
TransformerXL - Leverage Transformer For Language Modeling
Bài đăng này đã không được cập nhật trong 5 năm
Transformer là một mô hình được sử dụng rất phổ biến trong Natural Language Processing hiện nay, cũng bởi vì sự mạnh mẽ của nó trong việc song song hóa tính toán và khả năng capture được phụ thuộc xa - long range dependency nhờ cơ chế Self Attention. Tuy nhiên, dù có những ưu điểm tuyệt vời như vậy nhưng Transformer bản thân nó cũng tồn tại những giới hạn nhất định, trong bài viết này, tôi sẽ nêu ra các hạn chế của mô hình Vanilla Transformer trong nhiệm vụ mô hình hóa ngôn ngữ - Language Modeling và giới thiệu về phiên bản nâng cấp hơn của "người máy biến hình" - TransfomerXL mà nhớ đó chúng ta có thể giải quyết được một vài vấn đề mà mô hình Transformer thông thường gặp phải.
1. Problems of Vanilla Transformer:
Nếu các bạn còn nhớ thì RNN chỉ tính toán hidden state của một token tại một time step nhất định và sử dụng hidden state đó cho việc tính toán hidden state của token sau đó tại time step tiếp theo - việc này khiến việc huấn luyện mô hình trở nên chậm chạp tuy nhiên nó giúp RNN có thể handle được các chuỗi token có độ dài bất kỳ mà không gặp phải bất cứ vấn đề gì. Ngược lại, Transfomer có khả năng song song hóa quá trình tính toán, hidden state của tất cả các token cùng một thời điểm thông qua cơ chế Self Attention, tuy nhiên để làm được điều này ta cần phải Batch Training tức là đưa các chuỗi trong cùng một batch về cùng độ dài cố định, ở đây tôi gọi là . i.e các chuỗi token có độ dài lớn hơn sẽ phải được loại bỏ bớt. Trong context của Language Modeling điều này dẫn tới các hệ lụy sau đây.
- Limited Context-dependency: Do mô hình chỉ có thể nhận vào một chuỗi có độ dài tối đa token mỗi lần cho nên nó sẽ không thể capture được long range dependency có độ dài vượt qua giới hạn này.
- Context Fragmentation: Một đoạn văn bản dài khi đưa qua transformer sẽ được phân đoạn thành nhiều mảnh - segments ( có thể không tương ứng với giới hạn các câu trong văn bản ) và được huấn luyện độc lập. Điều này dẫn tới việc chúng ta không hề có ngữ cảnh cho các token đầu tiên ở mỗi segment và ở giữa những segment với nhau.

Figure 1: Fixed-length Context In Transformer.
2. TransformerXL:
Để giải quyết được các nhược điểm nêu trên, Dai et al., 2019 đề xuất các cải tiến cho mô hình Vanilla Transformer bao gồm Segment-level Recurrence Mechanism và Relative Positional Encodings cho phép mô hình có thể học được ngữ cảnh vượt ra ngoài giới hạn cố định và đặt tên cho nó là TransformerXL.
2.1. Segment-level Recurrence Mechanism:
Cơ chế này cho phép TransformerXL có thể học được long-range dependency nhờ thông tin của các segment phía trước. Trong quá trình trình huấn luyện, hidden state của segment phía trước sẽ được cố định và lưu lại như nguồn thông tin phụ trợ cho việc tính toán các hidden state cho segment phía sau. Cụ thể hơn, khi TransformerXL thực hiện tính toán cho segment hiện tại, mỗi layer của nó sẽ nhận vào 2 luồng thông tin sau.
- Đầu ra của layer trước đó của segment hiện tại ta đang tính toán ( màu xám trên hình).
- Đầu ra của layer trước đó của segment phía trước ( màu xanh trên hình ) - thứ sẽ cho phép mô hình học được long-range dependency.

Figure 2: Segment-level Recurrence Mechanism In TransformerXL.
Sau đó 2 luồng thông tin trên sẽ được tổng hợp lại rồi sử dụng để tính ma trận Key và Value cho hidden state của layer hiện tại.
Cơ chế này giúp độ dài của long-range dependency mà mô hình có thể học được sẽ tăng lần, với là số lượng layer có trong mạng. Ngoài ra điều này cho phép các segment phía sau có thể sử dụng thông tin ngữ cảnh của các segment phía trước, qua đó giải quyết được vấn đề Context Fragmentation.
2.2. Relative Positional Encodings:
Thực hiện trực tiếp Segment-level Recurrence Mechanism lên Vanilla Transformer sẽ không thể hoạt động được do Positional Encoding của mỗi segment là riêng biệt i.e các token ở cùng một vị trí ở mỗi segment sẽ có Positional Encoding là giống nhau. Ví dụ như token đầu tiên ở segment thứ 1 sẽ có positional encoding giống với token đầu tiên ở segment thứ 2, mặc dù vị trí của chúng về bản chất là khác nhau. Sự nhầm lẫn này có thể gây những ảnh hướng không tốt tới hiệu suất mô hình.
Bài báo đề xuất thêm Relative Positional Encodings, giúp mã hóa thông tin khoảng cách tương đối giữa mỗi token chứ không phải vị trí tuyệt đối của chúng. Attention Score của mỗi layer sẽ được decompose thành 4 thành phần sau đây.
- Context Weight : phần Attention score không có bất cứ thông tin nào về vị trí của mỗi token.
- Content Dependent Positional Bias: là phần thông tin của position liên quan tới Query thứ . Sử dụng một hàm Sinusoidal làm Lookup Table nhận vào là khoảng cách giữa các token.
- Learned Global Content Bias: Một vector trọng số có thể học, được thêm vào cho phép mô hình học được mức độ quan trọng của token Key thứ .
- Global Positional Bias: Một vector trọng số có thể học được thêm vào để cho phép mô hình có thể học được tầm quan trọng dựa trên khoảng cách giữa mỗi token.

Figure 3: 4 Components In TransformerXL's Attention Score
3. Results:
TransformerXL đạt được kết quả SOTA ( State of The Art ) trên nhiều datasets benchmarks về Language Modeling trên cả mức word-level và character-level.
- Trên WikiText-103, một bộ dataset lớn về Language Modeling ở mức word-level, TransformerXL (18 layers) đạt perplexity bằng 18.3 so với previous SOTA là Baevski & Auli đạt 20.5
- Trên EnWiki8, một bộ dataset ở mức character level, TransformerXL (12 layers) đạt 1.06 bpc (bits per character) sánh ngang với Al-Rfou và với 24 layers TransofmerXL đạt SOTA là 0.99 bpc
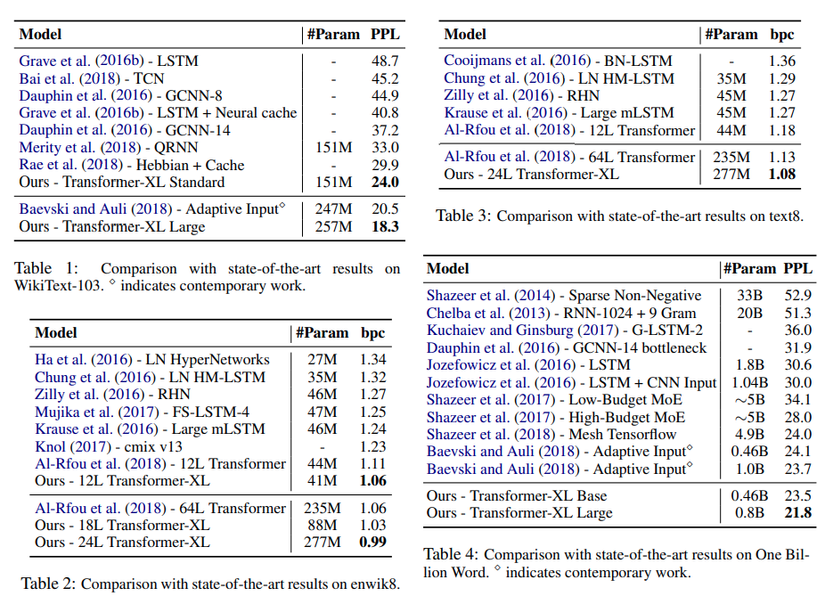
Figure 4: SOTA results on several datasets benchmarks of TransformerXL.
Ngoài ra, các bằng chứng thực nghiệm cho thấy, TransformerXL có khả năng học được long-range dependency dài hơn RNN và so với Vanilla Transformer và thu được perplexity tốt hơn rất nhiều.
4. Conclusion:
Với 2 cơ chế mới là Segment-level Recurrence Mechanism và Relative Positional Encodings, TransformerXL đã giải quyết được các vấn đề gặp phải trong mô hình Vanillar Transformer là Limited Context-dependency và Context Fragmentation thứ giới hạn khả năng capture long-range dependency. Ngoài ra các cải tiến này còn giúp TransformerXL đạt được kết quả SOTA trên nhiều datasets benchmarks về Languge Modeling, các ứng dụng của nó còn được sử dụng cả trong SOTA pretrained language model XLNET, tôi sẽ đề cập tới vào một dịp khác.
5. References:
https://arxiv.org/pdf/1901.02860.pdf
https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html
All rights reserved
