
[Paper Explain] YOLOX: đi ngược lại những người tiền nhiệm
Bài đăng này đã không được cập nhật trong 2 năm

Những nghiên cứu mới xuất hiện mới với tốc độ cực nhanh trong ngành trí tuệ nhân tạo nói chung và thị giác máy tính nói riêng. Nghiên cứu sau dựa trên nghiên cứu trước. Những kỹ thuật được chứng minh là hiệu quả qua nhiều năm khiến chúng ta ít khi nghĩ rằng chúng nên được bỏ đi. Thi thoảng mình cũng hay bắt gặp những bài báo "rethinking" (hay "revisiting")để xem xét lại vấn đề và mình nghĩ điều này là thực sự cần thiết để kiểm tra lại những thứ mà chúng ta thường cho rằng "nó phải thế".
YOLOX có thể được coi là một bài "rethinking" như vậy. Kỹ thuật sử dụng anchors được áp dụng từ YOLOv2 và kỹ thuật coupled head thậm chí được sử dụng trong tất cả các phiên bản YOLO tiền nhiệm. Những thay đổi trong YOLOX bao gồm việc không còn sử dụng anchor và coupled head. Cụ thể, khác với phiên bản trước, YOLOX là anchor-free và decoupled head. Mặc dù những thay đổi này đã được nghiên cứu qua các bài báo trước đó, những vẫn chưa được ứng dụng vào YOLO, và YOLOX đã chính thức áp dụng chúng. Trong bài này, mình sẽ tóm tắt những thay đổi chính của YOLOX và hiệu quả của chúng.
Lưu ý: khi nhắc đến các phiên bản tiền nhiệm của YOLO, mình đang muốn nói đến YOLO, YOLOv2, YOLOv3, YOLOv4, Scaled-YOLOv4, YOLOv5, và YOLOR.
Một số thuật ngữ tạm dịch
coupled head: đầu gộp
decoupled head: đầu tách
strong augmentation: tăng cường dữ liệu mạnh
multi positives: đa tích cực
Tổng quan
Hai năm qua, đã có nhiều tiến bộ trong nghiên cứu cho bài toán phát hiện vật thể như máy phát hiện vật thể anchor-free, chiến lược gán nhãn nâng cao (advanced label assignment strategies), máy phát hiện vật thể end-to-end. Những tiến bộ này vẫn chưa được áp dụng cho YOLO. Nhận thấy điều này, tác giả đã tiến hành thử nghiệm và cho ra đời YOLOX.
Cụ thể trong bài này, tác giả trình bày việc áp dụng các kỹ thuật:
- Đầu tách
- Tăng cường dữ liệu mạnh
- anchor-free
- Đa tích cực
- SimOTA
- NMS free (kỹ thuật thuật này không được áp dụng vào phương pháp đề xuất do làm giảm độ chính xác và tốc độ)
Những cải tiến
Đầu tách
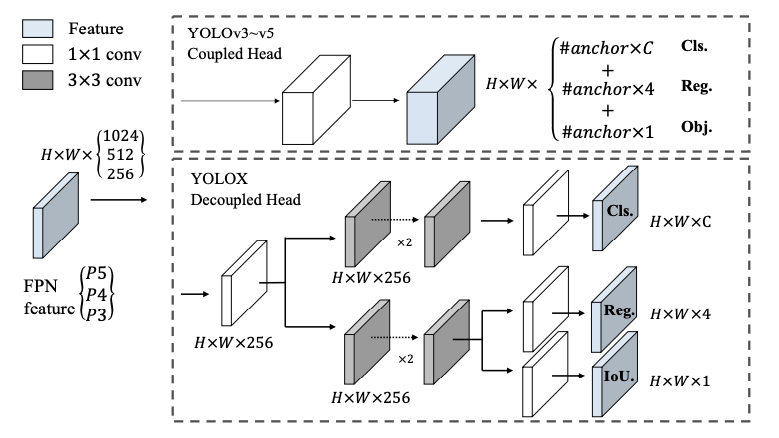
Một vấn đề với đầu gộp là sự xung đột giữa task phân loại và task hồi quy, vấn đề này làm ảnh hưởng đến độ chính xác của mô hình nói chung. Đó là lý do mà hầu hết các bộ phát hiện vật thể, dù là một bước hay hai bước đều sử dụng đầu tách. Về mặt kiến trúc, họ nhà YOLO đã phát triển nhiều xương sống và tháp đặc trưng (feature pyramids). Tuy nhiên, từ trước đến nơi họ nhà YOLO luôn sử dụng đầu gộp. YOLOX thấy điều này cần phải thay đổi.
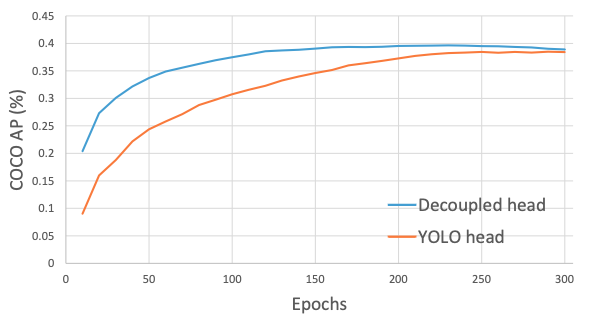
Các thí nghiệm của tác giả đã chỉ ra rằng, việc gộp đầu sẽ làm giảm hiệu năng của bộ phát hiện và thay thế đầu gộp giúp tăng tốc độ hội tụ của mô hình như minh hoạ ở hình 2. Việc tách đầu được tác giả thực hiện cùng với việc thay thế một lớp conv thành bốn lớp conv và bốn lớp conv như minh hoạ trong hình 1.
Tăng cường dữ liệu mạnh
Tác giả sử dụng Mosaic và MixUp để tăng hiệu năng của YOLOX. Những kỹ thuật này không phải là mới và đã được áp dụng vào bài toán phát hiện vật thể từ lâu. Sau khi áp dụng kỹ thuật tăng cường dữ liệu mạnh, việc huấn luyện trước trên tập dữ liệu ImageNet không mang lại lợi ích nữa nên tác giả huấn luyện mô từ đầu.
Anchor-free
Kỹ thuật sử dụng anchor được áp dụng từ YOLOv2 đến YOLOR. Kỹ thuật này yêu cầu quá trình xác định những anchor tối ưu cho việc huấn luyện (bằng cách phân cụm, tiến hoá). Những anchor này phụ thuộc vào miền của dữ liệu(domain-specific) và thiếu tính tổng quát. Hơn nữa, cơ chế sử dụng anchor tăng độ phức tạp của đầu phát hiện cũng như số lượng dự đoán mỗi ảnh. Việc không sử dụng anchor làm giảm số lượng siêu tham số cần phải tinh chỉnh, giảm độ phức tạp của đầu detect và loại bỏ những vấn đề liên quan (phân cụm anchor...)
Việc chuyển YOLO sang anchor-free khá đơn giản. Mỗi đầu dự đoán, thay vì dự đoán cho ba anchor thì chỉ cần dự đoán một lần và dự đoán trực tiếp các giá trị chiều cao và chiều rộng của vật thể. Ví dụ, như đối với tập COCO thì đầu ra của mỗi đầu của YOLOX sẽ có chiều (trong trường hợp gộp đầu) là (thay vì ). Những thay đổi này sẽ giảm số lượng tham số và GFLOPs của máy phát hiện làm tăng tốc độ của mô hình. Và khá bất ngờ, nó cũng làm tăng độ chính xác.
Lưu ý: khi làm thí nghiệm với anchor-free, ở đây, mỗi đối tượng chỉ được một grid tích cực đảm nhận việc phát hiện đối tượng đó. Việc chọn grid này dựa vào vị trí trung tâm của đối tượng trên ảnh và kích thước của đối tượng để xác định mức FPN phù hợp.
Đa tích cực
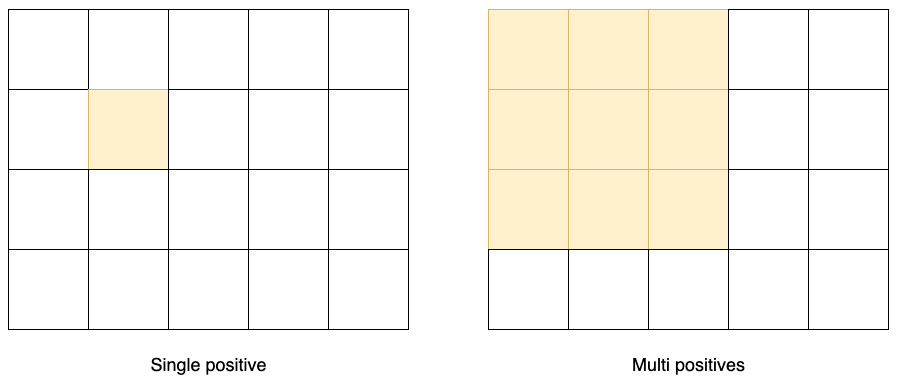
Việc chỉ có một grid tích cực cho một vật thể sẽ làm giảm độ chính xác của mô hình. Những grid khác, nếu có thể đảm nhận tốt việc phát hiện vật thể sẽ mang lại lợi ích về gradient, và làm giảm sự mất cân bằng giữa số lượng grid tích cực/tiêu cực trong quá trình huấn luyện. Với kỹ thuật này, tác giả gán vùng trung tâm thành tích cực như minh hoạ trên hình 3. Việc sử dụng kỹ thuật này làm tăng đáng kể độ chính xác của mô hình.
SimOTA
Phương pháp đa tích cực như trên để gán nhãn làm tăng đáng kể độ chính xác. Tuy nhiên, dựa trên một nghiên cứu khác của chính nhóm tác giả, một phương pháp gán nhãn tốt cần phải có bốn yếu tố: 1) nhận thức về mất mát/chất lượng, 2) center prior, 3) linh hoạt số lượng grid tích cực cho từng đối tượng, và 4) có cái nhìn toàn cục. Phương pháp OTA mà tác giả nghiên cứu thoả mãn cả bốn yếu tố này. (Ở đây có thể sẽ hơi khó hiểu một chút, các bạn có thể đọc thêm bài báo OTA để hiểu hơn về những yếu tố này)
Việc sử dụng OTA cải thiện rất nhiều độ chính xác của mô hình được huấn luyện. Tuy nhiên, do phương pháp OTA làm tăng 25% thời gian huấn luyện, là tương đối lớn nếu chạy 300 epochs. Do đó tác giả sử dụng phiên bản đơn giản hơn của nó là SimOTA để thu được một kết quả gần giống như vậy.
SimOTA đầu tiên tính mức độ phù hợp của từng cặp dự đoán-nhãn, được biểu diễn bởi chi phí (cost). Chi phí giữa nhãn và dự đoán được tính như sau:
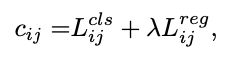
trong đó là hệ số cân bằng, và là giá trị mất mát phân loại và mất mát hồi quy giữa nhãn và dự đoán . Sau đó, với mỗi nhãn , chúng ta chọn top dự đoán có giá trị mất mát ít nhất trong một vùng trung tâm cố định (ví dụ là vùng ), những grid này được chọn làm những grid tích cực. Những grid còn lại là grid tiêu cực. Giá trị là khác nhau với các vật thể khác nhau. Để hiểu rõ hơn phần này, bạn đọc có thể tìm hiểu thêm phần "Dynamic Estimation strategy" trong OTA.
Chiến lược gán nhãn SimOTA làm tăng đáng kể độ chính xác của mô hình so với việc sử dụng chiến lược đa tích cực.
Kết quả
Kết quả thử nghiệm các phương pháp
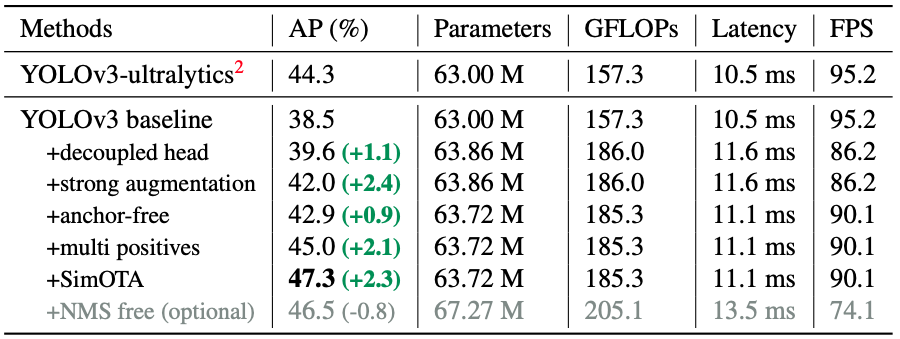
Baseline được chọn để so sánh là mô hình YOLOv3 với một số thay đổi so với paper YOLOv3. Từ hình 4, ta có thể thấy tất cả các kỹ thuật (trừ NMS free) đều cải thiện chỉ số AP. Sau khi thêm đầu tách, độ trễ của mô hình tăng do phải tăng thêm các lớp tích chập ở các đầu phát hiện. Sau khi thêm anchor-free thì độ trễ giảm, do độ phức tạp của các đầu phát hiện giảm đi.
So sánh với các SOTA khác
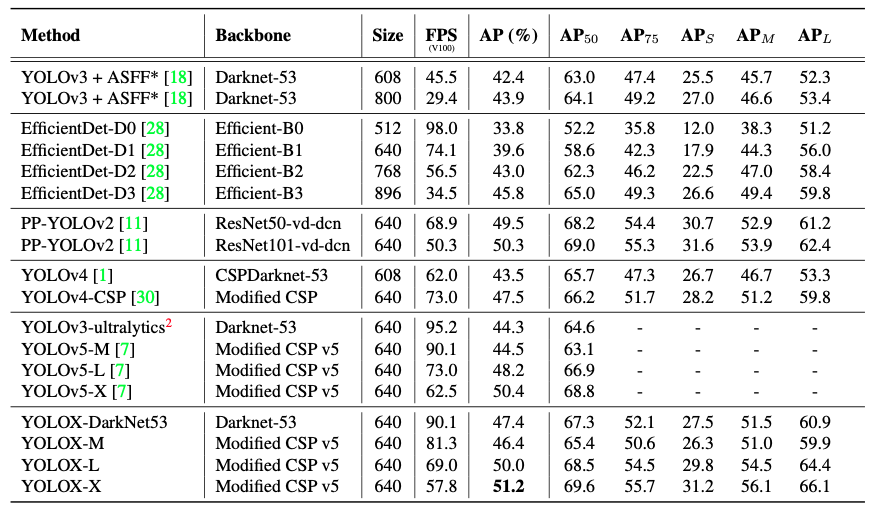
Từ hình 5, ta có thể thấy YOLOX đã cải thiện đáng kể chỉ số AP so với các SOTA trước. Tuy nhiên, khi so sánh với YOLOv5, điểm FPS cũng đã giảm xuống như một phần đánh đổi lấy điểm AP.
Lời kết
Tổng kết một chút về bài báo YOLOX, cá nhân mình thấy kỹ thuật đầu tách + anchor-free và SimOTA khá tiềm năng để được tiếp tục sử dụng ở những phiên bản sau của YOLO. Đặc biệt là SimOTA, vì nó chỉ tăng thời gian lúc huấn luyện và không có ảnh hưởng đến độ trễ lúc dự đoán. Những cải tiến liên quan đến gán nhãn (label assigment) của OTA cũng rất hay. Sắp tới mình cũng sẽ viết bài về sự thay đổi các phương pháp gán nhãn qua các đời YOLO và các phương pháp gán nhãn với bài toán phát hiện vật thể nói chung. SimOTA cũng đã được tích hợp vào YOLOR và cải thiện đáng kể chỉ số AP, các bạn có thể theo dõi thêm trên Github chính thức của YOLOR.
Cá nhân mình thấy bài báo YOLOX khá dễ đọc nên khuyến khích các bạn đọc bài báo gốc. Vì mục đích của bài viết này chỉ nhằm tóm tắt tổng quan các ý chính. Hy vọng bài viết này có ích với bạn. Cảm ơn các bạn đã đọc bài. Nếu các bạn có câu hỏi hay điều gì cần trao đổi thì đừng ngại để lại ở phần bình luận nhé. See ya!
Tham khảo/reference
https://arxiv.org/pdf/2107.08430.pdf
https://aicurious.io/posts/papers-yolox/
All rights reserved
