
Đôi dòng về Pseudo Labeling trong Machine Learning
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Nhân một ngày đang hì hục với cái đồ án môn học mà chưa biết xử lý thế nào khi muốn cải tiến kết quả với dataset nhỏ, lại được ngồi nghe Seminar của anh Leader, mình có cảm hứng để viết bài viết này chia sẻ kiến thức cho chính bản thân cũng như mọi người về việc sử dụng pseudo labeling trong các bài toán Machine Learning.
Có thể nói việc sử dụng Pseudo Label có vai trò rất to lớn trong các vấn đề về small dataset. Hãy tưởng tượng bạn có một bài toán mà có cả dữ liệu có nhãn và không có nhãn, thì việc sử dụng pseudo label là một giải pháp tương đối ổn áp. Chúng ta bắt gặp ứng dụng của Pseudo labeling trong các app như Google photos khi nó nhận dạng các khuôn mặt trong ảnh, và tạo ra một tên gợi ý dựa trên những dữ liệu đã lưu trước đó.
Chúng ta cùng điểm qua một vài nội dung chính liên quan đến Pseudo Labeling nào!
Semi-Supervised Learning
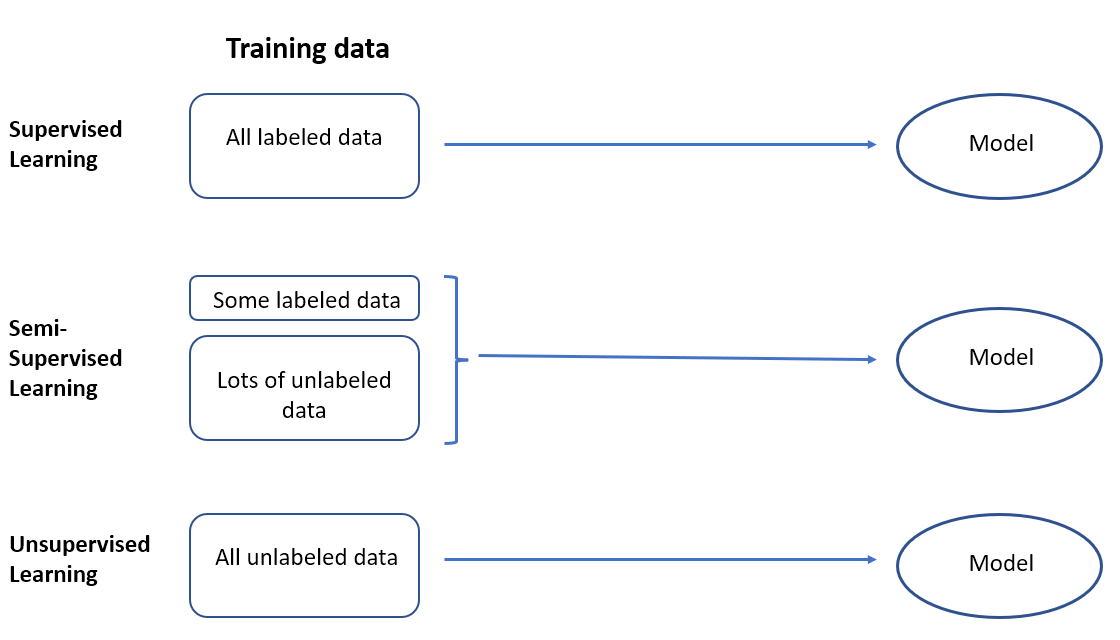
Chắc hẳn chúng ta đã quá quen thuộc với 2 cái tên Supervised Learning và Unsupervised Learning, phân biệt dễ nhất giữa chúng là dữ liệu bài toán có nhãn và không có nhãn.
Vậy Semi-Supervised Learning là gì?
Trước hết để mình dẫn dắt một chút. Yoshua Bengio's đã từng trả lời cho câu hỏi của Quora:"Why is Unsupervised Learning important? ". Yoshua Bengio's trả lời nôm na như sau: Với học có giám sát, chúng ta dạy cho máy tính "học" như con người bằng các dữ liệu có nhãn. Tuy nhiên đây không phải cách học có của con người. Ừ thì nhờ ngôn ngữ chúng ta có được các cái tên minh họa cho các sự vật hiện tượng, nhưng phần lớn những gì chúng ta quan sát ban đầu đều không được gán nhãn, ít nhất là lúc đầu.
Việc đánh nhãn dữ liệu là vô cùng tốn kém và mất thời gian, đơn giản việc ứng dụng AI trong sinh học (tinh sinh học), để có được dữ liệu có nhãn cho các bài toán chuẩn đoán, yêu cầu phải là những người bác sĩ có chuyên môn. Vậy giải pháp ở đây là gì? Hiển nhiên là một cách sao cho:
- Thuật toán Machine Learning hoạt động mà không cần nhãn dữ liệu (Unsupervised Learning).
- Tự động gán nhãn dữ liệu hoặc sử dụng số lượng lớn dữ liệu không nhãn kết hợp số lượng nhỏ dữ liệu có nhãn (Chính là Semi-Supervised Learning).
Các bài toán khi chúng ta có một lượng lớn dữ liệu X nhưng chỉ một phần trong chúng được gán nhãn được gọi là Semi-Supervised Learning. Những bài toán thuộc nhóm này nằm giữa hai nhóm Supervised và Unsupervised .
Dữ liệu không nhãn có ích gì?
- Dữ liệu có nhãn tương đối đắt và khó lấy hơn rất nhiều so với dữ liệu không có nhãn.
- Dữ liệu không có nhãn cải thiện độ chắc chắn của mô hình bằng ranh giới quyết định chính xác hơn.
Pseudo Labeling là gì?
Để hiểu qua Pseudo Labeling là gì, mời bạn đọc xem qua hình vẽ dưới đây
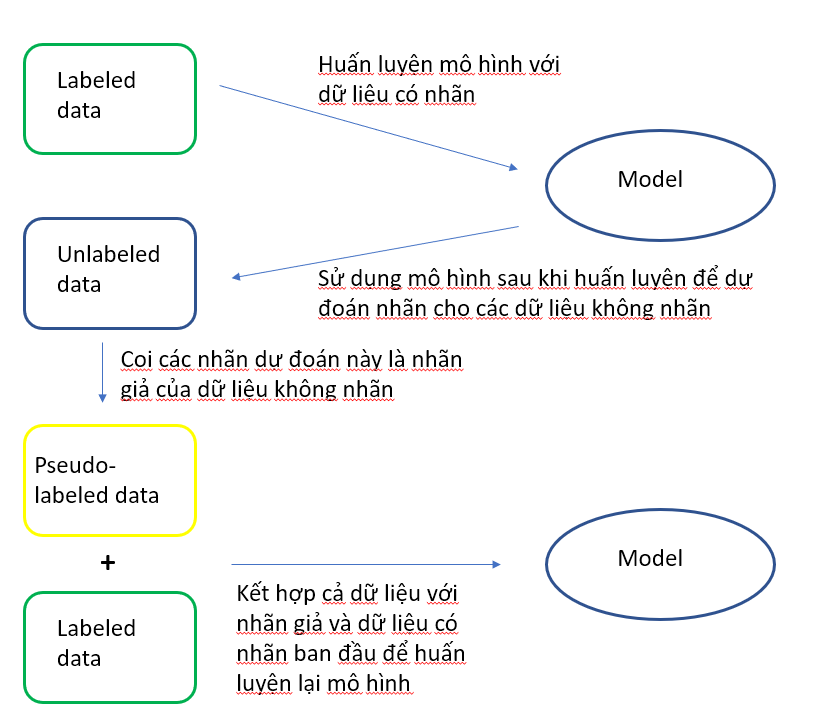
Pseudo labeling hiểu đơn giản là bạn dùng một mô hình sau khi huấn luyện với dữ liệu có nhãn để dự đoán “nhãn giả” cho các dữ liệu không nhãn, sau đó sử dụng dữ liệu có nhãn ban đầu với dữ liệu có nhãn giả vừa tạo để huấn luyện lại mô hình. Bổ sung một chút là khi tạo các nhãn giả, lọc ra những dự đoán có độ tin cậy cao (ví dụ như xác suất đáng tin cậy, cao hơn 1 ngưỡng (threshold) nào đó) Pseudo Labeling là một phương pháp hiệu quả giúp cải thiện độ chính xác của bài toán phân loại, đặc biệt là trong trường hợp ít dữ liệu. Ví dụ ở đây là một idea tác giả đã sử dụng pseudo-labeling để chiến thắng trong cuộc thi "Santander's Customer Transaction competition".
Bạn đọc có thể tham khảo thêm source code về Pseudo Labeling ví dụ ở đây, được implement bằng pytorch bởi tác giả Anirudh Shenoy
Một số lưu ý khi dùng Pseudo Labeling
- Không nên trộn lẫn dữ liệu có nhãn với dữ liệu nhãn giả, nên tách biệt dữ liệu nhãn thật và nhãn giả để ta có 2 hàm loss, với trọng số hàm loss đối với dữ liệu nhãn giả thấp hơn để làm giảm phần nào ảnh hưởng của dữ liệu nhãn giả.
- Loss_per_batch = labeled_los_batch + weight * pseudolabel_loss_batch
- Bạn cũng có thể trộn lẫn 2 loại dữ liệu này để xem kết quả thế nào, sau cùng chúng ta sẽ đánh giá mô hình dự trên tập test
Tóm lại
- Theo cá nhân mình thấy thì đay là một kỹ thuật tương đối đơn giản mà hiệu quả trong 1 số trường hợp lại tương đối cao, đặhc biệt trong các bài toán phân loại mà dữ liệu thì ít (phân loại 2,3 nhãn thì đẹp). Cá nhân mình cũng đang thử trong đồ án môn học thử xem, có gì mình sẽ cập nhật kết quả cũng như nội dung đồ án trong các bài viết sau nhé. Cảm ơn mọi người đã đọc đến những dòng cuối cùng này. Cho mình một upvote và một vài comment để mình có động lực chia sẻ thêm nhé ^^
References
All rights reserved
