
[Paper Explain] Communication-Efficient Learning of Deep Networks from Decentralized Data
Bài đăng này đã không được cập nhật trong 4 năm
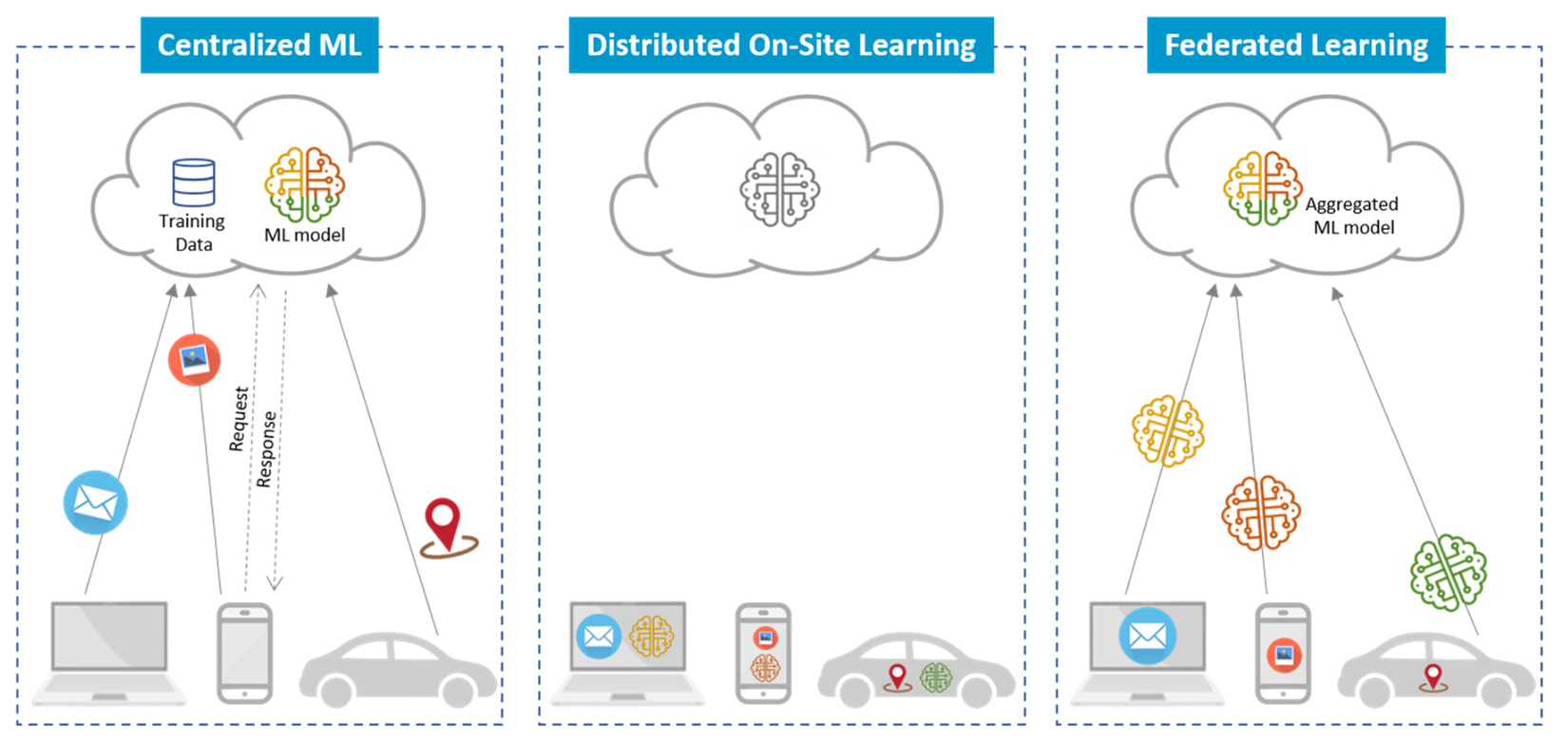
Đặt vấn đề
Trong thời đại smartphone, laptop, tablet (trong tương lai là cả các thiết bị IoT) đã quá phổ biến như hiện nay. Lượng dữ liệu sản sinh từ các thiết bị này hàng ngày là vô cùng lớn. Với các kỹ sư AI luôn "đói" dữ liệu thì đây quả là nguồn tài nguyên khao khát được khai thác. Tuy nhiên, chủ nhân của những thiết bị này không dễ dàng trao đi dữ liệu (và cả tài nguyên tính toán, năng lượng, bộ nhớ...) của họ. Để thuyết phục họ, chúng ta cần đảm bảo tính riêng tư (privacy preserving), truyền dữ liệu tốn ít thời gian và năng lượng (communication-efficient) và có phần thưởng khuyến khích cho người đóng góp cải thiện mô hình (incentive).
Bài báo hôm nay chúng ta bàn đến đề xuất phương pháp Học liên kết (Federated Learning) để cải thiện mô hình thông qua dữ liệu của các thiết bị mà vẫn đảm bảo về mặt rủi ro về tính riêng tư và xử lý, truyền dữ liệu một cách hiệu quả. Trước đó, đã có những nghiên cứu về Huấn luyện mô hình phân tán. Tuy nhiên, trong những nghiên cứu đó, tính phân tán chưa được thể hiện rõ và không xem xét đến trường hợp dữ liệu mất cân bằng và non-IID (non independent and non identically distributed). Trong bài báo này, tác giả chú trọng vào những đặc tính này của dữ liệu và đó cũng là những đặc điểm cơ bản của Học liên kết.
Giới thiệu
Trong bài báo, tác giả nghiên cứu một mô hình Học liên kết cho phép người dùng có thể cải thiện mô hình từ dữ liệu của chính mình và những người dùng khác. Mỗi người dùng sẽ có một tập dữ liệu huấn luyện riêng, những dữ liệu này sẽ không bao giờ được tải lên server. Thay vào đó mỗi client sẽ tính toán những update cần thiết lên server. Server sẽ đảm nhận vai trò tổng hợp lại những update từ client. Để đảm tính hiệu quả cũng như tính riêng tư, những update được gửi lên server cần phải luôn mang ít thông tin hơn dữ liệu thô và chúng khó có thể suy ngược được thông tin của client.
Tác giả cũng đưa ra một giải thuật tối ưu để đảm bảo việc giao tiếp giữa server và client là ít nhưng vẫn đảm bảo được việc cải thiện mô hình tốt nhất. Các so sánh của phương pháp được đề xuất với các baseline khác cho thấy sự hiệu quả của phương pháp được đề xuất.
Học liên kết
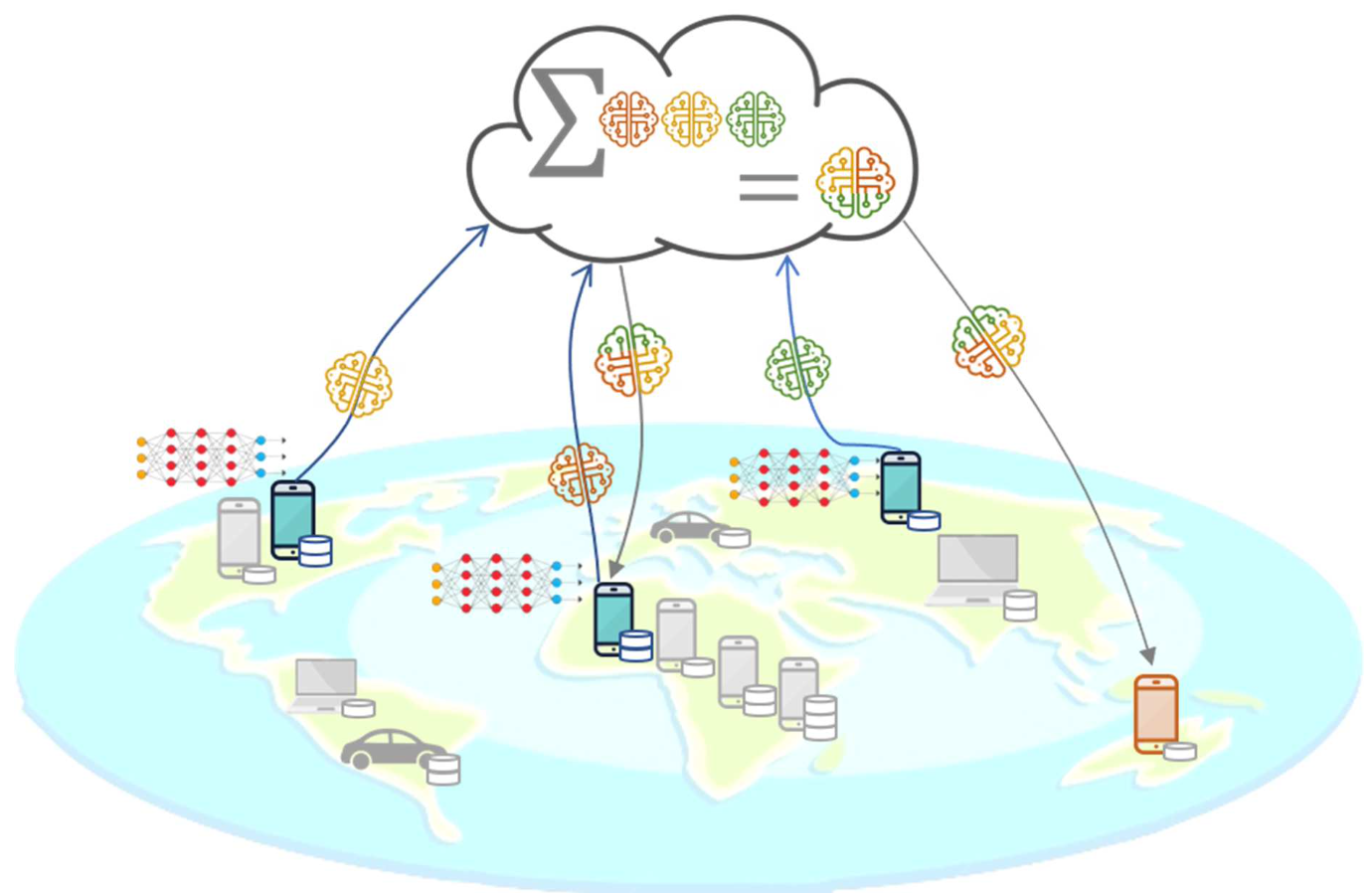
Tư tưởng tổng quát của mô hình Học liên kết được đưa ra trong bài báo được thể hiện như hình trên. Các thiết bị client sẽ thực hiện các tính toán để update mô hình mới và gửi lên server. Server sẽ làm nhiệm vụ tổng hợp các update này để tạo ra một mô hình mới. Cần lưu ý rằng dữ liệu thô trên thiết bị hoàn toàn không được truyền đi.
Tác giả đề xuất phương pháp Tối ưu liên kết (Federated optimization). Phương pháp này mô tả cụ thể những việc mà server và client sẽ phải thực hiện và thông tin được truyền đi giữa server và client. Độ hiệu quả của phương pháp này trực tiếp quyết định đến tính riêng tư và số vòng(round) cần update để thu được độ chính xác nhất mong muốn. Cụ thể tác giả giới thiệu giải thuật FederatedAveraging, giải thuật này thực hiện tối ưu trên client bằng stochastic gradient descent(SGD) và thực hiện lấy trung bình mô hình ở phía server. Chi tiết giải thuật được mô tả dưới đây:

Diễn giải giải thuật trên theo một cách khác, các bước thực hiện như sau:
- Server: Khởi tạo tham số
- Server: chọn ngẫu nhiên các client tham gia vào việc cải thiện mô hình (điều khiển số lượng client bằng tham số , tổng số lượng client là ), và gửi tham số mô hình hiện tại đến client.
- Các client: thực hiện tối ưu mô hình nhận được từ server trên tập dữ liệu cục bộ bằng SGD. (số epoch E, mini-batch size B)
- Các client: gửi lại tham số mới của mô hình cho server
- Server: tính trung bình các tham số mới nhận được từ các client với trọng số bằng số lượng mẫu dữ liệu tương ứng trên client.
- Quay lại bước 2 để tiếp tục round mới.
Việc khởi tạo mô hình ở phía server sau đó gửi các tham số này cho các client thay vì để các client tự khởi tạo là rất quan trọng để thu việc lấy trung bình mô cho kết quả tốt. Hình dưới đây so sánh kết quả lấy trung bình hai mô hình trong hai trường hợp là khởi tạo độc lập và khởi tạo giống nhau.
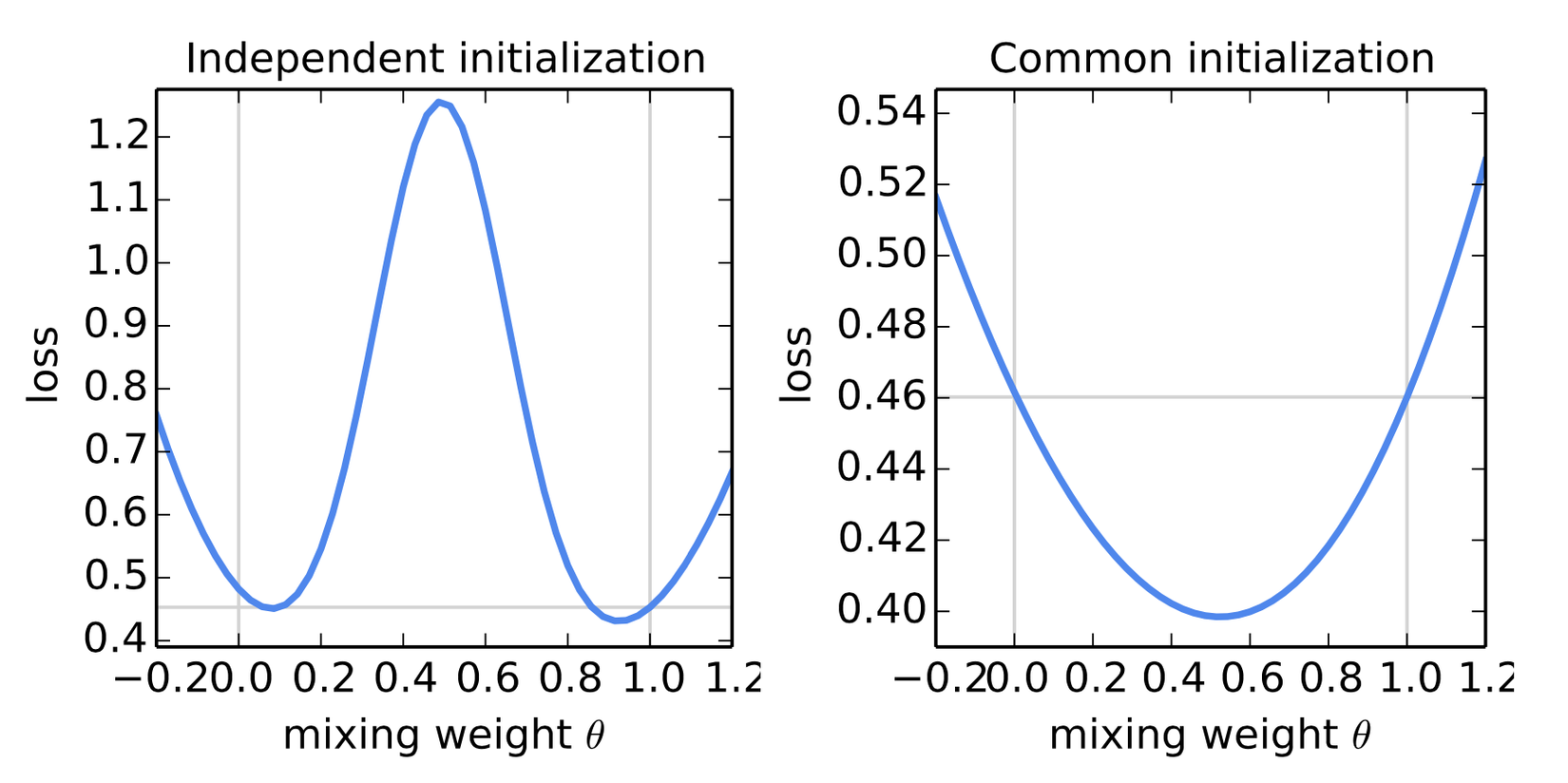
Qua hình trên ta thấy việc các mô hình được khởi tạo giống nhau rất quan trọng để mô hình trung bình thu được có kết quả tốt. Việc đơn giản chọn tỷ lệ 1:1 giữa 2 mô hình cũng đã cho kết quả rất tốt. Ngoài việc tham số khởi tạo giống nhau, các client trong round cùng nhận tham số từ server.
Thí nghiệm
Tác giả thực hiện những thí nghiệm với cả hai bài toán phân loại ảnh và mô hình ngôn ngữ. Bài viết này chỉ nêu các thí nghiệm cho bài toán phân loại ảnh. Các thí nghiệm này nhằm mục đích tìm ra ảnh hướng của các tham số để giải thuật FederatedAveraging hoạt động hiệu quả nhất. Hai tập dữ liệu mà tác giả sử dụng để thí nghiệm là MNIST và CIFAR10.
Một điều quan trọng trong thí các thí nghiệm này là xem xét tính non-IID của dữ liệu, điều mà các nghiên cứu trước chưa xét đến. Ngoài ra, tác giả cũng thử nghiệm của trường hợp dữ liệu IID. Để chia dữ liệu thoả mãn IID trên tập MNIST, tác giải trộn dữ liệu và chia cho 100 client, mỗi client nhận 600 mẫu dữ liệu. Với cách chia non-IID, đầu tiên tác giả sắp xếp dữ liệu theo nhãn rồi chia thành 200 phần dữ liệu, mỗi phần 300 mẫu, gán cho mỗi client 2 phần dữ liệu, như vậy với cách chia này mỗi client sẽ có nhiều nhất 2 loại chữ số. Tác giả sử dụng cách chia cực kỳ non-IID như vậy để xem mức độ chịu đựng của giải thuật. Cần lưu ý, dữ liệu trong cả hai cách chia trên đều là cân bằng.
Tăng xử lý song song. Thí nghiệm đầu tiên là thí nghiệm để tìm ra tỷ lệ các client tham gia tối ưu C. Trong thí nghiệm này, tác giả thực hiện với hai mô hình là NN và CNN cho bài toán MNIST. Kết quả được thể hiện qua bảng dưới.
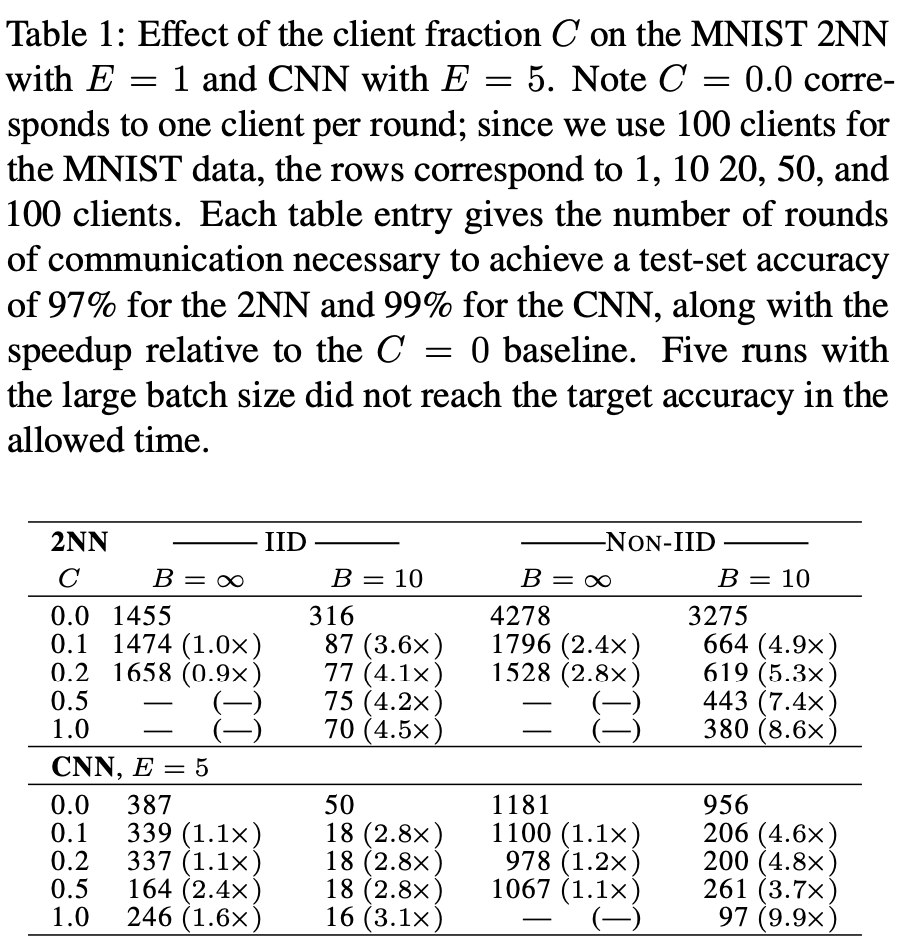
Mỗi ô trong bẳng là số round cần thiết để thu được độ chính xác test 97% với NN và 99% với CNN. Các ô không có kết quả là các thử nghiệm vượt quá thời gian cho phép. Từ kết quả này, ta thấy được với , số lượng round cần thiết giảm đáng kể. Ngoài ra, cho số lượng round cần thiết tốt trong khi cân bằng với việc tính toán hiệu quả. Vì vậy, trong hầu hết các thí nghiệm sau, tác giả cố định .
Tăng lượng tính toán mỗi client. Trong thí nghiệm này, tác giả tăng khối lượng tính toán của phía client bằng cách giảm hoặc tăng hoặc cả hai.
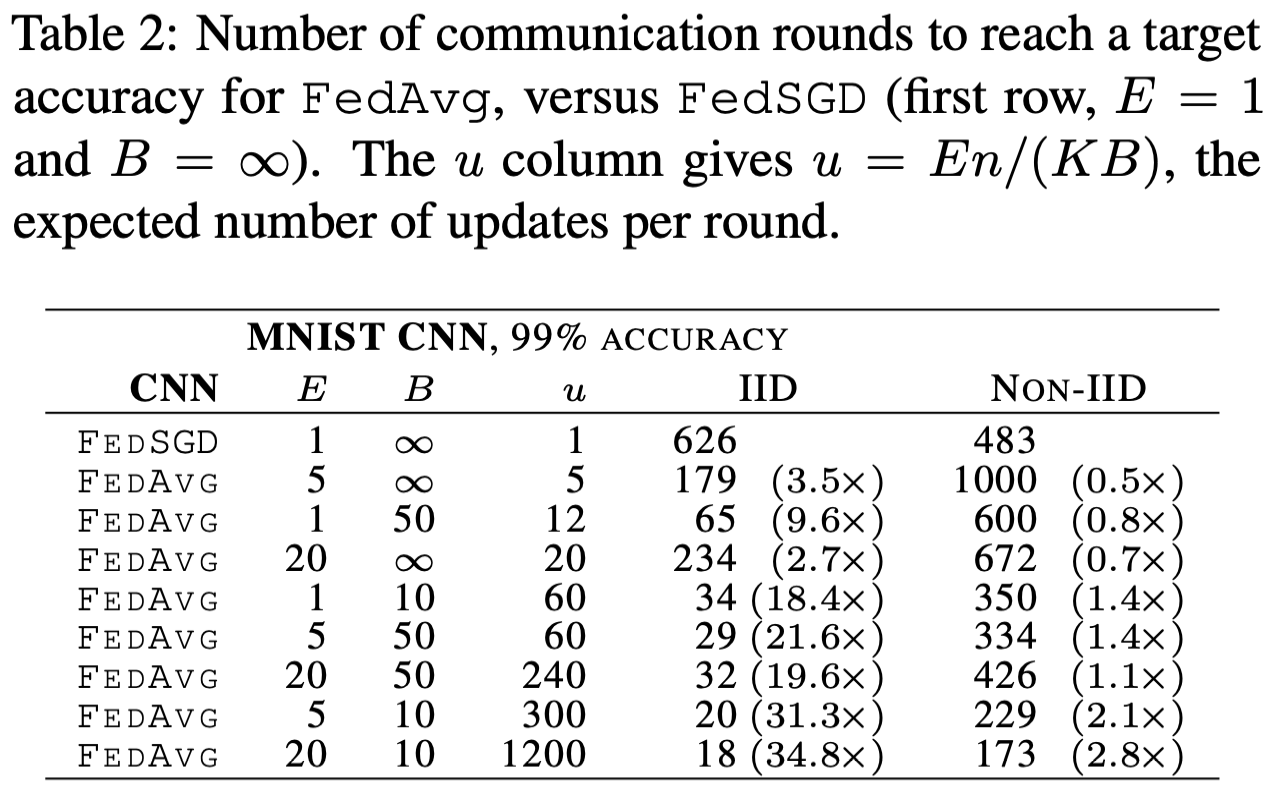
Ở đây giải thuật FEDSGD tương ứng với FEDAVG với và . Qua kết quả trên ta có thể thấy việc tăng khối lượng tính toán ở phía client có thể làm giảm số round cần thiết để thu được độ chính xác mong muốn.
Thí nghiệm với CIFAR-10 Để xác định thêm tính hiệu quả của FedAvg tác giả thử nghiệm thêm với tập CIFAR-10. Trong thí nghiệm này tác giả, sử dụng thêm 1 baseline để so sánh, client huẩn luyện mô hình với toàn bộ tập data mà không chia dữ liệu, sử dụng SGD với mini-batch size là 100.

Như vậy, FedAvg vẫn hoạt động hiệu quả với tập CIFAR10 và cải thiện đáng kể số round cần thiết để thu được cùng độ chính xác.
Kết luận
Trong bài báo này, tác giả đã đưa ra mô hình Học liên kết và chứng minh được tính hiệu quả của nó trong bài toán thực tế thông qua các thí nghiệm so sánh. Nhiều phần của mô hình này vẫn đang được sử dụng và cải tiến cho đến tận bây giờ.
Trong bài bài này tác giải không đề cập quá nhiều đến độ hiệu quả của phương pháp này đối với tính riêng tư của dữ liệu. Tuy nhiên bản thân những update được gửi đi cũng khó có thể suy ngược lại được thông tin của người dùng hơn dữ liệu thô(hoặc gradient). Các hướng tương lai của tác giả để cải tăng tính đảm bảo riêng tư bao gồm differential privacy, secure multi-party computation, và tổ hợp của những phương pháp này.
Về mặt hiệu quả giao tiếp giữa client và server. Những kết quả thí nghiệm cũng chỉ ra được sự cải thiện đáng kể so với các phương pháp khác.
All rights reserved
