
[Paper Explain] YOLOR: Sự khởi đầu cho một xu hướng mới?
Bài đăng này đã không được cập nhật trong 4 năm

YOLO có lẽ là một trong những họ giải thuật được phát triển nhiều phiên bản nhất trong lĩnh vực trí tuệ nhân tạo. Chúng ta đã có YOLOv1 đến YOLOv5 và mới nhất hiện nay là hai phiên bản YOLOR và YOLOX. Mỗi lần ra một phiên bản YOLO mới, nhiều kỹ thuật SOTA được tích hợp trong đó và thực sự mình cảm thấy học được rất nhiều từ những bài báo này. YOLOR ra mắt năm 2021, trong phiên bản này, YOLOR áp dụng học sâu tiềm ẩn để cải thiện độ chính xác và có một số thay đổi về mặt cấu trúc mô hình để cải thiện tốc độ. Phương pháp tận dụng kiến thức tiềm ẩn trong YOLOR, theo mình đánh giá, là một cách tiềm năng để cải thiện mô hình và sẽ mở ra nhiều nghiên cứu mới liên quan đến phương pháp này. Phương pháp này không chỉ áp dụng cho bài toán phát hiện vật thể mà còn có thể áp dụng cho nhiều bài toán học sâu khác. Do đó, YOLOR rất đáng để tìm hiểu. Trong bài này, mình sẽ trình bày một cách đơn giản và dễ hiểu nhất có thể về YOLOR.
Một số thuật ngữ tạm dịch
explicit knowledge: kiến thức tường minh
implicit knowledge: kiến thức tiềm ẩn
implicit deep learning: học sâu tiềm ẩn
explicit representation: biểu diễn tường minh
implicit representation: biểu diễn tiềm ẩn
Điểm mới trong mô hình YOLOR
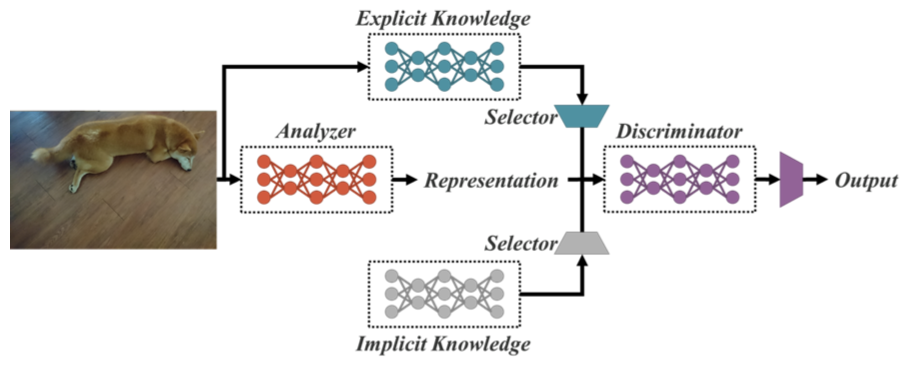
Ý tưởng chính của bài báo là sử dụng những kiến thức tiềm ẩn để cải thiện độ chính xác của mô hình. Đây là một ý tưởng mình thấy rất đột phá. Chúng ta sẽ thấy ở phần sau phương pháp này tăng rất ít các tính toán cần thiết nhưng hiệu quả mang lại rất đáng kể.
Định nghĩa về kiến thức tiềm ẩn ở trong bài báo này khác với định nghĩa chung của mạng nơ ron. Trong mạng nơ ron, những đặc trưng thu được từ những lớp nông (shallow layer) được gọi là kiến thức tường minh, những đặc trưng thu được từ những lớp sâu (deep layer) được gọi là kiến thức tiềm ẩn. Trong bài báo này, kiến thức tường minh được định nghĩa là những hiểu biết được trích xuất từ ảnh đầu vào; kiến thức tiềm ẩn là những hiểu biết không được trính xuất từ ảnh đầu vào.
Để dễ hình dung chúng ta hãy cùng xem hình 1. Chúng ta có thể thấy kiến thức tường minh được tính toán từ ảnh đầu vào trong quá trình forward. Trong khi đó, kiến thức tiềm ẩn không phụ thuộc vào ảnh đầu vào trong quá trình forward mà chúng là những đặc trưng cố định đóng vai trò giống như các tham số trong mô hình.
Kiến thức tiềm ẩn được sử dụng như thế nào
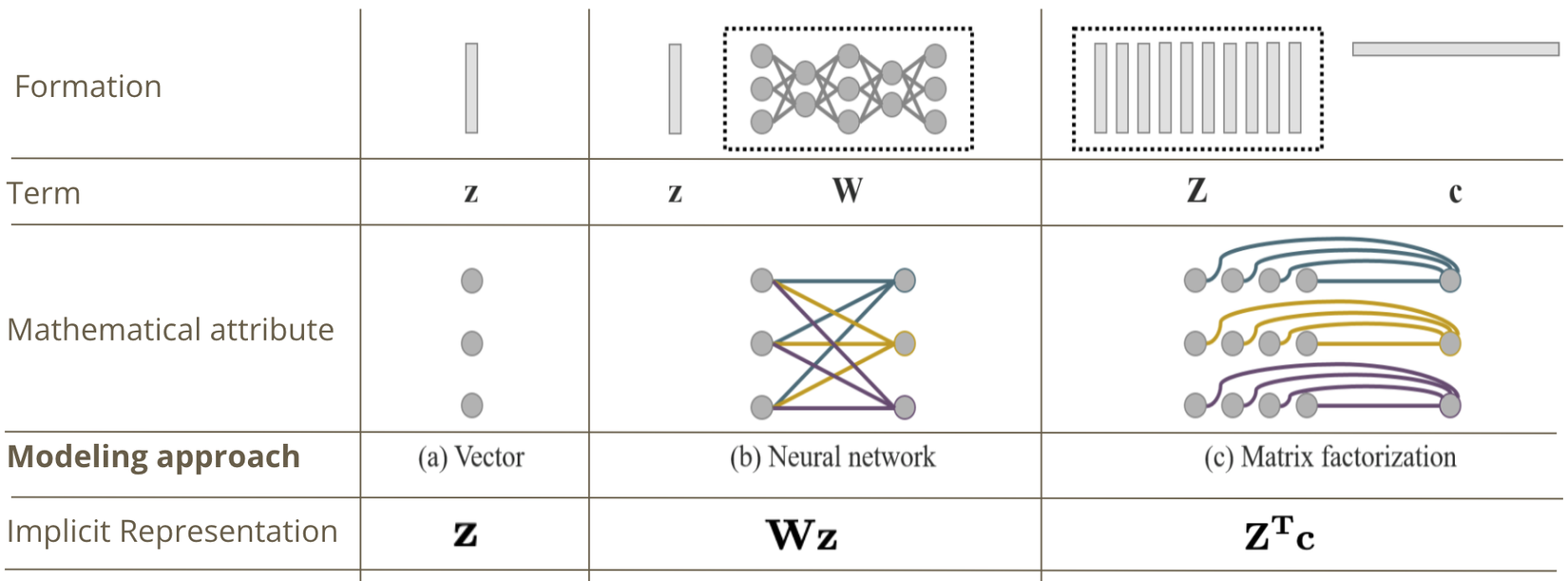
Ở hình 1, chúng ta thấy kiến thức tiềm ẩn được minh hoạ dưới dạng một mạng nơ rơn. Tuy nhiên, đó chỉ là một cách để mô hình hoá kiếm thức tiềm ẩn, hai cách khác để mô hình hoá là dưới dạng một véc tơ hoặc tích của hai ma trận như thể hiện ở hình 2.
Đến đây chúng ta cần phân giữa biệt kiến thức tiền ẩn nguyên thuỷ và biểu diễn tiềm ẩn. Kiến thức tiềm ẩn nguyên thuỷ được sử dụng để tính biểu diễn tiềm ẩn, biểu diễn tiềm ẩn này sau đó được sử dụng để kết hợp với biểu diễn tường minh (được trích xuất từ ảnh đầu vào) để đưa ra kết quả của mô hình. Trong trường hợp mô hình hoá kiến thức tiềm ẩn dưới dạng véc tơ, kiến thức tiềm ẩn nguyên thuỷ cũng chính là biểu diễn tiềm ẩn. Còn trong trường hợp mô hình hoá sử dụng mạng nơ rơn và tích của hai ma trận, biểu diễn tiềm ẩn được tính theo tham số tương ứng là và .
Do biểu diễn tiềm ẩn không phụ thuộc vào ảnh đầu vào, nên bất kể kiến thức tiềm ẩn được mô hình hoá phức tạp như nào thì biểu diễn tiềm ẩn vẫn có thể được đơn giản thành các véc tơ khi inference.
Các cách để kết hợp kiến thức tường minh và tiềm ẩn
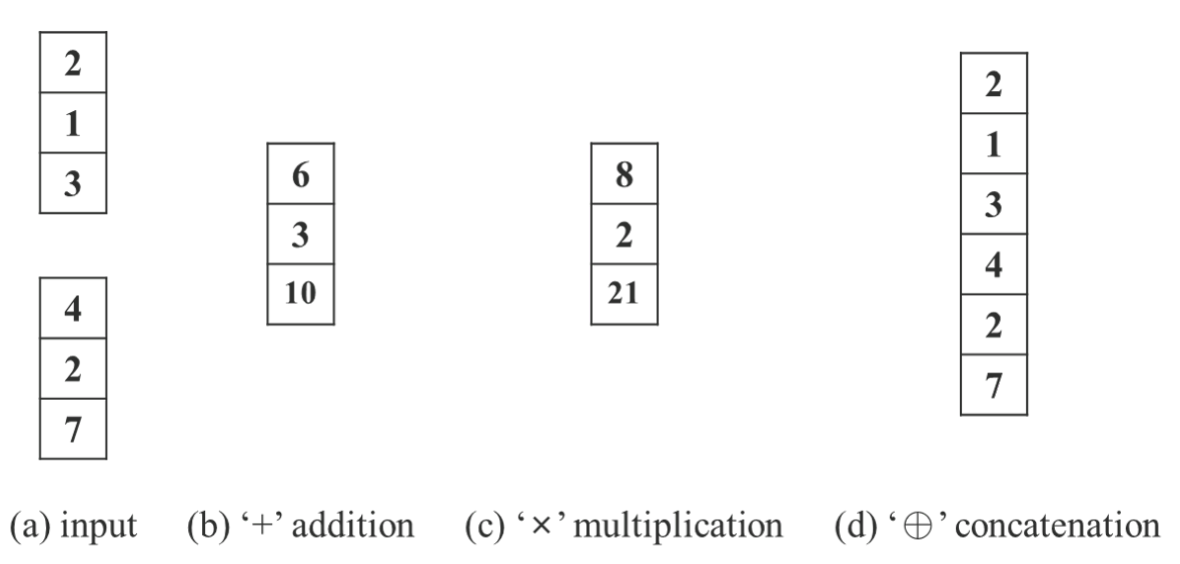
Đẳng thức cho dự đoán của mô hình được để xuất có thể được viết tổng quát như sau: . Trong đó, là các tham số của mạng nơ rơn, biểu thị phép biến đổi của mạng nơ ron, là tham số sử dụng để sinh biểu diễn tiềm ẩn, là phép biến đổi để phục vụ cho việc kết hợp kiến thức tường minh và kiến thức tiềm ẩn. Toán tử là toán tử được sử dụng để kết hợp và . Để dễ hình dung hơn, chúng ta có thể xem hình 3.
Áp dụng kiến thức tiềm ẩn vào các task.
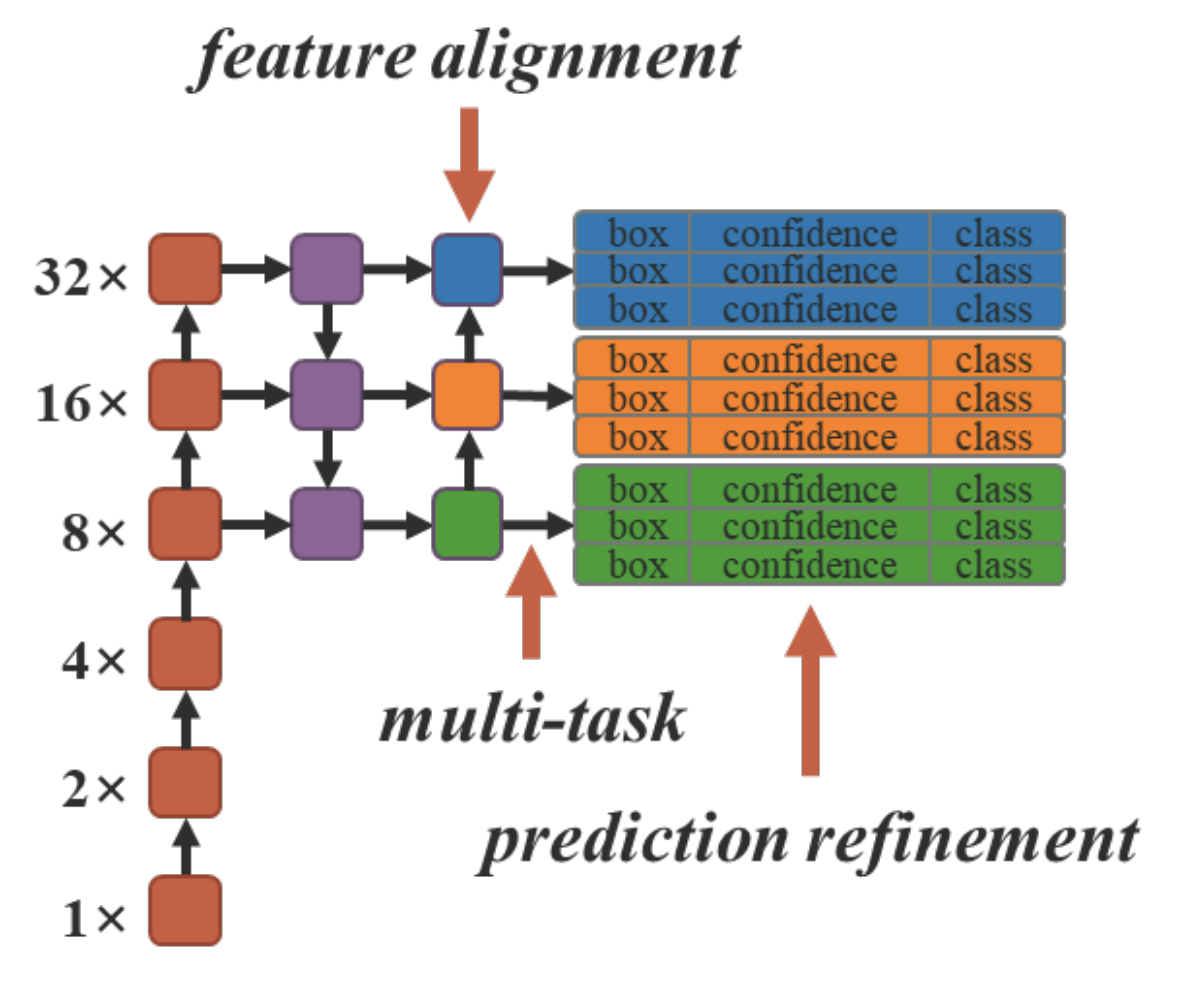
Hình 4 thể hiện mô hình tổng quát của YOLOv4-CSP. Kiến thức tiềm ẩn được đưa vào tại những chỗ mũi tên chỉ để cải thiện các task tương ứng: feature alignment, multi-task, prediction refinement.
Các toán tử kết hợp được chứng mình bằng thực nghiệm là sẽ cho kết quả tốt hơn nếu nó phù hợp với ý nghĩa về mặt vật lý của task. Ví dụ, toán tử cộng sử dụng cho feature alignment và toán tử nhân sử dụng cho prediction refinement sẽ cho kết quả tốt hơn.
Kết quả YOLOR so với các SOTA khác
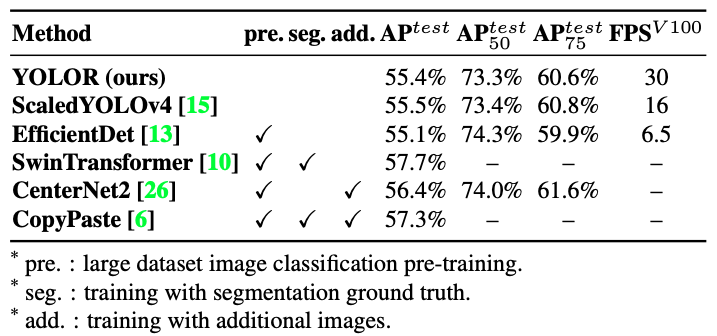
YOLOR có chỉ số tương đương với Scaled YOLOv4 trong khi FPS cao hơn 88%. Có thể nhiều bạn đăng thắc mắc tại sao đưa thêm tính toán vào mô hình mà FPS của YOLOR lại cao hơn Scaled-YOLOv4 88%, nguyên nhân là tác giả sử dụng kiến trúc khác với các topology được giới thiệu ở phần phụ lục của bài báo(Trong bài này mình sẽ không trình bày phần đó).
SwinTransformer, CopyPaste, CenterNet2 có độ chính xác cao hơn nhưng cần có một hoặc vài yêu cầu như huấn luyện trước trên tập dữ liệu phân loại lớn, sử dụng segmentation ground-truth hoặc cần thêm dữ liệu. Trong khi YOLOR không cần những điều kiện trên.
Ảnh hưởng của việc thêm kiến thức tiềm ẩn
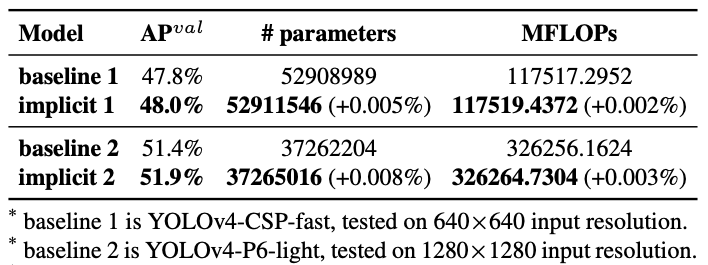
Tổng kết
Trong bài này, mình đã giới thiệu ngắn gọn những ý chính về YOLOR. Tác giả bài báo đã chứng minh bằng thực nghiệm việc đưa vào kiến thức tiềm ẩn như đề xuất làm tăng đáng kể độ chính xác mà làm giảm không đáng kể FPS. Hy vọng bài viết này có ích với các bạn. Mình khuyến khích các bạn đọc thêm paper gốc vì bài viết này chỉ định hướng tóm tắt dễ hiểu hơn. Mình cũng rất chào mừng các bạn có câu hỏi hay có thảo luận thêm. Cảm ơn các bạn đã đọc bài.
Hy vọng trong năm mới chúng ta sẽ có các thêm các phiên bản cải tiến của YOLO, có thể YOLOv6 hay YOLOv6 Pro Max 
All rights reserved
