[YOLO series] p2. Build YOLO from scratch
Bài đăng này đã không được cập nhật trong 5 năm
1. Introduction

Trong bài trước Lý thuyết YOLO và YOLOv2, mình đã viết về lý thuyết, tư tưởng, ưu nhược điểm của YOLO. Nếu bạn nào chưa đọc , hãy bỏ chút thời gian quay lại đọc, phải có nền tảng lý thuyết thì đọc code mới dễ hiểu.
Lý thuyết thôi là chưa đủ. Trong bài này, mình sẽ hướng dẫn bạn code. Mình sẽ tập trung vào phần việc phân tích cấu trúc và code. All in notebook. Tất cả nội dung nằm trọn trong Kaggle notebook của mình. Notebook kèm nội dung văn bản hướng dẫn giống hệt bài viết này, bạn có thể đọc trực tiếp notebook.
Mục tiêu chính của bài là hướng dẫn Build YOLO from scratch, tức sẽ tập trung vào việc hướng dẫn code và build model + loss function. Phần việc chính mình sẽ cố gắng viết dễ hiểu và rút gọn nhất có thể. Vậy nên model có tệ cũng đừng quá bất ngờ, chỉ cần run/train đúng để hiểu được tư tưởng, k cần tốt. Vì thời gian và resource hạn chế, mình sẽ bỏ qua việc test and validate model
Bộ dataset được sử dụng là bộ WIDER (face dataset) được cung cấp sẵn trên Kaggle. Bạn có thể truy cập và download theo link này.
Link:
- My Notebook
- Dataset
- Đọc những bài tương tự tại:
1.2 Cấu trúc code
Cấu trúc code bao gồm các phần chính sau đây:
- Read and preprocess data from .txt file
- Define Dataset and Dataloader
- Define module and backbone of YOLO
- Define Loss function
- Train model
2. Code
Hai năm trước mình từng code bằng Tensorflow 1.x.x . Hồi đó mình mất 4 ngày để code, code xong toát cả mồ hôi hột. Giờ thì mình sẽ code lại bằng Torch, đơn giản và tiện hơn rất nhiều. Mất chưa tới 1 ngày 
Nếu ai chưa biết torch cũng không sao. Về cơ bản, cú pháp của Torch cũng giống numpy, người mới vẫn đọc hiểu được.
2.1 Import, define global Variables ...
Import libs
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
import torch
import torchvision
from glob import glob
from tqdm import tqdm
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader, Dataset
import albumentations as A
from albumentations.pytorch.transforms import ToTensor, ToTensorV2
from random import randint, choice, shuffle, choices
import cv2
from torch import nn
import torch.nn.functional as F
!pip install torch-summary
Define CONST, global variables
DATA_DIR = '../input/wider-data/WIDER'
TRAIN_DIR = '../input/wider-data/WIDER/WIDER_train'
BOX_COLOR = (0, 0, 255)
TEXT_COLOR = (255, 255, 255)
S = 13 #chia ảnh thành grids 13x13 cells
BOX = 5 #box number each cell = number of anchor boxes
CLS = 2 # [face, not_face]
H, W = 416, 416
OUTPUT_THRESH = 0.7
# pre-defined anchor-boxes
ANCHOR_BOXS = [[1.08,1.19],
[3.42,4.41],
[6.63,11.38],
[9.42,5.11],
[16.62,10.52]]
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
torch.autograd.set_detect_anomaly(True)
Define some util functions
#show 1 ảnh
def plot_img(img, size=(7,7)):
plt.figure(figsize=size)
plt.imshow(img[:,:,::-1])
plt.show()
# vẽ bounding box lên ảnh
def visualize_bbox(img, boxes, thickness=2, color=BOX_COLOR, draw_center=True):
img_copy = img.cpu().permute(1,2,0).numpy() if isinstance(img, torch.Tensor) else img.copy()
for box in boxes:
x,y,w,h = int(box[0]), int(box[1]), int(box[2]), int(box[3])
img_copy = cv2.rectangle(
img_copy,
(x,y),(x+w, y+h),
color, thickness)
if draw_center:
center = (x+w//2, y+h//2)
img_copy = cv2.circle(img_copy, center=center, radius=3, color=(0,255,0), thickness=2)
return img_copy
2.2 Read and preprocess data in .txt file
def get_xywh_from_textline(text):
coor = text.split(" ")
result = []
xywh = [int(coor[i]) for i in range(4)] if(len(coor) > 4) else None
return xywh
def read_data(file_path, face_nb_max=10):
'''
Read data in .txt file
Return:
list of image_data,
each element is dict {file_path: , box_nb: , boxes:}
'''
data = []
with open(file_path, 'r') as f:
lines = f.readlines()
for i, cur_line in enumerate(lines):
if '.jpg' in cur_line:
img_data = {
'file_path': cur_line.strip(),
'box_nb': int(lines[i+1]),
'boxes': [],
}
face_nb = img_data['box_nb']
if(face_nb <= face_nb_max):
for j in range(face_nb):
rect = get_xywh_from_textline(lines[i+2+j].replace("\n", ""))
if rect is not None:
img_data['boxes'].append(rect)
if len(img_data['boxes']) > 0:
data.append(img_data)
return data
train_data = read_data('../input/wider-data/WIDER/wider_face_train_bbx_gt.txt')
img_data = choice(train_data)
img = cv2.imread(f"{TRAIN_DIR}/{img_data['file_path']}").astype(np.float32)/255.0
vis_img = visualize_bbox(img, img_data['boxes'], thickness=3, color=BOX_COLOR)
plot_img(vis_img)
Demo image:

2.3 Define class Dataset
Dataset trong Torch hay chính là generator được dùng để sinh data trong quá trình train Torch đã cung cấp sẵn 2 class là Dataset và Dataloader, việc xây dựng generator trở lên đơn giản
Mình định nghĩa class FaceDataset, hàm getitem() sẽ trả về cặp (img, target_tensor). Trong đó target_tensor chứa thông tin về bboxes, label, objectness_prob, là 1 matrix có Shape = (S,S,B,(4+1+CLS)).
class FaceDataset(Dataset):
def __init__(self, data, img_dir=TRAIN_DIR, transforms=None):
self.data = data
self.img_dir = img_dir
self.transforms = transforms
def __len__(self):
return len(self.data)
def __getitem__(self, id):
img_data = self.data[id]
img_fn = f"{self.img_dir}/{img_data['file_path']}"
boxes = img_data["boxes"]
box_nb = img_data["box_nb"]
labels = torch.zeros((box_nb, 2), dtype=torch.int64)
labels[:, 0] = 1
img = cv2.imread(img_fn).astype(np.float32)/255.0
try:
if self.transforms:
sample = self.transforms(**{
"image":img,
"bboxes": boxes,
"labels": labels,
})
img = sample['image']
boxes = torch.stack(tuple(map(torch.tensor, zip(*sample['bboxes'])))).permute(1, 0)
except:
return self.__getitem__(randint(0, len(self.data)-1))
target_tensor = self.boxes_to_tensor(boxes.type(torch.float32), labels)
return img, target_tensor
def boxes_to_tensor(self, boxes, labels):
"""
Convert list of boxes (and labels) to tensor format
Output:
boxes_tensor: shape = (Batchsize, S, S, Box_nb, (4+1+CLS))
"""
boxes_tensor = torch.zeros((S, S, BOX, 5+CLS))
cell_w, cell_h = W/S, H/S
for i, box in enumerate(boxes):
x,y,w,h = box
# normalize xywh with cell_size
x,y,w,h = x/cell_w, y/cell_h, w/cell_w, h/cell_h
center_x, center_y = x+w/2, y+h/2
grid_x = int(np.floor(center_x))
grid_y = int(np.floor(center_y))
if grid_x < S and grid_y < S:
boxes_tensor[grid_y, grid_x, :, 0:4] = torch.tensor(BOX * [[center_x-grid_x,center_y-grid_y,w,h]])
boxes_tensor[grid_y, grid_x, :, 4] = torch.tensor(BOX * [1.])
boxes_tensor[grid_y, grid_x, :, 5:] = torch.tensor(BOX*[labels[i].numpy()])
return boxes_tensor
def collate_fn(batch):
return tuple(zip(*batch))
def target_tensor_to_boxes(boxes_tensor):
'''
Recover target tensor (tensor output of dataset) to bboxes
Input:
boxes_tensor: bboxes in tensor format - output of dataset.__getitem__
Output:
boxes: list of box, each box is [x,y,w,h]
'''
cell_w, cell_h = W/S, H/S
boxes = []
for i in range(S):
for j in range(S):
for b in range(BOX):
data = boxes_tensor[i,j,b]
x_center,y_center, w, h, obj_prob, cls_prob = data[0], data[1], data[2], data[3], data[4], data[5:]
prob = obj_prob*max(cls_prob)
if prob > OUTPUT_THRESH:
x, y = x_center+j-w/2, y_center+i-h/2
x,y,w,h = x*cell_w, y*cell_h, w*cell_w, h*cell_h
box = [x,y,w,h]
boxes.append(box)
return boxes
Khởi tạo transform, dataset, dataloader
rain_transforms = A.Compose([
A.Resize(height=416, width=416),
A.RandomSizedCrop(min_max_height=(350, 416), height=416, width=416, p=0.4),
A.HorizontalFlip(p=0.5),
ToTensorV2(p=1.0)
],
bbox_params={
"format":"coco",
'label_fields': ['labels']
})
train_dataset = FaceDataset(train_data, transforms=train_transforms)
train_loader = DataLoader(
train_dataset,
batch_size=8,
shuffle=True,
num_workers=2,
collate_fn=collate_fn, drop_last=True)
2.4 Define YOLOv2 model
Để đơn giản và dễ hiểu, mình không dùng Darknet-backbone mà mình sẽ xây dụng TinyYOLO - phiên bản nhỏ hơn của YOLO với kiến trúc bao gồm các Convolution layer xếp chồng lên nhau. Việc xây dựng backbone cho YOLO không hề khó. Thứ khó code nhất là Loss function
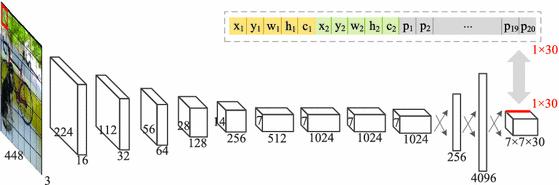
from torchsummary import summary
def Conv(n_input, n_output, k_size=4, stride=2, padding=0, bn=False):
return nn.Sequential(
nn.Conv2d(
n_input, n_output,
kernel_size=k_size,
stride=stride,
padding=padding, bias=False),
nn.BatchNorm2d(n_output),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(p=0.2, inplace=False))
# This is tiny-yolo
class YOLO(torch.nn.Module):
def __init__(self, nc=32, S=13, BOX=5, CLS=2):
super(YOLO, self).__init__()
self.nc = nc
self.S = S
self.BOX = BOX
self.CLS = CLS
self.net = nn.Sequential(
nn.Conv2d(
3, nc,
kernel_size=4,
stride=2,
padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
Conv(nc, nc, 3,2,1),
Conv(nc, nc*2, 3,2,1),
Conv(nc*2, nc*4, 3,2,1),
Conv(nc*4, nc*8, 3,2,1),
Conv(nc*8, nc*16, 3,1,1),
Conv(nc*16, nc*8, 3,1,1),
Conv(nc*8, BOX*(4+1+CLS), 3,1,1),
)
def forward(self, input):
output_tensor = self.net(input)
output_tensor = output_tensor.permute(0, 2,3,1)
W_grid, H_grid = self.S, self.S
output_tensor = output_tensor.view(-1, H_grid, W_grid, self.BOX, 4+1+self.CLS)
return output_tensor
model = YOLO(S=S, BOX=BOX, CLS=CLS)
test_img = torch.rand(1,3,416,416)
output = model(test_img)
2.5 Loss function
Trước khi đọc code, hay nhìn lại các công thức này một chút. Thứ YOLO trả về không phải (x,y,w,h) trực tiếp của Object. Ta cần vài bước biến đổi theo công thức
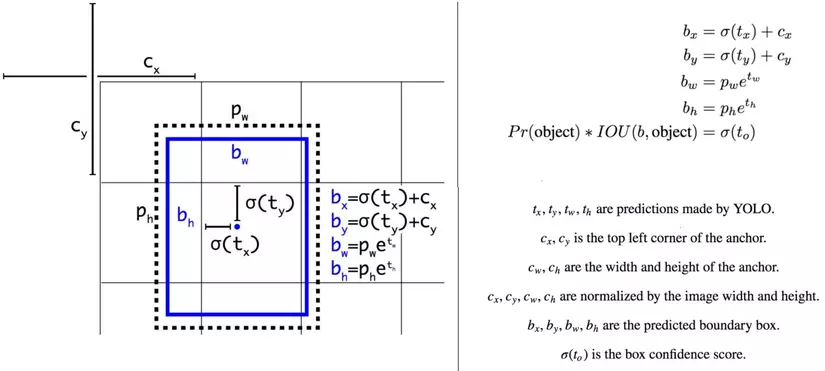
Như mình đã nói, thứ khó code nhất của YOLO là loss function. Tư tưởng thì đơn giản nhưng việc implement thì khá phức tạp. Loss YOLO được kết hợp từ 5 loss thành phần. Trong quá trình tính loss, bạn phải xác định được IOU của từng predicted bbox với groundtruth bbox nằm cùng trong một Cell. Nếu vẫn chưa hiểu rõ bạn cần làm những gì, hãy đọc code
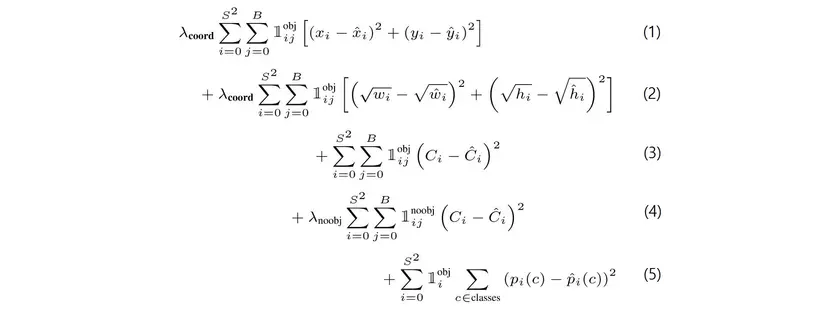
Các hàm phụ trợ cho loss function
def post_process_output(output):
"""Convert output of model to pred_xywh"""
# xy
xy = torch.sigmoid(output[:,:,:,:,:2]+1e-6)
# wh
wh = output[:,:,:,:,2:4]
anchors_wh = torch.Tensor(ANCHOR_BOXS).view(1,1,1,BOX,2).to(device)
wh = torch.exp(wh)*anchors_wh
# objectness confidence
obj_prob = torch.sigmoid(output[:,:,:,:,4:5]+1e-6)
# class distribution
cls_dist = torch.softmax(output[:,:,:,:,5:], dim=-1)
return xy, wh, obj_prob, cls_dist
def post_process_target(target_tensor):
"""
Tách target tensor thành từng thành phần riêng biệt: xy, wh, object_probility, class_distribution
"""
xy = target_tensor[:,:,:,:,:2]
wh = target_tensor[:,:,:,:,2:4]
obj_prob = target_tensor[:,:,:,:,4:5]
cls_dist = target_tensor[:,:,:,:,5:]
return xy, wh, obj_prob, cls_dist
def square_error(output, target):
return (output-target)**2
Loss function - thứ khó code nhất của Yolo. Dù đã từng code bằng Tensorflow cách đây 2 năm nhưng giờ code lại mình vẫn mất 8 tiếng để code nó cho đúng
def custom_loss(output_tensor, target_tensor):
"""
Luồng xử lí:
1. Tính diện tích các pred_bbox
2. Tính diện tích các true_bbox
3. Tính iou giữa từng pred_bbox với true_bbox tương ứng (nằm trong cùng 1 cell)
4. Trong mỗi cell, xác định best_box - box có iou với true_bbox đạt giá trị max so với 4 pred_bbox còn lại
5. Tính các loss thành phần theo công thức trong ảnh
6. Tính Total_loss
"""
cell_size = (W/S, H/S)
NOOB_W, CONF_W, XY_W, PROB_W, WH_W = 2.0, 10.0, 0.5, 1.0, 0.1
pred_xy, pred_wh, pred_obj_prob, pred_cls_dist = post_process_output(output_tensor)
true_xy, true_wh, true_obj_prob, true_cls_dist = post_process_target(target_tensor)
# tính diện tích các pred_bbox
pred_ul = pred_xy - 0.5*pred_wh
pred_br = pred_xy + 0.5*pred_wh
pred_area = pred_wh[:,:,:,:,0]*pred_wh[:,:,:,:,1]
# Tính diện tích các true_bbox
true_ul = true_xy - 0.5*true_wh
true_br = true_xy + 0.5*true_wh
true_area = true_wh[:,:,:,:,0]*true_wh[:,:,:,:,1]
# Tính iou giữa từng pred_bbox với true_bbox tương ứng (nằm trong cùng 1 cell)
intersect_ul = torch.max(pred_ul, true_ul)
intersect_br = torch.min(pred_br, true_br)
intersect_wh = intersect_br - intersect_ul
intersect_area = intersect_wh[:,:,:,:,0]*intersect_wh[:,:,:,:,1]
# Trong mỗi cell, xác định best_box - box có iou với true_bbox đạt giá trị max so với 4 pred_bbox còn lại
iou = intersect_area/(pred_area + true_area - intersect_area)
max_iou = torch.max(iou, dim=3, keepdim=True)[0]
best_box_index = torch.unsqueeze(torch.eq(iou, max_iou).float(), dim=-1)
true_box_conf = best_box_index*true_obj_prob
# Tính các loss thành phần theo công thức trong ảnh
xy_loss = (square_error(pred_xy, true_xy)*true_box_conf*XY_W).sum()
wh_loss = (square_error(pred_wh, true_wh)*true_box_conf*WH_W).sum()
obj_loss = (square_error(pred_obj_prob, true_obj_prob)*(CONF_W*true_box_conf + NOOB_W*(1-true_box_conf))).sum()
cls_loss = (square_error(pred_cls_dist, true_cls_dist)*true_box_conf*PROB_W).sum()
# Loss kết hợp
total_loss = xy_loss + wh_loss + obj_loss + cls_loss
return total_loss
2.6 Train model
Trước khi train model, mình sẽ định nghĩa hàm nonmax_suppression, sử dụng để loại đi các bbox dư thừa của cùng 1 vật thể

from tqdm import tqdm
def output_tensor_to_boxes(boxes_tensor):
cell_w, cell_h = W/S, H/S
boxes = []
probs = []
for i in range(S):
for j in range(S):
for b in range(BOX):
anchor_wh = torch.tensor(ANCHOR_BOXS[b])
data = boxes_tensor[i,j,b]
xy = torch.sigmoid(data[:2])
wh = torch.exp(data[2:4])*anchor_wh
obj_prob = torch.sigmoid(data[4:5])
cls_prob = torch.softmax(data[5:], dim=-1)
combine_prob = obj_prob*max(cls_prob)
if combine_prob > OUTPUT_THRESH:
x_center, y_center, w, h = xy[0], xy[1], wh[0], wh[1]
x, y = x_center+j-w/2, y_center+i-h/2
x,y,w,h = x*cell_w, y*cell_h, w*cell_w, h*cell_h
box = [x,y,w,h, combine_prob]
boxes.append(box)
return boxes
def overlap(interval_1, interval_2):
x1, x2 = interval_1
x3, x4 = interval_2
if x3 < x1:
if x4 < x1:
return 0
else:
return min(x2,x4) - x1
else:
if x2 < x3:
return 0
else:
return min(x2,x4) - x3
def compute_iou(box1, box2):
"""Compute IOU between box1 and box2"""
x1,y1,w1,h1 = box1[0], box1[1], box1[2], box1[3]
x2,y2,w2,h2 = box2[0], box2[1], box2[2], box2[3]
## if box2 is inside box1
if (x1 < x2) and (y1<y2) and (w1>w2) and (h1>h2):
return 1
area1, area2 = w1*h1, w2*h2
intersect_w = overlap((x1,x1+w1), (x2,x2+w2))
intersect_h = overlap((y1,y1+h1), (y2,y2+w2))
intersect_area = intersect_w*intersect_h
iou = intersect_area/(area1 + area2 - intersect_area)
return iou
def nonmax_suppression(boxes, IOU_THRESH = 0.4):
"""remove ovelap bboxes"""
boxes = sorted(boxes, key=lambda x: x[4], reverse=True)
for i, current_box in enumerate(boxes):
if current_box[4] <= 0:
continue
for j in range(i+1, len(boxes)):
iou = compute_iou(current_box, boxes[j])
if iou > IOU_THRESH:
boxes[j][4] = 0
boxes = [box for box in boxes if box[4] > 0]
return boxes
Đến giai đoạn cuối cùng: train model. Thực ra vì mình không có thời gian và resource nên mình sẽ test ngay trên dữ liệu train (chỉ với vài ảnh).
Nghe test với dữ liệu train thì hơi buồn cười nhỉ, nhưng đó chính là cách mình dùng để kiểm tra model có hoạt động đúng hay không. Nếu feed 1 lượng nhỏ data vào train mà model không cho output giống với target, điều đó có nghĩa model của bạn đang sai ở đâu đó, trong loss function, model backbone, post-preprocess ... Ngược lại, nếu điều kiện này thoả mãn đồng nghĩa với việc code bạn đã đúng, model đúng (thường là thế). Lúc này, việc của bạn chỉ là tune lại model sao cho ngon hơn mà thôi
model = YOLO(S=S, BOX=BOX, CLS=CLS)
model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
epochs = 10
iters = 1
imgs, targets = next(iter(train_loader))
demo_img = imgs[0].permute(1,2,0).cpu().numpy()
boxes = target_tensor_to_boxes(targets[0])
plot_img(visualize_bbox(demo_img.copy(), boxes=boxes), size=(5,5))
for epoch in tqdm(range(300)):
# for imgs, targets in tqdm(train_loader):
# mình sẽ train và test trên 1 lượng dữ liệu nhỏ
# để kiểm tra model và code có hoạt động đúng hay không
model.zero_grad()
tensor_imgs, tensor_targets = torch.stack(imgs), torch.stack(targets)
output = model(tensor_imgs.to(device))
loss = custom_loss(output_tensor=output, target_tensor=tensor_targets.to(device))
loss_value = loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
iters += 1
if iters%200 == 0:
## Test nay trên tập train, nếu kết quả thỏa mãn đồng nghĩa với code của bạn đã chạy đúng
boxes = output_tensor_to_boxes(output[0].detach().cpu())
boxes = nonmax_suppression(boxes)
img = imgs[0].permute(1,2,0).cpu().numpy()
img = visualize_bbox(img.copy(), boxes=boxes)
plot_img(img, size=(4,4))
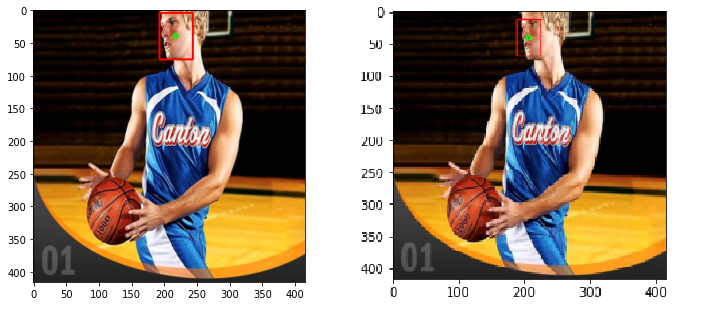
Và đây là kết quả test trên dữ liệu train chỉ sau 15s. Bên trái là ảnh target, phải là ảnh predict. Đó, với mẹo này, sau 15s mình đã kiểm chứng được rằng code, model hoạt động chuẩn. Việc của bạn bây giờ là chỉnh lại backbone, add layer, augmentation data và ngồi mòn đ*t train tiếp cho ngon hơn. Do mình đang ngồi ở quán cafe, chủ quán sắp đuổi rồi nên phải nhanh chóng kết thúc, không thể ngồi đợi train 3 tiếng để show model xịn hơn được . Cảm ơn bạn đã đọc bài viết. Đừng quên upvote (nếu bạn đang đọc bài này trên Viblo)
All rights reserved
