
[Paper Explain] Label-Efficient Semantic Segmentation with Diffusion Models: Tính discriminative của mô hình generative
Bài đăng này đã không được cập nhật trong 3 năm
Lời mở đầu
DIffusion thì đã quá nổi tiếng với những task sinh ảnh từ text rồi. Trong bài này, mình sẽ giới thiệu về một nghiên cứu liên quan đến tính discriminative trong mô hình sinh để có thể ứng dụng của nó vào việc giải quyết các bài toán discriminative. Đó là paper: Label-Efficient Semantic Segmentation with Diffusion Models, được publish tại ICLR2022.
Với các bạn chưa có background về mô hình diffusion hoặc cần ôn lại các bạn có thể tham khảo bài viết khác của mình về chủ đề này tại đây. Sau đây mình xin đi vào các phần chính.
Phân tích representation
Trước khi khi đi vào các thí nghiệm, hãy cùng ôn lại một chút về UNet, kiến trúc được sử dụng trong các mô hình diffusion. Đầu vào của mô hình là một ảnh được thêm nhiễu, mạng UNet được yêu cầu phải dự đoán lượng nhiễu đã được thêm vào ảnh gốc. Mạng UNet có thể được chia làm 2 phần chính là encoder và decoder. Trong phần này chúng ta sẽ xét đến những activations từ các block trong decoder. Kiến trúc của UNet và cách lấy activations để phân tích được minh hoạ ở hình 1.
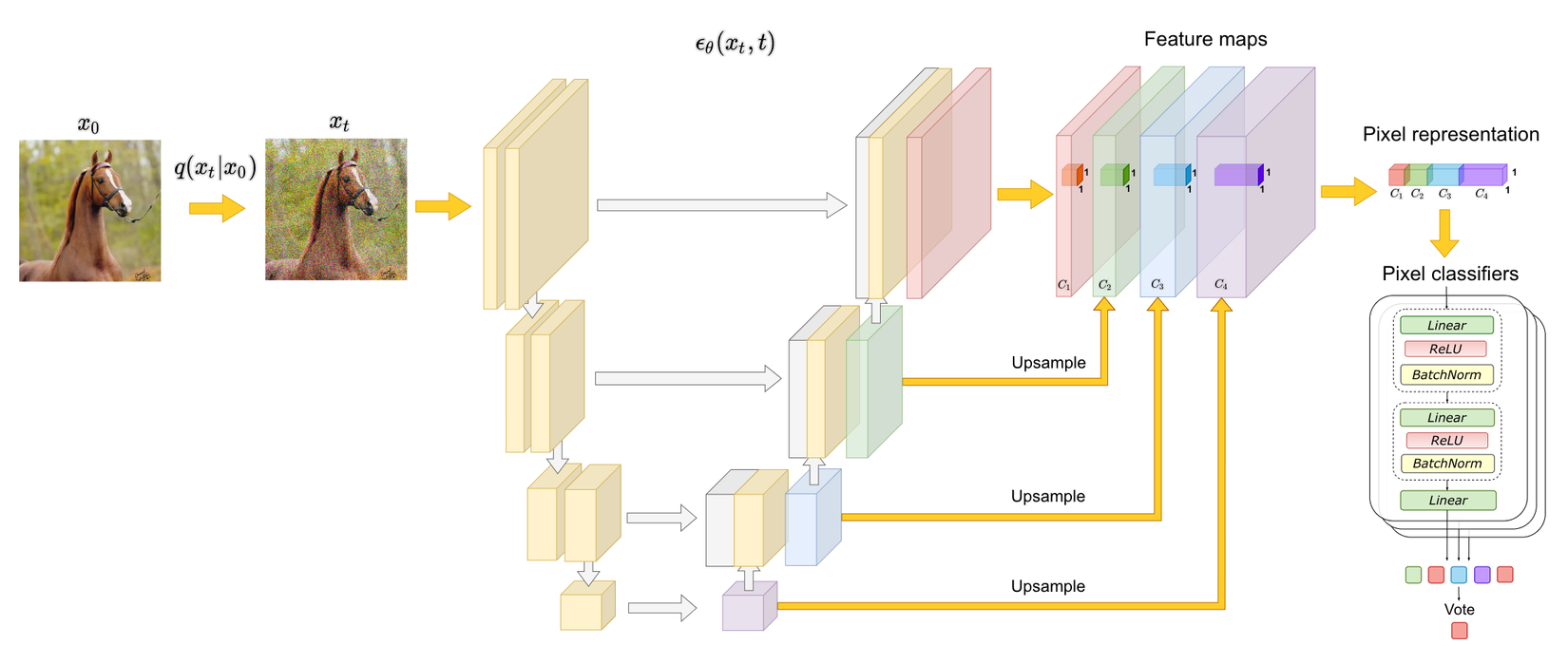
Segmentation dựa trên feature của noise predictor
Trong phần này chúng ta sẽ xây dựng một mạng MLP để thực hiện việc segmentation dựa vào representation sinh ra bởi DDPM. Mục đích của việc này là để tìm hiểu xem những biểu diễn này của DDPM có chứa thông tin semantic hay không. Tổng quan phương pháp thực hiện được thể hiện ở hình 1. Chúng ta sẽ chỉ lấy feature ở decoder vì những feature từ encoder đã được tổng hợp thông qua skip connection. Mạng MLP sẽ được huấn luyện trên 20 ảnh và được đánh giá trên 20 ảnh khác bằng chỉ số mIoU. Kết quả của thử nghiệm này được thể hiện ở hình 2. Các block được đánh số từ sâu đến nông.
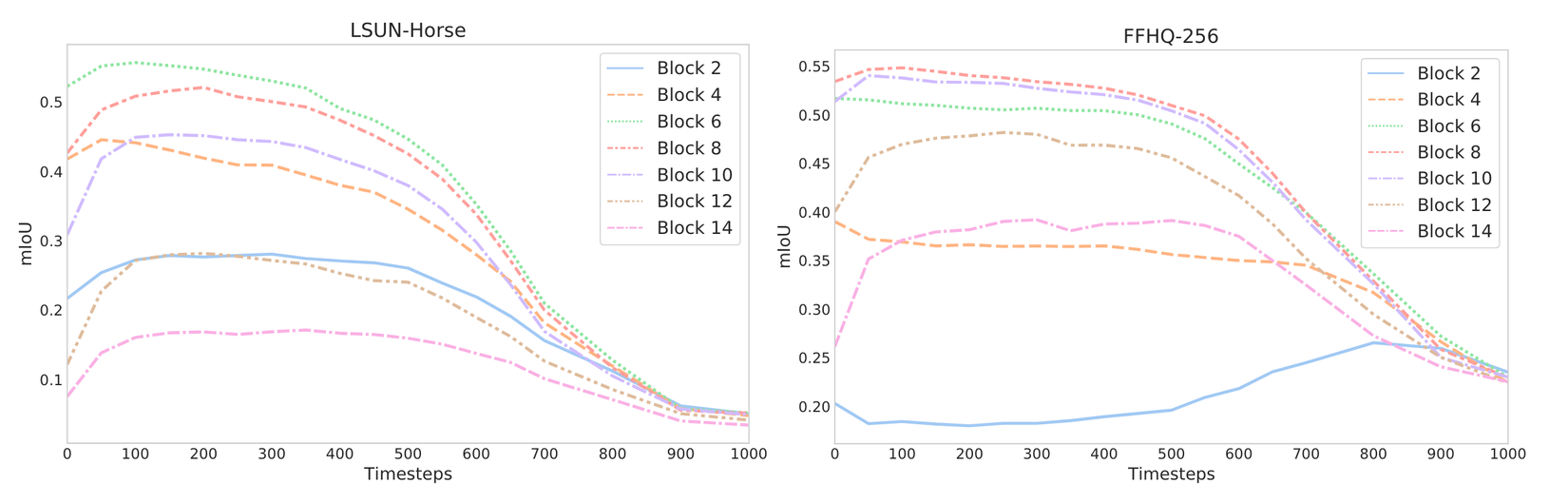
Kết quả ở hình 2 cho thấy rằng tính discriminative của những feature là khác nhau đối với các block và step khác nhau. Cụ thể, những feature ứng với các timestep đầu bắt được những thông tin ngữ cảnh tốt hơn cho task dự đoán label của pixel. Trái lại, những feature ứng với những timestep lớn dường như không hữu ích cho việc dự đoán label. Giữa các block khác nhau, những feature tạo ra bởi các layer ở giữa decoder mang nhiều thông tin hữu ích nhất. Điều này đúng ở tất cả các timestep.
Tác giả cũng xem xét độ chính xác dự đoán các class dựa trên yếu tố kích thích trung bình của các vật thể của các class này trên tập train. Độ chính xác của các vật thể có kích thước lớn tăng sớm hơn ngay ở phần đầu của quá trình reverse. Những block nông hơn thì có nhiều thông tin hơn cho các vật thể nhỏ, trong khi các block sâu hơn thì cho performance tốt hơn với các vật thể lớn. Điều này cũng dễ hiểu nếu nhìn vào vai trò của các block này trong mạng UNet. Trong cả hai trường hợp, những feature có tính discriminative nhất vẫn tương ứng với những block ở giữa decoder. Kết quả của những thí nghiệm này được thể hiện ở hình 3.
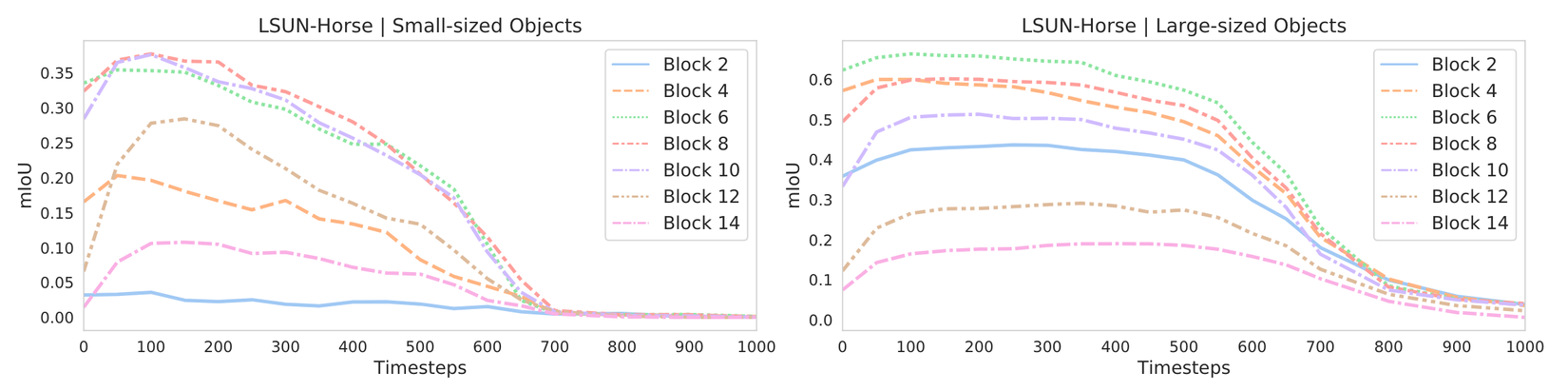
Sử dụng k-means để phân cụm

Kết quả cho phần này cũng giải thích phần nào về kết quả của thí nghiệm trước và cho chúng ta cái nhìn trực quan hơn.
Kết bài
Như vậy chúng ta đã đi qua hai thí nghiệm chính cho thấy tính discriminative có trong mô hình diffusion. Team mình cũng đã tự verify kết quả một số thí nghiệm trên và thấy khá giống với report của paper. Trong paper có trình bày về ứng dụng tính discriminative này của mô hình diffusion để outperform được những phương pháp tương tự cho bài toán few-shot segmentation. Nhưng mình không trình bày ở phần trên do thấy đó cũng không phải là contribution đáng kể và có nhiều cách khác để ứng dụng những finding ở những thí nghiệm trên.
Hy vọng bài viết này có ích với bạn. Đừng quên để lại 1 upvote nếu thấy hay. Cảm ơn các bạn đã đọc bài và hẹn gặp lại ở những bài viết tiếp theo về mô hình diffusion.
Tài liệu
Paper: Label-Efficient Semantic Segmentation with Diffusion Models
All rights reserved
