
Draw to your screen - Chơi QuickDraw bằng "đũa thần" với Object Tracking - OpenCV
Bài đăng này đã không được cập nhật trong 7 năm
"Đũa thần" là có thật?

Đã từ rất lâu, chúng ta đã được tiếp cận và không còn xa lạ gì với các hình ảnh khoa học viễn tưởng như các thiết bị màn hình được cấy ghép dưới da của con người hay việc hiển thị thông tin trực tiếp trong không gian mà không cần 1 màn hình nào khác thông qua sản phẩm của các hãng phim nổi tiếng.
Việc này không chỉ thể hiện trí tưởng tượng, sáng tạo tuyệt vời của các nhà làm phim, mà chúng còn nói lên những tham vọng trong lĩnh vực công nghệ của các nước phát triển trong tương lai. Hàng loạt thành công rực rỡ, vượt xa kỳ vọng của các nhà khoa học, các công ty công nghệ trong thời gian gần đây đang khiến cho loài người "hiện thực hoá" được toàn bộ những gì mà trước đây chỉ có ở trên phim ảnh.
Mục tiêu
Câu chuyện trên của mình chỉ mang tính giải trí một chút cho mọi người  ) Tuy nhiên, đúng như trong tiêu đề, ngày hôm nay mình sẽ cùng các bạn làm một ứng dụng dựa trên xử lý ảnh, giúp chúng ta "vẽ" được lên trên màn hình bằng bất cứ "vật dụng" gì nhé!
) Tuy nhiên, đúng như trong tiêu đề, ngày hôm nay mình sẽ cùng các bạn làm một ứng dụng dựa trên xử lý ảnh, giúp chúng ta "vẽ" được lên trên màn hình bằng bất cứ "vật dụng" gì nhé!
Để làm được điều này, chúng ta sẽ cần tới kỹ thuật theo dấu vật thể (Object Tracking) với sự hỗ trợ của thư viện OpenCV. Sau đó, để tăng tính "vui vẻ" cho nó, mình có ứng dụng mô hình Deep Learning vào để chơi trò chơi rất nổi tiếng của Google là QuickDraw .. Bắt đầu thôi!
Object Tracking (Theo dấu vật thể)
Đây là một bài toán cũng đang rất được quan tâm trong lĩnh vực xử lý ảnh vào thời điểm hiện nay bên cạnh sự gia tăng đáng kể cả về hiệu suất lẫn số lượng của các thuật toán Object Detection (Xác định vật thể). Theo dấu vật thể có rất nhiều ứng dụng hữu ích như: giám sát từ video, đếm số vật thể trong 1 vùng và đặc biệt là lấy các thông tin quan trọng về 1 đối tượng (trong lĩnh vực thể thao, phân tích dữ liệu vận động viên, ..)
Để có thể tracking một vật thể, công việc của chúng ta là sẽ phải đoán được các đường, hướng chuyển động của chúng bằng việc xác định lại vị trí của vật thể đó trong tất cả các frame. Nói một cách đơn giản, nếu không sử dụng object tracking, chúng ta sẽ phải liên tục sử dụng object detection cho từng khung hình, điều này làm lãng phí thời gian và công sức rất nhiều vì 2 lý do chính sau:
- Hiện nay đa số các thuật toán, phương pháp xác định vật thể (Object Detection) có độ chính xác tương đối đều đang đòi hỏi một khả năng tính toán khá lớn về mặt phần cứng, điều này tương đương với việc chúng sẽ tiêu tốn thời gian rất nhiều với các thiết bị phần cứng "bình thường", vậy nên việc liên tục chạy một mô hình Object Detection là điều rất hạn chế.
- Với việc sử dụng Object Detection, chúng ta xem như không "quan tâm" gì đến các thông tin về vị trí của vật thể mà chúng ta vừa lấy được ở các frame trước đó. Cứ mỗi frame, toàn bộ thông tin lấy được đều không còn giá trị nữa, trong khi chúng ta hoàn toàn có thể tiết kiệm công sức hơn vì trong thực tế vị trí của 1 vật thể sau 1 vài khung hình cũng không có nhiều sự thay đổi.
Với những lý do đó, việc nghiên cứu các mô hình Object Tracking trở nên quan trọng hơn, mong muốn tối ưu muốn đạt được thuật toán này có thể kể đến:
- Chỉ sử dụng thuật toán Object Detection tại frame đầu tiên để lấy ra vị trí vật thể cần tracking.
- Tốc độ nhanh hơn nhiều (rất nhiều) so với Object Detection
- Có thể xử lý khi vật thể bị mất khỏi video trong 1 vài frame
Trong khuôn khổ bài hướng dẫn, mình tập trung vào việc ứng dụng thuật toán để tạo ra sản phẩm mong muốn nên với những bạn quan tâm, các bạn có thể để lại câu hỏi cho mình dưới comment và tìm đọc thêm về các thuật toán Object Tracking ở đây.
Object Tracking với thư viện OpenCV
Có thể các bạn chưa biết, OpenCV cũng hỗ trợ cho chúng ta việc Object Tracking với các hàm thuật toán khác nhau để thực hiện việc này.
Lựa chọn thuật toán phù hợp
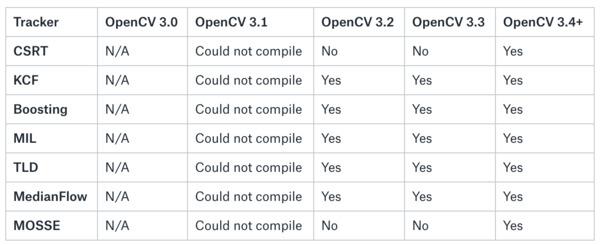
Có tổng cộng 8 thuật toán được OpenCV hỗ trợ bao gồm
- BOOSTING Tracker: Sử dụng học máy dựa trên các đặc tính Haar cascades
- MIL Tracker: Đạt độ chính cao hơn BOOSTING nhưng việc lấy lại vật thể bị mất là không thực sự hiệu quả
- KCF Tracker: <Kernelized Correlation Filters> Tốc độ nhanh hơn BOOSTING và MIL, nhưng cũng không hiệu quả trong việc xử lý vật thể bị mất 1 vài frame.
- CSRT Tracker: <Discriminative Correlation Filter> Đạt hiệu quả hơn KCF nhưng bù lại tốc độ bị giảm đi.
- MedianFlow Tracker: Đây là model xử lý rất tốt việc vật thể bị mất 1 vài frame, tuy nhiên, nếu vị trí của vật thể giữa các frame quá lớn (tốc độ di chuyển cao) thì MedianFlow không phải là lựa chọn tốt.
- TLD Tracker:
- MOSSE Tracker: Không chính xác bằng KCF, CSRT, nhưng điểm mạnh của thuật toán này là ở tốc độ. Tốc độ xử lý của nó là nhanh nhất trong số 8 thuật toán.
- GOTURN Tracker: Thuật toán duy nhất sử dụng Deep Learning
Lựa chọn: Tuỳ theo bài toán, tuỳ theo yêu cầu của các bạn, chúng ta sẽ chọn 1 thuật toán thích hợp. Theo kinh nghiệm, nếu bạn cần độ chính xác cao, tuy nhiên không bận tâm quá nhiều đến thời gian xử lý, hãy chọn CSRT. Trong trường hợp muốn cải thiện tốc độ hơn 1 chút hãy nghĩ đến KCF. Cuối cùng, nếu bạn cần 1 tốc độ lớn, thời gian xử lý nhỏ là ưu tiên số 1 thì chắc chắn nên dùng thuật toán Mosse
Python Code
Để sử dụng được 8 thuật toán trên, chúng ta cần cài thư viện OpenCV lẫn OpenCV-contrib với 2 lệnh sau
pip install opencv-python
pip install opencv-contrib-python
Ban đầu, chúng ta sẽ cần khai báo thư viện và các hằng số thể hiện cho thuật toán sẽ dùng
import cv2
import numpy as np
OPENCV_OBJECT_TRACKERS = {
"csrt": cv2.TrackerCSRT_create,
"kcf": cv2.TrackerKCF_create,
"boosting": cv2.TrackerBoosting_create,
"mil": cv2.TrackerMIL_create,
"tld": cv2.TrackerTLD_create,
"medianflow": cv2.TrackerMedianFlow_create,
"mosse": cv2.TrackerMOSSE_create
}
Khai báo các hằng số khác, ở đây mình sẽ dùng thuật toán CSRT
tracker = OPENCV_OBJECT_TRACKERS["csrt"]() #Using CSRT
initBB = None
Khai báo video mà chúng ta sử dụng để test
vs = cv2.VideoCapture("demo.avi")
Đọc video theo từng frame, resize về cố định, khởi tạo và thực hiện tracker của OpenCV (Nhằm hạn chế khối lượng cần phải xử lý, nếu video độ phân giải quá cao sẽ làm thuật toán bị chậm, vậy nên chúng ta sẽ giảm size của frame đưa vào)
while True:
_, frame = vs.read()
if frame is None:
break
frame = imutils.resize(frame, width=500)
frame = cv2.flip(frame, 1)
H, W, _ = frame.shape
if initBB is not None:
(success, box) = tracker.update(frame)
if success:
(x, y, w, h) = [int(v) for v in box]
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("s"):
initBB = cv2.selectROI("Frame", frame, fromCenter=False, showCrosshair=True)
tracker.init(frame, initBB)
elif key == ord("q"):
break
vs.release()
cv2.destroyAllWindows()
Hàm cv2.selectROI giúp chúng ta chọn trực tiếp 1 bounding box trên frame, trả lại cho chúng ta các toạ độ của box chúng ta vừa chọn (Ở đây chúng ta sẽ chọn box bao quanh vật chúng ta cần tracking). Sau đó khởi tạo tracker với các toạ độ đó. Tại mỗi frame, chúng ta update tracker và vẽ lại box bao quanh tracker 1 lần để tiện theo dõi và hiệu chỉnh code.
Để gọi đến hàm cv2.selectROI, chúng ta ấn phím "s". Chương trình dừng khi video kết thúc (Không còn frame nào) hoặc khi chúng ta ấn "q".Kết quả sẽ được như sau

Draw to your screen (Ứng dụng vẽ lên màn hình)
Đến đây chắc các bạn đã hình dung ra "cây đũa thần" của chúng ta là vật gì rồi. Nó có thể là bất-cứ-thứ-gì. Chúng ta sẽ dùng Object Tracking để theo dấu chuyển động của vật thể đó rồi hiển thị đường di chuyển của vật thể lên màn hình để tạo nên nét vẽ của mình.
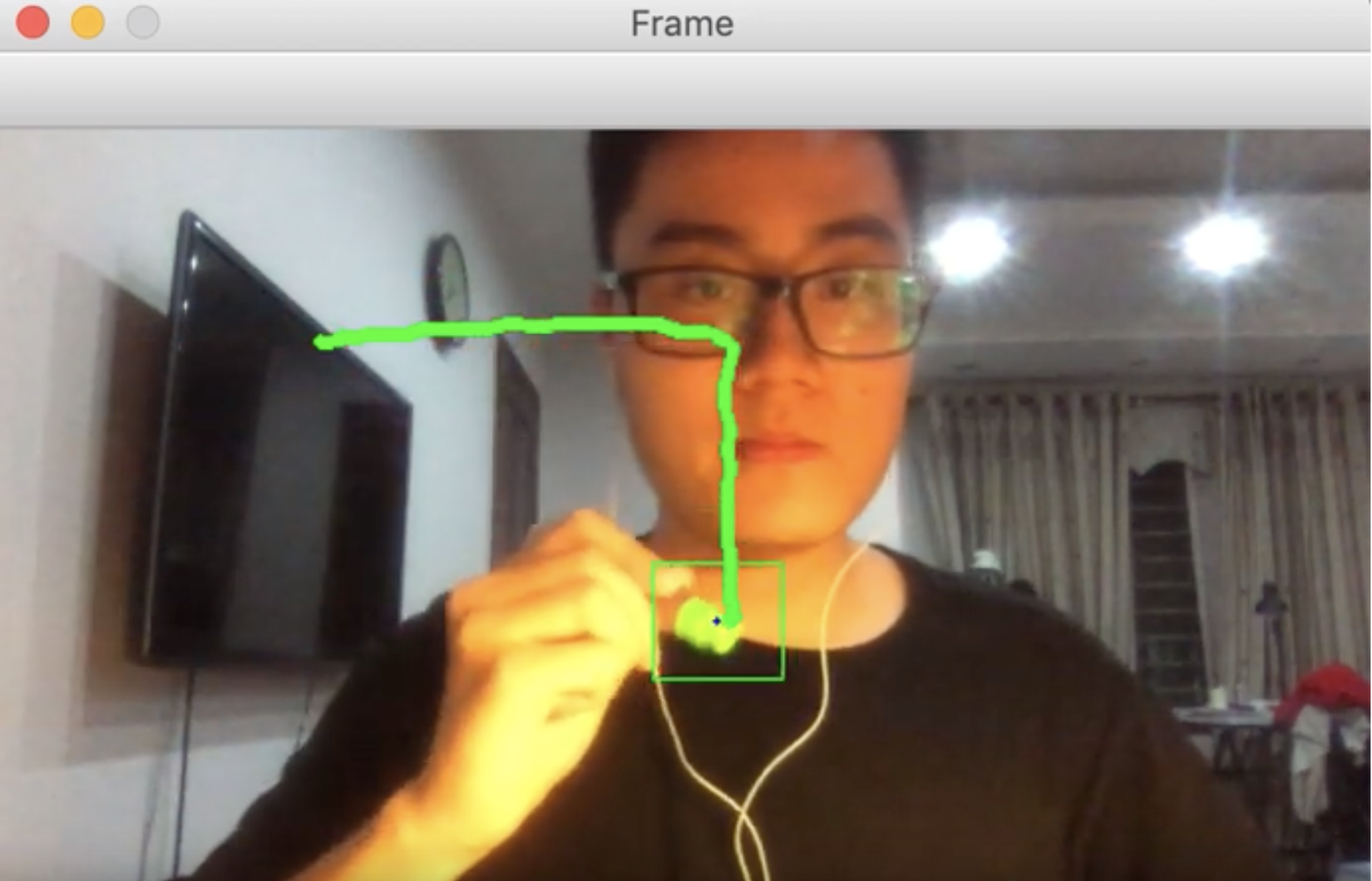
...
drawed = []
...
while True:
...
frame = cv2.flip(frame, 1)
for i in range(1, len(drawed)):
cv2.line(drawed, (drawed[i-1][0], drawed[i-1][1]), (drawed[i][0], drawed[i][1]), (0, 255, 0), 3)
...
if initBB is not None:
(success, box) = tracker.update(frame)
if success:
(x, y, w, h) = [int(v) for v in box]
cv2.rectangle(draw_frame, (x, y), (x + w, y + h),
(255, 0, 0), 2)
cv2.circle(draw_frame, (x + w//2,y + h//2), 1, (255, 0, 0), -1)
drawed.append([x + w//2, y + h//2])
Ý tưởng chính ở đây là, tại mỗi frame, chúng ta sẽ lấy ra và ghi lại tâm điểm (tung độ và hoành độ) của vật thể đang được tracking vào mảng drawed. Trước mỗi frame, chúng ta sẽ nối lần lượt các điểm đã ghi lại theo thứ tự lại để tạo ra đường di chuyển của vật thể với hàm cv2.line()
Quickdraw Game
Link trò chơi dành cho những bạn chưa biết: https://quickdraw.withgoogle.com/

Luật chơi rất đơn giản, bạn sẽ được thử thách vẽ ra một vật thể. Bạn sẽ vẽ trong thời gian 15s liên tục sao cho AI của Google đoán được vật bạn đang vẽ chính là vật được yêu cầu. Vậy giờ chúng ta sẽ chơi trò chơi này, và chúng ta cần một mô hình để "nhận ra" hình vẽ của chúng ta đang vẽ là gì!
Thu thập và xử lý tập dữ liệu
Google Quickdraw cung cấp cho chúng ta "rất rất rất" nhiều dữ liệu về hình vẽ tay của tất cả các người chơi trên thế giới. Tất nhiên là kèm theo nhãn. Bộ dữ liệu này cũng đã từng được đem thi các challenge của Kaggle với giải thưởng lên đến vài chục nghìn USD. Ngoài ra bộ dataset này do tính đa dạng, phân vùng của nó mà nó còn được sử dụng để phân tích tính cách, xu hướng của những người dân thuộc các quốc gia trên thế giới.
Các bạn có thể đọc bài báo phân tích con người các quốc gia dựa trên xu hướng vẽ hình tròn này:
https://qz.com/994486/the-way-you-draw-circles-says-a-lot-about-you/
Và mình tin với lượng dữ liệu khổng lồ về hình vẽ tay này, chúng ta sẽ còn phân tích và học hỏi được rất nhiều điều.
Vào vấn đề chính, ở đây, để demo, mình sẽ chỉ lấy toàn bộ dữ liệu vẽ tay của 3 class: Square (Hình vuông/ chữ nhật), Triangle (Hình tam giác) và Circle (Hình tròn). Các bạn có thể tăng độ khó, độ hấp dẫn cho game bằng cách lấy dữ liệu của nhiều class hơn nhé!!

Dữ liệu của chúng ta được đưa về dưới dạng list gồm (số lượng items x784). Số 784 ở đây là dạng flatten của 28x28, chúng ta sẽ resize về (28, 28) để tiện áp dụng cho mạng Deep Learning.
import numpy as np
images = []
labels = []
for s in square:
images.append(s)
labels.append(0)
for c in circle:
images.append(c)
labels.append(1)
for t in triangle:
images.append(t)
labels.append(2)
images = np.array(images)/255.
images = np.reshape(images, (-1, 28, 28))
Chia tập train test
Chúng ta tiến hành trộn ngẫu nhiên tập dữ liệu rồi chia tập huấn luyện, tập test để theo dõi quá trình training nhằm đảm bảo model không bị Overfit hay Underfit
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
images, labels = shuffle(images, labels, random_state=0)
X_train, X_test, y_train, y_test = train_test_split(
images, labels, test_size=0.2, random_state=42)
Xây dựng và huấn luyện Deep Learning Model
Chúng ta sẽ xây dựng 1 model đơn giản bằng keras để phân loại được bài toán này
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
batch_size = 128
num_classes = 3
epochs = 10
# input image dimensions
img_rows, img_cols = 28, 28
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',input_shape=(img_rows, img_cols, 1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
 Chọn hàm loss là categorical_crossentropy và optimizer là Adam
Chọn hàm loss là categorical_crossentropy và optimizer là Adam
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
Tiến hành training
model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(X_test, y_test))
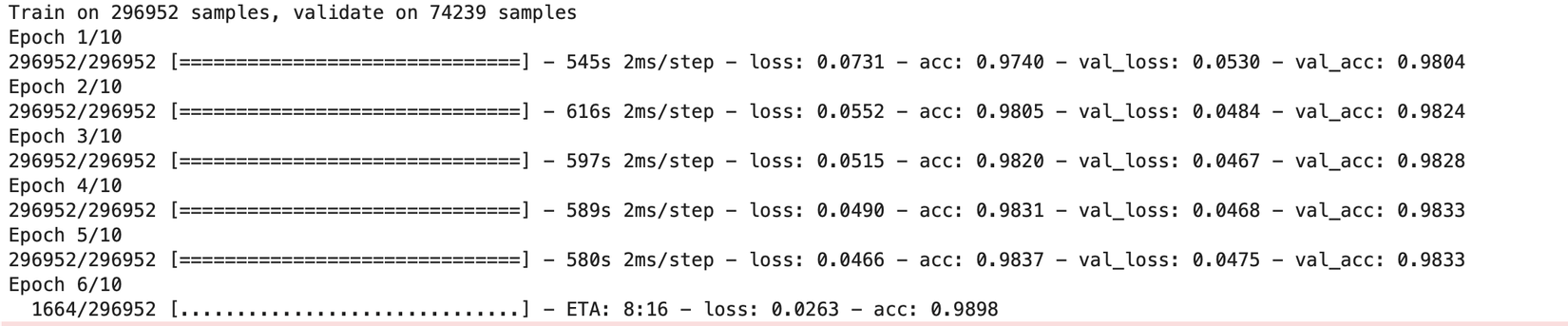
Mình quyết định dừng ở epoch thứ 5 khi thấy loss trên tập validation có vẻ không còn giảm được nữa. Kết quả rất khả quan với độ chính xác phân loại 98.33% trên tập validation.
Lấy kết quả dự đoán và áp dụng
Tạo input tối ưu cho mô hình
Chúng ta sẽ chỉ đưa những phần "vẽ tay" vào trong mô hình để đạt hiệu quả cao nhất. Vậy nên chúng ta sẽ phải tạo ra một đầu vào dựa trên những gì chúng ta vừa vẽ.
xmin, ymin = np.min(drawed, 0)
xmax, ymax = np.max(drawed, 0)
table_width = xmax - xmin + 20
table_height = ymax - ymin + 20
table = np.zeros((table_height, table_width, 3))
for i in range(1, len(drawed)):
cv2.line(table, (drawed[i-1][0]-xmin+10, drawed[i-1][1]-ymin+10), (drawed[i][0]-xmin+10, drawed[i][1]-ymin+10), (255, 255, 255), 3)
Ở đây mình sẽ crop ra hình ảnh phần vẽ tay chúng ta thực hiện, sau đó paddding mỗi phía vào 10 pixels để có đầu vào giống đầu vào chúng ta đã huấn luyện nhất. Đây là kết quả chúng ta mong muốn thu được để đưa vào model dự đoán
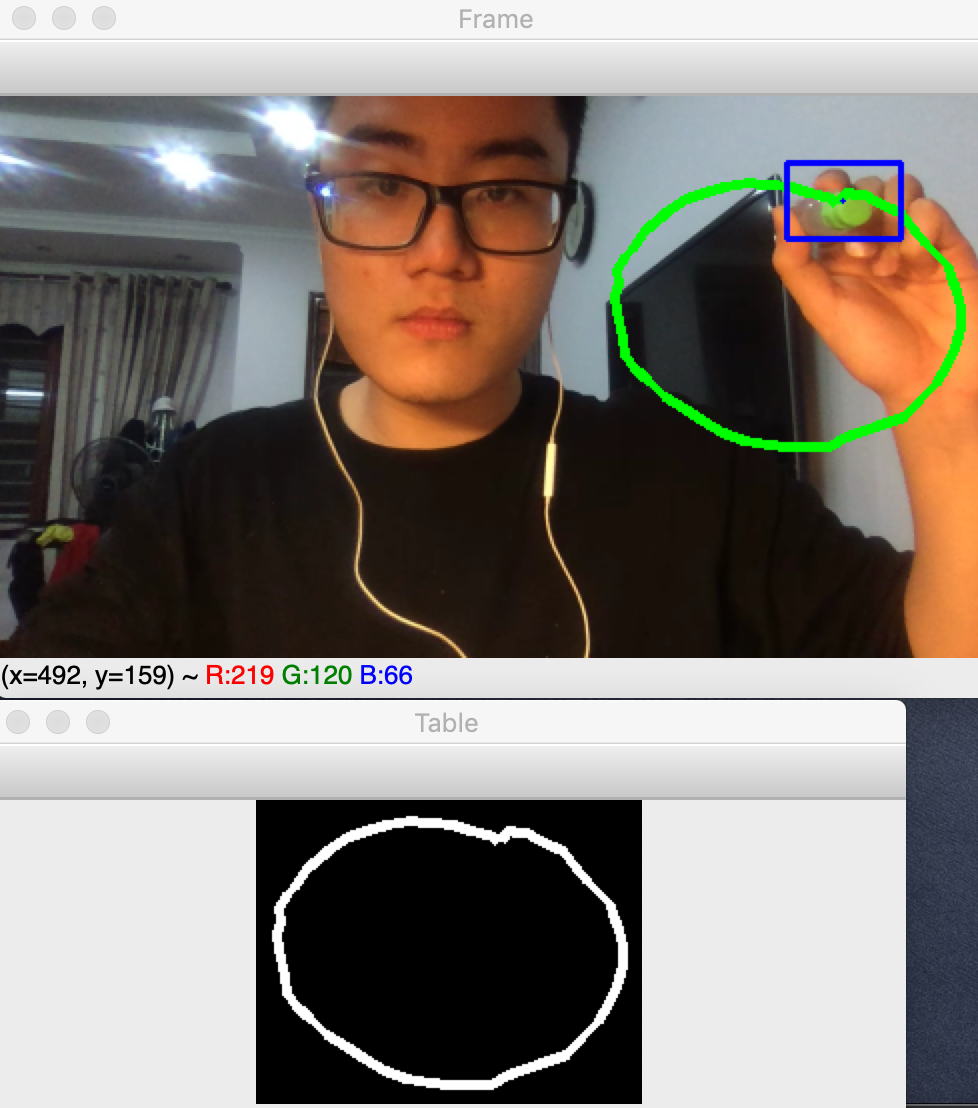
Hiển thị kết quả dự đoán
Mỗi khi ấn phím "d", chúng ta sẽ thực hiện chuẩn hoá ảnh trên rồi đưa vào model, lấy kết quả predict ra rồi hiển thị kết quả liên tiếp trong 20 frames kế tiếp (để người xem kịp nhìn). Và xoá những gì đã vẽ.
...
result = ""
delay_text = 0
..
while True:
if delay_text > 0:
cv2.putText(draw_frame, result, (W//2 - 30, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
...
if key == ord("d"):
delay_text = 20
xmin, ymin = np.min(drawed, 0)
xmax, ymax = np.max(drawed, 0)
table_width = xmax - xmin + 20
table_height = ymax - ymin + 20
table = np.zeros((table_height, table_width, 3))
for i in range(1, len(drawed)):
cv2.line(table, (drawed[i-1][0]-xmin+10, drawed[i-1][1]-ymin+10), (drawed[i][0]-xmin+10, drawed[i][1]-ymin+10), (255, 255, 255), 3)
table = cv2.resize(table, (28, 28))
table = table[:, :, 0]/255.
table = np.expand_dims(table, 0)
table = np.expand_dims(table, -1)
predictions = np.argmax(model.predict(table)[0])
if predictions == 0:
result = "Square"
elif predictions == 1:
result = "Circle"
else:
result = "Triangle"
drawed = []
delay_text -= 1
Kết quả
Video demo kết quả ứng dụng chúng ta vừa làm được
Để tiện theo dõi hơn cho các bạn, mình cũng đã đẩy code lên github ở link sau:
https://github.com/hoanganhpham1006/Draw-to-your-screen
Bài viết của mình còn nhiều sai sót, hãy comment giúp mình những phần các bạn cảm thấy khó hiểu hoặc cảm thấy chưa hợp lý trong quá trình áp dụng nhé. Chúc các bạn thành công
All rights reserved
