
SAM: Giải thuật tối ưu đang dần được ứng dụng rộng rãi
Bài đăng này đã không được cập nhật trong 3 năm
Cập nhật
[+ chạy SAM trên Pytorch Lightning]
Lời nói đầu
Trong quá trình training, chúng ta thường chỉ quan tâm đến giá trị training loss mà không quan tâm đến độ dốc (sharpness) của hình dạng đồ thị(landscape) loss quanh điểm đó. Mối quan hệ giữa hình dạng của đồ thị loss và tính tổng quát hoá (generalization) của mô hình đã được nghiên cứu trong các nghiên cứu trước. Một nghiên cứu thực nghiệm với hơn 40 phương pháp đo phức tạp chỉ ra rằng: phép đo sharpness-based có mối tương quan cao nhất (so với những phép đo còn lại) với tính tổng quát hoá. Từ đó, nhiều nghiên cứu tối ưu mô hình có tính đến dộ dốc của loss được công bố. Tuy nhiên, những phương pháp này hoặc chưa hiệu quả về mặt tính toán (efficient) hoặc chưa cải thiện nhiều về độ chính xác hoặc cả hai. SAM có lẽ là phương pháp sharpness-based đầu tiên đề xuất được cách áp dụng đem lại hiệu quả rõ rệt với chi phí tính toán tăng thêm chấp nhận được (so với độ chính xác tăng thêm thì mình sẵn sàng đánh đổi). Kể từ khi SAM ra mắt năm 2020, nhiều nghiên cứu cải thiện SAM về cả mặt performance và effciency đã được công bố.

Tóm tắt một số đặc điểm của SAM:
- SAM là một objective function.
- SAM hướng tới tìm trọng số vừa thoả mãn 2 điều kiện
- có loss trên tập train nhỏ (như objective thông thường)
- loss của tất cả các trọng số hàng xóm gần đó đều phải nhỏ (, với là giá trị trọng số của mô hình và ).
- Ưu điểm của SAM:
- Cải thiện tính tổng quát hoá của mô hình từ đó cho kết quả tốt hơn trên tập test.
- Robust với label noise
- Tái hiện kết quả training tốt hơn (reproducible)
- Attention map có tính interpretable cao
- Dễ implement, và chi phí tính toán hiệu quả (so với những phương pháp sharpness-based khác)
- Nhược điểm:
- Thời gian training lâu gấp đôi so với huấn luyện không dùng SAM
Cơ sở của SAM
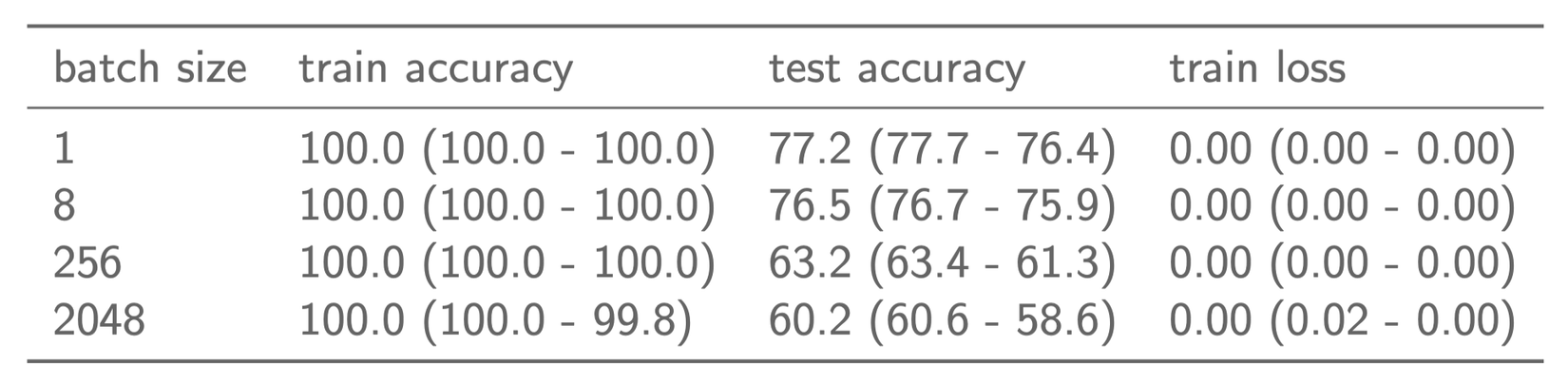
Có một thực tế là không phải tất cả các minima có giá trị loss trên tập train bằng nhau đều lại kết quả trên tập test tương đương nhau. Bảng 1 cho thấy kết quả huẩn luyện mô hình CNN trên tập CIFAR10 với các batch size khác nhau. Trong cả 4 trường hợp train loss đều xấp xỉ bằng 0 và train accuracy đều là 100%. Tuy nhiên, test accuracy ở các trường hợp lại có sự khác nhau rõ rệt. Như vậy, chỉ dựa vào loss để đánh giá một mô hình được huấn luyện tốt hay chưa là chưa đủ. Một mô hình được cho kết quả rất tốt trên tập train có thể cho kết quả rất tệ trên tập test. Trong trường hợp đó, mô hình có tính tổng quát hoá không tốt.
Sự kết nối giữa hình dạng của đồ thị loss và tính tổng quát hoá của mô hình đã được nghiên cứu rộng rãi cả về mặt lý thuyết và thực nghiệm. Cụ thể, những minima có hình dạng loss phẳng hơn (flatness) sẽ những tổng quát hoá hơn minima có độ dốc lớn (sharpness). Như ở hình 1, ta có thể dự đoán rằng minima ở hình bên phải sẽ có tính tổng quát hoá tốt hơn so với mô hình ở bên trái. Tận dụng trên sự liên kết giữa hình dạng đồ thị loss và tính tổng quát hoá của mô hình, SAM cải thiện tính tổng quát hoá của mô hình bằng cách tối ưu đồng thời giá trị loss và độ dốc của loss.
Giải thuật SAM
Trong phần này mình sẽ trình bày giải thuật tối ưu SAM.
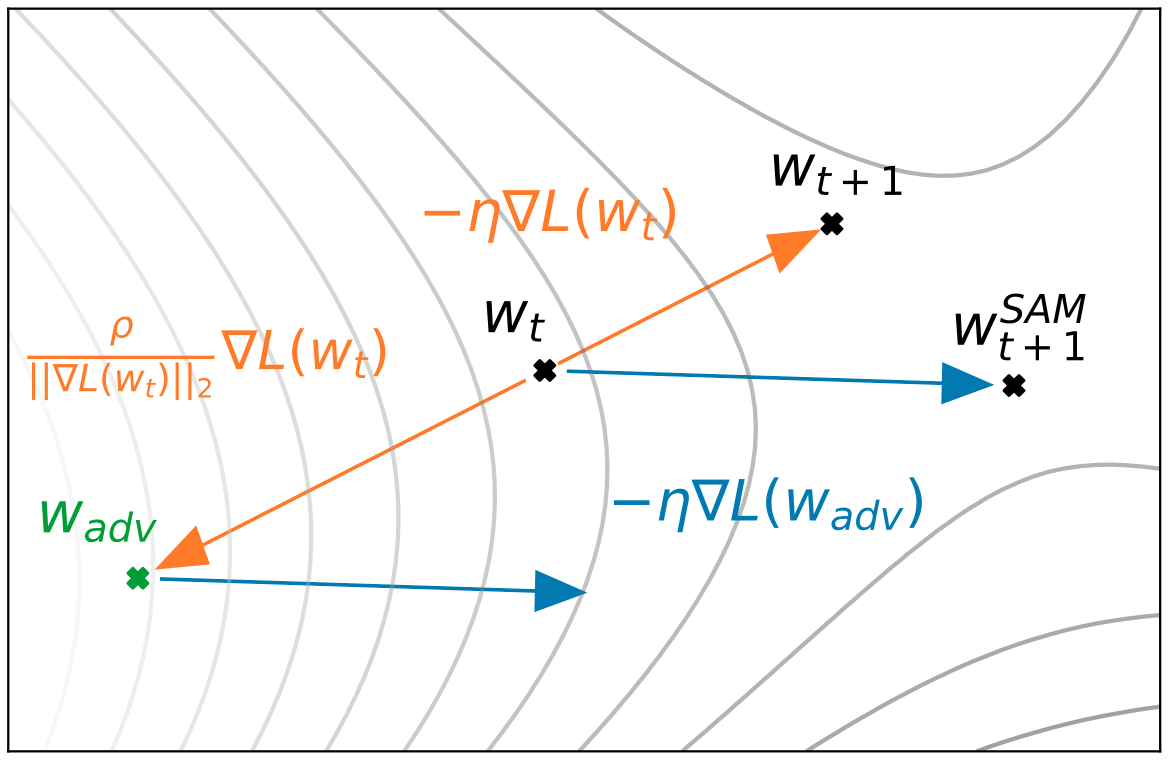
Hình 2 mình hoạ giải thuật gradient descent thông thường (từ sang ) và SAM (từ sang . Giải thuật gradient descent thông thường được sẽ update trọng số theo ngược chiều gradient bằng cách trừ tích của gradient với giá trị learning rate . Giải thuật SAM trước tiên tính (adversarial) bằng cách cộng với (là gradient được scale norm theo ). Mục đích tính là vì SAM kỳ vọng giá trị loss tại giá trị này sẽ có giá trị gần với giá trị loss lớn nhất xung quanh . Sau đó, ta tính gradient tại sau đó apply gradient này tại . Với các bước thực hiện như vậy, SAM hướng tới tìm vừa có loss tại đó nhỏ và loss tại những giá trị xung quanh cũng nhỏ.
Một câu hỏi mà một số bạn hỏi là tại sao SAM update gradient tại mà không phải tại . Để trả lời, ta hãy nhìn vào công thức đạo hàm của hàm loss SAM được ghi trong paper:

Gradient của hàm loss SAM tại W được tính xấp xỉ thông qua gradient của hàm loss thông thường tại (được estimate bằng ). Vậy nên gradient được apply vào chứ không phải
SAM Pytorch
Tác giả của paper implement SAM trên Jax. Mọi người cũng có thể sử dụng SAM (và cả ASAM, một phiên bản cải tiến về độ hiệu quả của SAM) được implement trên Pytorch (không official) ở link sau: https://github.com/davda54/sam. Trong phần README của repo đã hướng dẫn chi tiết cách sử dụng SAM vào trong project hiện tại của bạn. Dễ thấy, thời gian training với SAM sẽ lâu hơn gấp đôi so với baseline do phải forward và backward hai lần. Đây cũng chính là nhược điểm lớn nhất của SAM.
SAM cũng có thể sử dụng được trong pytorch_lightning, trong README có hướng dẫn riêng về phần này. Tuy nhiên, các bạn cũng cần đặt self.automatic_optimization = Falsevà sửa configure_optimizers theo ví dụ minh họa sau. Trong định nghĩa mô hình, chúng ta cần tắt tự động tối ưu:
class SegmentationModel(pl.LightningModule):
def __init__(self, *args, **kwargs):
super().__init__()
# other configs
self.automatic_optimization = False
Đặt optimizer thành SAM:
def configure_optimizers(self):
base_optimizer = torch.optim.Adam
optimizer = SAM(self.parameters(), base_optimizer, lr=0.0001)
return optimizer
Trong training_step:
def training_step(self, batch, batch_idx):
optimizer = self.optimizers()
# first forward-backward pass
loss_1 = self.compute_loss(batch)
self.manual_backward(loss_1)
optimizer.first_step(zero_grad=True)
# second forward-backward pass
loss_2 = self.compute_loss(batch)
self.manual_backward(loss_2)
optimizer.second_step(zero_grad=True)
return loss_1
Kết quả
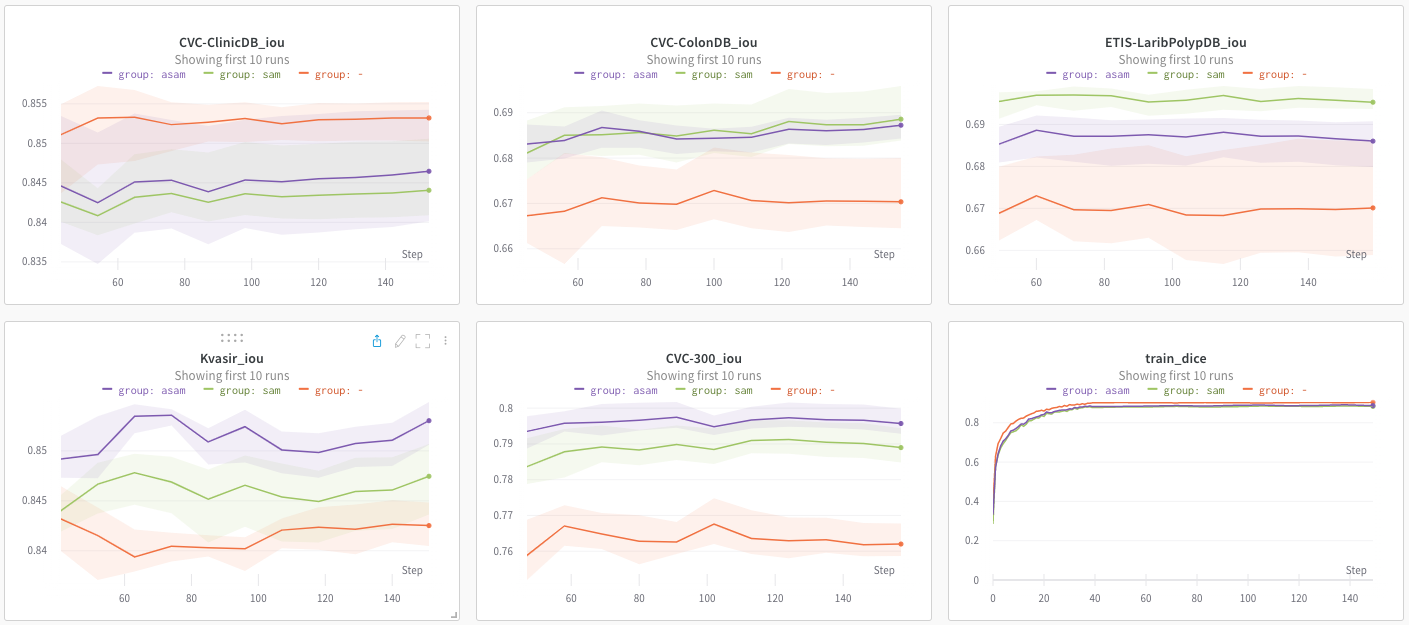
Để xác thực tính hiệu quả của giải thuật SAM. Mình đã áp dụng SAM và ASAM vào bài toán polyp segmentation. Hình 3 thể hiện kết quả đánh giá mô hình huấn luyện trên cả tập train và 5 tập test. Cả mô hình huấn luyện với SAM và ASAM đều cho độ chính xác thấp hơn trên tập train so với baseline chỉ dùng SGD. Tuy nhiên, cả hai mô hình này đều tất hơn baseline trên 4/5 tập. Cho thấy hiệu quả vượt trội của SAM so với baseline. Một điều nữa là mỗi thí nghiệm đều được thực hiện 5 lần, và mô hình train với SAM và ASAM có variance thấp hơn hẳn so với baseline. Đều này giống với tính chất mà tác giả nêu ra là tính reproducibility của mô hình train với SAM sẽ được cải thiện.
Các nghiên cứu sau SAM
Kể từ sau khi SAM ra mắt năm 2020. Nhiều nghiên cứu theo hướng sharpness-based đã xuất hiện với mục cải thiện về cả độ chính xác và nhược điểm về thời gian training. Một số trong những nghiên cứu đó có thể kể đến:
- ASAM: một phiên bản adaptive của SAM
- ESAM: phiên bản hiệu quả về mặt tính toán hơn của SAM
- LookSAM: SAM nhanh hơn cho huấn luyện mô hình Vision Transformer
- SAF: một phiên bản cải thiện về thời gian training của SAM. Nó được cho là gần như không lâu hơn so với việc huấn luyện thông thường (không dùng SAM).
Kết luận
SAM có lẽ là một trong số ít những paper gần đây mình biết mang liệu hiệu quả rõ rệt và có thể được áp dụng rộng rãi trong nhiều bài toán. Trong bài viết này mình đã trình bày về cách hoạt động cũng như cách áp dụng và kết quả của SAM. Một số phần quan trọng không được nhắc đến trong bài này lý thuyết, chứng minh và biến đổi các bạn có thể xem thêm trong paper. Team mình đã áp dụng SAM trong một số dự án và đều cải thiện kết quả đáng kể.
Hy vọng việc áp dụng SAM cũng sẽ đem lại kết quả tương tự với các bạn. Mình rất mong được biết kết quả của việc áp dụng SAM vào trong bài toán của các bạn. Cảm ơn các bạn đã đọc bài, nếu thấy hữu ích hãy cho mình 1 upvote nhé.
References:
https://arxiv.org/abs/2010.01412 https://arxiv.org/abs/2106.01548 https://www.youtube.com/watch?v=QBiLph-r5Hw&t=2808s https://github.com/davda54/sam
All rights reserved
