
Ask Me Anything - Question Answering với Deep Learning
Bài đăng này đã không được cập nhật trong 7 năm
Hệ thống trả lời câu hỏi (Question Answering System)

Hệ thống trả lời câu hỏi được định nghĩa là một mô hình có khả năng trả lời những câu hỏi được đưa ra bằng ngôn ngữ tự nhiên của con người. Chương trình sẽ tạo ra câu trả lời cho chúng ta bằng cách truy vấn/ tìm kiếm ở trong một hệ tri thức nào đó (hay hiểu đơn giản là một nguồn thông tin, một kho kiến thức). Thông thường, hệ tri thức đó là do chúng ta cung cấp cho mô hình từ một vài thông tin trước đó, một vài tài liệu hay thậm chí là từ một trang web có chứa lượng thông tin đầy đủ như Wikipedia.
Chúng ta có thể tạm chia hệ thống trả lời câu hỏi ra thành 2 loại, dựa trên nguồn thông tin mà nó sử dụng để đưa ra câu trả lời.
- Nguồn thông tin mở (Open domain): Hệ thống có thể trả lời được tất cả các câu hỏi về mọi chủ đề, không yêu cầu câu hỏi phải tập trung vào 1 nguồn, 1 lĩnh vực nào đó. Điều này có nghĩa là hệ kiến thức cơ sở của chúng ta sẽ phải đảm bảo được độ lớn, độ sau và độ phức tạp rất cao.
- Nguồn thông tin giới hạn/ đóng (Closed domain): Hệ thống sẽ tìm ra thông tin để trả lời nhưng chỉ dựa trên từ 1 nguồn thông tin hết sức hạn chế hoặc từ 1 lĩnh vực cụ thể.
Hiện nay có khá nhiều phương pháp để giải quyết cho vấn đề này, có thể kể đến cả những phương pháp truy vấn cơ sở dữ liệu truyền thống mà không cần đến Machine Learning. Tuy nhiên, các phương pháp mới nhất đều sử dụng những mô hình Deep Learning và đem lại những kết quả ấn tượng.
Trong bài viết lần này, khó với những lần trước một chút, không còn là những ứng dụng đơn giản, mình sẽ hướng dẫn các bạn tạo ra được một hệ thống trả lời câu hỏi bằng Deep learning với Tensorflow. Hệ thống này mình cài đặt dựa trên ý tưởng và sự nghiên cứu của mình về một papers khá mới Ask Me Anything: Dynamic Memory Networks for Natural Language Processing. Papers sử dụng một kỹ thuật có tên là Memory Networks và giải quyết dựa trên nguồn thông tin đóng. Bắt đầu thôi!
Xây dựng hệ thống trả lời câu hỏi với Tensorflow
Bước chuẩn bị
Các thư viện cần dùng
Ngoài Tensorflow, chúng ta sẽ cần cài đặt thêm 2 thư viện khác rất tiện lợi đó là Numpy và Matplotlib. Các thư viện còn lại đều đã có sẵn khi cài đặt Python. Cụ thể chúng ta sẽ import vào các thư viện dưới đây
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import urllib
import sys
import os
import zipfile
import tarfile
import json
import hashlib
import re
import itertools
Dataset cho bài toán Question Answering
Chúng ta sẽ sử dụng đến một dataset dành riêng cho việc huấn luyện các mô hình trả lời câu hỏi dựa trên nguồn đóng của Facebook Research có tên bAbI. Các bạn có thể tìm hiểu thêm về tập dữ liệu này ở trang web dưới đây
Facebook's Dataset babI: https://research.fb.com/downloads/babi/
Lý do mình thử trên tập dataset này là bởi tất cả các câu hỏi trong tập dữ liệu sẽ đều được cung cấp tương ứng với những thông tin ngữ cảnh (context information) có chứa câu trả lời. Ngoài ra, Đây cũng là một tập dữ liệu tương đối lớn, được chia cụ thể ra thành 20 vấn đề cụ thể (tasks) của bài toán trả lời câu hỏi. Trong bài này chúng ta sẽ sử dụng task số 5 - Một task mà mỗi ngữ cảnh sẽ có thông tin về những hành động của 3 chủ thể (Three Argument Relations). Một trong những ví dụ về task #5 chính là ở bức ảnh mình để ngay trên đầu bài viết này.

Tập dữ liệu trên được xây dựng với ngôn ngữ là tiếng Anh, nhưng chỉ cần nhìn 1 chút, các bạn cũng có thể thấy 1 vấn đề đó là để đưa ra được câu trả lời, thì ngoài việc phải xác định được rõ hành động nào là của chủ thế nào, mô hình cũng phải có khả năng phân biệt được những từ ngữ miêu tả 1 hành động như nhau. Ví dụ ở trên như 2 từ "passed" và "handed" đều có nghĩa là "đưa cho", thậm chí trong câu hỏi, chúng ta lại có 1 từ khác để nói về hành động này là từ "give". Tức là ở đây, chúng ta cần mô hình còn phải có khả năng hiểu về nghĩa của từ chứ không chỉ đơn giản là tìm những từ giống nhau.
Mô hình pretrained Word2Vec - GloVed
Để làm được vấn đề vừa rồi gặp phải, nếu là một người đã có những hiểu biết về học máy, chắc chắn các bạn sẽ nghĩ ngay đến việc sử dụng mô hình word2vec. Và đó cũng chính là cách mình sử dụng cho bài viết lần này.
Ngoài lề một chút về phương pháp word2vec, các bạn quan tâm có thể tham khảo 2 bài viết sau mà theo mình là cực kỳ dễ hiểu và chất lượng của tác giả Quang Phạm:
Để tập trung vào mô hình question answer, chúng ta sẽ sử dụng sẵn một mô hình đã được huấn luyện cho bài toán word2vec có tên là GloVed. Đây là một mô hình biểu diễn từ được công bố mở của một trong những nơi phát triển nhất về công nghệ thông tin nói chung trên toàn thế giới - Stanford. Các bạn có thể tìm hiểu thêm thông tin, cũng như tải xuống mô hình này để chúng ta sử dụng ở đây
Stanford's Global Vectors for Word Representation: https://nlp.stanford.edu/projects/glove/
Sau khi tải xuống toàn bộ thư viện, dataset và pretrained model trên, chúng ta đã sẵn sàng để bắt đầu xây dựng mô hình của mình :D
Tiền xử lý dữ liệu
Lúc đầu, chúng ta sẽ đọc vào pretrained model đã tải xuống, tạo một cơ chế dành cho những từ chưa xuất hiện trong mô hình bằng với hàm fill_unk.
glove_vectors_file = "glove.6B/glove.6B.50d.txt"
glove_wordmap = {}
with open(glove_vectors_file, "r", encoding="utf8") as glove:
for line in glove:
name, vector = tuple(line.split(" ", 1))
glove_wordmap[name] = np.fromstring(vector, sep=" ")
wvecs = []
for item in glove_wordmap.items():
wvecs.append(item[1])
s = np.vstack(wvecs)
# Gather the distribution hyperparameters
v = np.var(s,0)
m = np.mean(s,0)
RS = np.random.RandomState()
def fill_unk(unk):
global glove_wordmap
glove_wordmap[unk] = RS.multivariate_normal(m,np.diag(v))
return glove_wordmap[unk]
Ngoài ra chúng ta còn cần phải khai báo nơi lưu các file dataset đã tải về.
#Select "task 5"
train_set_file = "qa5_three-arg-relations_train.txt"
test_set_file = "qa5_three-arg-relations_test.txt"
train_set_post_file = "tasks_1-20_v1-2/en/"+train_set_file
test_set_post_file = "tasks_1-20_v1-2/en/"+test_set_file
Hãy mở tập dữ liệu lên để nhìn qua một lượt nhé
1 Fred picked up the football there.
2 Fred gave the football to Jeff.
3 What did Fred give to Jeff? football 2
4 Bill went back to the bathroom.
5 Jeff grabbed the milk there.
6 Who gave the football to Jeff? Fred 2
7 Jeff gave the football to Fred.
8 Fred handed the football to Jeff.
9 What did Fred give to Jeff? football 8
10 Jeff handed the football to Fred.
11 Fred gave the football to Jeff.
12 Who did Fred give the football to? Jeff 11
13 Jeff gave the football to Fred.
14 Jeff put down the milk.
15 Who did Jeff give the football to? Fred 13
1 Mary moved to the hallway.
2 Jeff moved to the garden.
...
Chúng ta có thể rút ra được những điều sau. Cấu trúc của dataset bAbI được chia thành các context, mỗi thông tin đều được đánh số thứ tự. Mỗi khi chuyển sang context khác, thứ tự sẽ được đặt lại từ 1. Những thông tin sẽ được kết thúc bằng dấu ".", còn những câu hỏi sẽ là "?". Với mỗi câu hỏi, câu trả lời sẽ được để bên cạnh, còn số bên cạnh câu trả lời được ghi rõ trong phần mô tả là thông tin gợi ý liên quan đến câu hỏi đó (Tuy nhiên chúng ta sẽ không dùng đến thông tin này).
Trong bài viết lần này, để dễ dàng hơn cho việc huấn luyện mô hình ở bước tiếp theo, từ file dữ liệu nói trên, chúng ta sẽ phải tạo ra các input mà mỗi input sẽ bao gồm đầy đủ các thông tin: Context, Question và Answer. Điều quan trọng là input của chúng ta đều sẽ phải được chuyển về dưới dạng các vector số thực dựa vào pretrained GloVe nhé. Chúng ta sẽ có 3 hàm dưới đây để làm được tất cả các điều này
def sentence2sequence(sentence):
"Input: paragraph/ Output: (m, d) matrix - d 50, m number of tokens"
tokens = sentence.strip('"(),-').lower().split(" ")
rows = []
words = []
#Greedy search for tokens
for token in tokens:
i = len(token)
while len(token) > 0:
word = token[:i]
if word in glove_wordmap:
rows.append(glove_wordmap[word])
words.append(word)
token = token[i:]
i = len(token)
continue
else:
i = i-1
if i == 0:
rows.append(fill_unk(token))
words.append(token)
break
return np.array(rows), words
def contextualize(set_file):
"""
Read in the dataset of questions and build question+answer -> context sets.
Output is a list of data points, each of which is a 7-element tuple containing:
1. The sentences in the context in vectorized form.
2. The sentences in the context as a list of string tokens.
3. The question in vectorized form.
4. The question as a list of string tokens.
5. The answer in vectorized form.
6. The answer as a list of string tokens.
7. A list of numbers for supporting statements, which is currently unused.
"""
data = []
context = []
with open(set_file, "r", encoding="utf8") as train:
for line in train:
l, ine = tuple(line.split(" ", 1))
# Split the line numbers from the sentences they refer to.
if l is "1":
# New contexts always start with 1,
# so this is a signal to reset the context.
context = []
if "\t" in ine:
# Tabs are the separator between questions and answers,
# and are not present in context statements.
question, answer, support = tuple(ine.split("\t"))
data.append((tuple(zip(*context))+
sentence2sequence(question)+
sentence2sequence(answer)+
([int(s) for s in support.split()],)))
# Multiple questions may refer to the same context, so we don't reset it.
else:
# Context sentence.
context.append(sentence2sequence(ine[:-1]))
return data
def finalize(data):
final_data = []
for cqas in data:
contextvs, contextws, qvs, qws, avs, aws, spt = cqas
lengths = itertools.accumulate(len(cvec) for cvec in contextvs)
context_vec = np.concatenate(contextvs)
context_words = sum(contextws,[])
# Location markers for the beginnings of new sentences.
sentence_ends = np.array(list(lengths))
final_data.append((context_vec, sentence_ends, qvs, spt, context_words, cqas, avs, aws))
return np.array(final_data)
Hàm sequence2sequence có mục đích là biến các câu (tập hợp của từ) thành các tập hợp vector. Chúng ta đầu tiên sẽ phải tách các từ trong câu, rồi chuyển hoá các từ đó thành ra các vector rồi lại nối chúng lại.
Hàm contextualize thực hiện việc đọc và xử lý các dòng của file input. Còn hàm finalize chỉ có nhiệm vụ là sắp đặt lại input cho phù hợp / chính xác nhất với đầu vào mô hình của chúng ta.
Sau khi xong xuôi, chúng ta đã sẵn sàng lấy vào dữ liệu để chuẩn bị cho bước tiếp theo!!
train_data = contextualize(train_set_post_file)
test_data = contextualize(test_set_post_file)
final_train_data = finalize(train_data)
final_test_data = finalize(test_data)
Xây dựng mô hình Memory Networks (*)
Những lưu ý nhỏ trước khi bắt đầu
Lưu ý: Như mình đã nói, mô hình này mình đang thực hiện implement dựa trên papers Ask Me Anything: Dynamic Memory Networks for Natural Language Processing, vẫn còn khá mới hiện nay, chính vì vậy đây là phần sẽ mất thêm của các bạn thời gian rất nhiều nểu bạn là một người luôn muốn hiểu rõ ràng mọi thứ. Bản thân mình cũng đã mất khoảng 1 tháng để có thể khiến mọi thứ bớt mông lung. Vậy nên dù muốn hay không, mình nghĩ các bạn cũng hãy dành công sức nhất định để đọc và hình dung được rõ ràng hơn. Trong khuôn khổ bài viết này, mình cũng sẽ cố gắng giải thích hết sức có thể cho các bạn 1 phần nào đó của phương pháp.
Lưu ý: Để có thể dễ dàng trong việc cài đặt lại phương pháp Memory Networks, các bạn sẽ cần phải có những hiểu biết về mạng Recurrent Neural Network và cơ chế Attention của Deep Learning. Đây là 2 thuật toán chính, tạo nên sự đột phá của phương pháp này. Một số bài viết có thể giúp ích cho các bạn
RNN : Tạo Language Model để tự động sinh văn bản tiếng Việt - một bài viết cũ hơn của mình
Cơ chế Attention: [Machine Learning] Attention, Attention, Attention, ...! - một bài viết hay về lý thuyết cũng như ứng dụng của Attention của tác giả Phan Hoàng
Vậy đủ rồi, vào code thôi  .
.
Hyperparameters
Như bao mô hình khác, chúng ta khai báo các hyperparameters cho mô hình của mình
tf.reset_default_graph()
# The number of dimensions used to store data passed between recurrent layers in the network.
recurrent_cell_size = 128
# The number of dimensions in our word vectorizations.
D = 50
learning_rate = 0.005
# Dropout probabilities
input_p, output_p = 0.5, 0.5
batch_size = 128
# Number of passes in episodic memory
passes = 4
# Feed Forward layer sizes: the number of dimensions used to store data passed from feed-forward layers.
ff_hidden_size = 256
weight_decay = 0.00000001
# The strength of our regularization. Increase to encourage sparsity in episodic memory,
# but makes training slower. Don't make this larger than leraning_rate.
training_iterations_count = 400000
# How many questions the network trains on each time it is trained.
# Some questions are counted multiple times.
display_step = 100
# How many iterations of training occur before each validation check.
Tổng quan về mô hình
 Nhìn chung, Memory Network được xây dựng dựa trên cách tiếp cận của chính chúng ta khi trả lời các câu hỏi sau khi đọc các bài "Đọc-Hiểu". Điều này sẽ dễ hình dung hơn cho các bạn đang thường xuyên phải đi học ngoại ngữ phải không =)). Đầu tiên, chúng ta sẽ đọc toàn bộ các câu trong bài viết một lượt (Context) và sẽ cố ghi nhớ các thông tin, tiếp theo chúng ta sẽ gặp phải các câu hỏi (Question) về bài viết đó. Câu trả lời (Answer) chúng ta đưa ra sẽ dựa trên việc chúng ta thực hiện một vài sự so sánh câu hỏi nhận được với từng thông tin mà chúng ta đã ghi nhớ được vừa rồi để tạo ra sự suy diễn ngược dần dần.
Nhìn chung, Memory Network được xây dựng dựa trên cách tiếp cận của chính chúng ta khi trả lời các câu hỏi sau khi đọc các bài "Đọc-Hiểu". Điều này sẽ dễ hình dung hơn cho các bạn đang thường xuyên phải đi học ngoại ngữ phải không =)). Đầu tiên, chúng ta sẽ đọc toàn bộ các câu trong bài viết một lượt (Context) và sẽ cố ghi nhớ các thông tin, tiếp theo chúng ta sẽ gặp phải các câu hỏi (Question) về bài viết đó. Câu trả lời (Answer) chúng ta đưa ra sẽ dựa trên việc chúng ta thực hiện một vài sự so sánh câu hỏi nhận được với từng thông tin mà chúng ta đã ghi nhớ được vừa rồi để tạo ra sự suy diễn ngược dần dần.
Cụ thể hơn một chút để dễ hình dung, như ví dụ ở trong ảnh trên (Ảnh được mình cắt ra trực tiếp từ paper đó). Với câu hỏi về địa điểm của "quả bóng đá", mô hình đầu tiên sẽ cố gắng tập trung vào các thông tin có chứa từ này, nó sẽ nhận ra có vẻ John sẽ là người cuối cùng có hành động liên quan đến "quả bóng đá". Tiếp tục so sánh với các thông tin ghi nhớ được, mô hình sẽ cần biết được rằng giờ sẽ phải tập trung tìm kiếm vào các thông tin nói về John và sẽ biết được địa điểm cuối cùng mà John đến là hành lang. Đây có vẻ cũng là cách tiếp cận thông thường của bộ não con người.
Tóm tắt lại, phương pháp này vừa đòi hỏi chúng ta sử dụng kỹ thuật để ghi nhớ thông tin từ ngữ cảnh (Context) - phương pháp RNN, vừa đòi hỏi chúng ta xây dựng 1 thuật toán, để giúp mô hình đặt trọng số và tăng độ quan trọng của những thông tin nào đó lên mỗi khi tìm ra được 1 chi tiết đặc biệt - đây chính là cái gọi là cơ chế Attention.
Có tổng cộng 4 module và giờ chúng ta sẽ lần lượt đi code lại từng module đó.
Input Module
Module này sẽ có nhiệm vụ là lưu trữ các thông tin ngữ cảnh (Context). Module sử dụng một lớp RNN và lấy ra các output tại các time-series tương ứng với phần kết thúc của từng câu. Đây là một trong những cách rất hay để biểu diễn 1 câu thành 1 vector số thực. Cụ thể ở đây, chúng ta sử dụng cell GRU.
# Context: A [batch_size, maximum_context_length, word_vectorization_dimensions] tensor
# that contains all the context information.
context = tf.placeholder(tf.float32, [None, None, D], "context")
context_placeholder = context # use context as a variable name later on
# input_sentence_endings: A [batch_size, maximum_sentence_count, 2] tensor that
# contains the locations of the ends of sentences.
input_sentence_endings = tf.placeholder(tf.int32, [None, None, 2], "sentence")
# recurrent_cell_size: the number of hidden units in recurrent layers.
input_gru = tf.contrib.rnn.GRUCell(recurrent_cell_size)
# input_p: The probability of maintaining a specific hidden input unit.
# Likewise, output_p is the probability of maintaining a specific hidden output unit.
gru_drop = tf.contrib.rnn.DropoutWrapper(input_gru, input_p, output_p)
# dynamic_rnn also returns the final internal state. We don't need that, and can
# ignore the corresponding output (_).
input_module_outputs, _ = tf.nn.dynamic_rnn(gru_drop, context, dtype=tf.float32, scope = "input_module")
# cs: the facts gathered from the context.
cs = tf.gather_nd(input_module_outputs, input_sentence_endings)
# to use every word as a fact, useful for tasks with one-sentence contexts
s = input_module_outputs
Question Module
Nhiệm vụ của module này là lưu thông tin của câu hỏi. Phương pháp sử dụng giống hệt như của Input Module nên mình sẽ không phải nhắc lại nữa.
# query: A [batch_size, maximum_question_length, word_vectorization_dimensions] tensor
# that contains all of the questions.
query = tf.placeholder(tf.float32, [None, None, D], "query")
# input_query_lengths: A [batch_size, 2] tensor that contains question length information.
# input_query_lengths[:,1] has the actual lengths; input_query_lengths[:,0] is a simple range()
# so that it plays nice with gather_nd.
input_query_lengths = tf.placeholder(tf.int32, [None, 2], "query_lengths")
question_module_outputs, _ = tf.nn.dynamic_rnn(gru_drop, query, dtype=tf.float32,
scope = tf.VariableScope(True, "input_module"))
# q: the question states. A [batch_size, recurrent_cell_size] tensor.
q = tf.gather_nd(question_module_outputs, input_query_lengths)
Episodic Memory Module
Đây là phần mà mình cho là thú vị nhất của paper này. Tại module này, các thông tin ngữ cảnh đang được lưu trữ (Context) sẽ được so sánh với câu hỏi (Question) nhiều lần, và sau mỗi lần cơ chế Attention sẽ lại được gọi đến để đánh dấu ra những thông tin quan trọng, cần phải chú ý hơn để dùng cho vòng lặp tiếp theo. Vậy là sau mỗi lần lặp lại trong Episodic Memory Module, trọng số của từng thông tin trong Context sẽ có sự thay đổi, đó chính là kết quả của việc tìm kiếm thông tin mà chúng ta đang cần. Những thông tin có chứa những "vật thể" hay "hành động" được nhận thấy là liên quan đến câu hỏi sẽ được chú ý. Hãy tham khảo đoạn code dưới đây.
# make sure the current memory (i.e. the question vector) is broadcasted along the facts dimension
size = tf.stack([tf.constant(1),tf.shape(cs)[1], tf.constant(1)])
re_q = tf.tile(tf.reshape(q,[-1,1,recurrent_cell_size]),size)
# Final output for attention, needs to be 1 in order to create a mask
output_size = 1
# Weights and biases
attend_init = tf.random_normal_initializer(stddev=0.1)
w_1 = tf.get_variable("attend_w1", [1,recurrent_cell_size*7, recurrent_cell_size],
tf.float32, initializer = attend_init)
w_2 = tf.get_variable("attend_w2", [1,recurrent_cell_size, output_size],
tf.float32, initializer = attend_init)
b_1 = tf.get_variable("attend_b1", [1, recurrent_cell_size],
tf.float32, initializer = attend_init)
b_2 = tf.get_variable("attend_b2", [1, output_size],
tf.float32, initializer = attend_init)
# Regulate all the weights and biases
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, tf.nn.l2_loss(w_1))
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, tf.nn.l2_loss(b_1))
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, tf.nn.l2_loss(w_2))
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, tf.nn.l2_loss(b_2))
def attention(c, mem, existing_facts):
"""
Custom attention mechanism.
c: A [batch_size, maximum_sentence_count, recurrent_cell_size] tensor
that contains all the facts from the contexts.
mem: A [batch_size, maximum_sentence_count, recurrent_cell_size] tensor that
contains the current memory. It should be the same memory for all facts for accurate results.
existing_facts: A [batch_size, maximum_sentence_count, 1] tensor that
acts as a binary mask for which facts exist and which do not.
"""
with tf.variable_scope("attending") as scope:
# attending: The metrics by which we decide what to attend to.
attending = tf.concat([c, mem, re_q, c * re_q, c * mem, (c-re_q)**2, (c-mem)**2], 2)
# m1: First layer of multiplied weights for the feed-forward network.
# We tile the weights in order to manually broadcast, since tf.matmul does not
# automatically broadcast batch matrix multiplication as of TensorFlow 1.2.
m1 = tf.matmul(attending * existing_facts,
tf.tile(w_1, tf.stack([tf.shape(attending)[0],1,1]))) * existing_facts
# bias_1: A masked version of the first feed-forward layer's bias
# over only existing facts.
bias_1 = b_1 * existing_facts
# tnhan: First nonlinearity. In the original paper, this is a tanh nonlinearity;
# choosing relu was a design choice intended to avoid issues with
# low gradient magnitude when the tanh returned values close to 1 or -1.
tnhan = tf.nn.relu(m1 + bias_1)
# m2: Second layer of multiplied weights for the feed-forward network.
# Still tiling weights for the same reason described in m1's comments.
m2 = tf.matmul(tnhan, tf.tile(w_2, tf.stack([tf.shape(attending)[0],1,1])))
# bias_2: A masked version of the second feed-forward layer's bias.
bias_2 = b_2 * existing_facts
# norm_m2: A normalized version of the second layer of weights, which is used
# to help make sure the softmax nonlinearity doesn't saturate.
norm_m2 = tf.nn.l2_normalize(m2 + bias_2, -1)
# softmaxable: A hack in order to use sparse_softmax on an otherwise dense tensor.
# We make norm_m2 a sparse tensor, then make it dense again after the operation.
softmax_idx = tf.where(tf.not_equal(norm_m2, 0))[:,:-1]
softmax_gather = tf.gather_nd(norm_m2[...,0], softmax_idx)
softmax_shape = tf.shape(norm_m2, out_type=tf.int64)[:-1]
softmaxable = tf.SparseTensor(softmax_idx, softmax_gather, softmax_shape)
return tf.expand_dims(tf.sparse_tensor_to_dense(tf.sparse_softmax(softmaxable)),-1)
# facts_0s: a [batch_size, max_facts_length, 1] tensor
# whose values are 1 if the corresponding fact exists and 0 if not.
facts_0s = tf.cast(tf.count_nonzero(input_sentence_endings[:,:,-1:],-1,keep_dims=True),tf.float32)
with tf.variable_scope("Episodes") as scope:
attention_gru = tf.contrib.rnn.GRUCell(recurrent_cell_size)
# memory: A list of all tensors that are the (current or past) memory state
# of the attention mechanism.
memory = [q]
# attends: A list of all tensors that represent what the network attends to.
attends = []
for a in range(passes):
# attention mask
attend_to = attention(cs, tf.tile(tf.reshape(memory[-1],[-1,1,recurrent_cell_size]),size),
facts_0s)
# Inverse attention mask, for what's retained in the state.
retain = 1-attend_to
# GRU pass over the facts, according to the attention mask.
while_valid_index = (lambda state, index: index < tf.shape(cs)[1])
update_state = (lambda state, index: (attend_to[:,index,:] *
attention_gru(cs[:,index,:], state)[0] +
retain[:,index,:] * state))
# start loop with most recent memory and at the first index
memory.append(tuple(tf.while_loop(while_valid_index,
(lambda state, index: (update_state(state,index),index+1)),
loop_vars = [memory[-1], 0]))[0])
attends.append(attend_to)
# Reuse variables so the GRU pass uses the same variables every pass.
scope.reuse_variables()
Answer Module
Điều Module này sẽ phải thực hiện, là từ đầu ra của Module Episodic Memory (những thông tin được đánh trọng số sau những vòng lặp), so sánh chúng với câu hỏi và đưa ra được câu trả lời. Vì câu trả lời sẽ là một từ, một vật thể, một hành động nào đó nằm trong Context, nên thuật toán ở đây, là so sánh từng từ này để tìm ra từ tương đồng nhất với câu hỏi. Module Episodic Memory cũng đã làm nhiệm vụ đánh trọng số một cách rất tốt nên việc tìm ra sự tương đồng này của chúng ta cũng sẽ chính xác hơn nhiều.
# a0: Final memory state. (Input to answer module)
a0 = tf.concat([memory[-1], q], -1)
# fc_init: Initializer for the final fully connected layer's weights.
fc_init = tf.random_normal_initializer(stddev=0.1)
with tf.variable_scope("answer"):
# w_answer: The final fully connected layer's weights.
w_answer = tf.get_variable("weight", [recurrent_cell_size*2, D],
tf.float32, initializer = fc_init)
# Regulate the fully connected layer's weights
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES,
tf.nn.l2_loss(w_answer))
# The regressed word. This isn't an actual word yet;
# we still have to find the closest match.
logit = tf.expand_dims(tf.matmul(a0, w_answer),1)
# Make a mask over which words exist.
with tf.variable_scope("ending"):
all_ends = tf.reshape(input_sentence_endings, [-1,2])
range_ends = tf.range(tf.shape(all_ends)[0])
ends_indices = tf.stack([all_ends[:,0],range_ends], axis=1)
ind = tf.reduce_max(tf.scatter_nd(ends_indices, all_ends[:,1],
[tf.shape(q)[0], tf.shape(all_ends)[0]]),
axis=-1)
range_ind = tf.range(tf.shape(ind)[0])
mask_ends = tf.cast(tf.scatter_nd(tf.stack([ind, range_ind], axis=1),
tf.ones_like(range_ind), [tf.reduce_max(ind)+1,
tf.shape(ind)[0]]), bool)
# A bit of a trick. With the locations of the ends of the mask (the last periods in
# each of the contexts) as 1 and the rest as 0, we can scan with exclusive or
# (starting from all 1). For each context in the batch, this will result in 1s
# up until the marker (the location of that last period) and 0s afterwards.
mask = tf.scan(tf.logical_xor,mask_ends, tf.ones_like(range_ind, dtype=bool))
# We score each possible word inversely with their Euclidean distance to the regressed word.
# The highest score (lowest distance) will correspond to the selected word.
logits = -tf.reduce_sum(tf.square(context*tf.transpose(tf.expand_dims(
tf.cast(mask, tf.float32),-1),[1,0,2]) - logit), axis=-1)
Huấn luyện mô hình
Hàm loss và optimizer
Hàm loss chúng ta sử dụng sẽ là sigmoid_cross_entropy_with_logits với việc tối ưu khoảng cách vector đầu ra của answer so với đáp án chính xác. Optimizer Adam cũng sẽ được dùng bởi những ưu điểm của nó khi dùng cơ chế Attention so với các hàm optimizer khác.
# gold_standard: The real answers.
gold_standard = tf.placeholder(tf.float32, [None, 1, D], "answer")
with tf.variable_scope('accuracy'):
eq = tf.equal(context, gold_standard)
corrbool = tf.reduce_all(eq,-1)
logloc = tf.reduce_max(logits, -1, keep_dims = True)
# locs: A boolean tensor that indicates where the score
# matches the minimum score. This happens on multiple dimensions,
# so in the off chance there's one or two indexes that match
# we make sure it matches in all indexes.
locs = tf.equal(logits, logloc)
# correctsbool: A boolean tensor that indicates for which
# words in the context the score always matches the minimum score.
correctsbool = tf.reduce_any(tf.logical_and(locs, corrbool), -1)
# corrects: A tensor that is simply correctsbool cast to floats.
corrects = tf.where(correctsbool, tf.ones_like(correctsbool, dtype=tf.float32),
tf.zeros_like(correctsbool,dtype=tf.float32))
# corr: corrects, but for the right answer instead of our selected answer.
corr = tf.where(corrbool, tf.ones_like(corrbool, dtype=tf.float32),
tf.zeros_like(corrbool,dtype=tf.float32))
with tf.variable_scope("loss"):
# Use sigmoid cross entropy as the base loss,
# with our distances as the relative probabilities. There are
# multiple correct labels, for each location of the answer word within the context.
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits = tf.nn.l2_normalize(logits,-1),
labels = corr)
# Add regularization losses, weighted by weight_decay.
total_loss = tf.reduce_mean(loss) + weight_decay * tf.add_n(
tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))
# TensorFlow's default implementation of the Adam optimizer works. We can adjust more than
# just the learning rate, but it's not necessary to find a very good optimum.
optimizer = tf.train.AdamOptimizer(learning_rate)
# Once we have an optimizer, we ask it to minimize the loss
# in order to work towards the proper training.
opt_op = optimizer.minimize(total_loss)
Bắt đầu huấn luyện
Chúng ta sẽ viết một hàm phụ trách việc lấy ngẫu nhiên ra các dữ liệu để tạo ra từng batch training
def prep_batch(batch_data, more_data = False):
"""
Prepare all the preproccessing that needs to be done on a batch-by-batch basis.
"""
context_vec, sentence_ends, questionvs, spt, context_words, cqas, answervs, _ = zip(*batch_data)
ends = list(sentence_ends)
maxend = max(map(len, ends))
aends = np.zeros((len(ends), maxend))
for index, i in enumerate(ends):
for indexj, x in enumerate(i):
aends[index, indexj] = x-1
new_ends = np.zeros(aends.shape+(2,))
for index, x in np.ndenumerate(aends):
new_ends[index+(0,)] = index[0]
new_ends[index+(1,)] = x
contexts = list(context_vec)
max_context_length = max([len(x) for x in contexts])
contextsize = list(np.array(contexts[0]).shape)
contextsize[0] = max_context_length
final_contexts = np.zeros([len(contexts)]+contextsize)
contexts = [np.array(x) for x in contexts]
for i, context in enumerate(contexts):
final_contexts[i,0:len(context),:] = context
max_query_length = max(len(x) for x in questionvs)
querysize = list(np.array(questionvs[0]).shape)
querysize[:1] = [len(questionvs),max_query_length]
queries = np.zeros(querysize)
querylengths = np.array(list(zip(range(len(questionvs)),[len(q)-1 for q in questionvs])))
questions = [np.array(q) for q in questionvs]
for i, question in enumerate(questions):
queries[i,0:len(question),:] = question
data = {context_placeholder: final_contexts, input_sentence_endings: new_ends,
query:queries, input_query_lengths:querylengths, gold_standard: answervs}
return (data, context_words, cqas) if more_data else data
Giờ sẽ là bước quan trọng nhất của chúng ta: Training
# training_iterations_count: The number of data pieces to train on in total
# batch_size: The number of data pieces per batch
def train(iterations, batch_size):
training_iterations = range(0,iterations,batch_size)
training_iterations = tqdm(training_iterations)
wordz = []
for j in training_iterations:
batch = np.random.randint(final_train_data.shape[0], size=batch_size)
batch_data = final_train_data[batch]
sess.run([opt_op], feed_dict=prep_batch(batch_data))
if (j/batch_size) % display_step == 0:
# Calculate batch accuracy
acc, ccs, tmp_loss, log, con, cor, loc = sess.run([corrects, cs, total_loss, logit,
context_placeholder,corr, locs],
feed_dict=validation_set)
# Display results
print("Iter " + str(j/batch_size) + ", Minibatch Loss= ",tmp_loss,
"Accuracy= ", np.mean(acc))
# Initialize variables
init = tf.global_variables_initializer()
# Launch the TensorFlow session
sess = tf.Session()
sess.run(init)
from tqdm import tqdm
# Prepare validation set
batch = np.random.randint(final_test_data.shape[0], size=batch_size*10)
batch_data = final_test_data[batch]
validation_set, val_context_words, val_cqas = prep_batch(batch_data, True)
train(500000,batch_size)
Sẽ mất một thời gian khá dài để ra được kết quả. Các bạn nên cài đặt và sử dụng thêm thư viện tqdm để giúp chúng ta theo dõi tiến trình nhé!
0%| | 1/3125 [00:19<17:07:40, 19.74s/it]
Iter 0.0, Minibatch Loss= 0.6729166 Accuracy= 0.0203125
3%|▎ | 101/3125 [05:08<2:34:09, 3.06s/it]
Iter 100.0, Minibatch Loss= 0.67268276 Accuracy= 0.4078125
6%|▋ | 201/3125 [09:58<2:25:06, 2.98s/it]
Iter 200.0, Minibatch Loss= 0.67266554 Accuracy= 0.4015625
10%|▉ | 301/3125 [14:36<2:17:01, 2.91s/it]
Iter 300.0, Minibatch Loss= 0.67267096 Accuracy= 0.478125
13%|█▎ | 401/3125 [19:16<2:10:56, 2.88s/it]
Iter 400.0, Minibatch Loss= 0.672627 Accuracy= 0.49765626
16%|█▌ | 501/3125 [24:03<2:06:01, 2.88s/it]
Iter 500.0, Minibatch Loss= 0.6726332 Accuracy= 0.5101563
19%|█▉ | 601/3125 [29:06<2:02:14, 2.91s/it]
Iter 600.0, Minibatch Loss= 0.6726215 Accuracy= 0.575
22%|██▏ | 701/3125 [33:44<1:56:39, 2.89s/it]
Iter 700.0, Minibatch Loss= 0.67262524 Accuracy= 0.55
26%|██▌ | 801/3125 [38:27<1:51:35, 2.88s/it]
Iter 800.0, Minibatch Loss= 0.6726075 Accuracy= 0.6015625
29%|██▉ | 901/3125 [42:50<1:45:44, 2.85s/it]
Iter 900.0, Minibatch Loss= 0.6726142 Accuracy= 0.5757812
32%|███▏ | 1001/3125 [47:17<1:40:19, 2.83s/it]
Iter 1000.0, Minibatch Loss= 0.6726233 Accuracy= 0.60625
...
Thử nghiệm và kết quả
Đầu tiên, hãy xem cơ chế Attention hoạt động như thế nào với các thông tin trong 5 context đầu tiên trong tập test (tập này chúng ta chưa hề sử dụng để huấn luyện)
ancr = sess.run([corrbool,locs, total_loss, logits, facts_0s, w_1]+attends+
[query, cs, question_module_outputs],feed_dict=validation_set)
a = ancr[0]
n = ancr[1]
cr = ancr[2]
attenders = np.array(ancr[6:-3])
faq = np.sum(ancr[4], axis=(-1,-2)) # Number of facts in each context
limit = 5
for question in range(min(limit, batch_size)):
plt.yticks(range(passes,0,-1))
plt.ylabel("Episode")
plt.xlabel("Question "+str(question+1))
pltdata = attenders[:,question,:int(faq[question]),0]
# Display only information about facts that actually exist, all others are 0
pltdata = (pltdata - pltdata.mean()) / ((pltdata.max() - pltdata.min() + 0.001)) * 256
plt.pcolor(pltdata, cmap=plt.cm.BuGn, alpha=0.7)
plt.show()
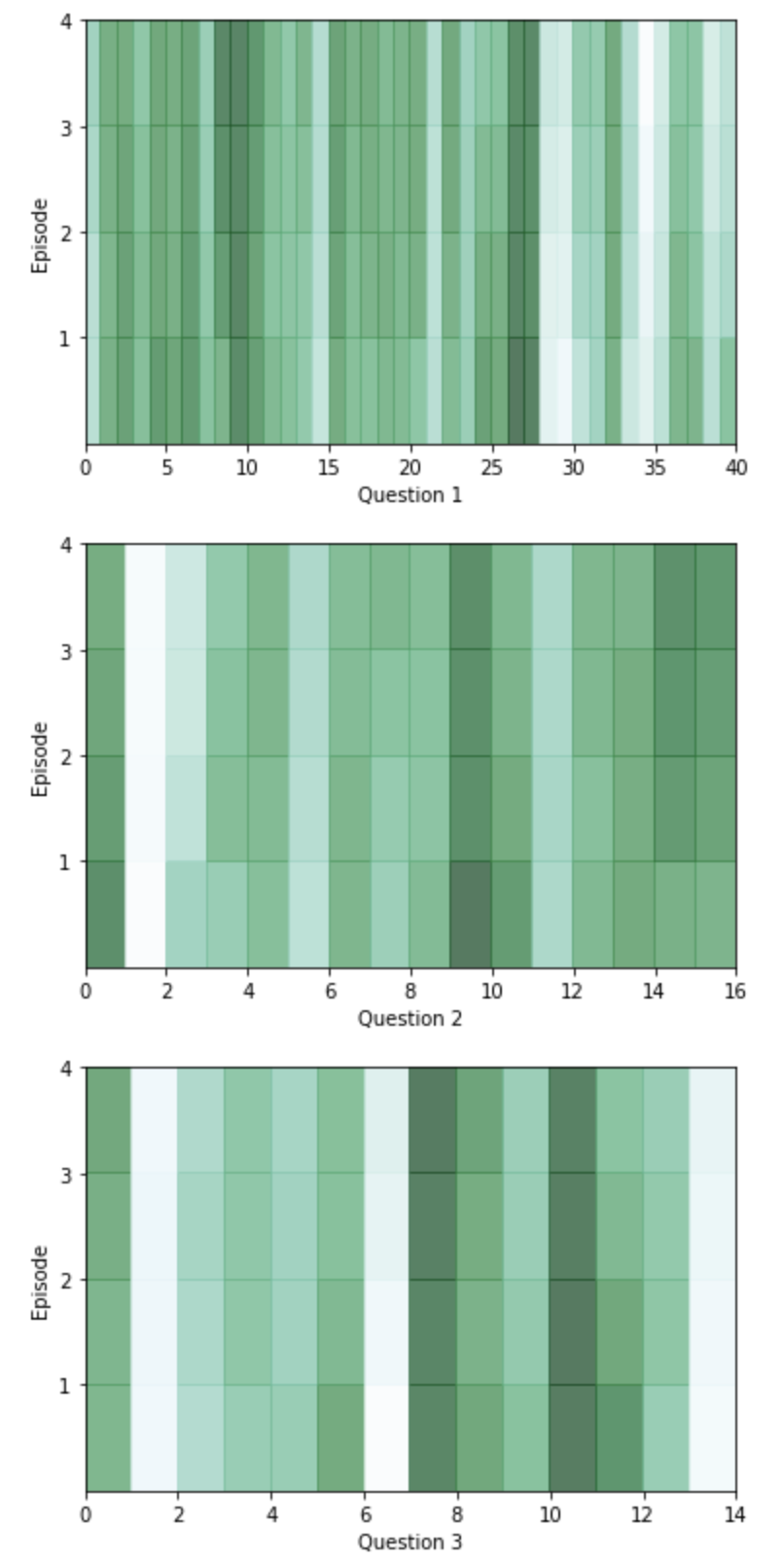
Mỗi episode là một lần lặp của mô hình qua các thông tin trong Context và là một lần thay đổi các trọng số của cơ chế Attention. Trong biểu đồ trên, màu xanh đậm hơn thể hiện sự chú ý và trọng số cao hơn của mô hình dành cho một từ nào đó có ở trong ngữ cảnh.
Giờ hãy xem hiệu quả của mô hình bằng việc xem mô hình trả lời các câu hỏi.
ancr = sess.run([corrbool,locs, total_loss, logits, facts_0s, w_1]+attends+
[query, cs, question_module_outputs],feed_dict=validation_set)
a = ancr[0]
n = ancr[1]
cr = ancr[2]
attenders = np.array(ancr[6:-3])
faq = np.sum(ancr[4], axis=(-1,-2)) # Number of facts in each context
limit = 5
for question in range(min(limit, batch_size)):
plt.yticks(range(passes,0,-1))
plt.ylabel("Episode")
plt.xlabel("Question "+str(question+1))
pltdata = attenders[:,question,:int(faq[question]),0]
# Display only information about facts that actually exist, all others are 0
pltdata = (pltdata - pltdata.mean()) / ((pltdata.max() - pltdata.min() + 0.001)) * 256
plt.pcolor(pltdata, cmap=plt.cm.BuGn, alpha=0.7)
plt.show()
TEXT: fred moved to the garden . mary journeyed to the bedroom . bill moved to the office .
bill moved to the kitchen . bill went back to the hallway . mary moved to the hallway .
fred journeyed to the hallway . jeff journeyed to the hallway . mary travelled to the bedroom .
jeff went back to the garden . fred travelled to the office . jeff went back to the bedroom .
mary went back to the bathroom . mary moved to the garden . jeff travelled to the garden .
jeff moved to the bedroom . mary went back to the kitchen . jeff went to the garden .
bill journeyed to the office . mary went to the office . fred travelled to the bedroom .
jeff moved to the bathroom . bill moved to the hallway . bill went to the office .
jeff went to the kitchen . jeff moved to the bedroom . bill travelled to the bedroom .
mary moved to the garden . bill journeyed to the bathroom . bill picked up the football there .
mary went back to the kitchen . jeff travelled to the bathroom . fred went to the hallway .
bill picked up the apple there . bill passed the apple to jeff . jeff handed the apple to bill .
bill handed the apple to jeff . jeff gave the apple to bill . bill gave the apple to jeff . mary took the milk there .
QUESTION: who received the apple ?
RESPONSE: jeff <Correct>
EXPECTED: jeff
TEXT: mary took the apple there . bill went to the garden . bill went to the bathroom .
jeff moved to the office . bill travelled to the bedroom . jeff travelled to the hallway .
mary gave the apple to fred . mary travelled to the office . mary took the milk there .
mary discarded the milk . mary picked up the milk there . bill went back to the garden .
fred passed the apple to bill . mary went to the kitchen . jeff went to the garden . bill gave the apple to fred .
QUESTION: who did bill give the apple to ?
RESPONSE: fred <Correct>
EXPECTED: fred
TEXT: bill went to the bathroom . bill journeyed to the hallway . fred journeyed to the office .
mary got the football there . mary got the apple there . mary went back to the hallway .
mary handed the apple to bill . bill gave the apple to mary . mary gave the apple to bill .
bill gave the apple to mary . mary passed the apple to bill . bill gave the apple to mary .
fred went to the bedroom . mary dropped the apple .
QUESTION: what did bill give to mary ?
RESPONSE: apple <Correct>
EXPECTED: apple
TEXT: mary grabbed the milk there . mary gave the milk to jeff . mary moved to the garden .
fred travelled to the hallway . fred moved to the bathroom . fred moved to the hallway .
mary journeyed to the bedroom . jeff put down the milk . bill picked up the football there .
bill handed the football to mary . mary passed the football to bill . bill travelled to the office .
QUESTION: who gave the football ?
RESPONSE: bill <Incorrect>
EXPECTED: mary
TEXT: fred journeyed to the bedroom . fred got the milk there . fred went back to the kitchen .
bill picked up the football there . fred handed the milk to mary . mary moved to the garden .
bill dropped the football . mary gave the milk to bill . bill handed the milk to mary .
mary passed the milk to bill . jeff went to the garden . jeff journeyed to the kitchen .
jeff moved to the bedroom . bill picked up the football there .
QUESTION: what did mary give to bill ?
RESPONSE: milk <Correct>
EXPECTED: milk
Kết quả khá hấp dẫn nhỉ ) (Paper Quốc tế mà)
Kết luận
Thực ra đây là một bài viết mang tính giải thích, cài đặt cho một paper mà mình đang tìm hiểu và muốn chia sẻ cho các bạn. Vì vậy nên lượng kiến thức có thể sẽ hơi nhiều và khiên các bạn có thể không hiểu được ngay sau vài lần đọc. Bản thân mình cũng đã mất khoảng 1 tháng để hiểu và implement được. Rất cảm ơn sự quan tâm của các bạn tới các bài viết của mình. Mọi đóng góp, ý kiến hay thắc mắc các bạn hãy để lại ngay dưới phần comment nhé. ^^
All rights reserved
