
Xây dựng hệ thống kiểm soát nhận dạng khuôn mặt với OpenCV Dlib và Deep Learning
Bài đăng này đã không được cập nhật trong 7 năm
Hệ thống kiểm soát nhận dạng khuôn mặt là gì?

Vào thời điểm mình viết bài viết này, chắc hẳn cụm từ NHẬN DẠNG KHUÔN MẶT (FACIAL RECOGNITION) đã không còn là một khái niệm quá xa lạ đối với bất kỳ một ai. Đây là một kỹ thuật nhằm xác định một người từ một hình ảnh hoặc một khung hình trong video lấy được. Công nghệ nhận diện khuôn mặt giờ đã trở nên rất quen thuộc, và được áp dụng phổ biến trong các hệ thống an ninh ở nhiều nơi trên thế giới, trong đó có cả Việt Nam.
Ưu điểm của công nghệ này so với các công nghệ nhận dạng khác (nhận dạng vân tay, nhận dạng giọng nói, nhận dạng mống mắt) chính là việc nó không đòi hỏi sự hợp tác đến từ người dùng.
Mục tiêu
Hiện nay có rất nhiều kỹ thuật để thực hiện việc nhận dạng khuôn mặt, tuy nhiên điểm chung của các kỹ thuật này là đều sẽ phải thực hiện qua 3 bước:
- Xác định và lấy ra (các) khuôn mặt có trong hình ảnh
- Từ hình ảnh các khuôn mặt lấy ra từ bước 1, thực hiện việc phân tích, trích xuất các đặt trưng của khuôn mặt
- Từ các thông tin có được sau khi phân tích, kết luận và xác minh danh tính người dùng
Thông qua bài viết lần này, mình sẽ xây dựng một hệ thống hoàn chỉnh cho việc nhận dạng khuôn mặt dựa vào thư viện Dlib của OpenCV và mạng Deep Learning sử dụng hàm Triplet Loss. Hy vọng sẽ giúp các bạn nắm được công nghệ này để có thể tự triển khai được trong thực tế.
Xây dựng hệ thống nhận dạng khuôn mặt
Một chút đọc lại trong phần ngay trước, mình đã nói về 3 bước thực hiện của một hệ thống nhận dạng khuôn mặt, và giờ chúng ta sẽ thực hiện đầy đủ 3 bước đó nhé.
Xác định khuôn mặt trong ảnh (Facial detection) - Việc khó đã có Dlib lo
 Điều cần làm đầu tiên với bức ảnh/ khung hình chúng ta có đó chính là xác định xem trong bức ảnh/ khung hình đó có sự xuất hiện của bao người khuôn mặt (bao nhiêu người) và vị trí của chúng trong bức ảnh. Bài toán trở nên rất giống với bài toán xác định vật thể (Object Detection). Đây là một trong những bài toán rất khó bởi chúng ta sẽ cần nhiều kinh nghiệm cũng như lý thuyết về xử lý ảnh để có thể giải quyết được bước này. Cụ thể hơn, một số kỹ thuật cho bài toán này có thể kể đến như:
Điều cần làm đầu tiên với bức ảnh/ khung hình chúng ta có đó chính là xác định xem trong bức ảnh/ khung hình đó có sự xuất hiện của bao người khuôn mặt (bao nhiêu người) và vị trí của chúng trong bức ảnh. Bài toán trở nên rất giống với bài toán xác định vật thể (Object Detection). Đây là một trong những bài toán rất khó bởi chúng ta sẽ cần nhiều kinh nghiệm cũng như lý thuyết về xử lý ảnh để có thể giải quyết được bước này. Cụ thể hơn, một số kỹ thuật cho bài toán này có thể kể đến như:
- Kỹ thuật xác định dựa vào các kiến thức con người (Knowledge-based): Kỹ thuật này dựa vào các hiểu biết của con người về khuôn mặt để xác định được một khuôn mặt trong ảnh (Ví dụ như việc một khuôn mặt sẽ phải có mắt, mũi, miệng và khoảng cách giữa chúng thường sẽ phải thoả mãn các ràng buộc nào đó,..). Điểm khó của kỹ thuật này nằm ở việc chúng ta sẽ phải xây dựng nên 1 bộ quy tắc. Nếu bộ quy tắc quá chung chung hay quá chặt chẽ thì đều không được vì nó sẽ dẫn tới việc nhận dạng nhầm hoặc không nhận dạng được.
- Kỹ thuật xác định dựa vào đặc tính khuôn mặt (Feature-based): Kỹ thuật này tạo ra một mô hình, sau đó chúng ta sẽ huấn luyện mô hình đó như một mô hình để phân loại (classifier) nhằm xác định trong các khung hình cắt ra từ 1 ảnh ban đầu, đâu là các vùng của một khuôn mặt. Điểm yếu lớn nhất của kỹ thuật này là về mặt thời gian. Có vấn đề này là do chúng ta sẽ phải lấy ra rất nhiều vùng trong 1 bức ảnh nhằm đưa qua classifier.
- Kỹ thuật xác định dựa vào mẫu cho trước (Template-Matching): Kỹ thuật này xác định được vị trí của một khuôn mặt trong bức ảnh dựa vào việc so sánh giữa các bức ảnh khuôn mặt chúng ta cho trước (Feature template) và các khung hình được cắt ra. Template-Matching rất dễ dàng để sử dụng tuy nhiên cũng gặp phải vấn đề về thời gian tương tự như kỹ thuật Feature-base ở trên.
- Kỹ thuật xác định dựa vào hình dáng (Appearance-Base): Đây là kỹ thuật mà Dlib sẽ sử dụng, phương pháp sử dụng các phương pháp hình thái học kết hợp với phân tích từ mô hình machine-leanring để xác định trực tiếp về vị trí của các vùng có khuôn mặt trong ảnh. Chúng ta sẽ nói kỹ hơn nữa về kỹ thuật này ở phần sau.
Tin vui cho các bạn là chúng ta sẽ không cần phải hiểu tất cả, thậm chí cũng không cần nắm quá rõ về một kỹ thuật nào trong số các kỹ thuật trên mà vẫn có thể thực hiện được dễ dàng bước này.

Đúng như tiêu đề của mình có ghi, mọi việc khó nhất của bước này, chúng ta đều sẽ "nhờ" Dlib giải quyết! Dlib là một chương trình của thư viện OpenCV, hỗ trợ người dùng trong việc xác định khuôn mặt. Thuật toán mà Dlib sử dụng đó là HOG (Histogram of Oriented Gradients) và SVM (Support Vector Machine), đây chính là lý do tại sao Dlib có thời gian chạy rất nhỏ và có thể sử dụng trong các hệ thống thời gian thực. Tuy nhiên gần đây, Dlib cũng đã cung cấp thêm các hàm xác định khuôn mặt dựa trên mạng CNN nên tiếp theo chúng ta sẽ cùng thử cả 2 phương pháp này nhé. Tất cả sẽ có trong đoạn code dưới đây.
import time
import dlib
import cv2
# Đọc ảnh đầu vào
image = cv2.imread('/Users/phamhoanganh/Desktop/2.jpg')
# Khai báo việc sử dụng các hàm của dlib
hog_face_detector = dlib.get_frontal_face_detector()
cnn_face_detector = dlib.cnn_face_detection_model_v1('/Users/phamhoanganh/Desktop/mmod_human_face_detector.dat')
# Thực hiện xác định bằng HOG và SVM
start = time.time()
faces_hog = hog_face_detector(image, 1)
end = time.time()
print("Hog + SVM Execution time: " + str(end-start))
# Vẽ một đường bao màu xanh lá xung quanh các khuôn mặt được xác định ra bởi HOG + SVM
for face in faces_hog:
x = face.left()
y = face.top()
w = face.right() - x
h = face.bottom() - y
cv2.rectangle(image, (x,y), (x+w,y+h), (0,255,0), 2)
# Thực hiện xác định bằng CNN
start = time.time()
faces_cnn = cnn_face_detector(image, 1)
end = time.time()
print("CNN Execution time: " + str(end-start))
# Vẽ một đường bao đỏ xung quanh các khuôn mặt được xác định bởi CNN
for face in faces_cnn:
x = face.rect.left()
y = face.rect.top()
w = face.rect.right() - x
h = face.rect.bottom() - y
cv2.rectangle(image, (x,y), (x+w,y+h), (0,0,255), 2)
cv2.imshow("image", image)
cv2.waitKey(0)
Đi qua một chút về đoạn code trên. Đầu tiên, hãy chắc chắn rằng các bạn đã cài đặt Dlib và thực hiện import.
pip install dlib
Chi tiết hơn về cách cài đặt, các bạn hãy làm theo bài viết này
Tiếp theo, mình đọc vào một ảnh bất kỳ, sau đó gán và khai báo các hàm xác định khuôn mặt của Dlib.
- dlib.get_frontal_face_detector: hàm sử dụng HOG + SVM để xác định khuôn mặt
- dlib.cnn_face_detection_model_v1: hàm sử dụng CNN để xác định khuôn mặt, tuy nhiên để sử dụng được hàm này ngay mà không cần huấn luyện lại, chúng ta cần phải load weights của mạng CNN đã được train trước. Các bạn có thể tải xuống weights ở đây và thực hiện khai báo như mình ở trên nhé.
Đây là bức ảnh mà mình sẽ sử dụng để thử

Tiếp đến, chúng ta thực hiện việc gọi hàm xác định khuôn mặt. Ở đây, để so sánh 2 phương pháp, trước và sau mỗi khi thực hiện hàm xác định của mỗi phương pháp, mình đầu ghi lại thời gian để tiện cho việc so sánh sau này.
faces_hog = hog_face_detector(image, 1)
faces_cnn = cnn_face_detector(image, 1)
Tham số cần truyền vào cả 2 hàm đều là ảnh đầu vào và số lượng của cửa sổ tìm kiếm. Nếu số này càng lớn, đồng nghĩa với việc sẽ có thêm các cửa sổ tìm kiếm (kích thước cửa sổ mới sẽ nhỏ dần). Điều này giúp ta nhận ra được các khuôn mặt ở xa (bị nhỏ) ở trong ảnh tuy nhiên đánh đổi bằng việc thời gian chạy sẽ tăng theo cấp số mũ. Ở đây mình chỉ để 1 cửa sổ.
Cả 2 hàm đều trả về cho chúng ta 1 list các toạ độ của các khuôn mặt có trong ảnh, và từ đó mình sẽ thực hiện vẽ lên ảnh các đường bao chữ nhật.
LƯU Ý: Để phân biệt thì đối với các khuôn mặt được xác định nhờ HOG+SVM, mình sẽ vẽ đường bao màu xanh, còn các vùng được xác định nhờ CNN, mình sẽ vẽ đường bao màu đỏ! Hãy cùng xem kết quả.
 Dễ thấy rằng CNN cho ta kết quả gần như tuyệt đối, còn đối với phương pháp HOG kết hợp SVM, chúng ta hãy để ý những trường hợp phương pháp này không xác định được... Chắc các bạn cũng đều nhận ra, HOG+SVM bị bỏ qua các khuôn mặt quay nghiêng góc hoặc bị che một phần. Điều này đúng với tên hàm mà Dlib cung cấp cho chúng ta get_frontal_face_detector!!
Dễ thấy rằng CNN cho ta kết quả gần như tuyệt đối, còn đối với phương pháp HOG kết hợp SVM, chúng ta hãy để ý những trường hợp phương pháp này không xác định được... Chắc các bạn cũng đều nhận ra, HOG+SVM bị bỏ qua các khuôn mặt quay nghiêng góc hoặc bị che một phần. Điều này đúng với tên hàm mà Dlib cung cấp cho chúng ta get_frontal_face_detector!!
Tuy nhiên trước khi buông lời phán xét, hãy xem thêm thông số về thời gian mà mình cho in ra
Hog + SVM Execution time: 0.1367199420928955
CNN Execution time: 4.2889978885650635
Với một bức ảnh khoảng 800x600 pixel như thế này, phương pháp sử dụng HOG kết hợp SVM mất khoảng 0.13 giây để xác định được toàn bộ khuôn mặt, còn phương pháp CNN lại phải mất tới 4.29 giây (gấp khoảng 40 lần). Sự chênh lệch này sẽ lớn hơn rất nhiều nếu chúng ta thử trên một bức ảnh chất lượng cao hơn. Tuy nhiên do hiện nay mình đang sử dụng MBP2017 là 1 loại máy không hỗ trợ về tính toán, GPU quá mạnh nên phương pháp CNN tỏ ra kém hiệu quả. Vậy nên với "cơ sở vật chất" của mình thì mình sẽ chọn sẽ dụng phương pháp HOG + SVM để đảm bảo được hệ thống của mình sẽ hoạt động được với thời gian thực nhé!!
Đến đây, chúng ta đã xử lý xong bước đầu tiên theo một cách ... rất dễ dàng và tiện lợi nhờ sự hỗ trợ của DLIB. Hệ thống của chúng ta đã có thể xác định được các vị trị khuôn mặt ở trong ảnh! Ngoài ra, Dlib còn hỗ trợ chúng ta lấy ra các điểm quan trọng trên khuôn mặt (Landmark), tuy nhiên mình sẽ không đề cập tới trong bài viết này vì hệ thống chúng ta đang xây dựng hoàn toàn không sử dụng chúng.
Biểu diễn các khuôn mặt dưới dạng vector
Nói đến việc nhận dạng, xác định khuôn mặt này là "của ai", chúng ta sẽ cần tính độ GIỐNG/ KHÁC nhau giữa các khuôn mặt chúng ta lấy được. Và nói về độ GIỐNG/ KHÁC nhau, để đơn giản, chúng ta sẽ quy về bài toán Tính khoảng cách giữa các vector. Dù là trong xử lý âm thanh hay xử lý ảnh hay xử lý ngôn ngữ tự nhiên, việc chuyển về vector để tính khoảng cách đều là một lựa chọn rất tốt. Và trong bài viết này, mình sẽ biến các khung hình khuôn mặt về các vector có 128 chiều (số chiều này là do sau nhiều lần mình thử và chọn ra, các bạn có thể thử và lựa chọn số khác).
Về lý thuyết thì là như vậy, nhưng vấn đề quan trọng nhất ở đấy chính là
CẦN MỘT MÔ HÌNH CHUYỂN TỪ KHUNG HÌNH KHUÔN MẶT SANG VECTOR, SAO CHO ẢNH 2 KHUÔN MẶT GẦN NHAU THÌ 2 VECTOR TƯƠNG ỨNG CŨNG PHẢI CÓ KHOẢNG CÁCH GẦN NHAU. ẢNH 2 KHUÔN MẶT KHÁC NHAU THÌ 2 VECTOR TƯƠNG ỨNG CŨNG PHẢI XA NHAU HƠN.
Và để giải quyết vấn đề này, mình sẽ giới thiệu cho các bạn mô hình học sâu ConvNet sử dụng hàm loss Triplet.
Triplet là gì?
Tiếng việt của Triplet có thể tạm được dịch ra là "bộ ba". Với rất nhiều các bài toán khác trước đây của các mô hình học sâu, thông thường chúng ta sẽ cho lần lượt từng ảnh một vào để mô hình học, tuy nhiên với bài toán lần này, chúng ta sẽ phải sử dụng từng "bộ ba".
Bộ ba của chúng ta bao gồm: 1 ảnh mặt của 1 người bất kỳ (query), 1 ảnh mặt khác của người đó (positive), 1 ảnh mặt của người khác (negative). Với việc huấn luyện mô hình như thế, chúng ta sẽ có thêm thông tin về mối quan hệ giữa các ảnh, điều này giúp mô hình chúng ta phù hợp hơn nhiều với bài toán.
ConvNet
 Đây là một mạng học sâu với cấu trúc 3 nhánh. Với 1 ảnh đưa vào, chúng ta sẽ thu được 1 vector cuối cùng đầu ra (Trong ảnh là 4096 chiều, còn mình sẽ đưa về 128 chiều). Điểm khác ở đây là ảnh sẽ được phân tích theo 3 mô hình khác nhau, mô hình đã được chứng minh hiệu quả trong nhiều bài toán/ cuộc thi xử lý ảnh khác. Vậy nên chúng ta sẽ sử dụng ConvNet trên trong bài toán lần này.
Đây là một mạng học sâu với cấu trúc 3 nhánh. Với 1 ảnh đưa vào, chúng ta sẽ thu được 1 vector cuối cùng đầu ra (Trong ảnh là 4096 chiều, còn mình sẽ đưa về 128 chiều). Điểm khác ở đây là ảnh sẽ được phân tích theo 3 mô hình khác nhau, mô hình đã được chứng minh hiệu quả trong nhiều bài toán/ cuộc thi xử lý ảnh khác. Vậy nên chúng ta sẽ sử dụng ConvNet trên trong bài toán lần này.
Triplet loss
Một lần nữa
CẦN MỘT MÔ HÌNH CHUYỂN TỪ KHUNG HÌNH KHUÔN MẶT SANG VECTOR, SAO CHO ẢNH 2 KHUÔN MẶT GẦN NHAU THÌ 2 VECTOR TƯƠNG ỨNG CŨNG PHẢI CÓ KHOẢNG CÁCH GẦN NHAU. ẢNH 2 KHUÔN MẶT KHÁC NHAU THÌ 2 VECTOR TƯƠNG ỨNG CŨNG PHẢI XA NHAU HƠN.
Vậy làm sao mô hình của chúng ta hiểu được điều này khi huấn luyện để có thể giúp chúng ta tạo ra các vector như ý? Đây chính là lúc việc sử dụng "bộ ba" trở nên hiệu quả. Và hàm loss của mô hình chúng ta sẽ có dạng như sau
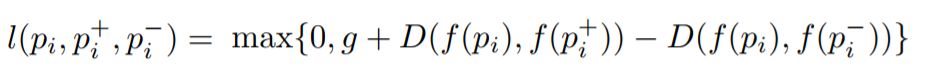
Với là vector biểu diễn . là khoảng cách giữa 2 vector. Hàm loss của chúng ta sẽ là [. Nhìn qua một chút, chúng ta đang huấn luỵên để cho hàm trên CÀNG LỚN CÀNG TỐT (max). Điều này có nghĩa là mô hình chúng ta sẽ cố gắng học sao cho càng ngày, nó càng giảm khoảng cách giữa 2 vector (Query Image) và (Positive Image), và tăng khoảng cách giữa Query Image và Negative Image! Đây là điều chúng ta đang muốn mô hình học được
Chuẩn bị dữ liệu huấn luyện mô hình
Đối với tuỳ từng tổ chức, mục đích sử dụng, chúng ta nên có 1 tập dữ liệu đặc thù, nhưng ở đây mình đang mô phỏng lại một hệ thống, vậy nên mình sẽ sử dụng 1 bộ data lớn một chút để thử nghiệm. Và ở đây mình chọn thử nghiệm hệ thống trên tập Labeled Face in Wild (LFW). Dataset này bao gồm hơn 13000 ảnh mặt người (được gán nhãn) thu thập trên mạng internet. Các bạn có thể tìm thấy bộ dữ liệu này ở đây
LFW Dataset: http://vis-www.cs.umass.edu/lfw/
Huấn luyện mô hình
def convnet_model_():
vgg_model = applications.VGG16(weights=None, include_top=False, input_shape=(221, 221, 3))
x = vgg_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.6)(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.6)(x)
x = Lambda(lambda x_: K.l2_normalize(x,axis=1))(x)
# x = Lambda(K.l2_normalize)(x)
convnet_model = Model(inputs=vgg_model.input, outputs=x)
return convnet_model
def deep_rank_model():
convnet_model = convnet_model_()
first_input = Input(shape=(221, 221, 3))
first_conv = Conv2D(96, kernel_size=(8,8), strides=(16,16), padding='same')(first_input)
first_max = MaxPool2D(pool_size=(3,3), strides=(2,2), padding='same')(first_conv)
first_max = Flatten()(first_max)
first_max = Lambda(lambda x: K.l2_normalize(x, axis=1))(first_max)
second_input = Input(shape=(221, 221, 3))
second_conv = Conv2D(96, kernel_size=(8,8), strides=(32,32), padding='same')(second_input)
second_max = MaxPool2D(pool_size=(7,7), strides=(4,4), padding='same')(second_conv)
second_max = Flatten()(second_max)
second_max = Lambda(lambda x: K.l2_normalize(x, axis=1))(second_max)
merge_one = concatenate([first_max, second_max])
merge_two = concatenate([merge_one, convnet_model.output])
emb = Dense(4096)(merge_two)
emb = Dense(128)(emb)
l2_norm_final = Lambda(lambda x: K.l2_normalize(x, axis=1))(emb)
final_model = Model(inputs=[first_input, second_input, convnet_model.input], outputs=l2_norm_final)
return final_model
deep_rank_model = deep_rank_model()
Mình xây dựng theo đúng mô hình ConvNet đã nói ở trên, 1 ảnh sẽ được đưa vào 3 đường khác nhau, trước khi nối lại để tạo thành 1 vector 128 chiều. Vector này sẽ đại diện cho bức ảnh, và khi mô hình được huấn luyện tốt, 128 thuộc tính này có thể coi như là 128 thuộc tính đặc trưng của khuôn mặt đó. Cũng vì đó, bước huấn luyện mô hình từ khuôn mặt sang vector còn gọi là bước TRÍCH CHỌN ĐẶC TRƯNG.
Giờ chúng ta sẽ code hàm triplet loss đúng theo công thức
batch_size = 24
_EPSILON = K.epsilon()
def _loss_tensor(y_true, y_pred):
y_pred = K.clip(y_pred, _EPSILON, 1.0 - _EPSILON)
loss = 0.
g = 1.
for i in range(0, batch_size, 3):
try:
q_embedding = y_pred[i]
p_embedding = y_pred[i+1]
n_embedding = y_pred[i+2]
D_q_p = K.sqrt(K.sum((q_embedding - p_embedding)**2))
D_q_n = K.sqrt(K.sum((q_embedding - n_embedding)**2))
loss = loss + g + D_q_p - D_q_n
except:
continue
loss = loss/batch_size*3
return K.maximum(loss, 0)
deep_rank_model.compile(loss=_loss_tensor, optimizer=SGD(lr=0.001, momentum=0.9, nesterov=True))
Một điểm khác mà mình đã nói từ đầu trong việc huấn luyện mô hình này đó là việc chúng ta sẽ đưa ảnh theo BỘ BA. Và từ đó hàm loss cũng sẽ tính theo các BỘ BA, không phải tính riêng từng đầu ra như các mô hình khác.
Đây là cách mình chọn BỘ BA, ảnh đầu sẽ được coi là ảnh query, ảnh tiếp theo sẽ là positive (ảnh cùng class) và cuối cùng là ảnh negative (ảnh khác class)
def image_batch_generator(images, labels, batch_size):
labels = np.array(labels)
while True:
batch_paths = np.random.choice(a = len(images), size = batch_size//3)
input_1 = []
for i in batch_paths:
pos = np.where(labels == labels[i])[0]
neg = np.where(labels != labels[i])[0]
j = np.random.choice(pos)
while j == i:
j = np.random.choice(pos)
k = np.random.choice(neg)
while k == i:
k = np.random.choice(neg)
input_1.append(images[i])
input_1.append(images[j])
input_1.append(images[k])
input_1 = np.array(input_1)
input = [input_1, input_1, input_1]
yield(input, np.zeros((batch_size, )))
deep_rank_model.fit_generator(generator=image_batch_generator(X, y, batch_size),
steps_per_epoch=len(X)//batch_size,
epochs=2000,
verbose=1,
callbacks=callbacks_list)
Mô phỏng kết quả (Data Visualize)
Sau khi đã training xong, chúng ta muốn theo dõi kết quả 1 cách trực quan hơn. Liệu mô hình chúng ta có làm tốt được nhiệm vụ trích chọn đặc trưng, và khiến cho những khuôn mặt giống nhau thì về gần nhau, còn ngược lại thì xa nhau không? Để có thể NHÌN RÕ ĐIỀU NÀY 1 CÁCH TRỰC QUAN, chúng ta sẽ cần sử dụng thuật toán t-SNE. Thuật toán sẽ giúp chúng ta đưa từ không gian vector 128 chiều về không gian 3 chiều, giúp mắt ta quan sát dễ dàng nhất. Cụ thể về thuật toán và cách mô phỏng mình sẽ không đề cập ở đây, các bạn muốn tìm hiểu thêm, có thể đọc bài viết rất "có tâm" này của tác giả Phan Hoàng nhé:
Đây là kết quả Visualize của mình:
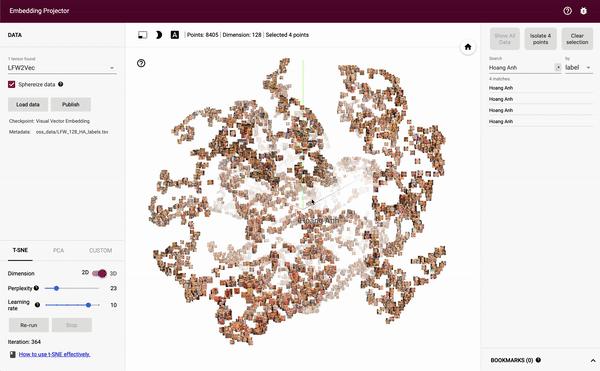
Hoặc các bạn có thể xem trực tiếp tại: https://hoanganhpham1006.github.io/face-detector-Visualize/
Các bạn hãy chọn t-SNE rồi đợi cho nó training khoảng 300-400 iter rồi dừng nhé. Việc training ở đây là training để đưa từ không gian 128 chiều về không gian 3 chiều, hoàn toàn không liên quan tới việc huấn luyện mình viết trong bài này
Do mình training cũng chưa đủ lâu, nên các ảnh cũng chưa thực sự phân cụm 1 cách rõ ràng, tuy nhiên những ảnh cùng 1 người hoặc 2 người giống nhau đều nằm khá gần nhau trong không gian này!
Vậy là chúng ta đã có một mô hình để chuyển từ ảnh khuôn mặt sang vector đúng theo ý đồ của chúng ta. Giờ chúng ta sẽ sang bước cuối cùng nhé!
Xác minh danh tính khuôn mặt
Cách đơn giản và không kém hiệu quả chính là tính khoảng cách Euclit của vector đặc trưng khuôn mặt đang cần nhận dạng với các vector đặc trưng khác, và lấy vector GẦN NÓ NHẤT làm kết quả xác minh
# Với mỗi khung hình mặt phát hiện ra
...
frame = image[y:y+h, x:x+w]
frame = cv2.resize(frame, (221, 221))
frame = frame /255.
frame = np.expand_dims(frame, axis=0)
emb128 = deep_rank_model.predict([frame, frame, frame])
minimum = 99999
person = -1
for k, e in enumerate(embs128):
#Euler distance
dist = np.linalg.norm(emb128-e)
if dist < minimum:
minimum = dist
person = k
cv2.putText(image, names[person], (x - 10, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)

Ngoài ra để có thể tăng tính chính xác hơn nữa, các bạn hãy thêm 1 "ngưỡng khoảng cách tối đa". Nếu vector chúng ta cần xác định nằm quá xa so với các vector còn lại, thì khả năng cao chúng không phải của người nào trong số dữ liệu chúng ta đang có
Kết luận
Như vậy mình đã xây dựng xong hệ thống nhận dạng khuôn mặt của mình. Hy vọng các bạn sẽ có thể thực hiện theo và thành công! Mọi thắc mắc hãy để lại dưới comment nhé, mình rất sẵn lòng để giải đáp!
Link source code: https://github.com/hoanganhpham1006/face-detector
Cảm ơn các bạn đã quan tâm theo dõi
All rights reserved
