
[Paper Explain] YOLOv7: Sử dụng các "trainable bag-of-freebies" đưa YOLO lên một tầm cao mới (Phần 1)
Bài đăng này đã không được cập nhật trong 3 năm
Mở đầu
Chắc hẳn mọi người đã không còn xa lạ gì với cái tên YOLO, làm mưa làm gió trong bài toán Object Detection với tốc độ cực nhanh mà vẫn có độ chính xác khá cao. Bộ đôi WongKinYiu và Alexey đã có khá nhiều đóng góp cho họ nhà YOLO với YOLOv4, Scaled-YOLOv4, YOLOR và đến gần đây là một bản cập nhật cực kì khủng khiếp: YOLOv7.
Mình xin dịch nguyên cái tóm tắt cực kì trẻ trâu của YOLOv7 như sau:
YOLOv7 vượt qua mọi model Object Detection trong cả tốc độ và độ chính xác từ 5 FPS tới 160 FPS và đạt độ chính xác cao nhất với 56.8% AP trong số toàn bộ các model Object Detection real-time, có tốc độ 30 FPS hoặc hơn trên GPU V100. YOLOv7-E6 (56 FPS trên V100, 55.9% AP) vượt qua cả backbone nhà Transformer là SWIN-L Cascade-Mask R-CNN (9.2 FPS trên A100, 53.9% AP) với 509% về tốc độ và 2% về AP, hay là cả các backbone CNN cao cấp như ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS trên A100, 55.2% AP) với 551% về tốc độ và 0.7% về AP. Và đương nhiên là YOLOv7 cũng vượt qua cả: YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5, DETR, Deformable DETR, DINO-5scale-R50, ViT-Adapter-B cũng như là rất nhiều các mạng Object Detection khác cả về mặt tốc độ cũng như là độ chính xác. Hơn nữa, YOLOv7 được train trên COCO từ đầu mà không sử dụng bất kì pretrained nào.
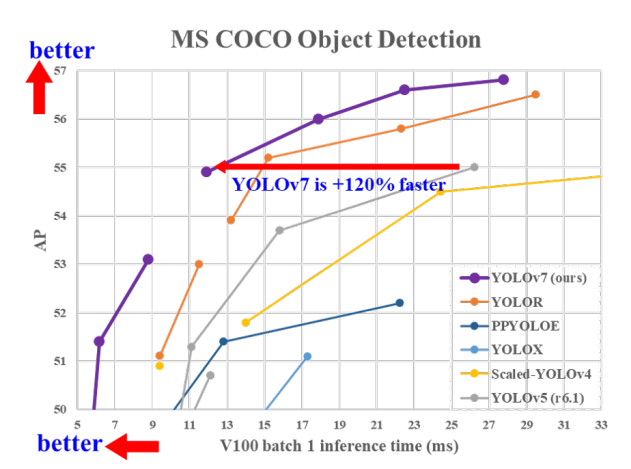
Trong phần 1 của bài phân tích YOLOv7 này, mình sẽ nói về các kiến thức cần nắm được để có thể hiểu được YOLOv7. Nếu có bất kì sai sót nào mong các bạn có thể góp ý cho mình.
Một số khái niệm, kiến thức cần nắm được
Bag-of-freebies
Bag-of-freebies (BoF): Khái niệm này lần đầu được nhắc tới trong YOLOv4. BoF là các kĩ thuật được thêm vào trong training có thể tăng độ chính xác mà không tăng thời gian xử lý của model: kĩ thuật Augmentations, hàm loss, label smoothing,...
Label Assignment
Như chúng ta đã biết, các model Object Detection mạnh từ trước tới nay đều sử dụng kĩ thuật Anchor Box. Nếu chưa rõ kĩ thuật Anchor Box là gì, các bạn có thể đọc ở đây. Tuy nhiên, với sự ra đời của FCOS, đạt độ chính xác khá cao mà không cần sử dụng đến Anchor Box, đã có khá nhiều sự chú ý dành cho việc loại bỏ Anchor Box ra khỏi các model Object Detection. Ta gọi các dạng model đó là Anchor-free. Thế việc loại bỏ Anchor Box có tác dụng gì mà các nhà nghiên cứu lại dành nhiều sự chú ý đến chúng?
- Việc đau đầu nhất khi sử dụng Anchor Box đó chính là các hyper-parameters để định nghĩa kích cỡ, hình dạng của các Anchor Box, liệu rằng các Anchor Box ta chọn có phù hợp với Dataset đó không? Thông thường, các hyper-parameters này sẽ được chọn thông qua thuật toán k-means (từ YOLOv2). Tuy nhiên, các Anchor Box được chọn bởi k-means đó thường đã bị fit trên COCO, và đôi lúc sẽ không hoạt động tốt với custom Dataset. YOLOv5 đã khéo léo xử lý việc này bằng việc sử dụng Genetic Algorithm (GA) vào sau k-means để chọn ra bộ Anchor Box phù hợp hơn với custom Dataset. Việc này thêm một chút thời gian trong lúc training.
- Loại bỏ việc tính toán liên quan tới Anchor Box trong training. Với việc sử dụng Anchor Box, trong lúc training, ta sẽ phải thực hiện các phép tính IoU để xét Anchor Box nào sẽ ứng với Ground Truth (GT) Box nào.
Tóm lại là Anchor-free thì training nhanh hơn, dùng ít GPU/CPU hơn là sử dụng Anchor Box (Anchor-based).
Tuy nhiên, cho tới tận FCOS thì những model Anchor-based vẫn cho ra kết quả tốt hơn Anchor-free. Cho tới tận ATSS thì các phương pháp Anchor-free mới có thể đạt độ chính xác ngang bằng với Anchor-based. ATSS cho rằng sự khác biệt giữa Anchor-free và Anchor-based thực chất nằm ở cách chúng ta định nghĩa thế nào là một positive sample (fore-ground/FG), thế nào là một negative sample (background/BG). Và nếu positive samples và negative samples được định nghĩa tốt thì độ chính xác của các phương pháp Anchor-free có thế sánh ngang với Anchor-based.
Và quá trình tìm ra định nghĩa cho Positive và Negative samples này gọi là quá trình Label Assignment. Nếu các bạn muốn hiểu sâu hơn về quá trình Label Assignment từ đầu thì mình khuyến khích các bạn đọc phần 3.1 trong paper FCOS và 3.3 trong paper ATSS.
Re-parameterization
Một idol trong team mình đã có 1 bài phân tích về paper nói về kĩ thuật Re-parameterized ở đây. Còn ở đây, mình sẽ tóm tắt lại để các bạn hiểu được Re-parameterization (Re-param) là gì, hoạt động ra sao và có ích như nào.
Kĩ thuật Re-param đơn giản nhất được áp dụng lần đầu trong họ YOLO là tại YOLOv5. Khi mà các bạn thực hiện inference với YOLOv5, nó thường xuất hiện dòng "Fusing layers..." như dưới này nè

Đấy là YOLOv5 đang thực hiện hợp nhất lớp Convolution (Conv) và lớp BatchNorm (BN) vào làm một lớp, khiến việc inference diễn ra nhanh hơn (từ 2 layers là Conv + BN -> Conv). Quá trình hợp nhất này chỉ diễn ra trong lúc inference, còn trong lúc training model thì nó vẫn hoạt động như bình thường, là 2 lớp riêng biệt: Conv và BN. Đây gọi là kĩ thuật Re-param.
Tiếp theo, mình sẽ giải thích cách mà Re-param hoạt động, chú ý rằng phần này sẽ bao gồm toán học, nếu các bạn không có nhu cầu hiểu sâu hơn thì có thể bỏ qua.
Trước tiên, ta phải nhớ lại cách mà BN hoạt động. Trong quá trình training, khi đưa một mini-batch gồm phần tử, ta sẽ có thể tính được mean và variance của mini-batch phần tử đó như sau:
Với một đầu vào là vector có chiều, , ta sẽ tiến hành normalized mỗi chiều đó một cách riêng biệt như sau:
với và ; là channel thứ của input thứ trong batch gồm input, là mean của batch gồm input tại channel thứ , tương tự với .
Lúc này, có mean là 0, và variance là 1. Để trả lại sự biểu diễn mạnh mẽ của mạng nơ-ron, thay vì chỉ lấy đơn điệu là một sự biểu diễn với mean 0, variance 1, ta thêm vào BN 2 "learnable parameter" là và . Do đó, được biến đổi như sau:
Hay:
Mở rộng BN lên tensor gồm 4 chiều (batch, channels, height, width), quá trình inference của BN diễn ra như sau:
Để có thể gộp lớp Conv và BN vào làm một, ta phải tạo ra một lớp Conv mới hành xử như 2 lớp. Cụ thể, weight và bias của lớp Conv mới được biến đổi như sau:
Chú ý chiều của tensor weight lại được biểu diễn là . Chỗ này có thể hơi khó hiểu vì BN thực hiện trên chiều channels, mà tại sao thứ bị đổi ở đây lại là chiều đầu tiên của tensor weight. Đó là vì tensor weight của một lớp Conv trong Pytorch được biểu diễn như ảnh dưới

Vì vậy, lớp Conv mới được tạo ra sau khi kết hợp BN vào lớp Conv cũ như sau:
def fuse_conv_and_bn(conv, bn):
# tạo ra một lớp Conv mới là lớp Conv kết hợp BN với lớp Conv cũ
fusedconv = nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
# Prepare filters
w_conv = conv.weight.clone().view(conv.out_channels, -1) # weight của lớp conv cũ
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var))) # tạo ra phân số trong phép tính (1)
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape)) # tính weight mới cho lớp Conv mới theo công thức (1)
# Prepare spatial bias
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn) # công thức (2)
return fusedconv
Model scaling
Model scaling là một kĩ thuật khuếch đại độ lớn của model để có được hiệu năng tốt hơn. Model scaling được phân tích kĩ lần đầu tiên trong EfficientNet với kĩ thuật scale tổng hợp cả 3 chiều của mạng nơ-ron là: chiều sâu, chiều rộng và chiều độ phân giải của ảnh đầu vào.
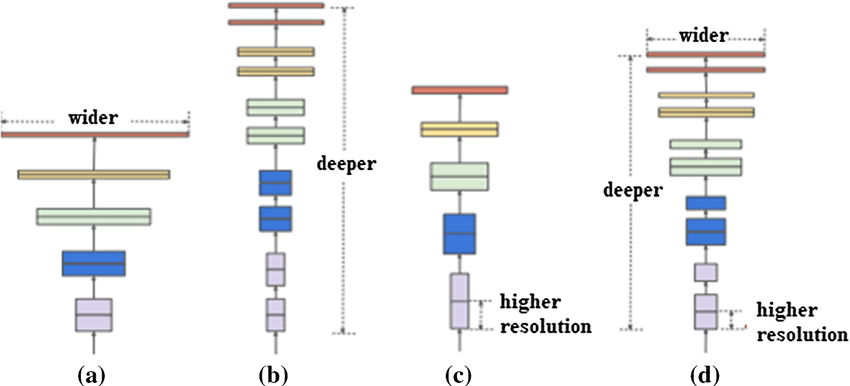
Implicit Knowledge
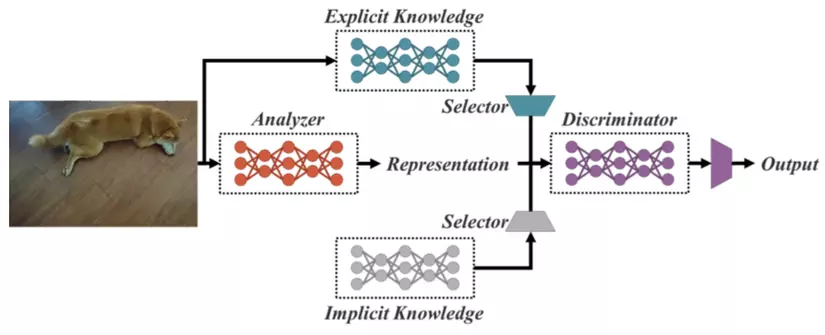
Implicit Knowledge (kiến thức tiềm ẩn) được giới thiệu và áp dụng lần đầu vào Object Detection ở trong YOLOR. Senpai của team mình đã có một bài phân tích về YOLOR tại đây và tại đây mình sẽ tóm tắt lại Implicit Knowledge là gì.
Con người thì có thể hiểu một sự vật, sự việc thông qua việc học trực tiếp nó (explicit knowledge) hoặc cũng có thể tự mình hiểu được nó mà không phải trực tiếp học về nó thông qua vô số các kinh nghiệm từ trước (implicit knowledge). YOLOR muốn đưa implicit knowledge đó vào trong mạng nơ-ron. YOLOR lúc này định nghĩa explicit knowledge là những kiến thức mà model học được thông qua sự tiếp xúc với các input, còn implicit knowledge là một thứ gì đó mà model sẽ tự rút ra được trong quá trình training, độc lập với input.
YOLOR đề xuất ra 3 cách biểu diễn implicit knowledge, tuy nhiên biểu diễn đơn giản nhất, dưới dạng vector, được YOLOR sử dụng và đạt hiệu quả ổn.
Implicit knowledge được kết hợp vào mạng nơ-ron theo 2 cách, cộng và nhân:
# Implicit cộng
class ImplicitA(nn.Module):
def __init__(self, channel, mean=0., std=.02):
super(ImplicitA, self).__init__()
self.channel = channel
self.mean = mean
self.std = std
self.implicit = nn.Parameter(torch.zeros(1, channel, 1, 1))
nn.init.normal_(self.implicit, mean=self.mean, std=self.std)
def forward(self, x):
return self.implicit + x
# Implicit nhân
class ImplicitM(nn.Module):
def __init__(self, channel, mean=0., std=.02):
super(ImplicitM, self).__init__()
self.channel = channel
self.mean = mean
self.std = std
self.implicit = nn.Parameter(torch.ones(1, channel, 1, 1))
nn.init.normal_(self.implicit, mean=self.mean, std=self.std)
def forward(self, x):
return self.implicit * x
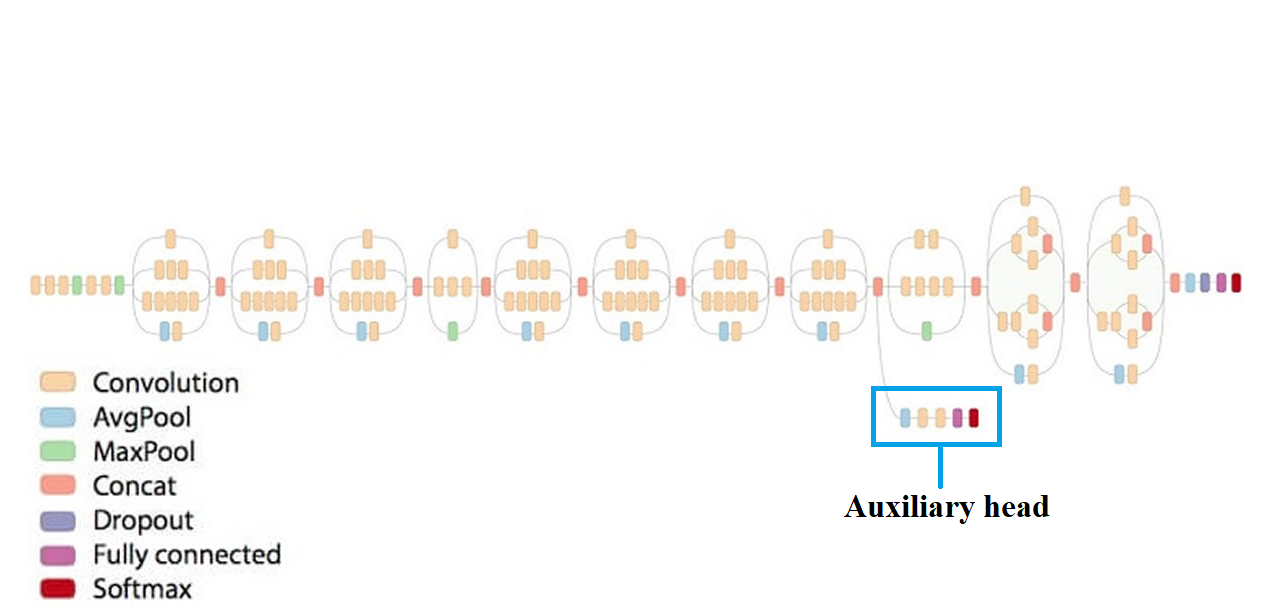
Deep Supervision (Auxiliary head)
Deep supervision là một kĩ thuật được dùng khá nhiều ở bài toán Segmentation, lần đầu tiên được giới thiệu trong Inception Network. Từ các layer khá nông của model, ta tạo thêm ra thêm một head ảo, bắt model phải predict luôn từ những lớp khá nông. Nguyên lý thực sự của deep supervision vẫn chưa được tìm hiểu và phân tích một cách kĩ càng, tuy nhiên có nhiều giả thuyết cho rằng, việc bắt model predict từ sớm như vậy có thể tạo ảnh hưởng lên ngay các lớp nông để học thêm các đặc trưng cần thiết chứ không cần phải tới các lớp sâu trong model nữa, từ đó khiến quá trình học của model trở nên nhanh và dễ dàng hơn.
Mình cũng xin đóng góp thêm giả thuyết của bản thân như sau: Việc predict từ sớm cũng giống như có một FPN, model sử dụng thông tin từ các lớp nông để thực hiện predict, khiến feature maps được model đem đi predict có dạng multi-scale, do đó học multi-scale features một cách dễ dàng hơn. Và hơn nữa, đây cũng có thể coi như là ensemble của 2 model trong cùng một quá trình training.
Trong quá trình inference, chúng ta sẽ bỏ đi auxiliary head và chỉ sử dụng head gốc để đưa ra predict.
Kiến trúc của YOLOv7
- Backbone: ELAN, E-ELAN
- Neck: CSP-SPP và (ELAN, E-ELAN)-PAN
- Head: YOLOR và Auxiliary head
Kết
Phía trên là các kiến thức cơ bản cần nắm được để có thể hiểu trọn vẹn YOLOv7. Ở trong bài phân tích tiếp theo về YOLOv7, mình sẽ nói chi tiết về các thay đổi được áp dụng vào YOLOv7, kiến thức ở bên trên vừa nêu sẽ được áp dụng như nào, và từng phiên bản YOLOv7 khác nhau ở điểm nào. Nếu có gì sai sót, mong các bạn có thể góp ý cho mình.
Phần 2 của chuỗi YOLOv7 đã có ở đây: https://viblo.asia/p/paper-explain-yolov7-su-dung-cac-trainable-bag-of-freebies-dua-yolo-len-mot-tam-cao-moi-phan-2-0gdJz0YEVz5
Phần 3 của chuỗi YOLOv7 đã có ở đây: https://viblo.asia/p/paper-explain-yolov7-su-dung-cac-trainable-bag-of-freebies-dua-yolo-len-mot-tam-cao-moi-phan-3-018J253M4YK
Reference
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors - https://arxiv.org/abs/2207.02696
All rights reserved
