
Những sự thật thú vị về PT4AL: một SOTA Active Learning
Bài đăng này đã không được cập nhật trong 3 năm
Lời mở đầu
Nhân dịp đầu xuân năm mới, chúc mọi người sức khỏe dồi dào và có những bước tiến lớn trong sự nghiệp.
Khoảng thời gian này cũng là dịp mình thường nhìn lại năm cũ và lên kế hoạch cho năm mới. Để hưởng ứng hoạt động khai bút đầu xuân, mình đã chọn viết về một trải nghiệm nhỏ cuối năm 2022. Hy vọng trong năm mới dựa trên những trải nghiệm này, chúng ta có thể rút kinh nghiệm để đạt được những kết quả R&D thật sự chất lượng trong năm nay.
Trong bài viết này, mình mượn câu chuyện về PT4AL nói riêng để làm ví dụ cho một thực trạng chung của nhiều bài nghiên cứu. Những hiện tượng mà mình nói đến không hề mới và có thể bắt gặp ở cả công bố từ những tác giả và những hội thảo uy tín. Và có lẽ nhiều người trong chúng ta cũng đã tự đặt vài câu hỏi liên quan đến vấn đề này: "với các bài báo mới từ những nguồn uy tín, liệu chúng ta có thể tin hoàn toàn vào những nghiên cứu này không?". Để bàn luận về vấn đề này, mình xin đi vào chi tiết của bài viết.
Về PT4AL
Trong phần này, mình xin giới thiệu ngắn gọn về nhân vật chính của chúng ta: PT4AL. Riêng phần Chi tiết giải thuật, các bạn có thể bỏ qua nếu muốn mà không ảnh hưởng nhiều đến việc hiểu các phần sau.
Giới thiệu
PT4AL là viết tắt của Pretext task for Active Learning. Để hiểu về bối cảnh của PT4AL, sau đây là một vài keyword ngắn gọn về PT4AL:
- ECCV 2022 accepted: ECCV là một hội thảo uy tín về Computer Vision, rank: A/A*
- Active Learning: paper đề xuất 1 phương pháp để giải quyết bài toán Active Learning, đặc biệt là vấn đề Cold-start trong Active Learning.
- SOTA: tự nhận rằng nắm giữ SOTA trên CIFAR10, ...
- 13 issue/42 star/2 fork: các thông tin repo Github tại thời điểm viết bài.
Ý tưởng của bài báo
PT4AL xuất phát từ một giả thuyết cuả tác giả:
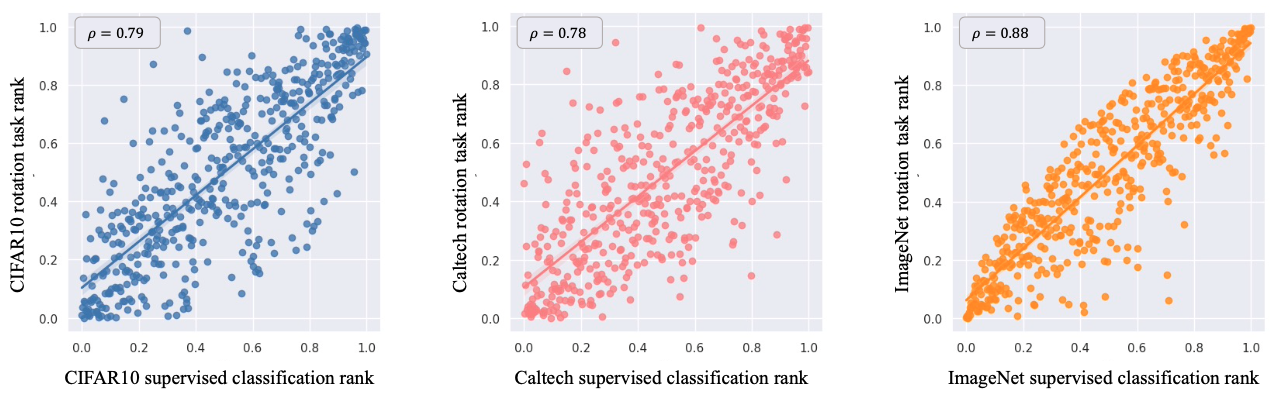
Nhìn vào kết quả của các thí nghiệm trên, chúng ta có thể thấy rằng giá trị mất mát của pretext task và main task thực sự có sự tương quan lớn. Vậy là giả thuyết của tác giả phần nào đã đúng. Việc tiếp theo là tận dụng giả thuyết này để quyết các vấn đề trong Active Learning.
Chi tiết giải thuật
Dựa vào vào giả thuyết được đã kiểm chứng qua thí nghiệm bên trên. Tác giả đã đề xuất PT4AL. Chi tiết các bước của giải thuât PT4AL như sau:
Bước 1: chúng ta huấn luyện một mô hình pretext task trên tập dữ liệu của main task. (Pretext task này là gì thì tuỳ thuộc vào main task. Theo tác giả đề xuất, với main task là Image Classification thì sử dụng pretext task là Rotation Prediction, còn với main task là Image Segmentation thì sử dụng pretext task là Image Colorization. Đề xuất này dựa trên kết quả thực nghiệm. Tác giả suy đoán rằng pretext task và main task nên cùng là pixel-level hoặc image-level)
Bước 2: sau khi có mô hình pretext task thì chúng ta tính loss của các dữ liệu trong tập train.
Bước 3: sắp xếp các dữ liệu trong tập train theo thứ tự giảm dần của loss pretext task và chia thành n (ví dụ: 10 đối với CIFAR10) batch. Mỗi batch có số lượng sample như nhau.
Bước 4: thực hiện lấy mẫu đều(uniform sampling) b (budget, ví dụ như 1000 với CIFAR10) mẫu dữ liệu trong batch 1 để gán nhãn. Sử dụng dữ liệu đã gán nhãn để huấn luyện mô hình main task.
Bước 5: Sử dụng mô hình main task mới nhất để thực hiện inference các dữ liệu trong batch tiếp theo. Chọn b mẫu dữ liệu trong batch mà mô hình main task có độ tự tin thấp nhất (least confident sampling) để gán nhãn. Tiếp tục huấn luyện mô hình main task trên tất cả dữ liệu gán nhãn để thu được mô hình main task mới.
Bước 6: Lặp lại bước số 5 cho đến khi qua hết tất cả các batch.
Giải thuật này được mô tả một cách chặt chẽ hơn như dưới đây:

Những sự thật
Sự thật 1
Sự thật đầu tiên: độ chính xác trên CIFAR10 (95.13%) mà tác giả công bố là độ chính xác trên tập huấn luyện (training set).
Chúng ta đều biết rằng nếu huấn luyện mô hình trên tập train và đánh giá nó cũng trên tập train thì kết quả đó không thể phản ánh đúng độ chính xác thực tế khi mô hình được triển khai. Việc đánh giá phương pháp dựa vào độ chính trên tập huấn luyện không phải là điều mà tác giả mong muốn. Lỗi này được phát hiện bởi một thành viên trong team mình và đã có trao đổi với tác giả. Mình cảm thấy thật khó tin khi một bài báo được ECCV chấp nhận lại mắc một sai lầm sơ đẳng như vậy. Mình thử reproduce kết quả trên tập CIFAR10 của paper theo code sai ban đầu thì được ~95% như tác giả công bố. Tuy nhiên, sau khi sửa lại code để đánh giá trên tập test. Kết quả mình reproduce lại được là 90.41 (trung bình 10 lần chạy), thấp hơn 4.6% accuracy so với công bố của tác giả.
Sự thật 2
Sự thật thứ 2: bước thứ 3 của giải thuật là sắp xếp các sample theo loss của pretext task. Nhưng thay vì sort ở dạng float thì tác giả lại sort theo dạng dữ liệu ... string.
Đây lại là một sai lầm sơ đẳng khác mà tác giả không hề mong muốn. Một lần nữa, mình cảm thấy khó tin khi một bài báo được chấp nhận tại ECCV lại mắc phải một lỗi như thế này. Bằng một cách thần kỳ nào đó, sự sai sót này mang lại kết quả thực sự tốt. Thậm chí tốt hơn so với việc làm đúng theo phương pháp đề xuất. Nếu sửa đúng lại code theo phương pháp đề xuất kết quả trên tập CIFAR10 giảm từ 90.41% còn 90.12%. Đi kèm với việc sửa code thì loss cũng phải được sắp xếp theo thứ tự tăng dần thay vì giảm dần. Kết quả này vẫn tốt hơn baseline chọn random (~88%). Thật may là khi sửa code đúng (và sửa lại cách sắp xếp), nó vẫn có những hiệu quả của nó. Tuy nhiên, độ chính xác giảm rất đáng kể (~0.3%) chứ không tốt hơn.
Sự thật 3
Sự thật thứ 3: mô hình main task của theo phương pháp của tác giả có thể đã biết (aware) được tập dữ liệu test. Do đó kết quả report có thể không phản ánh đúng chất lượng của phương pháp.
Cụ thể, khi thực hiện thí nghiệm trên tập CIFAR10, tác giả huấn luyện mô hình main task trong 10 iteration (tương ứng với 10 batch). Sau mỗi iteration, labeled set sẽ tăng thêm có thêm 1000 samples. Từ iteration thứ 2 trở đi, tác giả lấy checkpoint tốt nhất trên tập dữ liệu test ở iteration trước để training tiếp với tập dữ liệu có nhãn mới. Như vậy có đến 9 lần tác giả chọn mô hình tốt nhất trên tập test để huấn luyện tiếp. Điều này có thể vô tình làm cho các mô hình ở iteration sau hoạt động tốt hơn chỉ trên tập test này. Cách xử lý như này vẫn có nhiều tranh cãi. Một số repo khác cũng làm như vậy và một số thì nói rõ là không làm như vậy. Tuy nhiên, trong bài báo tác giả không nói đến việc có sử dụng trick này. Điều này có thể không công bằng khi so sánh với các phương pháp khác không sử dụng trick này.
Sự thật 4
Sự thật thứ 4: việc chia các sample vào các batch dựa theo loss chỉ cần thiết với batch 1.
Phương pháp yêu cầu thực hiện sắp xếp các sample theo thử tự loss pretext task giảm dần và chia tập huấn luyện thành 10 task. Với những batch còn lại (batch 2 đến batch 10) mình đã thử nghiệm shuffle rồi chia random. Kết quả thu được hoàn toàn giống với phương pháp đề xuất sau (trung bình 10 lần chạy). Tuy nhiên, điều này cũng không ảnh quá nhiều đến kết quả cũng như độ hiệu quả của phương pháp đề xuất.
Thảo luận
Qua ví dụ về PT4AL chúng ta có thể thấy được rằng việc publish code là của các bài báo là rất cần thiết với cộng đồng. Cộng đồng có thể cùng nghiên cứu góp ý, chỉ ra lỗi sai cũng như học hỏi từ các nghiên cứu chất lượng. Tuy nhiên, không phải nghiên cứu nào tác giả cũng sẵn sàng publish code. Dù code vẫn chưa chuẩn chỉnh nhưng mình cám ơn tác giả đã publish code. Giả sử tác giả không pulish code, mình tự implement lại thì đúng là tốn rất nhiều công sức mà lại không biết được tại sao lại không reproduce được. Mình cũng đã thực hiện rất nhiều thí nghiệm trên code base của tác nhưng khi phát hiện những sự thật kể trên thì những thí nghiệm này không còn nhiều ý nghĩa nữa. Đây cũng là một kinh nghiệm quá báu cho mình.
Cũng cần phải nói thêm rằng, PT4AL cũng không phải là paper duy nhất không thể reproduce được kết quả report. Nhóm nghiên cứu của mình đã bắt gặp không ít lần hiện tượng này. Bên cạnh đó cũng có những paper có thể reproduce được kết quả rất sát với report mà cá nhân mình trải nghiệm. Một số ví dụ mà mình có thể nhớ: YOLOR, Learning Loss for Active Learning hay chính những nghiên cứu mà team mình là tác giả  .
.
Kết bài
Trong bài viết này, mình đã mượn PT4AL để nói những vấn đề mà mình gặp thường phải trong quá trình nghiên cứu, như: 1. Kết quả của bài báo không thể tái hiện lại được. 2. Phương pháp có sử dụng một số trick, góp phần đáng kể để giúp phương pháp đạt SOTA, nhưng lại không được nhắc đến trong bài báo. 3. Một số phần trong phương pháp hoàn toàn không đóng góp vào việc tăng hiệu quả của phương pháp.
Và với câu hỏi ở đầu bài viết: "với các bài báo mới từ những nguồn uy tín, liệu chúng ta có thể tin hoàn toàn vào những nghiên cứu này không?". Cá nhân mình cho rằng: không nên tin hoàn toàn, kể cả có code thì cũng phải reproduce lại mới biết được. Ý kiến của bạn thì sao? Bạn đã từng gặp paper nào có vấn đề tương tự như này chưa? Đừng ngại để lại comment hay gạch đá bên dưới nhé! Cảm ơn các bạn đã đọc bài.
Tài liệu tham khảo
PT4AL: Using Self-Supervised Pretext Tasks for Active Learning
All rights reserved
