
[Paper Explain] YOLOv7: Sử dụng các "trainable bag-of-freebies" đưa YOLO lên một tầm cao mới (phần 2)
Bài đăng này đã không được cập nhật trong 2 năm
Mở đầu
Ở bài viết lần trước, mình đã trình bày sơ qua các kiến thức các bạn sẽ gặp phải trong YOLOv7, nếu muốn các bạn có thể đọc lại ở đây: https://viblo.asia/p/paper-explain-yolov7-su-dung-cac-trainable-bag-of-freebies-dua-yolo-len-mot-tam-cao-moi-phan-1-zXRJ8BGOVGq.
Ở phần 1, mình có nhắc tới khái niệm Label Assignment và đã giải thích sơ qua. Tuy nhiên, đối với các model Object Detection thời hiện đại (từ nửa sau 2020 trở đi), thì Label Assignment trở thành một vấn đề cực kì quan trọng. Các thành phần khác của YOLOv7 (ngoài backbone ELAN) thì không có gì quá mới mẻ và có thể đã quen thuộc với nhiều người như: Model Scaling, RepVGG Block,... Riêng Label Assignment thì ảnh hưởng tới tận 2 thay đổi thực hiện trong YOLOv7, nên mình quyết định sẽ phân tích kĩ về Label Assignment tại phần 2 này.
Label Assignment (LA)
Ở phần trước, mình đã giới thiệu sơ qua Label Assignment (LA) nghĩa là gì. Có lẽ vẫn sẽ còn nhiều người thắc mắc positive/negative sample là gì. Cùng đi ngược lại YOLOv1 một chút nhé. YOLOv1, cụ tổ của YOLO, là phiên bản duy nhất không sử dụng đến Anchor Box từ YOLOv1-YOLOv5. Nhìn lại hàm loss của YOLOv1, ta sẽ thấy tất cả các hàm loss đều có một tham số phụ hay , với đại diện cho cell có tồn tại object và ngược lại với . Các cell có tồn tại object này sẽ được gọi là positive samples và các cell không tồn tại object sẽ được gọi là negative samples. Lúc này, việc định nghĩa positive/negative samples sẽ là quá trình đi gán cell nào là cell tồn tại object, cell nào là cell không tồn tại object. Việc này sẽ ảnh hưởng trực tiếp tới hàm loss của model, do đó, ảnh hưởng tới hiệu năng của model.
Nhưng YOLOv1 thì đã quá là lạc hậu và có những thứ không phù hợp, không áp dụng được với các model Object Detection bây giờ. Để hiểu rõ hơn về Label Assignment và điểm khác nhau giữa Anchor-based và Anchor-free, mình sẽ đưa các bạn quay về RetinaNet (Anchor-based Object Detection model) và FCOS (Anchor-free Object Detection model). Trong YOLOv1, ở feature map cuối cùng có kích cỡ dùng để đưa ra prediction, YOLOv1 sẽ thực hiện predict tâm của Bounding Box và chiều dài, rộng của Bounding Box khi cell đó được cho là positive sample. Tuy nhiên, trong FCOS, ta sẽ predict giới hạn của Bounding Box. FCOS sẽ từ một điểm trung tâm của một cell, predict khoảng cách từ điểm trung tâm của cell đó đến 4 cạnh của Bounding Box khi điểm trung tâm đó được cho là positive sample. Còn khi predict Box thì RetinaNet thực hiện predict như từ YOLOv2 trở đi, vì cùng là Anchor-based.
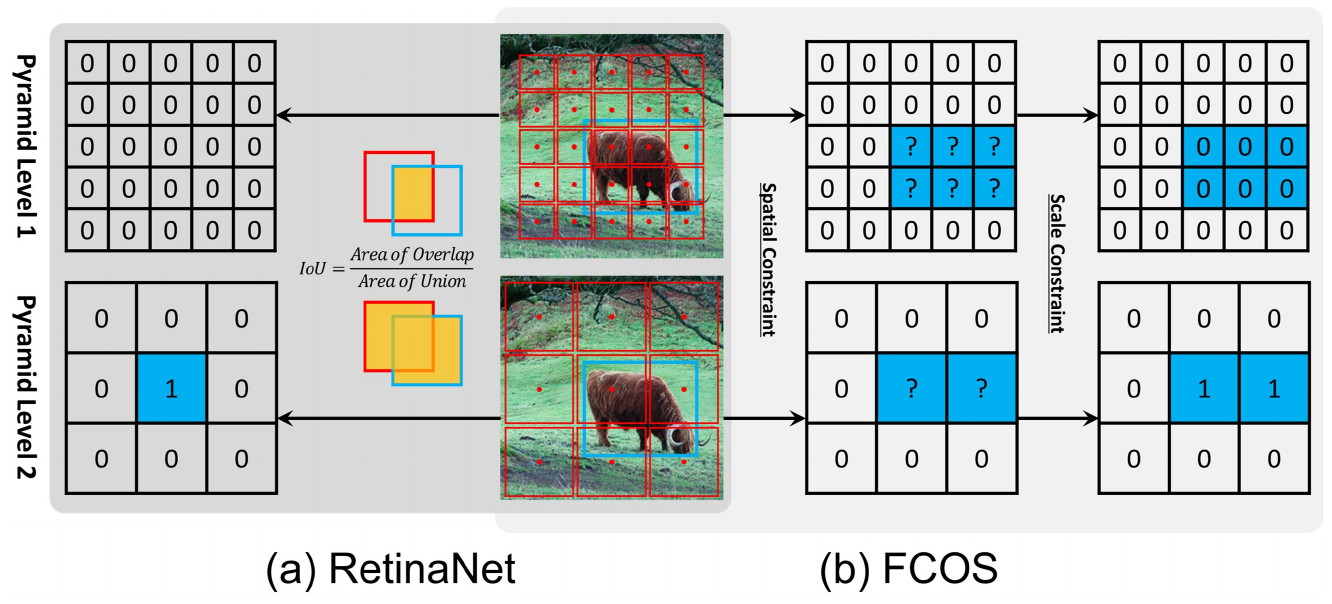
Để cho thuận tiện trong việc gọi tên, thì mình sẽ gọi luôn điểm trung tâm của một cell được sử dụng trong FCOS là anchor. Anchor trong các phương pháp Anchor-free là anchor point, còn anchor trong các phương pháp Anchor-based là anchor box, nên từ giờ mong các bạn sẽ chú ý đến ngữ cảnh khi mình sử dụng từ anchor. Có 3 điểm khác nhau chính giữa FCOS và RetinaNet:
- Số lương anchors được đính trong một cell: Như đã biết, Anchor-based sử dụng tới 9 anchors (với 3 kích cỡ và 3 hình dạng khác nhau) cho một cell. Còn với Anchor-free, điểm trung tâm của một cell thì chỉ có một mà thôi, làm gì có hình vuông nào mà có tới tận 2 cái điểm trung tâm.
- RetinaNet sử dụng IoU để xác định xem anchor nào là positive anchor, đây là chiến thuật Label Assignment của RetinaNet. Nếu chưa rõ về cách chọn positive anchor sử dụng IoU, mời các bạn đọc lại bài phân tích YOLOv2 của mình ở đây. Còn FCOS sử dụng giới hạn về scale và kích cỡ (Hình 1). Về chi tiết, mình khuyến khích các bạn nên đọc phần 3.2 trong paper FCOS để hiểu rõ được. Còn nếu có thắc mắc thì hãy comment xuống phía dưới để mình giải thích kĩ hơn.
- Cách predict ra box (Hình 2): RetinaNet predict Box dựa trên độ lệch giữa Anchor Box và Bounding Box. Còn FCOS predict Box dựa trên khoảng cách từ anchor tới 4 cạnh như mình đã nói ở trên.
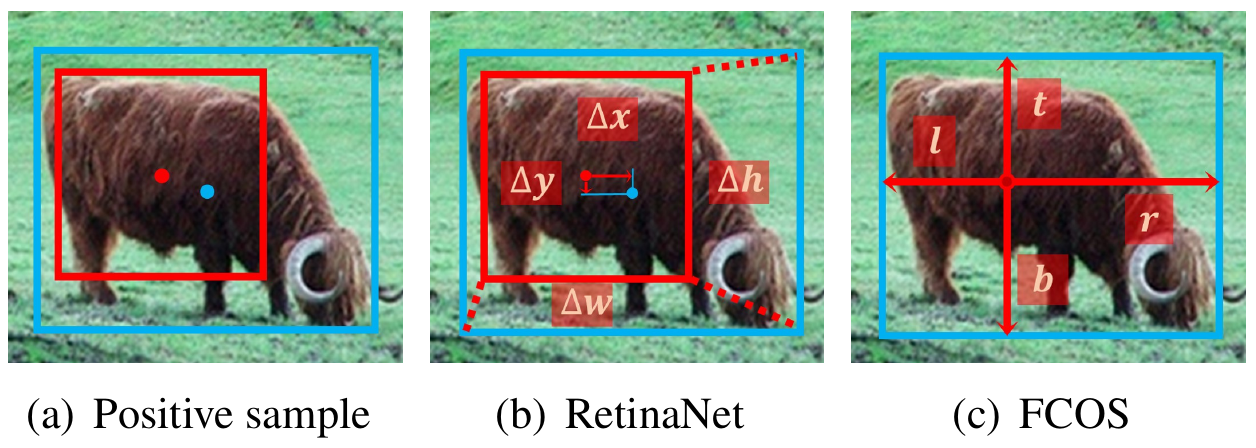
Hy vọng là với phần giải thích phía trên, các bạn đã hiểu kĩ hơn về positive/negative samples, LA là làm gì và sự khác nhau giữa Anchor-based và Anchor-free model.
OTA và SimOTA
YOLOv7 sử dụng LA là SimOTA (Simple OTA), chiến thuật LA được sử dụng trong YOLOX, là phiên bản đơn giản hơn của OTA. Ở phía dưới, mình sẽ phân tích về OTA và sau đó đi vào SimOTA.
Trước tiên, ta phải hiểu, LA của FCOS có gì chưa tốt?
- Vẫn còn phải sử dụng các hyper-params: FCOS đề ra các hyper-params là giới hạn về scale và kích cỡ để chọn positive samples ứng với từng scale của FPN.
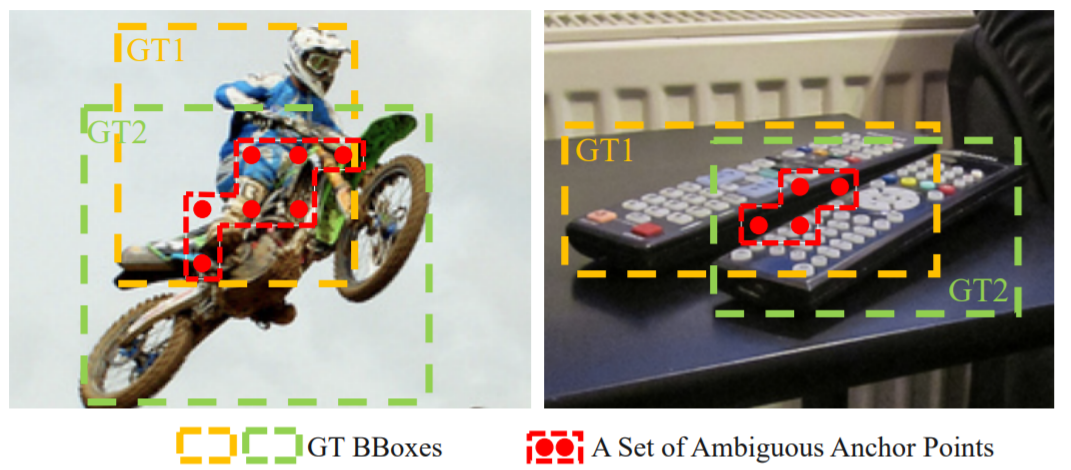
- Chưa giải quyết được các trường hợp anchors "ambigous" (không rõ ràng - Hình 3): Một anchors được cho là ambigous khi anchors đó thỏa mãn làm positive sample cho nhiều gt cùng 1 lúc. Như ở hình 3, các bạn có thể thấy gán các anchors được đánh dấu làm positive sample cho cả 2 gt box thì đều phù hợp cả. Nếu ta gán bừa những anchors này cho Background (BG) hay cho một object nào đó thì nó sẽ gây ảnh hưởng đến object khác, từ đó làm giảm hiệu suất của model.
Để khắc phục 2 nhược điểm kể trên, OTA muốn:
- Tự động chọn positive samples theo thuật toán chứ không phải phụ thuộc vào các hyper-params được định nghĩa trước (1)
- Số lượng positive samples cho từng object là khác nhau, vì mỗi object có kích cỡ, hình dạng khác nhau (2)
- Sử dụng Global View để chọn positive samples từ các ambiguous anchors (3)
LA là một bài toán Optimal Transport (OT)
 Cảnh báo: Phần tiếp theo sẽ bao gồm rất nhiều toán, và thuật toán
Cảnh báo: Phần tiếp theo sẽ bao gồm rất nhiều toán, và thuật toán
OTA giải quyết đồng thời (1) và (3) nhắc tới bên trên bằng việc coi quá trình Label Assigment là một bài toán Optimal Transport, từ đó tạo ra cái tên OTA: Optimal Transport Assignment. Vậy OT là gì và nó giúp ích gì cho việc giải quyết (1) và (3)? (1) thì có vẻ dễ hiểu rồi, mình sẽ làm rõ Global View trong (3) là gì nhé. Với các chiến thuật LA đã từng được đề ra, chúng thất bại trong việc giải quyết ambiguous anchors vì chúng sử dụng các hyper-params (Min Area, Max IoU) hoặc Local View. Local View nghĩa là chúng tập trung LA tốt cho một object trong một ảnh mà không hề quan tâm tới các objects khác như nào, lần lượt thực hiện LA cho các object trong ảnh một cách độc lập với nhau. Chính vì chúng ta chỉ thực hiện LA từng object trong ảnh một cách độc lập, nên rất dễ xảy ra trường hợp một anchor được chọn làm positive sample cho tới 2 objects. Vì vậy, Global View là thực hiện gán positive samples cho anchors một cách có tương tác giữa các anchors với nhau, khiến việc chọn 1 anchor làm positive sample cho cả 2 objects là không xảy ra. DETR là nghiên cứu đầu tiên mà thực hiện LA theo dạng Global View. DETR thực hiện one-to-one assignment (OTO assigment - một object gán với một positive sample) bằng cách sử dụng thuật toán Hungarian. Nếu muốn tìm hiểu sâu hơn về LA trong DETR, các bạn có thể đọc bài giải thích của một kouhai trong team mình tại đây. Tuy nhiên, đấy là LA áp dụng cho Transformer, còn với CNN thì khác. Vì với tính chất của CNN là thu nhặt sự tương quan giữa các vùng lân cận với nhau, nên thay vì áp dụng OTO Assignment thì áp dụng one-to-many assignment (OTM Assignment - gán một object với một positive sample trọng điểm và các positive samples gần sample trọng điểm đó) sẽ tốt hơn với CNN. Và thuật toán Optimal Transport (OT) sẽ giúp giải quyết vấn đề nêu trên một cách tuyệt vời.
Bài toán Optimal Transport (OT)
Bài toán OT mô tả vấn đề như sau: Giả dụ có nguồn cung và nguồn cầu ở trong một khu vực. Nguồn cung thứ có đơn vị hàng hóa còn nguồn cầu thứ cần đơn vị hàng hóa. Chi phí vận chuyển mỗi đơn vị hàng hóa từ nguồn cung thứ sang nguồn cầu thứ kí hiệu là . Mục tiêu của OT là tìm một kế hoạch vận chuyển sao cho toàn bộ hàng hóa từ nguồn cung có thể chuyển sang nguồn cầu với chi phí nhỏ nhất:
Áp dụng bài toán Optimal Transport (OT) cho LA
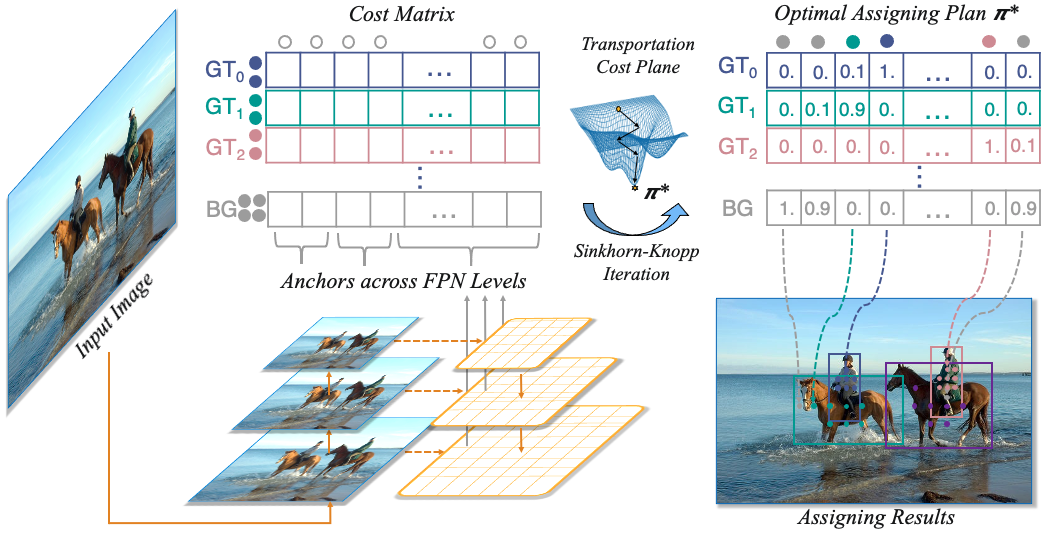
Oke áp dụng OT vào Label Assignment nào. Giả dụ, trong một ảnh , ta có gt và anchors. Ta sẽ coi mỗi gt là một nguồn cung có thể cung cấp positive samples (hay nói cách khác là một gt sẽ cần phải được gán cho positive samples), tức là , và mỗi anchor sẽ là một nguồn cầu cần một sample (anchor đó cần được gán là positive hoặc negative), tức là . Chi phí vận chuyển một positive sample từ sang anchor , , được định nghĩa là phép cộng có hệ số của cls và reg loss:
với là các parameters của model. và là prediction của model về Classification score và Bounding Box của anchor . và là gt của Classification và Bounding Box của . và là Loss của Classification và Regression (Bounding Box). là hệ số cân bằng.
Ngoài việc tìm và gán positive samples cho anchors, thì ta cũng cần phải chú ý tới negative samples, chiếm phần lớn trong mọi bức ảnh. Và để giải thuật toán OT thì ta cũng cần phải xét toàn bộ anchors trên một ảnh, nên ta sẽ thêm vào một nguồn cung nữa đó là Background (BG), nguồn cung này sẽ chỉ cung cấp negative samples. Số lượng negatives samples mà nguồn cung BG có thể cung cấp được là . Lúc này, chi phí để vận chuyển một đơn vị negative sample từ nguồn cung sang anchor là:
với là class BG. Concat ma trận vào hàng cuối cùng của ma trận , ta sẽ được ma trận chi phí vận chuyển bản full là .
Với sự xuất hiện của nguồn cung BG, vector nguồn hàng có thể cung cấp như sau:
Oke dừng lại một chút để giải thích kĩ hơn về ma trận chi phí vận chuyển bản full (mình sẽ gọi tắt là cost matrix) này nào. Cost matrix được tạo từ 2 ma trận con: ma trận chi phí vận chuyển của positive samples và ma trận chi phí vận chuyển của negative samples. Cost matrix có số hàng là với là số object có trong ảnh, cũng là số hàng của , là do thêm 1 hàng nữa từ ma trận ; số cột của cost matrix là , ứng với toàn bộ anchors trong ảnh đó. Các bạn nên vừa nhìn hình 4 vừa đọc thì sẽ dễ hiểu hơn.
Bài toán OT được giải sử dụng một thuật toán nữa gọi là Sinkhorn-Knopp Iteration. Mình xin phép không đi sâu vào thuật toán Sinkhorn-Knopp này vì nó không cần thiết để hiểu OTA. Sau khi giải xong, ta sẽ thu được kế hoạch vận chuyển tối ưu , từ đó gán anchors với nguồn cung positive/negative samples tương ứng (Hình 4).
OTA viết theo dạng mã giả như sau:
Input:
- là một ảnh đầu vào
- là tập hợp các anchors trong ảnh
- là gt cho object trong ảnh
- và : tham số gì đó liên quan đến thuật toán Sinkhorn-Knopp
- : hệ số cân bằng
Output: : kế hoạch vận chuyển tối ưu
- : là số lượng gt trong một ảnh, là số lượng anchors trong một ảnh
- : thực hiện forward pass một ảnh qua model
- Dynamic estimation: thực hiện Dynamic estimation để tìm ra số lượng positive samples mà từng nguồn cung có thể cung cấp là bao nhiêu (sẽ nói cụ thể về Dynamic estimation sau). Chính là ở hệ phương trình trên kìa
- : số negative samples mà nguồn cung BG có thể cung cấp
- OnesInit: mỗi nguồn cầu anchor cần được gán là 1 sample, positive hoặc negative
- : tính Classification Loss của từng nguồn cung và nguồn cầu
- : tính Regression Loss của từng nguồn cung và nguồn cầu
- : tính center prior cost (sẽ nói sau) của từng nguồn cung và nguồn cầu
- cost:
- cost:
- concat ma trận vào để tạo ra cost matrix
- thực hiện Sinkhorn-Knopp Iteration thu được kế hoạch vận chuyển tối ưu
- return
Dynamic k estimation và Center Prior
Oke với OT cho LA, ta đã giải quyết được vấn đề (1) và (3) đã nêu phía trên. Còn vấn đề (2): Số lượng positive samples cho từng object là khác nhau; sẽ được giải quyết với Dynamic k estimation.
Với mỗi một object trong ảnh, OTA sẽ chọn ra top các predictions dựa trên giá trị IoU của Bounding Box dự đoán và gt Bounding Box. Sau khi có được giá trị IoU lớn nhất, với mỗi giá trị IoU nằm trong khoảng [0,1], ta sẽ cộng toàn bộ giá trị IoU đó lại rồi lấy phần nguyên, đó chính là số positive samples được chọn ra cho một object.
Center Prior là một sự cải tiến thêm do mọi người đều nhìn thấy rằng nếu gán positive samples cho các anchors có vị trí gần tâm của object thì sẽ khá là có lợi. Vì vậy, tác giả tạo ra một hình vuông có diện tích bao quanh tâm của object trên mỗi level của FPN. Vì vậy, muốn gán cho một anchor nào đó là positive sample, nó phải thỏa mãn 2 yếu tố: nằm trong Bounding Box của object và nằm trong hình vuông bao quanh tâm object.
Để hình dung được OTA hoạt động như nào thì mình đã có viết 1 đoạn code để hiển thị các thành phần quan trọng của OTA lên ảnh, kết quả ở hình 5.

SimOTA
Vì OTA yêu cầu phải giải quyết bài toán OT thông qua thuật toán Sinkhorn-Knopp Iteration, làm tăng thời gian training lên tới 20%, nên YOLOX đã thay thế OTA thành simOTA (simple OTA chứ k phải simp đâu nhé). Lúc này, simOTA chỉ quan tâm đến chi phí vận chuyển positive samples từ gt sang anchors, nên cost matrix sẽ chỉ còn lại như sau:
đây chính là của OTA. simOTA lần này sẽ chỉ thực hiện Dynamic estimation và gán các top-k anchors ( được chọn thông qua Dynamic estimation) thỏa mãn thấp nhất làm positive samples luôn.
Kết
Phía trên là một bài phân tích tuy chưa đầy đủ nhưng cũng khá dài về Label Assignment, cũng như là simOTA, Label Assignment được sử dụng trong YOLOv7. Hy vọng trong phần sau của series phân tích YOLOv7 mình sẽ không cần phải nói quá kĩ về 1 phần nào đó như này nữa (vì không có gì khó, mới và ít bài phân tích như Label Assignment). Nếu có gì sai sót, mong các bạn có thể góp ý cho mình ở dưới comment.
Phần 3 của chuỗi YOLOv7 đã có ở đây: https://viblo.asia/p/paper-explain-yolov7-su-dung-cac-trainable-bag-of-freebies-dua-yolo-len-mot-tam-cao-moi-phan-3-018J253M4YK
Reference
YOLOv7: https://arxiv.org/abs/2207.02696
All rights reserved
