
Generative adversarial networks(GAN) và ứng dụng của nó trong deepfakes
Bài đăng này đã không được cập nhật trong 6 năm
Mở Đầu
Lưu ý: Trong bài mình vấn sẽ sử dụng một số từ tiếng anh chuyên ngành của nó , vì nếu dịch mấy từ đó ra tiếng việt sẽ rất buồn cười , mong các bạn thông cảm 
Cụm từ deep fake là một cụm từ rất HOT trong vài năm gần đây, hãy thử tưởng tượng bạn có thể vào vai chính trong một bộ phim mình thích, điều đấy sẽ ko còn là ước mơ nữa rồi vì công nghệ này sẽ giải quyết được điều đó, nhưng việc đầu tiên khi chúng ta nói về nó không phải là công nghệ mà lại chính là vấn đề về Đạo đức , công nghệ này chỉ nên được sử dụng cho mục đích nghiên cứu chứ không phải là mục đích xấu như porn hay chính trị... , ta có thể xem video sau để hiểu rõ hơn sự đáng sợ của công nghệ này:

Khái niệm cơ bản
Khái niệm của deep fake rất đơn giản. Giả dụ ta muốn transfer mặt của người A sang video có mặt của người B.
Đầu tiền ta sẽ thu thập dữ liệu của hai người A và B . Sau đó ta sẽ xây dựng một bộ mã hóa (encoder) để encode tất cả những hình ảnh trong một mạng CNN, và sử dụng decoder để tái tạo lại hình ảnh. Autoencoder( encoder & decoder) có hàng triệu tham số nhưng điều đó ko có nghĩa là nó sẽ ghi nhớ được tất các các features của tất cả các hình ảnh ta đưa vào mạng. Vì thế encoder nó sẽ cần phải lọc ra những features quan trọng nhất để tái tại lại ảnh là input ban đầu.
Để dễ tưởng tượng hơn thì mình sẽ ví dụ như này: Bạn vào một của hàng đi shopping và ko may đúng hôm đấy có tên cướp bước vào. Và điều hiển nhiên là bạn sẽ bị cướp sạch, cửa hàng cũng vậy :v . Cảnh sát đến và nhờ bạn mô tả các đặc trưng ,hình dáng tên cướp (encoder) cho họ và họ sẽ phác họa lại dựa trên những đặc điểm bạn vừa nói của tên cướp (decoder).
Để decode các features ta sẽ sử dụng hai bộ decoder riêng , một cho người A và một cho người B, ta sẽ huấn luyện encoder và decoder( sử dụng backpropagation) để cho đầu vào và đầu ra match nhau nhất có thể.
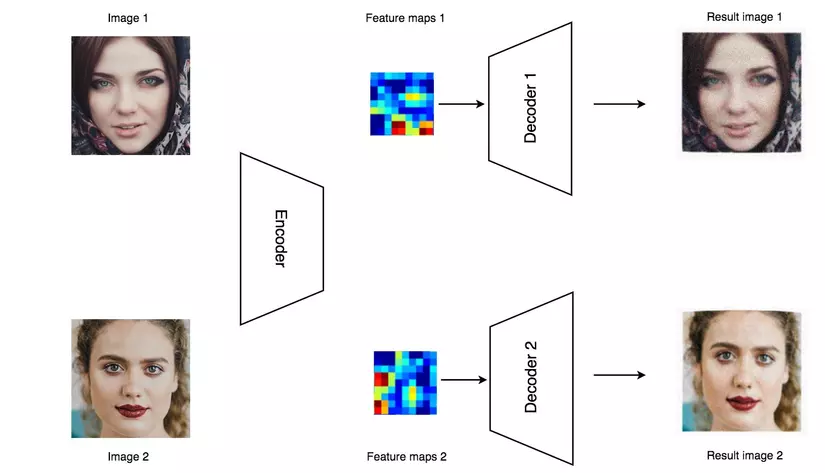
Sau khi hoàn tất quá trình huấn luyện thì ta sẽ sử lý hình ảnh crop ra mặt của người A và cho vào encoder, nhưng thay vì sử dụng decoder của A thì ta sẽ thay bằng decoder B để tái tạo lại hình ảnh đầu vào của người A với mặt của người B
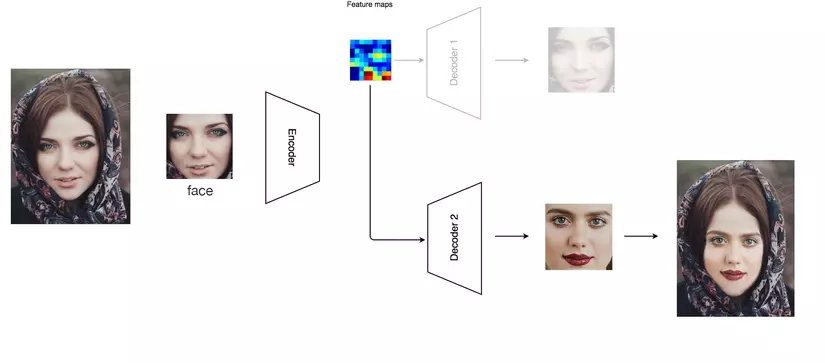
Trong quá trình thì encoder sẽ phát hiện ra góc cạnh mặt, màu da, nét mặt, các biểu hiện, ánh sáng ... hay tóm lại là tất cả các thông tin hiện trên khuôn mặt của người đó , điều này cực kỳ quan trọng để tái tạo lại hình ảnh. Chúng ta sẽ dựng lại khuôn mặt của người B lên bối cảnh video của người A( nôm na là swap mặt cho nhau :v) giống như hình ảnh dưới đây:

Xử lý dữ liệu hình ảnh
Trước khi quá trình huấn luyện thì ta phải chuẩn bị hàng ngàn hình ảnh của cả hai người . Ta sẽ sử dụng các thư viện có sẵn như dlib hay MTCNN dể detect và crop từ video hay bộ dữ liệu ảnh cho trước:
- Sử dụng các ảnh có chất lượng cao để có được kết quả tốt hơn
- Nếu bạn đã xác định chọn người A để đưa vào mạng thì hãy xóa tất cả những người ko liên quan trong data đấy của bạn , trong data đấy chỉ có mặt của người A
- Remove những hình ảnh bị che khuất bởi vật thể, thừa ánh sáng, chất lượng thấp...
- Kết quả đầu ra sẽ tốt hơn nếu hai người nhìn same same nhau hay có điểm trên khuôn mặt giống nhau, vì vậy hãy chọn data thông minh :v
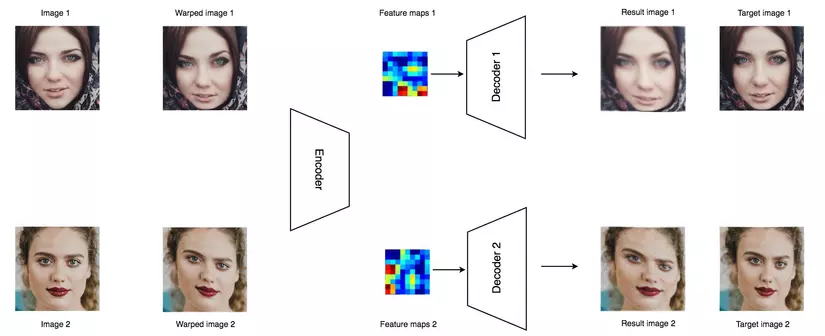
Chúng ta cũng không muốn autoencoder chỉ đơn giản là huấn luyện input và phỏng theo output, vì điều này chả có ý nghĩa gì cả. Ta sẽ sử dụng một kỹ thuật gọi là "denoising" để huấn luyện cho autoencoder học một cách thông minh hơn. Ý tưởng chíng của kỹ thuật này là bóp méo một số thông tin của dữ liệu , và điều ta mong đợi là autoencoder sẽ bỏ qua những bất thường đó để tái tạo lại được ảnh gốc ban đầu. Bằng cách huấn luyện rất nhiều lần, các thông tin bị bóp méo sẽ tự triệt tiêu lẫn nhau và hình ảnh ban đầu sẽ được tái tại lại một cách chuẩn xác nhất.
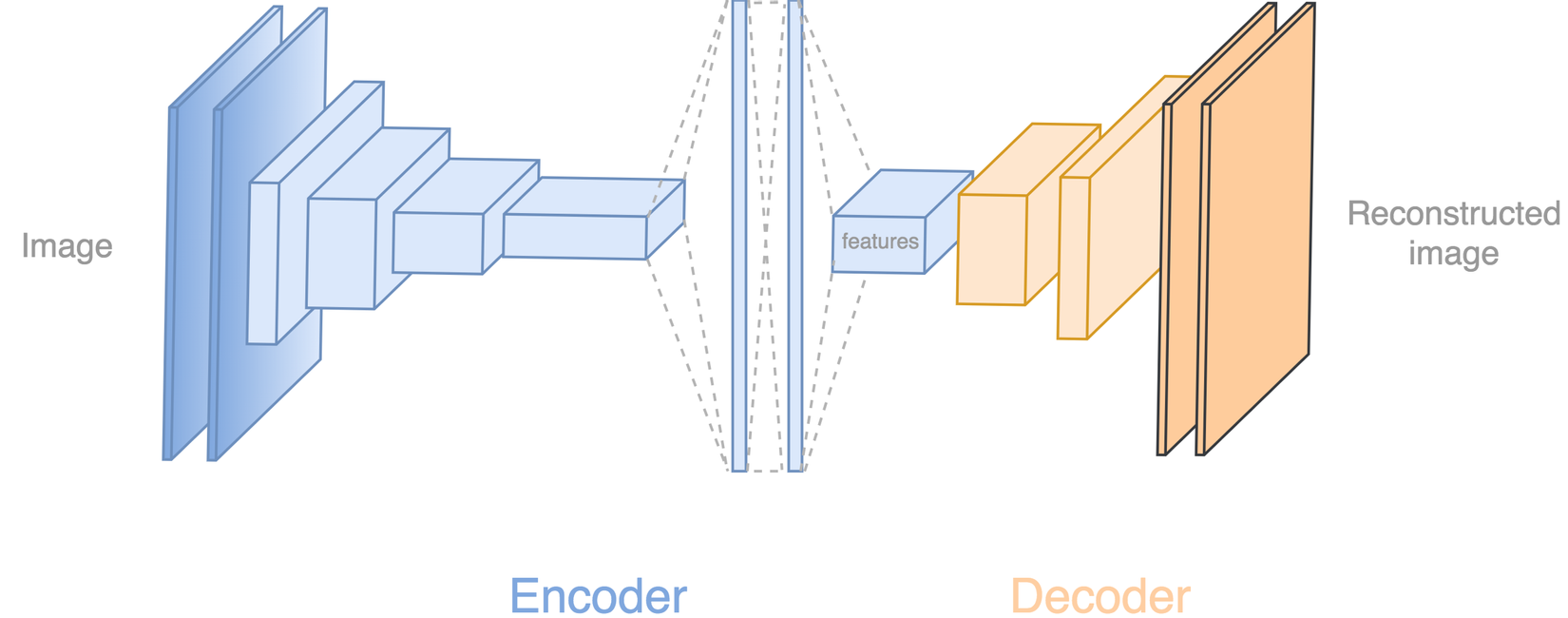
Autoencoder deep network
Ta sẽ tìm hiểu xem autoencoder trông như thế nào  ) . Encoder gồm 5 lớp conv để trích xuất features theo sau 2 lớp dense. Sau đó mạng sẽ dùng thêm một lớp conv để upsampling hình ảnh. Decoder sẽ tiếp tục upsampling thêm 4 lớp conv nữa đến khi nó reconstructs hình ảnh 64x64 lại.
) . Encoder gồm 5 lớp conv để trích xuất features theo sau 2 lớp dense. Sau đó mạng sẽ dùng thêm một lớp conv để upsampling hình ảnh. Decoder sẽ tiếp tục upsampling thêm 4 lớp conv nữa đến khi nó reconstructs hình ảnh 64x64 lại.
Mask
Trong deep face fakes ta sẽ sẽ tạo mask trước, nó giống như ta sẽ tạo một cái khung cố định rồi sau đó ta sẽ blend face vào dựa trên khung đó vào trong video chả hạn.
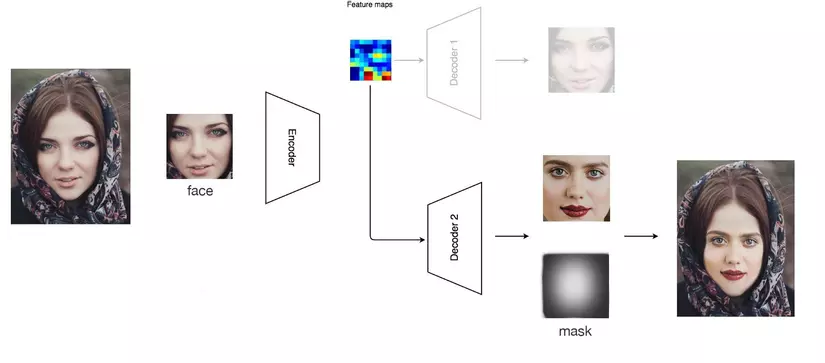
Nếu bạn nhìn vào trong một video fake, đôi lúc bạn sẽ thấy có hai cằm hiện ra hoặc một vài nét mờ của khuôn mặt. Đó là nhược điểm khi merge hai ảnh với nhau sử dụng mask. Để làm cho kết quả tốt hơn ta có thể cấu hình lại deep fakes ta áp dụng sharpen filter cho ảnh rồi sau đó mới blend với nhau. Nhưng rõ ràng là ta cần độ mờ để loại bỏ những góc cạnh thừa của khuôn mặt tốt hơn nên ta cần phải tạo ra mask để loại bỏ những phần không cần thiết đó.
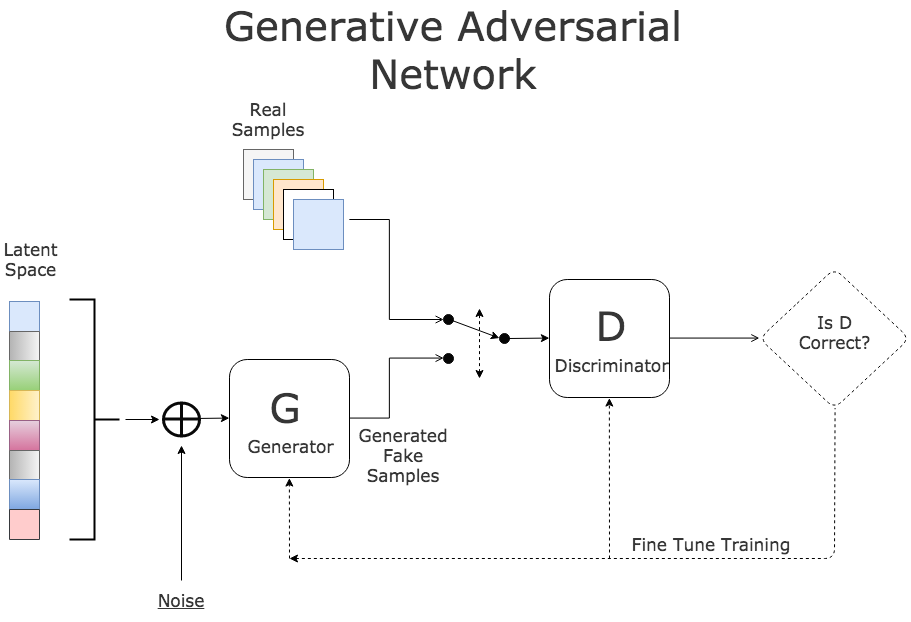
GAN
GANs là một thuật toán học không giám sát(unsupervised learning) cực kỳ mạnh mẽ được phát triên bởi Ian J. Goodfellow vào năm 2014. Về cơ bản GANs là một hệ thống gồm hai mạng neural network “cạnh tranh” và tự hoàn thiện nhau.
GANs sinh ra để giải quyết vấn đề gì?
Người ta đã nhận thấy hầu hết các mạng neural network chính thống có thể dễ dàng bị lừa trong việc phân loại sai mọi thứ bằng cách chỉ thêm một lượng “noise” nhỏ vào dữ liệu gốc. Mô hình sau khi được huấn luyện với lượng dữ liệu “noise” đó rất dễ dự đoán sai so với model gốc. Một nhược điểm rất lớn của các mạng neural network thông thường là chỉ được học trên dữ liệu hạn chế, do đó nó rất dễ bị overfitting. Ngoài ra khi ta ánh xạ giữa Input và Output thì hầu như là tuyến tính. Mặc dù, có vẻ như ranh giới phân tách giữa các lớp khác nhau là tuyến tính, nhưng trong thực tế, chúng chỉ bao gồm các tuyến tính và thậm chí một thay đổi nhỏ trong một đặc trưng của một bức ảnh chả hạn cũng có thể dẫn đến phân loại dữ liệu sai. Và sau đó GANs ra đời để ko bị lừa như thằng này :v
Gans hoạt động như thế nào?
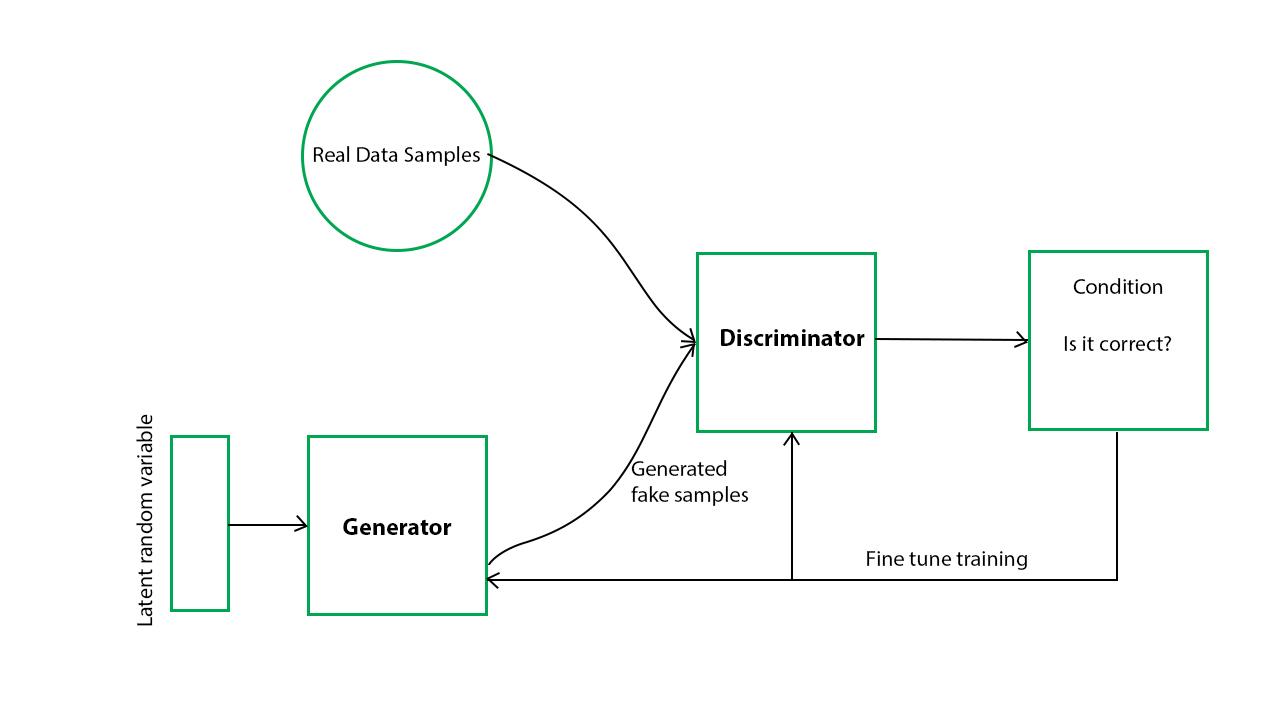
Ta có thể chia Gans ra làm hai phần:
- Generator: Thằng này nhận nhiệm vụ fake data sao cho giống thật nhất có thể (ma trận số, audio, hình nude… ).và cố gắng lừa tình thằng Discriminator để nó ko nhận ra.
- Discriminator: Kiểm định dữ liệu mà thằng Genarator đổ vào, phân biệt nó là fake hay real.
Generator và Discriminator đều là mạng neural network và cùng “cạnh tranh” nhau, Generator cố gắng tạo ra dữ liệu giống thật nhất có thể , còn Discriminator cố gắng phân biệt dữ liệu mà Genarator đổ vào và chứng minh nó là hàng fake sau đó thông báo lại cho Generator để nó cải thiện, cứ như thế quá trình này lặp đi lặp lại để generator có thể tạo ra sample hoàn hảo nhất mà Discriminator không thể phân biệt được.
-
: Generator
-
: Discriminator
-
: Phân phối xác xuất của real data
-
: Phân phối xác xuất của Generator
-
: Mẫu thử được lấy ra ngẫu nhiên của
-
: Mẫu thử được lấy ra ngẫu nhiên của
-
: Mạng Discriminator
-
: Mạng Generator
Generator (ký hiệu ) nhận nhiệm vụ học ra cách áp xạ từ một không gian tìm ẩn (a latent space) vào một không gian với phân phối từ dữ liệu cho trước. Discriminator (ký hiệu ) nhận nhiệm vụ phân biệt dữ liệu được tạo ra từ và dữ liệu cho trước. Giả sử ta có có , dữ liệu cho trước có ( gọi là real data). Ta có sẽ ánh xạ không gian dữ liệu cho trước ( gọi là fake data). là xác suất mà x là real data hay fake data. Mục tiêu của GANs là làm sao cho G cố gắng tạo ra được sao cho không còn thể phân biệt được là fake data. Tối ưu và giống như trò chơi minimax với hàm mục tiêu , trong đó G cố gắng làm tăng xác suất mà được tạo ra là real data và thì cố gắng làm điều ngược lại.
GAN trong deep fakes
Ta sử dụng discriminator để phân biệt đâu là real images đâu là image được tạo ra trong quá trình training. Ta sẽ sử dụng autoencoder để tạo ra các hình ảnh cho giống thật nhất vai trò của autoencoder giống như một mạng generator. Ngoài ra decoder cũng sẽ tạo ra dữ liệu cũng như mask, vì những masks này được sinh ra trong quá trình training.
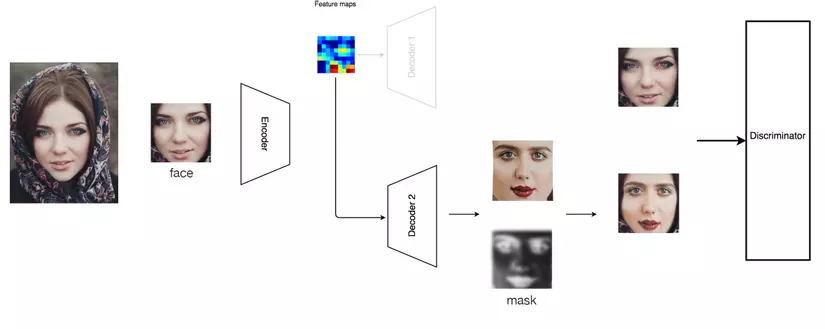
Mặc dù GAN rất mạnh mẽ, nhưng ta cần phải có rất nhiều thời gian training, và cũng sẽ mất rất nhiều thời gian cấu hình lại các thông số của GAN theo từng bộ dữ liệu.
Kết thúc
Deep fakes là một công nghệ mới và khá nguy hiểm nếu không sử dụng đúng mục đích, vấn đề về đạo đức phải đặt lên hàng đầu đối với công nghệ này, chúng nên chỉ được dùng để nghiên cứu và phát triển với mục đích tốt. Trên thực tế đừng công khai những video mà bạn dựng được với công nghệ này vì nó liên quan đến mặt pháp lý
Đây là kết quả mình train được với NVIDIA GeForce RTX 2080 Ti trong thời gian 20h với hai mặt của Hà Anh Tuấn và Hồ Ngọc Hà

Nguồn tham khảo:
All rights reserved
