
Bạn đã biết về Zero-shot Learning chưa?
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Trong các bài toán về Face Recognition, chắc hẳn các bạn đã nghe hoặc nên nghe về 1 khái niệm One-shot learning. Mình cũng đã từng làm đồ án môn học về phương pháp này, tương đối hay. Lại là lúc lượn lờ linh tinh, bắt gặp một khai niệm Zero-shot learning. Ủa, tiền thân của One-shot learning hay gì? Vì vậy, song song với việc tìm hiểu xem nó là gì, mình cũng mong muốn chia sẻ cho mọi người thêm một chút kiến thức mới cho những ai chưa biết. Còn Two-shot, Three-shot gì đấy thì để sau nhé
Chúc các bạn có thời gian đọc bài viết vui vẻ!
Zero-shot learning là gì?
Theo các nguồn mình đọc, có thể khái quát One-shot learning như sau: One-shot learning là một phương pháp xác định các danh mục chưa được quan sát thấy trong quá trình đào tạo. Ví dụ dễ hiểu, sẽ không có gì khó khăn khi bạn nhận ra một con ngựa vằn khi bạn đọc được nó chỉ khác con ngựa thường ở chỗ có thêm vằn, mặc dù bạn chưa thấy lần nào nhưng chắc chắn bạn sẽ nhận ra ngày lần đầu nhìn thấy nó.
Với các phương pháp học tập có giám sát hay không có giám sát truyền thống, việc dự đoán nhãn cho một đầu vào đều dựa vào những nhãn đã có, đã biết. Đối với One-shot learning, ý tưởng chính là dựa trên việc chuyển ngữ nghĩa từ các nhãn được quan sát (đã có) sang nhãn mới. Về cơ bản, Zero-shot hoạt động bằng cách kết hợp các mục quan sát/nhìn thấy với các mục không quan sát/nhìn thấy thông qua một số loại thông tin bổ trợ, mã hóa các thuộc tính phân biệt có thể quan sát của các đối tượng.
Ví dụ mô hình đào tạo phân loại động vật đã được huấn luyện để nhận dạng được con ngựa. Mô hình này có thể xác định được ngựa vằn nếu nó có các thông tin bổ trợ, thông tin bổ trợ ở đây có thể bao gồm các thuộc tính, mô tả dạng văn bản hoặc vector đặc trưng.

(Nguồn: https://arxiv.org/pdf/1707.00600.pdf)
Chìa khóa của việc chuyển giao ngữ nghĩa là mã hóa các danh mục dưới dạng vector trong một không gian ngữ nghĩa. Danh mục ở đây là gì? Ví dụ một con mèo có đặc điểm 4 chân, có đuôi, có lông, … các tính năng này sẽ được mã hóa thành các vector danh mục.
Zero-shot cũng bao gồm 2 giai đoạn, tuy nhiên có hơi khác một chút:
- Training: Huấn luyện mô hình với các thuộc tính đã biết
- Inference: Mô hình sau khi huấn luyện được sử dụng để phân loại các cá thể trong một tập hợp các lớp mới
Cách thức hoạt động của Zero-shot learning
Có 2 cách tiếp cận phổ biến được sử dụng các vấn đề về các bài toán nhận dạng ảnh
Tiếp cận dựa trên nhúng
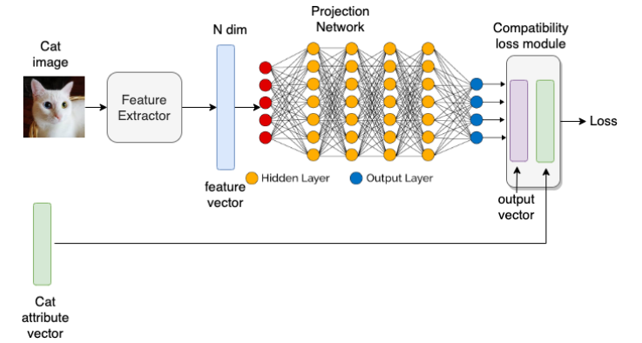
(Nguồn: https://zephyrnet.com/vi/zero-shot-learning-can-you-classify-an-object-without-seeing-it-before/ )
Mục tiêu chính là ánh xạ các đặc điểm, danh mục, các thuộc tính ngữ nghĩa vào 1 không gian nhúng bằng một hàm ánh xạ y=f(x), trong đó hàm này sẽ được học. Cùng tìm hiểu cách thức hoạt động của phương pháp này thông qua hình vẽ trên nhé Đối với quá trình Training:
- Các thuộc tính, danh mục sẽ được vector hóa để làm nhãn cũng như thuật tiện cho việc mô hình so sánh với dự đoán để điều chỉnh lại mô hình. Giả sử có các danh mục như: 4 chân, có đuôi, ăn cá, giả sử dùng kỹ thuật encoding đơn giản nhất đó là thuộc tính nào positive thì để là 1, negative để là 0 thì ta sẽ có attribute vector đối với con chim là [0,1, 1]. Đây là mình chỉ ví dụ vì có rất nhiều cách khác nhau encoding các thuộc tính, tuy nhiên bài viết gốc thì lại lấy vị dụ về văn bản, dễ dàng hơn.
- Đối với mỗi bức ảnh đầu vào sẽ được đưa qua một mạng Deep Neural network để trích xuất ra vector đặc trưng của ảnh. Giả sử vector đặc trưng này có số chiều là N. Trong khi dữ liệu có D thuộc tính cần quan tâm. Lúc này ta sẽ sử dụng một mạng ANN bao gồm các lớp Fully connected để giảm số chiều từ N xuống D, đồng thời tính toán vector biểu thị ra xác suất của các đặc trưng (có số chiều D). Đầu ra của mô hình sẽ được so sánh với vector thuộc tính đã nêu trên bằng 1 hàm Loss để điều chỉnh mô hình sao cho bức ảnh đầu vào trả ra đặc tính sát nhất với đặc tính đúng của nó. Đối với quá trình Inferences:
- Khi mô hình đã học được việc trả ra các đặc trưng, danh mục của ảnh đầu vào, khi đưa một bức ảnh mới chưa có trong các nhóm quan sát được vào, mô hình sẽ trả ra các đặc trưng ngữ nghĩa của bức ảnh đó dưới dạng vector (Đó là lý do tại sao gọi là tiếp cận dựa trên nhúng).
- Lại ví dụ với với con ngựa cho dễ hiểu nhé :v, giả sử có các đặc trưng như sau: 4 chân, ăn cá, ăn cỏ, có vằn, có đuôi, giả sử vector thuộc tính của con ngựa sẽ là [1, 0, 1, 0, 1]. Với giả sử mô hình đủ tốt để nhận diện ra các đặc tính cảu bức ảnh, ta đưa đầu vào là bức ảnh con ngựa vằn vào, mô hình trả ra cho ta vector thuộc tính dạng như con ngựa nhưng ở thuộc tính có vằn thì lại có trong khi con ngựa thì không. Chính việc tạo ra các vector thuộc tính này sẽ giúp chúng ta trong việc truy vấn về sau, kiểu như mô hình mình chỉ nhận dạng được con ngựa, tuy nhiên mình chỉ cần tìm các hình ảnh nào dự đoán là con ngựa và có thêm thuộc tính có vằn thì đó sẽ là con ngựa vằn =))
Đơn giản phải không nào? Tuy nhiên hạn chế cựa phương pháp này là hiện tượng thiên vị và dịch chuyển miền. Tức là việc học này chỉ dựa trên những gì mô hình nhìn thấy (Giả sử có những ảnh ngựa nó không ăn cỏ mà nó đang phi trên bờ biển chẳng hạn thì đặc tính ăn cỏ sẽ bị lu mờ do mô hình không nhận thấy), do vậy mô hình sẽ thiên về phía các đặc tính nhìn thấy được trong dữ liệu. Để khắc phục được yếu điểm này, mợi các bạn đọc tiếp cách tiếp cận thứ 2
Tiếp cận dựa trên mô hình sinh
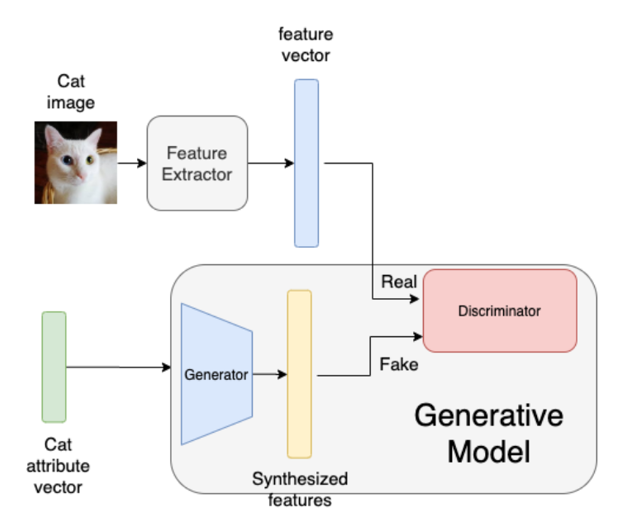
(Nguồn: https://zephyrnet.com/vi/zero-shot-learning-can-you-classify-an-object-without-seeing-it-before/ )
Trước tiên, chúng ta cùng tìm hiểu pipeline của cách tiếp cận này. Nhìn vào hình vẽ, trước hết , ảnh đầu vào vẫn được trích xuất ra vector đặc trưng thông qua một mạng DNN như ở cách tiếp cận nhúng. Còn về phía vector thuộc tính, thay vì được đối chiếu trực tiếp với đặc trưng của ảnh đầu vào, chúng sẽ được đưa vào một mô hình sinh (Generative Model).
Đảo qua một chút kiến thức cơ bản về mạng GAN (Generative Adversarial Networks), GAN cấu tạo gồm 2 mạng là Generator và Discriminator. Trong khi Generator sinh ra các dữ liệu giống như thật thì Discriminator cố gắng phân biệt đâu là dữ liệu được sinh ra từ Generator và đâu là dữ liệu thật (Nghĩa là coi dữ liệu sinh ra từ Generator là dữ liệu giả).
Quay lại kiến trúc mô hình bên trên, Vector thuộc tính thay vị được so sánh trực tiếp với vector đặc trưng thì chúng được đưa qua khối Generator để điều chỉnh vector thuộc tính sao cho giống với vector đặc trưng nhất có thể. Như vậy, khác với cách tiếp cận ban đầu, thay vì cố gắng biến đổi vector đặc trưng sao cho sát nhất với vector thuộc tính, ở cách tiếp cận này, cả 2 vector đều phải biến đổi sao cho giống nhau, khó phân biệt.
Chắc hẳn sẽ có 1 số bạn giống mình, đến đây chưa hiểu cái kiến trúc trên lắm. Vậy các bạn cùng tìm hiểu lại về mạng GAN nhé. Còn để mình nói đơn giản thế này cho dễ hiểu 2 khối Generator và Discriminator này hoạt động như thế nào. Trong khi khối Generator cố gắng học ông Fake cho giống ông Real, thì ông Discriminator cố gắng phân biệt ông Real với ông Fake. 2 ông này học kiểu ngược nhau, và mục tiêu là ông Generator phải thắng, qua mặt được ông Discriminator.
Sau khi mô hình sinh đã được huấn luyện, lúc này trong quá trình Inference, Ảnh đầu vào sẽ dược đưa vào mô hình, đi kèm với đó là các lớp nhìn thấy (có trong dataset train) và các lớp không nhìn thấy (mới) được đưa vào khối Generator, tiếp tục sử dụng khối Discriminative để phân biệt, trong đó việc phân biệt vector đặc trưng với đầu ra của khối Generator của thuộc tính nhìn thấy được phân biệt với trọng số cao hơn so với thuộc tính không nhìn thấy. Đơn giản vì với dữ liệu mới, nguyên lý là chủ yếu dựa trên các thuộc tính nhìn thấy, còn các thuộc tính mới là bổ sung nên trọng số phụ thuộc sẽ thấp hơn. Cuối cùng trả ra Classification score, từ đó có thể trả ra các kết quả mong muốn.
Kết luận
Theo bài viết gốc còn phần đánh giá cho phương pháp Zẻo-shot learning nữa nhưng cá nhân mình thấy tương đối sơ sài, vì vậy chưa đưa vào bài viết của mình, đồng thời mình thấy bài viết cũng đã tương đối nhiều chữ. Trên đây là những kiến thức mình tham khảo đồng thời kết hợp việc tìm hiểu của mình để diễn giải cho dễ hiểu hơn. Mình thấy đây là một chủ đề tương đối hay, ngoài ra còn có phương pháp Few-shot learning, mình sẽ trình bày vào các bài viết sau.
Cảm ơn các bạn đã đọc đến cuối cùng. Mong mọi người ủng hộ để mình có động lực chia sẻ nhiều hơn.
Conferences
[1] Chauhan, N. S. (2021). Zero-Shot Learning: Can you classify an object without seeing it before? KDnuggets. https://www.kdnuggets.com/2021/04/zero-shot-learning.html
[2] N. (2021, February 16). Bài 1: Giới thiệu về GAN. Deep Learning Cơ Bản. https://nttuan8.com/bai-1-gioi-thieu-ve-gan/
[3] Sinha, S. (2018, June 18). What Is Zero-Shot Learning? Analytics India Magazine. https://analyticsindiamag.com/what-is-zero-shot-learning/
[4] Xian, Y. (2017, July 3). Zero-Shot Learning -- A Comprehensive Evaluation of the Good, the. . . arXiv.Org. https://arxiv.org/abs/1707.00600
All rights reserved
