Phân loại cảm xúc người trong ảnh qua khuôn mặt và bối cảnh
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu bài toán
Nhận diện các thuộc tính khuôn mặt (giới tính, độ tuổi, cảm xúc...) là bài toán có nhiều ứng dụng quan trọng trong thực tế. Một ví dụ có thể dẫn đến nhu cầu về nhận diện các thuộc tính của khuôn mặt đó là bộ lọc của một kho ảnh, qua đó giúp người dùng có thể tìm kiếm các hình ảnh theo chủ đề mong muốn dễ dàng hơn.
Cảm xúc con người trong thực tế không chỉ biểu hiện qua khuôn mặt mà còn biểu hiện rất nhiều vào cử chỉ, hành động của người đó. Ví dụ có thể thấy trong thực tế, nhiều thường không có biểu cảm khuôn mặt mãnh mẽ nhưng nhìn tổng thể vẫn có thể biết được người đó vui, buồn, giận dữ, Do đó để cải thiện mô hình nhận diện khuôn mặt, ở đây sẽ trình bày mô hình một mô hình có sử dụng dữ liệu bối cảnh (context) là mô hình CAER và mô hình cải tiến sử dụng backbone của EfficientNet và ResNeSt.
Dữ liệu
Về việc tiền xử lý, đầu tiên mỗi ảnh sẽ được cho chạy qua mô hình RetinaFace để có được tọa độ bounding box và năm landmark của khuôn mặt, sau đó tùy vào mô hình sử dụng mà sẽ cần căn chỉnh (align) khuôn mặt dựa vào năm landmark đã có. Dù việc sử dụng RetinaFace với ngưỡng confidence cao đã tránh lẫn những vật thể không mong muốn nhưng cuối cùng cũng cần một bước manual review để hoàn thiện bộ dữ liệu.
Riêng về dữ liệu cho bài toán nhóm tuổi, bài toán này có hai cách tiếp cận là dự đoán chính xác (tương tự bài toán hồi quy) và dự đoán một số ít nhóm (bài toán phân lớp). Vì không có dữ liệu chính xác về tuổi nên để có được 6 nhóm tuổi trên, cần nghỉên cứu rất nhiều về quy tắc để ra được một bộ dữ liệu hoàn chỉnh.
Sau bước tiền xử lý, ta có hai bộ dữ liệu khác nhau của (Vì là bản quyền của công ty nên không thể public). Bộ thứ nhất (mình gọi là bộ V1) bao gồm 20000 ảnh cho tập train và 2500 ảnh cho tập val. Bộ thứ hai (Mình gọi là bộ V4) bao gồm 130000 ảnh cho tập train và 57000 ảnh cho tập validation (riêng với dữ liệu age là 24000 ảnh). Đánh giá sơ bộ thì bộ V1 khá balance giữa các class và sạch (do được mannual review), trong khi đó bộ V4 không được balance, có noise tuy nhiên lại gần với thực tế hơn. Mỗi ảnh của dữ liệu bao gồm người nhãn kèm theo bao gồm
- 5 loại cảm xúc: smile, sad, angry, anxiety và surprise.
- 6 nhóm tuổi: baby, child, ten-twenty, thirdty-forty, fifty, senior.
Một số mô hình và nghiên cứu liên quan
Context-Aware Emotion Recognition Networks (CAER)
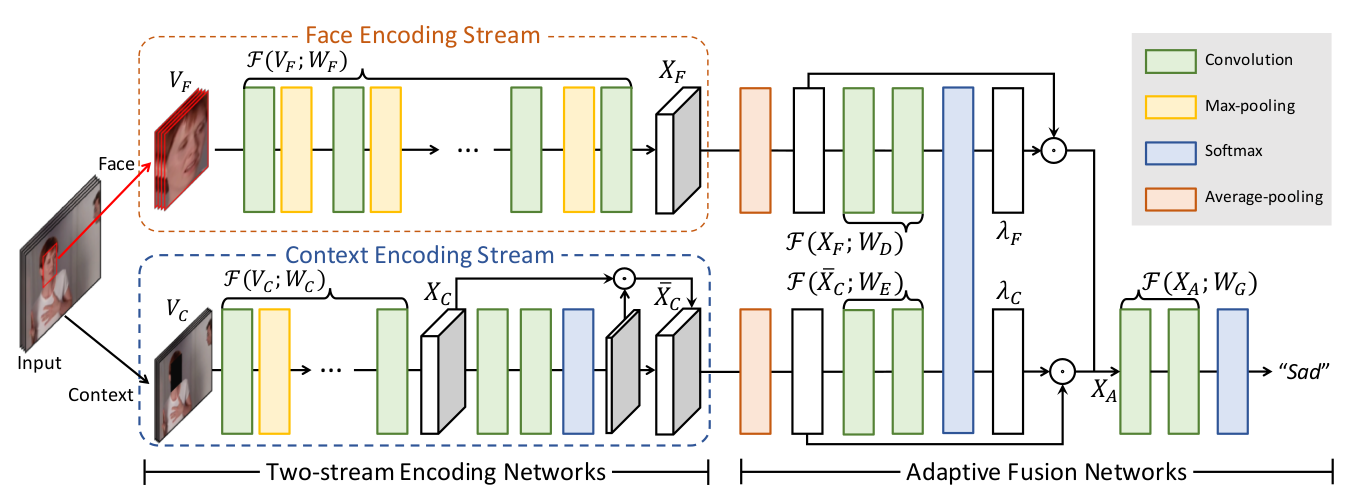
Mô hình Context-Aware Emotion Recognition Networks, gọi tắt là CAER được giới thiệu vào năm 2019 chi tiết bài báo xem tại đây, với ý tưởng chính là sử dụng thêm dữ liệu về bối cảnh (context) để cải thiện dự đoán của mô hình chỉ sử dụng dữ liệu mặt. Với mô hình CAER, việc căn chỉnh khuôn mặt là không cần thiết. Mô hình CAER sử dụng hai nhánh con riêng biệt, mỗi nhánh sẽ nhận đầu vào là mặt và bối cảnh (là hình ảnh ban đầu nhưng đã che mặt). Mỗi nhánh sẽ trích xuất các đặc trưng sau đó sử dụng adaptive fusion networks để ghép nối các đặc trưng và cho ra kết quả phân loại cuối cùng.
CAER hoạt động tương đối đơn giản, với phần trích xuất đặc trưng, cả hai nhánh đều sử dụng chung một Fully Convolutional Network để trích xuất đặc trưng. Riêng với nhánh context được bổ sung một mô-đun attention giúp mô hình học thêm những vùng cần chú ý trên ảnh. Sau khi hai nhánh face và context trích xuất được đặc trưng và , chúng sẽ được đưa qua mô-đun gọi là Adaptive Fusion Net nhằm kết hợp các đặc trưng này lại để mô hình đưa ra dự đoán cuối cùng. Về nguyên lý hoạt động, Adaptive Fusion Net sẽ kết hợp các đặc trưng bằng phương pháp concatenation (concat), tuy nhiên mô hình không concat một các naive mà sẽ học thêm các bộ trọng số và rồi nhân vào các , trước khi tiến hành concat. Việc này nhằm mục đích đánh giá đặc trưng về face hay context có ý nghĩa quan trọng hơn cho dự đoán cuối cùng.
EfficientNet
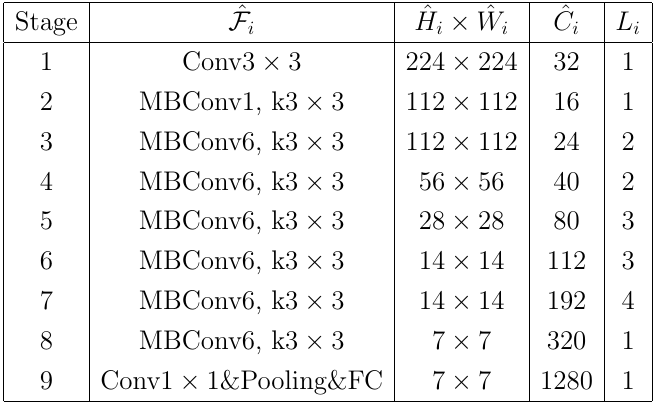
EfficientNet là một họ các mô hình được giới thiệu vào năm 2019 trong bài báo EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks với ý tưởng chính là việc thay đổi kích thước mô hình. Ở đây mình không giải thích chi tiết về cơ sở lý thuyết mà chỉ đưa ra mô hình cơ sở EfficientNet B0 sẽ được sử dụng trong phần sau. Mô hình EfficientNet B0 là stacking của 9 lớp được cho trong bảng sau, trong đó MBConv là khối Inverted Residual của mô hình MobileNetv2
EfficientNet B0 đã được sử dụng trong một bài toán tương tự về nhận diện các thuộc tính khuôn mặt (tuổi, cảm xúc...) trong bài báo Facial expression and attributes recognition based on multi-task learning of lightweight neural networks như một mô-đun Face Recognition, do đó mình sẽ dùng EfficientNet cho nhánh face ở phần mô hình đề xuất.
ResNeSt
Mô hình ResNet là một mô hình rất mạnh mẽ, riêng trong lĩnh vực Thị giác máy tính có thể coi nó là xương sống cho rất nhiều mô hình. Tuy nhiên với sự phát triển của bài toán thực tế ngày càng khó hơn, các mô hình ResNet cổ điển cũng đã bộc lộ những hạn chế và việc đi tìm những cải tiến cho ResNet là việc làm tất yếu. Một hướng đi cho việc phát triển các khối residual là thêm cơ chế attention như SK-Net, SE-Net (Squeeze and Excitation) hay ResNeSt. ResNeSt được giới thiệu vào năm 2020 trong bài báo ResNeSt: Split-Attention Networks ý tưởng cho một khối ResNeSt đến từ việc kết hợp cardinality của ResNext và Attention của khối SE-Net để cho ra công thức về mô hình Split-Attention. ResNeSt là mô hình gồm tập hợp các khối Split-Attention được xếp lại với nhau tương tự như cách mà ResNet xếp cái khối residual lại.
 Thực tế, ResNeSt đã được chứng minh sức mạnh trong một số bài toán liên quan đến gợi ý tag cho ảnh và đạt kết quả khá tốt, đó là lý do mình lựa chọn ResNeSt cho nhánh context trong mô hình đề xuất ở phần sau.
Thực tế, ResNeSt đã được chứng minh sức mạnh trong một số bài toán liên quan đến gợi ý tag cho ảnh và đạt kết quả khá tốt, đó là lý do mình lựa chọn ResNeSt cho nhánh context trong mô hình đề xuất ở phần sau.
Mô hình đề xuất
Mô hình CAER với thiết kế tương đối đơn giản nhưng lại cho độ chính xác khá tốt, tuy nhiên, backbone mỗi nhánh của CAER lại đơn giản nên chưa đủ mạnh mẽ cho những bài toán yêu cầu độ chính xác cao. Từ ý tưởng của CAER, mình xây dựng một mô hình sử dụng EfficientNet B0 cho dữ liệu mặt và ResNeSt cho dữ liệu bối cảnh. Ngoài ra thay vì sử dụng phép concat cho việc kết hợp hai nhánh sử dụng dữ liệu mặt và bối cảnh, mô hình cải tiến sử dụng một mạng riêng gọi là GatingNet (nhánh ở giữa trong hình vẽ dưới). GatingNet sẽ nhận đầu vào là ảnh gốc ban đầu, gồm cả mặt và bối cảnh. GatingNet có nhiệm vụ quyết định xem với từng bức ảnh, đặc trưng về mặt hay đặc trưng về bối cảnh sẽ quan trọng hơn và từ đó sẽ điều chỉnh trọng số đầu ra mỗi nhánh (đây là lý do cho việc sử dụng Sigmoid thay vì Softmax) trước khi cho kết quả cuối cùng. Ngoài ra, do dữ liệu đầu vào của GatingNet khá giống với dữ liệu của nhánh trích xuất đặc trưng bối cảnh (do bối cảnh chỉ là ảnh gốc che mặt), nên GatingNet sẽ sử dụng chung backbone ResNeSt50 giống như cho bối cảnh.
 Mô hình được huấn luyện qua 3 bước
Mô hình được huấn luyện qua 3 bước
- Bước 1: Bước này chỉ huấn luyện nhánh face, freeze 2 nhánh còn lại.
- Bước 2: Bước này chỉ huấn luyện nhánh context, freeze 2 nhánh còn lại.
- Bước 3: Huấn luyện GatingNet, vì dữ liệu của GatingNet khá tương đồng với bối cảnh nên dùng luôn weights đã luyện cho context ở Bước 2. Ngoài ra, để tránh weights bị phá, ở bước này chỉ huấn luyện bộ phân lớp của GatingNet trong khi phần ResNeSt và Attention được freeze.
Ngoài ra về phương pháp tối ưu, trải nghiệm thực tế cho thấy nếu dùng SAM thì cho kết quả tốt hơn phương pháp Adam khoảng 1% đến 1.5% accuracy.
Kết quả
Kết quả mô hình cho bài toán phân loại cảm xúc được cho ở bảng dưới
 Có thể thấy, việc sử dụng mô hình phức tạp hơn đã cho kết quả tổt hơn hẳn CAER, riêng chỉ với đặc trưng face, trên bộ V1 mô hình đã "outplay" CAER. Việc sử dụng thêm dữ liệu context đã giúp cải thiện mô hình, có thể thấy rõ trên bộ V4 cải thiện gần 3% accuracy. Ngoài ra, GatingNet khá nặng nên mình đã thử thay thế nó bằng Adaptive Fusion Net và kết hợp 2 nhánh tương tự của CAER, tuy nhiên kết quả đạt được trên bộ V1 tỏ ra đuối hơn so với GatingNet. Điều này củng cố việc sử dụng GatingNet mạnh mẽ hơn với cách kết hợp như mô hình baseline.
Có thể thấy, việc sử dụng mô hình phức tạp hơn đã cho kết quả tổt hơn hẳn CAER, riêng chỉ với đặc trưng face, trên bộ V1 mô hình đã "outplay" CAER. Việc sử dụng thêm dữ liệu context đã giúp cải thiện mô hình, có thể thấy rõ trên bộ V4 cải thiện gần 3% accuracy. Ngoài ra, GatingNet khá nặng nên mình đã thử thay thế nó bằng Adaptive Fusion Net và kết hợp 2 nhánh tương tự của CAER, tuy nhiên kết quả đạt được trên bộ V1 tỏ ra đuối hơn so với GatingNet. Điều này củng cố việc sử dụng GatingNet mạnh mẽ hơn với cách kết hợp như mô hình baseline.
Tiếp theo mình có đem mô hình này cho bài toán về tuổi, tuy nhiên việc thêm dữ liệu context không cải thiện nhiều kết quả. Điều này có thể dễ hiểu vì đặc trưng về bối cảnh không nói lên nhiều về tuổi tác như bài toán về cảm xúc. Kết quả cho bài toán về tuổi cho ở bên dưới

Tài liệu tham khảo
All rights reserved
