
Giải thuật di truyền và ứng dụng trong YOLOv5
Bài đăng này đã không được cập nhật trong 3 năm

Con người vẫn đang cố gắng mô phỏng các cơ chế trong tự nhiên để giải những bài toán chưa tìm ra giải pháp. Ví dụ mạng nơ-ron trong học máy được lấy ý tưởng mạng nơ-ron trong sinh học, cơ chế tập trung(attention) của não,... Trong bài này, mình sẽ giới thiệu cho các bạn về giải thuật di truyền, một phương pháp khác lấy ý tưởng từ sinh học. Một số ví dụ về áp dụng giải thuật di truyền trong AI cũng được giới thiệu sơ lược với mục đích để khuyến khích các bạn tìm hiểu thêm.
Chọn lọc tự nhiên (Natural selection)
Trước khi đi vào giải thuật di truyền, chúng ta hãy xem qua một chút về quá trình chọn lọc tự nhiên để hiểu về tư tưởng chung của giải thuật.
 Hình trên minh họa quá trình chọn lọc tự nhiên đối với loài hươu cao cổ. Không phải tất cả các loài hươu cao cổ đều có chiều dài cổ như nhau, chiều dài cổ của chúng chủ yếu phụ thuộc vào gen. Thức ăn ở chỗ thấp dễ dàng bị các sinh vật khác ăn và cũng dễ dàng bị hết. Nếu thức ăn ở chỗ thấp hết, những con hươu cao cổ có cổ dài hơn sẽ có khả năng sống sót cao hơn do chúng có thể với tới thức ăn. Qua thời gian thì có nhiều hơn những con hươu cao cổ có cổ dài do những con cổ không đủ dài không thể sống sót để sinh sản. Đó là quá trình chọn lọc tự nhiên và thích ứng tiến hóa.
Hình trên minh họa quá trình chọn lọc tự nhiên đối với loài hươu cao cổ. Không phải tất cả các loài hươu cao cổ đều có chiều dài cổ như nhau, chiều dài cổ của chúng chủ yếu phụ thuộc vào gen. Thức ăn ở chỗ thấp dễ dàng bị các sinh vật khác ăn và cũng dễ dàng bị hết. Nếu thức ăn ở chỗ thấp hết, những con hươu cao cổ có cổ dài hơn sẽ có khả năng sống sót cao hơn do chúng có thể với tới thức ăn. Qua thời gian thì có nhiều hơn những con hươu cao cổ có cổ dài do những con cổ không đủ dài không thể sống sót để sinh sản. Đó là quá trình chọn lọc tự nhiên và thích ứng tiến hóa.
Giải thuật di truyền (Genetic algorithm)
Giải thuật di truyền là một phương pháp tìm kiếm dựa trên kinh nghiệm được lấy cảm hứng từ thuyết tiến hóa tự nhiên của Charles Darwin. Giải thuật này phản ánh quá trình chọn lọc trong tự nhiên, nơi mà những cá thể phù hợp nhất được chọn để sinh sản để tạo ra thế hệ con cháu tiếp theo.
 Hình trên mô tả giải thuật di truyền. Giải thuật di truyền gồm 5 giai đoạn (phrase) chính: khởi tạo quần thể ban đầu (initial population), tính điểm phù hợp (fitness score), chọn lọc (selection), trao đổi chéo (cross-over), đột biến (mutation). Giải thuật kết thúc khi tìm thấy solution đủ tốt hoặc đến một thế hệ (sẽ giải thích khái niệm này ở phần sau) cho trước. Chúng ta sẽ đi cụ thể vào từng giai đoạn.
Hình trên mô tả giải thuật di truyền. Giải thuật di truyền gồm 5 giai đoạn (phrase) chính: khởi tạo quần thể ban đầu (initial population), tính điểm phù hợp (fitness score), chọn lọc (selection), trao đổi chéo (cross-over), đột biến (mutation). Giải thuật kết thúc khi tìm thấy solution đủ tốt hoặc đến một thế hệ (sẽ giải thích khái niệm này ở phần sau) cho trước. Chúng ta sẽ đi cụ thể vào từng giai đoạn.
Khởi tạo quần thể ban đầu
 Trước tiên chúng ta hãy làm quen với 3 khái niệm trong hình trên là: gen (gene), nhiễm sắc thể (chromosome), quần thể (population).
Nhiễm sắc thể đóng vai trò như cá thể hươu trong ví dụ ở phần trước. Nhiễm sắc thể là một solution cho bài toán, mỗi nhiễm sắc thể được biểu diễn bởi các gen. Ở trên hình trên có thể coi giá trị '1' là thể hiện có, '0' là không có một đặc trưng tương ứng với vị trí của ô gen. Ví dụ ô gen ngoài cùng bên trái là đặc trưng chân dài, ô ngoài cùng bên phải là đặc trưng cổ dài. Quần thể là tập hợp các nhiễm sắc thể cùng thế hệ. Quần thể ban đầu khởi tạo là thế hệ 0, thế hệ này sau khi trải qua chọn lọc, trao đổi, đột biến sẽ tạo ra thế hệ 1, thế hệ 1 tạo ra thế hệ 2 và tiếp diễn như vậy.
Quần thể ban đầu có thể là ngẫu nhiên hoặc được tạo ra từ một phương pháp khác.
Trước tiên chúng ta hãy làm quen với 3 khái niệm trong hình trên là: gen (gene), nhiễm sắc thể (chromosome), quần thể (population).
Nhiễm sắc thể đóng vai trò như cá thể hươu trong ví dụ ở phần trước. Nhiễm sắc thể là một solution cho bài toán, mỗi nhiễm sắc thể được biểu diễn bởi các gen. Ở trên hình trên có thể coi giá trị '1' là thể hiện có, '0' là không có một đặc trưng tương ứng với vị trí của ô gen. Ví dụ ô gen ngoài cùng bên trái là đặc trưng chân dài, ô ngoài cùng bên phải là đặc trưng cổ dài. Quần thể là tập hợp các nhiễm sắc thể cùng thế hệ. Quần thể ban đầu khởi tạo là thế hệ 0, thế hệ này sau khi trải qua chọn lọc, trao đổi, đột biến sẽ tạo ra thế hệ 1, thế hệ 1 tạo ra thế hệ 2 và tiếp diễn như vậy.
Quần thể ban đầu có thể là ngẫu nhiên hoặc được tạo ra từ một phương pháp khác.
Trong các phần sau cá thể, solution và nhiễm sắc thể đều cùng chỉ một thứ.
Tính điểm phù hợp
Điểm phù hợp là căn cứ để chúng ta có thể chọn được các solution tốt để tạo ra thế hệ solution tiếp theo tốt hơn, những solution có điểm phù hợp cao hơn sẽ có xác suất được chọn lọc cao hơn. Như vậy chúng ta sẽ cần có cách để đánh giá độ phù hợp (độ tốt) của solution. Thông thường những bài toán có thể giải quyết được bằng giải thuật di truyền thường có thể tính được độ phù hợp một cách dễ dàng.
Chọn lọc
Quá trình chọn lọc trong giải thuật mô phỏng quá trình chọn lọc tự nhiên, những cá thể có điểm phù hợp cao nhất có xu hướng được lựa chọn để tạo ra thế hệ tiếp theo, nhưng không nhất thiết phải chọn những cá thế phù hợp nhất.
Các cặp cá thể sẽ được lựa chọn làm bố và mẹ để tạo ra con cho thế hệ tiếp theo dựa trên điểm phù hợp của chúng.
Trao đổi chéo
Trao đổi chéo là quá trình tạo ra nhiều thay đổi nhất trong giải thuật di truyền. Với mỗi cặp cha mẹ, một cặp con ở thế hệ mới được tạo ra bằng cách đổi chỗ một đoạn nhiễm sắc thể giữa bố và mẹ.
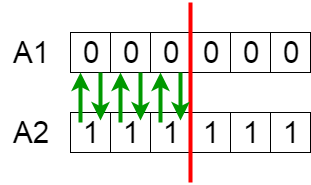
Hai cá thể cha và mẹ (A1 và A2) trao đổi một đoạn nhiễm sắc thể.
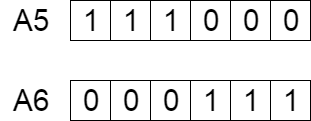
Hai con A5 và A6 được tạo ra từ A1 và A2.
Đột biến
Nếu chỉ có chọn lọc và trao đổi chéo một vài tính trạng của cá thể (solution) có thể sẽ không bao giờ được "activate". Sự đột biến tạo ra sự đa dạng các solution, bằng cách thay đổi một số ít gen với xác suất nhỏ.
 Hình trên minh họa sự đột biến gen của nhiễm sắc thể, chuyển trạng thái từ 1 thành 0.
Hình trên minh họa sự đột biến gen của nhiễm sắc thể, chuyển trạng thái từ 1 thành 0.
Giải thuật di truyền trong YOLOv5
Tiến hóa siêu tham số (Hyperparameter Evolution)
Theo tác giả: Các phương pháp truyền thống như grid search có thể khó sử dụng vì ba nguyên nhân. Thứ nhất, không gian tìm kiếm lớn. Thứ hai, không biết được sự tương quan giữa các chiều. Thứ ba, chi phí xác định điểm phù hợp tại mỗi điểm cao. Điều này làm cho giải thuật di truyền trở thành ứng cử viên phù hợp cho việc tìm kiếm hyperparameter.
Quần thể ban đầu
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
Quần thể ban đầu chỉ có 1 cá thể. Nếu ngay từ đầu cá thể được chọn đã tốt (điểm phù hợp cao) thì sẽ có khả năng tìm ra các cá thể tốt tốt hơn. Do đó các gen của cá thể này được tác giả lựa chọn thay vì sinh ngẫu nhiên.
Điểm phù hợp
Mục tiêu cần tối ưu là điểm phù hợp. Trong YOLOv5, hàm tính điểm phù hợp là tổng của: 10% của mAP@0.5 và 90% của mAP.
def fitness(x):
# Model fitness as a weighted combination of metrics
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
return (x[:, :4] * w).sum(1)
Tiến hóa
Trong YOLOv5 tác giả sử dụng phép đột biến với xác suất 90% và phương sai 0.04 để tạo cá thể mới từ những cha mẹ tốt nhất từ tất cả các thế hệ trước. Tác giả đề xuất sử tiến hóa tối thiểu 300 thế hệ để cho kết quả tốt nhất.
Chi tiết hơn các bạn có thể tham khảo tại https://github.com/ultralytics/yolov5/issues/607
Tiến hóa anchors
Một siêu tham số khác mà phương pháp trên không để tâm đến là các anchor trong YOLO. Quần thể ban đầu được tạo ra thuật toán bởi k-means. Hàm để tính điểm phù hợp là Best Possible Recall. Phép độ biến được sử dụng để tạo ra các cá thể mới tương tự như phần tiến hóa siêu tham số. Chi tiết phần này các bạn có thể tìm hiểu thêm tại: https://github.com/ultralytics/yolov5/blob/master/utils/autoanchor.py#L66
Lời kết
Trong bài này, mình đã giới thiệu về giải thuật di truyền và ví dụ về việc sử dụng giải thuật di truyền trong AI. Hy vọng các bạn cảm thấy bài viết này có ích. Các bạn có ý kiến hay thắc mắc hãy cho mình biết nhé. Cảm ơn các bạn đã theo dõi.
Tham khảo
https://github.com/ultralytics/yolov5/issues/607 https://towardsdatascience.com/introduction-to-genetic-algorithms-including-example-code-e396e98d8bf3
All rights reserved
