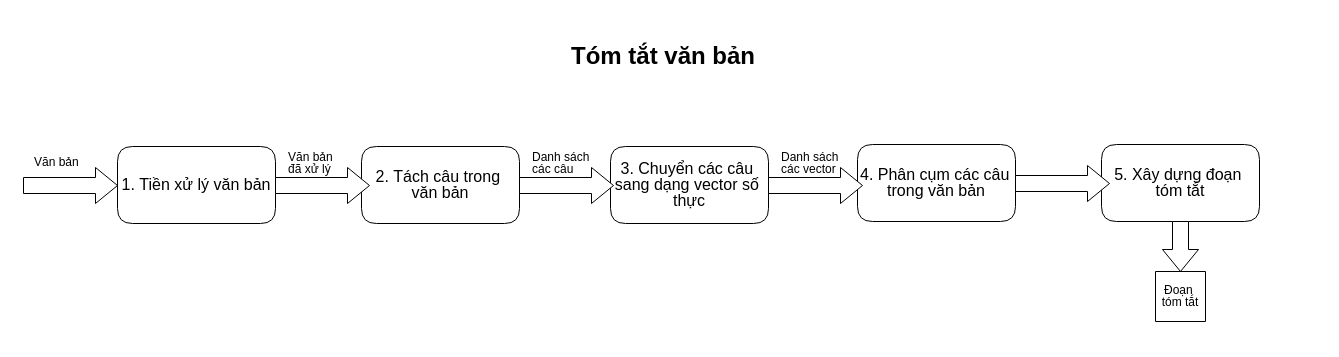
Như mục tiêu của bài viết đã nói rõ, trong bài viết lần này, mình sẽ cố gắng giới thiệu tới các bạn những phương pháp đơn giản nhất để có thể xây dựng được một chương trình tóm tắt văn bản. Và chương trình của chúng ta sẽ chỉ cần có 5 bước như sơ đồ ở trên 
Ý tưởng chính ở đây là chúng ta sẽ loại bỏ đi những câu có ý nghĩa tương tự nhau để tạo ra 1 văn bản tóm tắt nhé!
Cụ thể mình mô tả các bước như sau:
- Tiền xử lý văn bản: Văn bản đầu vào của chúng ta có thể chứa nhiều ký tự thừa, dấu câu thừa, khoảng trắng thừa, các từ viết tắt, viết hoa, ... điều này có thể làm ảnh hưởng tới các bước ở sau này nên chúng ta cần phải xử lý nó trước! Tuy nhiên trong bài lần này, chúng ta sẽ chỉ thử trên một số bài báo đã khá "quy củ" rồi nên mình sẽ chỉ thực hiện 2 phương pháp đó là Biến đổi hết về các chữ cái thường và Loại bỏ các khoảng trắng thừa.
- Tách câu trong văn bản: Ở bước này, chúng ta sẽ tách 1 đoạn văn bản cần tóm tắt đã qua xử lý thành 1 danh sách các câu trong nó.
- Chuyển các câu sang dạng vector số thực: Để phục vụ cho phương pháp tóm tắt ở bước tiếp theo, chúng ta cần chuyển các câu văn (độ dài ngắn khác nhau) thành các vector số thực có độ dài cố định, sao cho vẫn phải đảm bảo được "độ khác nhau" về ý nghĩa giữa 2 câu cũng tương tự như độ sai khác giữa 2 vector tạo ra. Điều này mình sẽ giới thiệu một phương pháp mình cho là khá đơn giản cũng như giải thích kỹ hơn cho các bạn ở phần sau khi chúng ta đi vào code.
- Phân cụm: Với các bạn nghiên cứu về Machine Learning thì đây chắc hẳn là một thuật toán rất quen thuộc (K-Means Clustering). Thuật toán này sẽ giúp chúng ta phân ra những cụm câu có ý nghĩa giống nhau, để từ đó chọn lọc và loại bỏ bớt các câu có cùng ý nghĩa.
- Xây dựng đoạn văn bản tóm tắt: Sau khi đã có các cụm, trong mỗi cụm (phân loại theo ý nghĩa), chúng ta sẽ chọn ra 1 câu duy nhất trong cụm đó để tạo nên văn bản được tóm tắt!
Xây dựng chương trình bằng Python
Chúng ta cùng nhau thử xây dựng chương trình để tóm tắt mẩu tin sau:
Công sở đậm dư âm Tết trong ngày đầu làm việc.
Trong lịch công tác của các bộ ngành 3 ngày đầu năm hầu như không có những cuộc họp. Chương trình làm việc chính của các lãnh đạo là chúc Tết. Một số nơi còn ghi lịch làm việc: lãnh đạo giải quyết công việc thường xuyên tại cơ quan. 9h sáng, hội trường Bộ Giáo dục và Đào tạo rộn tiếng cười đùa, chúc tụng, tiếng ly rượu cụng nhau chan chát. Sau đó các vụ, phòng bắt đầu những cuộc gặp gỡ riêng. Buổi "làm việc" đầu năm kết thúc sớm, với bữa tiệc tân niên tại gia. "Ngày thường, cùng cơ quan đấy nhưng mấy khi có dịp đến nhà nhau. Năm qua, người thì xây nhà mới, người thì có con đầu lòng. Đầu xuân, mọi người trong phòng đến nhà nhau, vừa chúc Tết, thăm hỏi luôn", anh Tuấn, cán bộ Tổng công ty Dệt may Việt Nam tâm sự.
Sau 2 màn tiệc ngọt tại cơ quan, 10h sáng, các thành viên trong phòng của Tuấn "đóng cửa" bắt đầu những cuộc viếng thăm truyền thống. "Hôm nay ai có việc gấp quá thì phải làm nhưng ít người như thế lắm. Cả sếp và nhân viên công ty tôi đều đi chúc Tết. Chúc Tết các phòng xong, chúng tôi đang triệu nhau đến thăm nhà mấy người đồng nghiệp, bạn bè gần đây", chị Nguyễn Thị Bích Thư, phòng Kỹ thuật, Công ty Thép Miền Nam, 56 Thủ Khoa Huân, quận 1 (TP HCM) hoan hỷ. Rộn ràng trong công sở, không khí xuân còn tràn ngập quanh các hàng quán cà phê. 9h sáng, nhưng các hàng quán trên đường Lý Tự Trọng, quận 1 (TP HCM) vẫn khá đông công chức. Họ kể chuyện chơi Tết, chúc tụng, trao lì xì cho nhau và vui vẻ cười đùa. Anh Hoàng, cán bộ một sở trên đường Lý Tự Trọng cho biết, ngày đầu năm, lãnh đạo sở gặp mặt lãnh đạo các phòng, ban, nhân viên, ăn kẹo, uống chút bia thân mật để động viên, lấy "khí thế" làm việc cho cả năm. Dư vị Tết có lẽ phải kéo dài thêm vài ngày nữa.
Trao đổi với VnExpress, Chánh Văn phòng của một bộ cho rằng: "Đầu năm chơi nhiều hơn làm" đã thành lệ khó sửa. Lãnh đạo cơ quan biết nhưng cũng phải thông cảm. "Anh em mời nhau đến nhà chơi, đi làm muộn một chút mình cũng phải thông cảm, quy định cứng nhắc quá thì mất vui. Tuy nhiên, công việc cơ quan vẫn phải đảm bảo", ông này nói. Cũng có một thực tế là đầu năm, người dân cũng mải vui Tết, chưa đến các cơ quan công quyền. Do vậy, không tạo áp lực công việc đối với công chức. Phòng công chứng số 1 (Hà Nội) ngày thường đông nghịt khách nhưng sáng nay vắng hoe. Anh Nguyễn Chí Thiện, công chứng viên cho biết, cả sáng chỉ có khoảng 30 hồ sơ công chứng, thấp "kỷ lục" trong năm. Vắng khách, sẵn mứt Tết "tồn đọng", nhân viên quây quần ngồi uống nước, bàn chuyện du xuân. 11h trưa, nhiều công sở ở Hà Nội khá im ắng, các quán ăn thì đông nghẹt khách. "Sáng đi được một tour rồi, trưa tụ họp ở quán ăn lấy sức. Chiều đi vài nhà nữa rồi karaoke", Ngọc Linh, nhân viên kinh doanh một hãng ôtô lớn hào hứng.
Với nhiều công chức, ngày đầu năm đi làm còn. . vui hơn Tết!
1. Tiền xử lý văn bản
Như mình đã nói ở trên, do chúng ta sẽ chỉ áp dụng trên các bài báo tin tức nên mình sẽ chỉ dùng 2 phương pháp là chuyển đổi hết sang chữ cái thường và loại bỏ các khoảng trắng nhé, chúng ta sẽ có đoạn code sau:
contents_parsed = content.lower() #Biến đổi hết thành chữ thường
contents_parsed = contents_parsed.replace('\n', '. ') #Đổi các ký tự xuống dòng thành chấm câu
contents_parsed = contents_parsed.strip() #Loại bỏ đi các khoảng trắng thừa
Và đây là kết quả chúng ta sẽ thu được
công sở đậm dư âm tết trong ngày đầu làm việc. trong lịch công tác của các bộ ngành 3 ngày đầu năm hầu như không có những cuộc họp. chương trình làm việc chính của các lãnh đạo là chúc tết. một số nơi còn ghi lịch làm việc: lãnh đạo giải quyết công việc thường xuyên tại cơ quan. 9h sáng, hội trường bộ giáo dục và đào tạo rộn tiếng cười đùa, chúc tụng, tiếng ly rượu cụng nhau chan chát. sau đó các vụ, phòng bắt đầu những cuộc gặp gỡ riêng.....
2. Tách các câu trong văn bản
Tại đây chúng ta sẽ tách các câu trong văn bản trên ra để thu được 1 danh sách các câu có ở trên. Việc này trở nên đơn giản hơn rất nhiều với thư viện NLTK, các bạn có thể dễ dàng sử dụng hàm sent_tokenize để lấy ra danh sách các câu nhé!
import nltk
sentences = nltk.sent_tokenize(contents_parsed)
Kết quả thu được:
['công sở đậm dư âm tết trong ngày đầu làm việc.', 'trong lịch công tác của các bộ ngành 3 ngày đầu năm hầu như không có những cuộc họp.', 'chương trình làm việc chính của các lãnh đạo là chúc tết.', 'một số nơi còn ghi lịch làm việc: lãnh đạo giải quyết công việc thường xuyên tại cơ quan.', '9h sáng, hội trường bộ giáo dục và đào tạo rộn tiếng cười đùa, chúc tụng, tiếng ly rượu cụng nhau chan chát.', ... ]
3. Chuyển các câu sang vector:
Về phần này, hiện nay có rất nhiều phương pháp training được sử dụng hiệu quả, nhằm biến đổi các câu sang các vector có độ dài cố định mà vẫn giữ được các đặc trưng, ý nghĩa của câu đó. Có thể kể đến phương pháp mà gần đây mình đang nghiên cứu và có vài lần làm thử là SkipThought (https://github.com/ryankiros/skip-thoughts/tree/master/training). Tuy nhiên mô hình này được training trên tập dữ liệu tiếng Anh và để training lại với dữ liệu tiếng Việt sẽ mất của các bạn thêm chút thời gian nữa. Mô hình này tỏ ra rất hiệu quả, tuy nhiên trong bài viết lần này mình muốn giới thiệu cho các bạn một phương pháp dễ dàng để tiếp cận hơn đó là sử dụng sẵn mô hình đã được huấn luyện chuyển đổi từ "Từ sang vector" (Word2Vec).
Phương pháp của mình đó chính là sẽ tách nhỏ từng câu thành các từ, sau đó dùng mô hình Word2Vec đã được training cho tiếng Việt, chuyển đổi các từ đó sang các vector số thực có chiều dài cố định. Cuối cùng, vector của 1 câu mà mình chuyển đổi sang sẽ là TỔNG của các vector đại diện cho các từ trong câu!
Mô hình Word2Vec cho tiếng Việt các bạn có thể dễ dàng tìm trên mạng, ở đây mình sử dụng mô hình tại
Các bạn hãy tải mô hình xuống nhé!
Với mô hình mình vừa tải xuống, các từ sẽ được biến đổi thành một vector 100 chiều. Chúng ta sẽ sử dụng thư viện gensim để load lại model.
from gensim.models import KeyedVectors
w2v = KeyedVectors.load_word2vec_format("vi_txt/vi.vec")
Tiếp theo là tách các từ trong câu và lấy tổng để được các vector cho từng câu trong danh sách mà chúng ta vừa có trên kia:
vocab = w2v.wv.vocab #Danh sách các từ trong từ điển
from pyvi import ViTokenizer
X = []
for sentence in sentences:
sentence_tokenized = ViTokenizer.tokenize(sentence)
words = sentence_tokenized.split(" ")
sentence_vec = np.zeros((100))
for word in words:
if word in vocab:
sentence_vec+=w2v.wv[word]
X.append(sentence_vec)
Trong đoạn code ở trên, mình sẽ duyệt qua từng câu trong danh sách câu của chúng ta. Với mỗi câu, mình sẽ tách các từ ra. Ở đây mình dùng thêm 1 thư viện pyvi để tách các từ tiếng Việt. Ví dụ như câu
"công sở đậm dư âm tết trong ngày đầu làm việc"
Chúng ta phải tách thành
['công_sở', 'đậm', 'dư_âm', 'tết', 'trong', 'ngày', 'đầu', 'làm_việc', '.']
Thư viện pyVi với hàm ViTokenize sẽ giúp chúng ta ghép các từ có nghĩa trong tiếng Việt lại với nhau nhằm đảm bảo giữ nguyên ý nghĩa của từng từ!
Sau đó, mình khai báo một vector 100 chiều gồm toàn số 0. rồi với mỗi một từ trong câu, mình đều sử dụng hàm word2vec chuyển thành vector rồi cộng nó vào vector này (nếu nó có thể chuyển được thành vector). Cuối cùng sau khi hết mỗi câu, mình thêm nó vào 1 mảng đặt tên là X.
VẬY VẤN ĐỀ Ở ĐÂY LÀ TẠI SAO CHUYỂN TỪ TỪ SANG VECTOR LẠI VẪN GIỮ ĐƯỢC Ý NGHĨA CỦA TỪNG TỪ?
Điều tuyệt vời nhất nằm ở mô hình Word2Vec chúng ta vừa tải về. Mô hình này được training trên nhiều bài viết bằng tiếng Việt với mô hình khá phức tạp trong khoảng thời gian tương đối lâu để giúp tạo ra 1 vector đại diện cho mỗi từ mà đảm bảo nguyên được sự "sai khác" về ý nghĩa của chúng so với các từ khác, các vector khác.
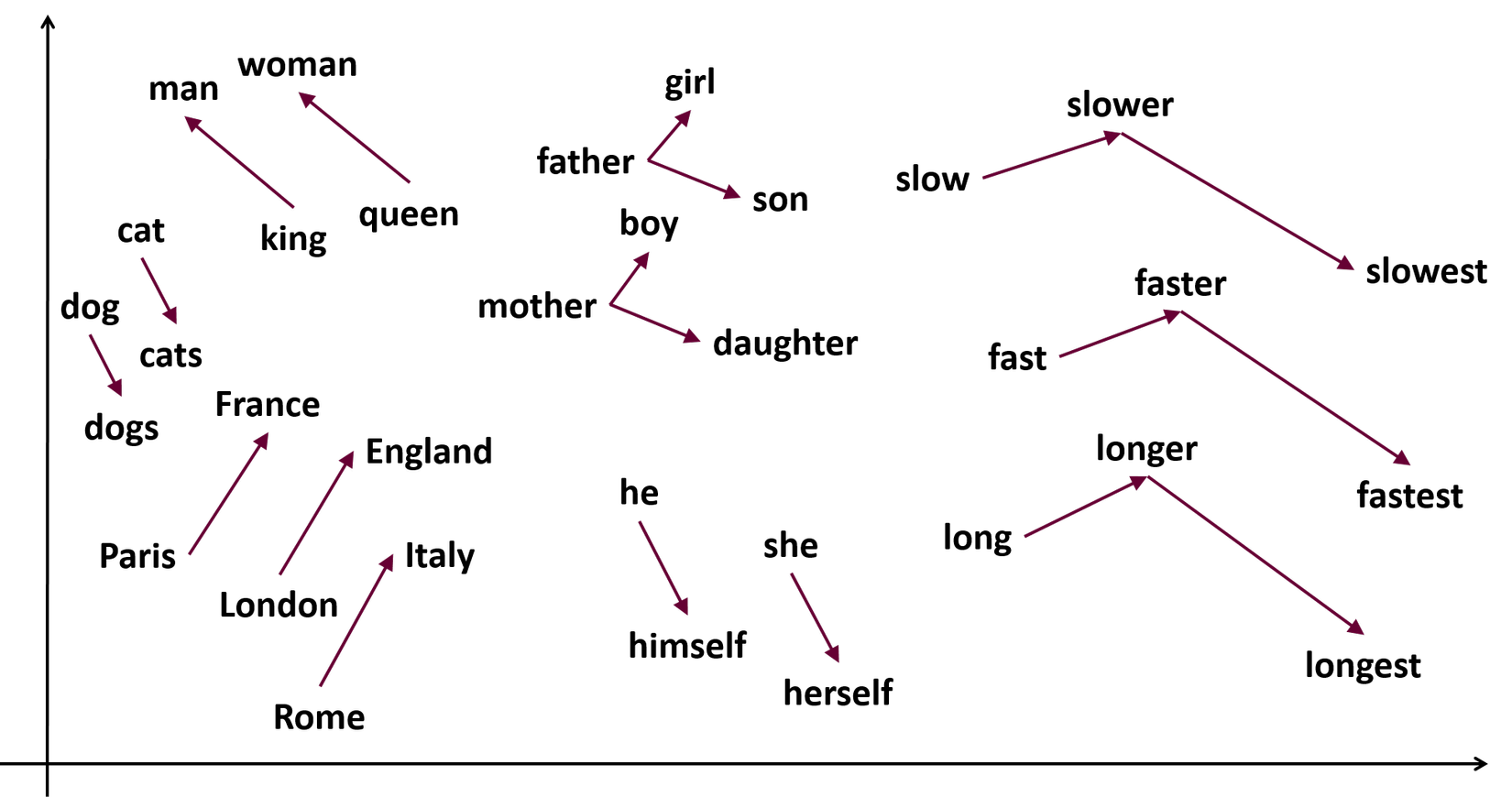
Các bạn có thể thấy như hình minh họa trên mình đã tìm được ở trên mạng. Sau khi training, mô hình này giúp chúng ta biễu diễn các từ thành các vector. Và nó giữ được ý nghĩa của các từ như chúng ta nhìn thấy trong hình trên. Ví dụ về mặt toán học: "Nếu chúng ta lấy $ man - woman $ ta sẽ thu được một vector cùng hướng, cùng độ dài với vector ta tính được khi lấy $ king - queen $.!!
Nếu có dịp mình sẽ giải thích về phương pháp huấn luyện mô hình Word2Vec này ở trong cái bài tiếp theo.
Quay trở lại viết chương trình đang xây dựng, X chúng ta thu được sẽ là các vector 100 chiều mà mỗi vector đại diện cho 1 câu trong văn bản vừa rồi của chúng ta!
4. Phân cụm
Bài toán phân cụm là 1 nhánh ứng dụng chính của lĩnh vực Unsupervised Learning (Học không giám sát), trong đó dữ liệu được mô tả trong bài toán không được dán nhãn (tức là không có đầu ra). Trong trường hợp này, thuật toán sẽ tìm cách phân cụm - chia dữ liệu thành từng nhóm có đặc điểm tương tự nhau, nhưng đồng thời đặc tính giữa các nhóm đó lại phải càng khác biệt càng tốt.
Và ở đây, chúng ta muốn phân cụm các vector đại diện cho từng câu trong văn bản vừa rồi để biết những câu nào mang ý nghĩa giống nhau.
Thuật toán phân cụm ở đây, mình chọn số cụm (clusters) chính bằng số câu mà chúng ta muốn tóm tắt. Thuật toán này các bạn có thể dễ dàng sử dụng và cài đặt với sklearn
from sklearn.cluster import KMeans
n_clusters = 5
kmeans = KMeans(n_clusters=n_clusters)
kmeans = kmeans.fit(X)
Ở đây mình muốn tóm tắt mẩu tin trên thành 5 câu duy nhất, vậy nên n_clusters sẽ để bằng 5 nhé. Quá trình phân cụm ở đây cũng sẽ diễn ra rất nhanh do số lượng câu trong văn bản rất nhỏ!
Và chúng ta đã có được 5 cụm "ý nghĩa" của văn bản trên, sẵn sàng để xây dựng ra một văn bản tóm tắt ở bước cuối cùng!
5. Xây dựng đoạn văn bản tóm tắt
Mỗi cụm mà chúng ta phân ra được ở trên, có thể hiểu là đại diện cho một ý nghĩa nào đó ở trong văn bản gốc. Tuy nhiên để tóm gọn lại cả 1 văn bản dài, với mỗi một ý nghĩa chúng ta sẽ chỉ chọn ra 1 câu duy nhất thôi! Và câu được chọn để ĐẠI DIỆN cho 1 cụm đó ở đây, sẽ là câu có khoảng cách gần với trung tâm của cụm nhất. Sau khi đã có được các câu của văn bản tóm tắt, giờ chúng ta quan tâm là sẽ sắp xếp thứ tự như thế nào cho hợp lý. Ở đây, với mỗi ý nghĩa, mình sẽ tính "thứ tự xuất hiện trung bình" của cụm đó.
Ví dụ cụm 1 có các câu 1, 2, 5. thứ tự trung bình sẽ là 8/3.
Làm tương tự với các cụm khác, sau đó chúng ta sẽ lấy các câu đại diện trong các cụm theo thứ tự từ nhỏ đến lớn của thứ tự xuất hiện trung bình để tạo ra một văn bản tóm tắt! Rất dễ hiểu phải không )
from sklearn.metrics import pairwise_distances_argmin_min
avg = []
for j in range(n_clusters):
idx = np.where(kmeans.labels_ == j)[0]
avg.append(np.mean(idx))
closest, _ = pairwise_distances_argmin_min(kmeans.cluster_centers_, X)
ordering = sorted(range(n_clusters), key=lambda k: avg[k])
summary = ' '.join([sentences[closest[idx]] for idx in ordering])
Trong đoạn code trên, mình có sử dụng hàm pairwise_distances_argmin_min của sklearning metric để lấy ra khoảng cách vector giữa các vector và các trung tâm cụm của nó, sau đó chọn ra khoảng cách nhỏ nhất để lấy được câu đại diện. Sau đó tính "thứ tự xuất hiện trung bình" và sắp xếp lại để tạo ra văn bản tóm tắt.
Và kết quả chúng ta thu được đoạn văn bản sau:
'cũng có một thực tế là đầu năm, người dân cũng mải vui tết, chưa đến các cơ quan công quyền. chúc tết các phòng xong, chúng tôi đang triệu nhau đến thăm nhà mấy người đồng nghiệp, bạn bè gần đây", chị nguyễn thị bích thư, phòng kỹ thuật, công ty thép miền nam, 56 thủ khoa huân, quận 1 (tp hcm) hoan hỷ. "anh em mời nhau đến nhà chơi, đi làm muộn một chút mình cũng phải thông cảm, quy định cứng nhắc quá thì mất vui". với nhiều công chức, ngày đầu năm đi làm còn vui hơn tết. 11h trưa, nhiều công sở ở hà nội khá im ắng, các quán ăn thì đông nghẹt khách.'
Thử thêm một số văn bản khác
Mình đang để số cụm là 5 vậy nên các văn bản tóm tắt đều sẽ có đúng 5 câu! Chúng ta cùng thử thêm với một số bài báo khác nhé!
Văn bản:
Tất cả bánh xu xê đều có hàn the.
Bánh xu xê đang bị phường Nguyễn Trung Trực (Ba Đình, Hà Nội) cấm bán vì việc sản xuất bắt buộc phải dùng hàn the. Tuy nhiên, các cửa hàng trên phố Hàng Than vẫn làm bánh này khi có khách đặt mua làm lễ ăn hỏi. Trong buổi kiểm tra vệ sinh thực phẩm sáng 1/4, Sở Y tế Hà Nội đã phát hiện hàn the - chất bị cấm dùng trong thức ăm - trong mẻ bánh xu xê 100 cái của cửa hàng Hồng Ninh, 79 Hàng Than. Mảnh giấy quỳ ngả màu đỏ sẫm chứng tỏ hàm lượng hàn the rất cao. Theo bà chủ cửa hàng, vài tháng nay khi phường Nguyễn Trung Trực cấm bán bánh xu xê, bà không bày bán mặt hàng này nữa, trừ khi có khách đặt cho đám cưới đám hỏi. Tuy biết hàn the là chất bị cấm nhưng bà vẫn phải dùng vì chất phụ gia thay thế hàn the không làm được bánh xu xê.
Ông Nguyễn Trọng Nghĩa, Phó chủ tịch UBND phường, giải thích: Chất phụ gia thay thế hàn the mà ngành y tế cho phép sử dụng tuy rất hiệu quả khi dùng sản xuất giò chả, bánh giò. . nhưng nếu dùng sản xuất bánh xu xê thì không đạt yêu cầu. Bánh xu xê làm từ chất phụ gia này không đủ độ trong, độ dai và không bảo quản được lâu, chỉ để khoảng 2 ngày là chảy nước. Do muốn sản xuất bánh xu xê thì bắt buộc dùng hàn the nên để ngăn ngừa nguy cơ từ chất này đối với sức khỏe, từ vài tháng nay phường Nguyễn Trung Trực đã cấm sản xuất và bán bánh này. Hầu như không cửa hàng nào bày bán nữa nhưng nếu có khách đặt thì vẫn nhận. Theo ông Nghĩa, cấm bán bánh xu xê là một hạ sách, là điều cực chẳng đã vì đây là một mặt hàng truyền thống của phường và rất cần thiết cho lễ ăn hỏi theo phong tục Việt Nam. Tuy nhiên, hiện phường chưa có cách nào để vẫn duy trì mặt hàng này mà không ảnh hưởng đến sức khỏe người dân. Ông Lê Anh Tuấn, Giám đốc Sở Y tế, cho biết sẽ đề nghị các cơ quan nghiên cứu tìm ra một chất phụ gia mới an toàn mà vẫn đảm bảo các yêu cầu về độ ngon miệng, thời hạn bảo quản. . của bánh xu xê.
Tóm tắt:
'hầu như không cửa hàng nào bày bán nữa nhưng nếu có khách đặt thì vẫn nhận. do muốn sản xuất bánh xu xê thì bắt buộc dùng hàn the nên để ngăn ngừa nguy cơ từ chất này đối với sức khỏe, từ vài tháng nay phường nguyễn trung trực đã cấm sản xuất và bán bánh này. bánh xu xê làm từ chất phụ gia này không đủ độ trong, độ dai và không bảo quản được lâu, chỉ để khoảng 2 ngày là chảy nước. ông lê anh tuấn, giám đốc sở y tế, cho biết sẽ đề nghị các cơ quan nghiên cứu tìm ra một chất phụ gia mới an toàn mà vẫn đảm bảo các yêu cầu về độ ngon miệng, thời hạn bảo quản. của bánh xu xê.'
Văn bản:
Sân chơi cho trẻ em vẫn chỉ là khẩu hiệu.
Mỗi khi hè về, "Tháng hành động vì trẻ em" tới, chuyện sân chơi cho thiếu nhi lại được nhiều người quan tâm hơn. Nhưng hè nào cũng vậy, trẻ vẫn cứ thiếu chỗ chơi. Những đô thị lớn như HN và TP HCM cũng không là ngoại lệ. Thường ngày, các điểm sinh hoạt văn hoá - thể thao dành cho thiếu nhi ở HN đã luôn quá tải. Đặc biệt là ở Cung Thiếu nhi, người ta đã phải tận dụng tối đa cơ sở vật chất, huy động thêm nhiều cộng tác viên, tăng ca học cả buổi tối. Công viên nước Hồ Tây cũng là một điểm thu hút đông trẻ em tới tham gia sinh hoạt, cho dù nơi đây giá vé không phải là "mềm" và không phải các trò chơi đều phù hợp với thiếu nhi. Trong khi đó, công viên Thủ Lệ (hay còn gọi là Vườn thú HN) có diện tích rộng, nhưng lại không "bắt mắt" trẻ, bởi chuồng thú thì hôi, hàng quán choán hết lối đi. Công viên Thống Nhất có địa thế đẹp, gần trung tâm thành phố, dễ tổ chức các khu vui chơi giải trí cho trẻ, nhưng lại rất ít các trò chơi mới. Những trò như: nhà gương, đu quay. . đã nhàm chán. Trong công viên, đây đó còn xuất hiện những chợ cóc bán tạp nham đủ thứ. Cảnh "tình tự" ở nhiều công viên diễn ra vô tư trước mắt trẻ. Các bậc phu huynh rất ngại cho con mình chơi đùa, sợ giẫm phải kim tiêm của dân chích hút. Trong khi các công viên chưa đáp ứng được nhu cầu chính đáng của mọi người dân, đặc biệt là trẻ em, thì hệ thống các nhà văn hoá thiếu nhi ở HN lại rất thiếu, nặng về hình thức. Phần lớn số 1.700 điểm vui chơi cấp phường, xã trên địa bàn HN chưa được xây dựng hoàn chỉnh, hoặc để đất trống. Thậm chí ở nhiều khu dân cư, các điểm vui chơi của trẻ em đã bị thu hẹp lại hoặc bị lấn chiếm, sử dụng sai mục đích. Tại khu chung cư Thanh Xuân Bắc, đơn vị thi công đã tự ý thay đổi công năng diện tích dành cho thiếu nhi. Rạp Kim Đồng - nơi một thuở chuyên chiếu phim cho thiếu nhi - nay bị chiếm làm quán bán bia. Một vài điểm vui chơi như Sega, Star Bowl, Cosmos. . luôn có nhiều thiếu nhi tới chơi, nhưng chủ yếu là con em gia đình khá giả, bởi giá vé ở đây khá cao. Tại TPHCM hiện cũng chưa một công trình nào được xây dựng đúng nghĩa là sân chơi dành cho thiếu nhi. Nhà văn hoá thiếu nhi thành phố có mặt bằng rộng, thu hút đông bạn nhỏ, đang trở thành quá tải, nhất là trong dịp hè và lễ hội. 24 nhà văn hoá thiếu nhi quận, huyện ngoài việc có dành chỗ cho thiếu nhi sinh hoạt, thì còn cho thuê mướn mặt bằng, hoặc "tranh thủ" mở đủ loại dịch vụ cho người lớn. Trong 4 "Ngày hội tuổi thơ" dịp 1.6, Nhà văn hoá thiếu nhi thành phố có trên 15.000 lượt người đến vui chơi. Trong khi đó, vào ngày thường, nơi đây chỉ đủ đón 1.000-1.500 trẻ. Trung bình mỗi tuần có trên 20.000 lượt trẻ tập trung ở khu vực này. Cũng hằng tuần, từ các tỉnh như Bình Dương, Đồng Nai, có hàng đoàn xe chở trẻ em đến Nhà văn hoá thiếu nhi của TP HCM để sinh hoạt, học các môn năng khiếu. Học sinh các huyện Hóc Môn, Củ Chi cũng đổ về đây cuối tuần. Do không đủ chỗ, các em vẫn phải ra ngồi học ở ghế đá. Lớp học chia làm nhiều suất. Phụ huynh phải trải chiếu ngồi đợi con em mình. Thỉnh thoảng, nhà văn hoá thiếu nhi thành phố lại đón trẻ ở các mái ấm, nhà mở về vui chơi, nên càng quá tải hơn. Khi dự án mở rộng đường Nam Kỳ Khởi Nghĩa thực thi, một phần diện tích không nhỏ của nơi này sẽ bị mất đi. Sân chơi vốn đã chật sẽ càng hẹp hơn. Ban lãnh đạo Nhà văn hoá thiếu nhi đang đề xuất UBND TP cho mở địa điểm ở vùng ven, hoặc xây dựng nhà văn hoá thiếu nhi mới quy mô hơn, nhưng đến nay vẫn chưa thực hiện được. Tại quận 1, Nhà văn hoá thiếu nhi khá khang trang, nhưng hội trường chính đã trở thành. . rạp kịch của sân khấu Idecaf. Ở đây chỉ có phòng để học, chứ không có trò chơi hay khoảng sân rộng cho trẻ em vui chơi (khoảng sân này đã được trưng dụng thành bãi để xe và quán cà phê). Khu đô thị mới Phú Mỹ Hưng, dù được thiết kế phục vụ an sinh của cộng đồng, nhưng khu vui chơi của trẻ con vẫn thường bị "bỏ quên" trong dự án. Theo kiến trúc sư Võ Thành Lân, ở TPHCM chưa có công trình nào dành cho trẻ em đạt chuẩn. Nhiều dự án nhấn mạnh yếu tố làm sân chơi cho thiếu nhi, nhưng làm hay không là chuyện khác.
Tóm tắt:
'thậm chí ở nhiều khu dân cư, các điểm vui chơi của trẻ em đã bị thu hẹp lại hoặc bị lấn chiếm, sử dụng sai mục đích. trong khi đó, vào ngày thường, nơi đây chỉ đủ đón 1.000-1.500 trẻ. luôn có nhiều thiếu nhi tới chơi, nhưng chủ yếu là con em gia đình khá giả, bởi giá vé ở đây khá cao. khu đô thị mới phú mỹ hưng, dù được thiết kế phục vụ an sinh của cộng đồng, nhưng khu vui chơi của trẻ con vẫn thường bị "bỏ quên" trong dự án. công viên nước hồ tây cũng là một điểm thu hút đông trẻ em tới tham gia sinh hoạt, cho dù nơi đây giá vé không phải là "mềm" và không phải các trò chơi đều phù hợp với thiếu nhi.'
Các nguồn tham khảo
Để cải tiến hơn chương trình này, các bạn có thể tìm hiểu sử dụng một số mô hình sao cho biến đổi được trực tiếp từ câu sang vector (chứ không phải lấy tổng các từ như mình), điều này sẽ làm cho các cụm "ý nghĩa" của các bạn được trở nên chính xác hơn. Ngoài ra, phương pháp phân cụm của mình ở đây cũng là một phương pháp khá đơn giản. Về kỹ thuật tóm tắt khác còn có rất nhiều như tóm tắt trừu tượng (Câu được tự sinh ra chứ không phải là 1 trong số câu trong văn bản), tóm tắt động (Generic) ,.. Các bạn quan tâm có thể tìm hiểu thêm nữa.
Một số nguồn để tham khảo về các phương pháp trong bài viết:
- Text Summarize Book: https://www.amazon.com/Advances-Automatic-Text-Summarization-Press/dp/0262133598/ref=as_li_ss_tl?ie=UTF8&qid=1503872626&sr=8-1&keywords=text+summarization&linkCode=sl1&tag=inspiredalgor-20&linkId=75d9f8d62261d17bdddf5c5c0f43881a
- Word to vector: https://radimrehurek.com/gensim/models/word2vec.html
- Kmean Clustering: https://machinelearningcoban.com/2017/01/01/kmeans/
Cảm ơn các bạn đã quan tâm!
All rights reserved
