
GraphRAG - Một sự nâng cấp mới của RAG truyền thống chăng?
Mở đầu
Chắc hẳn anh em làm về AI không còn quá mới lạ về RAG (Retrieval Augmented generation) nữa rồi. Với sự rầm rộ của GPT của OpenAI thì các ông lớn như Microsoft cũng bắt tay để tạo ra các dịch vụ như Azure OpenAI. Các dự án về chatbot xây dựng theo hệ thống RAG cũng ngày một nhiều. Diễn đàn, LinkedIn, research paper, workshop về RAG đang rất nhiều bởi tính ứng dụng cao của nó.
Bản thân mình cũng làm vài dự án về RAG, mà đọc lại mới thấy có mỗi một bài về Azure AI Search thì thấy cũng hơi thiếu, mà RAG thì các trang/bài viết cũng có tương đối nhiều rồi. Nhân một cơ may được đọc và nghiên cứu về GraphRAG, hôm nay mình xin phép trao đổi một chút tổng quan về phương pháp này, chi tiết cụ thể sâu xin phép chia sẻ ở các bài viết sau.
GraphRAG là gì?
-
Nhắc lại một chút về RAG - một kỹ thuật để cải thiện đầu ra của các mô hình ngôn ngữ lớn (LLM) bằng cách sử dụng thông tin từ tài liệu cụ thể để nó có thể trả lời tốt trong phạm vi cụ thể đó. Kỹ thuật này là một phần quan trọng của hầu hết các công cụ dựa trên LLM và phần lớn các phương pháp RAG sử dụng similarity vector làm kỹ thuật tìm kiếm (search engine), hướng tiếp cận này được gọi là Baseline RAG.
-
Các kỹ thuật RAG đã cho thấy triển vọng trong việc giúp các LLM lý luận về các tập dữ liệu riêng tư - dữ liệu mà LLM không được đào tạo và chưa bao giờ thấy trước đó, chẳng hạn như nghiên cứu độc quyền, tài liệu kinh doanh hoặc giao tiếp của một doanh nghiệp. Baseline RAG được tạo ra để giúp giải quyết vấn đề này, nhưng khi triển khai sẽ có những tình huống mà Baseline RAG hoạt động rất kém:
- Baseline RAG gặp khó khăn khi nối kết các điểm thông tin. Điều này xảy ra khi trả lời một câu hỏi đòi hỏi phải đi qua các mảnh thông tin khác nhau, đôi khi thông tin sẽ khá rắc rối, sau đó được tổng hợp lại. Và đôi khi do sự phức tạp hoặc dư thừa từ dữ liệu đưa vào mà LLM trả lời sai.
- Baseline RAG hoạt động rất kém (chứ không muốn nói là fail) khi được yêu cầu hiểu một cách toàn diện một thông tin nào đó trên các bộ sưu tập dữ liệu lớn hoặc thậm chí trên các tài liệu lớn. Ví dụ đưa cho nó một tập lớn các điều lệ công ty và bảo nó tốm tắt tất cả điều lệ công ty, thì baseline RAG xịt keo ngay
-
Để giải quyết vấn đề này, GraphRAG ra đời - 1 phương pháp mới của Microsoft Research. GraphRAG, sử dụng các LLM để tạo ra một đồ thị tri thức dựa trên một tập hợp đầu vào. Hiểu đơn giản thì thay vì lưu trữ các chunk text và embedding nó để search, thì GraphRAG biểu diễn và lưu trữ dưới dạng đồ thị, cùng các kỹ thuật nâng cao về gom nhóm, tìm kiếm để đưa ra câu trả lời tối ưu nhất, khắc phục được 2 nhược điểm bên trên. GraphRAG cho thấy sự cải thiện đáng kể, vượt trội hơn so với các phương pháp khác đã được áp dụng trước đó đối với các tập dữ liệu riêng tư. Paper các bạn có thể tham khảo tại đây
GraphRAG process
Để nói về quy trình của GraphRAG, chúng ta sẽ điểm qua 2 stage chính sau:
- Index
- Query
Index
Extract entities, relationships, ...
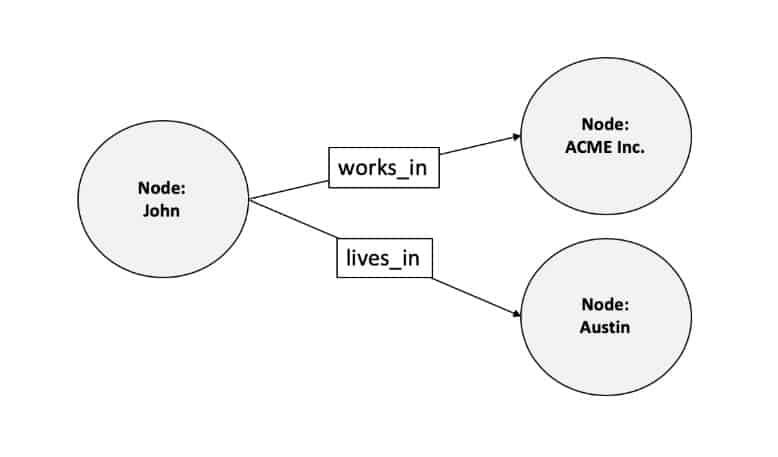
- Như mọi người từng học môn cấu trúc dữ liệu giải thuật, thì kiến trúc đồ thị là một kiến thức không thể thiếu với những bài toán nan giải nhưng đây cũng là phần kiến thức có tính áp dụng vô cùng cao. Mình đã từng thấy sự xuất hiện của nó trong các môn liên quan đến mạng máy tính, cấp phát IP, ... Trong đồ thị thì có 2 thành phần không thể thiếu, đó là Node và Edge.
- Quá trình Index của GraphRAG với mục tiêu lưu chung là lưu trữ thông tin để phục vụ Query, và việc lưu trữ này dưới dạng đồ thị
- Dữ liệu được chia thành các text units (chunks) với size cố định, sau đó sẽ được trích xuất entities, relationships, ...
- Theo như đội nghiên cứu của Microsoft chỉ ra và mình cũng có vọc source code của họ, thì việc trích xuất entities, relationships này được thực hiện bởi LLM, cụ thể họ thiết kế sao, chiến lược prompt thế nào thì chúng ta sẽ đi sâu vào lần khác nhé
- Các entities sẽ là các node của đồ thị, còn relationships thì chính là các cạnh của đồ thị
- Bên cạnh đó còn một vài kỹ thuật xử lý nữa nhưng mình chưa đi sâu như embedding node, trích xuất 1 vài thông tin quan trọng khác, ...
Comunity detection
- Một phần khác đặc biệt của GraphRAG của Microsoft mà mình muốn nhắc đến
- Không dừng lại ở việc chỉ dựng lên đồ thị với các entities và relationships, đồ thị này còn được đưa qua 1 công đoạn mang tên Comunity Detection. Nói nôm na thì sẽ gom nhóm các node thành các cộng đồng chung dựa vào thuật toán Leiden
- Điểm qua mọt chút thuật toán Leiden nhé, xuất phát từ hàm Modularity
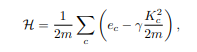
Trong đó là số cạnh của comunity , là tổng số cạnh của đồ thị, là tổng bậc của các nút trong đồ thị, gama > 0, gama càng cao thì càng có nhiều comunities, và ngược lại. Xin phép không bàn về công thức này và mục đích của nó vì mình cũng chưa có tgian ngâm cứu.
-
Phương pháp chung:
- Ban đầu mỗi node là 1 comunity
- Xét 1 node, tìm các cộng đồng mà khi di chuyển 1 node từ cộng đồng hiện tại sang cộng đồng khác thì giá trị hàm modularity tăng lên
- Chọn cộng đồng mà node đó đi tới giúp modularity tăng nhiều nhất, chuyển node đó sang cộng đồng đó
- Sau khi duyệt hết 1 lượt, chúng ta đã có một vài comunities được tạo thành, lúc này các comunities sẽ đóng vai trò là các node, và làm lại các bước trên
- Việc này lặp lại cho tới khi việc di chuyển không làm modularity tăng lên nữa
-
Tất nhiên về kỹ thuật di chuyển node hoặc duyệt comunity còn phức tạp và nhiều cải tiến về tốc độ và độ chính xác hơn nhưng bên trên mình trình bày ý tưởng chung nhất để các bạn nắm được thui.
-
Và từ đây chúng ta đã có đồ thị cùng các communities, các bạn có thể xem hình minh họa dưới đây
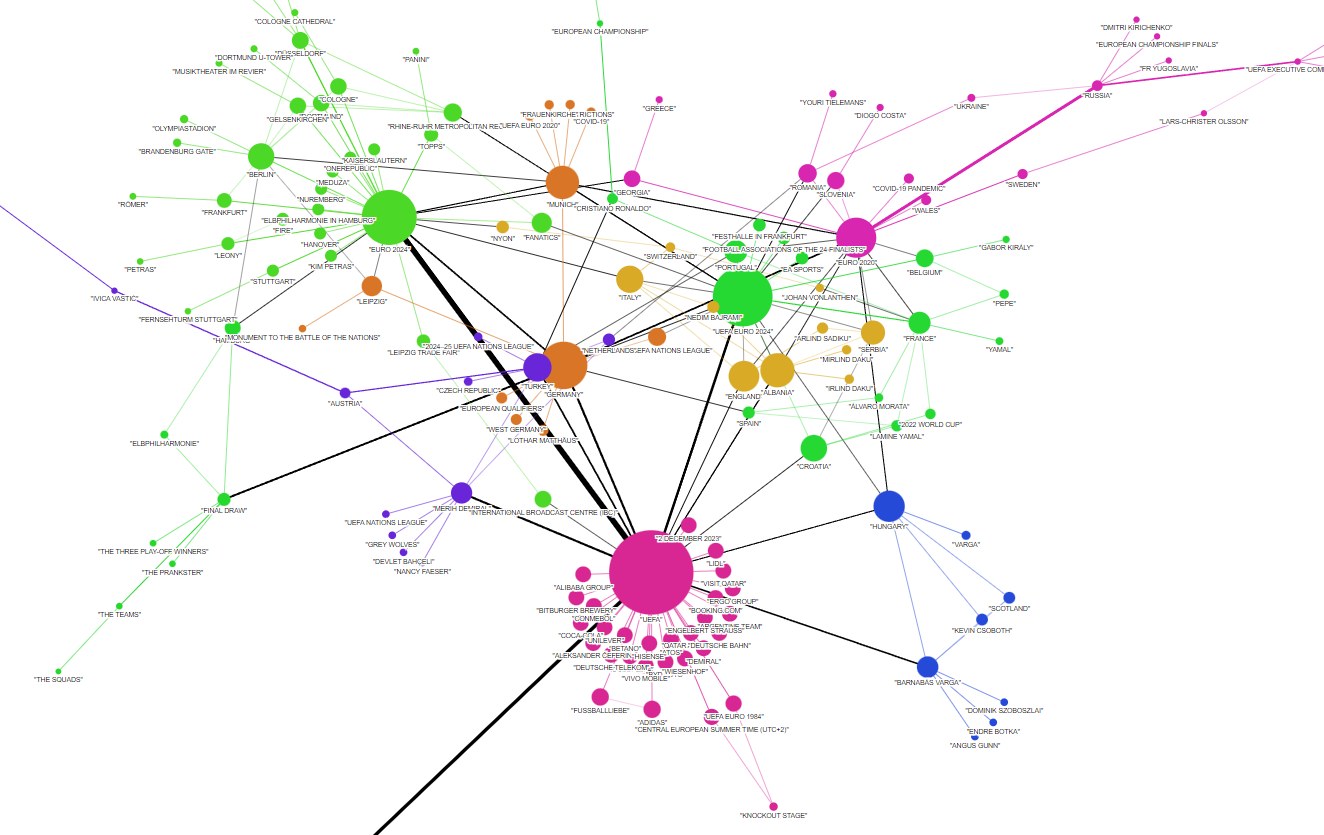
- Các comunities cũng được tạo summary cho chúng để cho việc query
- Sau cùng, chúng ta có một Knowledge graph
Query
Ok vậy index xong thì tới query, việc build các Comunity sẽ dùng cho Global Search và đồ thị thì Local Search, cùng điểm qua 2 phương pháp search này nhé
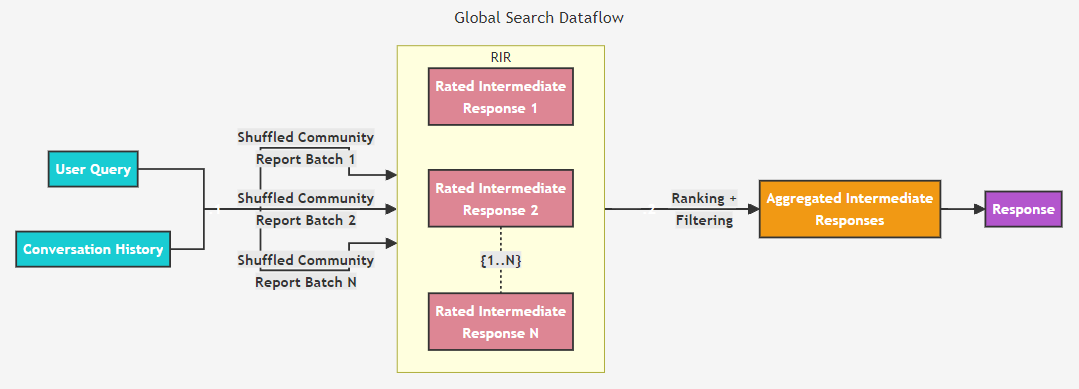
Global search
- Kỹ thuật này phù hợp với các câu hỏi mang tính toàn diện, tổng quan về dữ liệu, những câu hỏi mang tính khái quát chung mà RAG truyền thống có khả năng fail cao
- Nhờ vào việc gom nhóm các entities và relationships vào các community, thì lúc này ta sẽ dựa vào mô tả của các communities đó
- Được xử lý theo cơ chế Map-Reduce
- Map:
- Các community summaries được shuffle và chia thành các chunks với fix token size
- Dùng LLM sinh ra mỗi câu trả lời cho 1 chunk cùng với score (0-100) (tùy bài toán)
- Reduce:
- Sort các câu trả lời theo score
- Đưa vào LLM các câu trả lời này cho tới khi limi token để sinh ra global answer (target)
- Map:
Local search
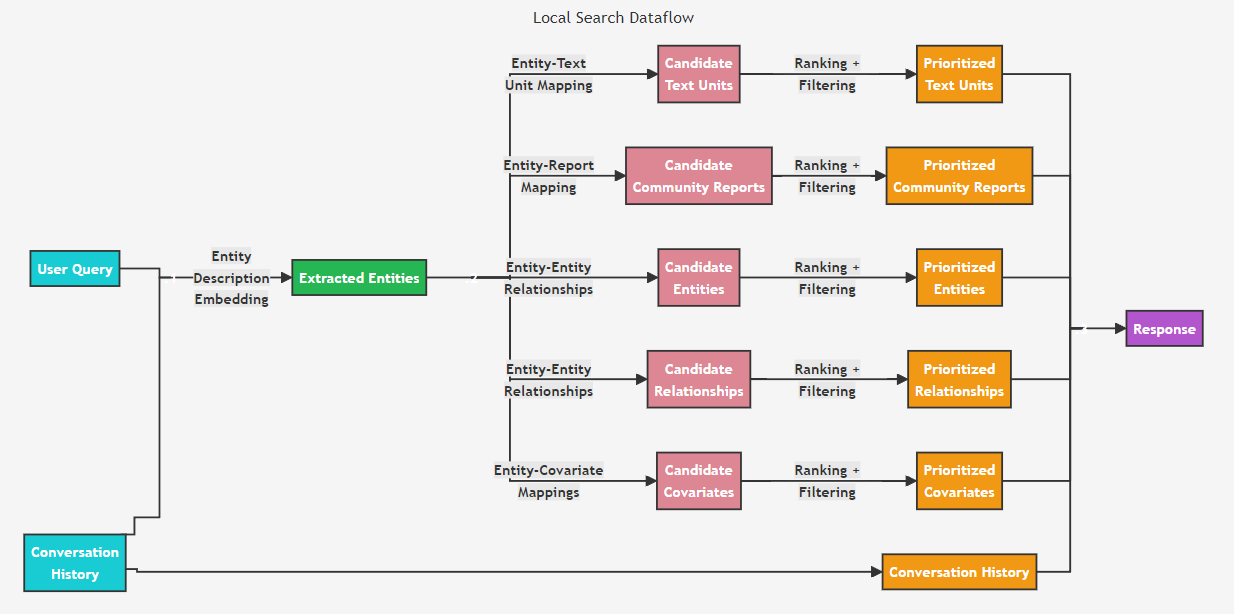
- Kỹ thuật này phù hợp với các câu hỏi sâu về một chủ đề nào đó, phù hợp để suy luận sâu hơn về các thực thể và các mối quan hệ láng giềng
- Cách thức hoạt động
- Xác định thực thể liên quan: Local Search xác định một tập hợp các thực thể từ knowledge graph có liên quan về mặt ngữ nghĩa với query của người dùng. Các thực thể này đóng vai trò là endpoint vào knowledge graph, cho phép trích xuất thêm các chi tiết liên quan như các entities được kết nối/liên quan, relationships, biến cố của thực thể và summary reports.
- Trích xuất thông tin: Ngoài ra, Local Search cũng trích xuất các đoạn văn bản có liên quan từ các tài liệu đầu vào thô được liên kết với cácentities đã xác định.
- Ưu tiên và lọc: Các nguồn dữ liệu ứng viên này sau đó được ưu tiên và lọc để phù hợp với một cửa sổ ngữ cảnh đơn lẻ có kích thước được xác định trước, được sử dụng để tạo phản hồi cho truy vấn của người dùng.
Kết luận
Bài viết này mình không đi sâu vào từng phần, xin phép để dành các bài viết sau. Mình thấy đây là một hướng tiếp cận khá hay cho các bài toán RAG, mình cũng đã thử và bất ngờ với cách trả lời chi tiết đầy đủ của nó, mặc dù hơi lâu và tốn kém tiền =))) do repo vẫn ở dạng research chứ đưa vào product thì ... Thời gian tới mình nghiên cứu kỹ hơn và triển khai, mình sẽ ra thêm các bài viết khác. Cảm ơn mọi người đã đọc!
Tài liệu tham khảo
All rights reserved
