
ETL vs ELT không đơn giản chỉ là LT và TL?
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu
Một trong những việc mà những người làm việc với Data cần làm, đặc biệt là Data Engineering, cần quan tâm đó là việc trích xuất dữ liệu từ nhiều nguồn, đổ về một chỗ (Data Warehouse, Data Lake, ...), để lưu trữ và phân tích dữ liệu. Chúng ta có thể gọi nó là Data Pipeline. Để hiểu hơn về nó, trước hết chúng ta cùng đi trao đổi về ETL và ELT nào. Lẹt doit
E-T-L là gì đã?
Extract
- Khai thác dữ liệu là giai đoạn đầu tiên của quy trình ETL/ELT, trong đó dữ liệu được thu thập từ nhiều các hệ thống nguồn khác nhau.
- Dữ liệu có thể hoàn toàn thô, chẳng hạn như dữ liệu cảm biến từ các thiết bị IoT hoặc có thể là dữ liệu phi cấu trúc từ các tài liệu y tế, dữ được quét hoặc email của công ty, nó có thể là dữ liệu truyền dữ liệu đến từ mạng truyền thông xã hội hoặc gần các giao dịch mua/bán trên thị trường chứng khoán theo thời gian thực hoặc có thể đến từ cơ sở dữ liệu doanh nghiệp và kho dữ liệu hiện có.
- Có nhiều kỹ thuật trích xuất dữ liệu, tùy thuộc vào loại nguồn dữ liệu và mục đích sử dụng dữ liệu
- OCR dùng để trích xuất các văn bản được quét từ tài liệu ảnh để có thể đọc được trên máy tính
- ADC có thể số hóa các tín hiệu và bản ghi âm thanh tương tự
- CCD chụp và số hóa hình ảnh
- Cookie: ghi nhật ký và theo dõi hành vi người dùng trên internet
- Web scraping
- APIs
- Ngôn ngữ SQL để truy vấn cơ sở dữ liệu quan hệ và NoSQL để truy vấn tài liệu, khóa-giá trị, biểu đồ
- Các thiết bị hình ảnh y tế và cảm biến sinh trắc học để thu thập dữ liệu
- ...
Transform
- Nơi các quy tắc (roles) và quy trình (process) được áp dụng đối với dữ liệu để chuẩn bị tải dữ liệu vào hệ thống đích (target system)
- Việc này thường được thực hiện trong một môi trường làm việc trung gian được gọi là "Staging area"
- Tại đây dữ liệu được làm sạch để đảm bảo độ tin cậy và tương thích với hệ thống đích
- Một số kỹ thuật chuyển đổi dữ liệu:
- Cleaning
- Filtering
- Joining
- Normalizing
- Data Structuring
- Feature Engineering
- Anonymizing and Encrypting
- Sorting
- Aggregating
Ngoài ra, đối với khối Transformation, chúng ta sẽ có thêm 2 từ khóa nữa cần quan tâm:
- Schema-on-write là cách tiếp cận thông thường được sử dụng trong các đường ống ETL, thực hiện truy vấn nhanh hơn, vì dữ liệu đã được tải ở một định dạng cụ thể và dễ dàng định vị chỉ mục cột hoặc nén dữ liệu. Tuy nhiên, phải mất nhiều thời gian hơn để tải dữ liệu vào cơ sở dữ liệu.
- Schema-on-read liên quan đến cách tiếp cận ELT hiện đại, tải dữ liệu ban đầu rất nhanh, vì dữ liệu không phải tuân theo bất kỳ định dạng nào để đọc hoặc phân tích cú pháp hoặc tuần tự hóa, vì nó chỉ là một bản sao/di chuyển của một tập tin.
Load
- Đây là giai đoạn load tất cả về việc ghi dữ liệu đã Trasform vào hệ thống đích. Hệ thống có thể đơn giản như một tệp được phân cách bằng dấu phẩy (như file CSV), cũng có thể là một cơ sở dữ liệu hay là một phần của một hệ thống phức tạp như Data Warehouse, Data Lake, ...
- Một số kỹ thuật tải dữ liệu
- Full loading: kỹ thuật tải toàn bộ dữ liệu từ nguồn vào hệ thống 1 lần duy nhất, thích hợp với dữ liệu lớn hoặc dữ liệu không thay đổi thường xuyên. Kỹ thuật này tốn nhiều tgian và tài nguyên hệ thống
- Incremental loading: kỹ thuật tải dữ liệu chỉ từ các bản ghi mới được thêm vào nguồn dữ liệu, kỹ thuậtnày tiết kiệm thời gian và tài nguyên hệ thống nhưng yêu cầu cần có cơ chế đánh dấu phân biệt
- Scheduled loading: kỹ thuật tải dữ liệu theo lịch trình định trước. Kỹ thuật này phù hợp với các ứng dụng có thời gian xử lý dữ liệu chậm hoặc khi nguồn dữ liệu không thay đổi thường xuyên
- On-demand loading: kỹ thuật tải dữ liệu khi có yêu cầu từ người dùng hoặc ứng dụng. Kỹ thuầ này giúp tiết kiệm tài nguyên hệ thống nhưng cần có cơ chế phản hồi nhanh để đáp ứng yêu cầu tải của dữ liệu
- Batch and stream: trong khi Batch được sử dụng để tải dữ liệu trước khi xử lý, thì Stream tải dữ liệu theo dạng dòng hoặc block trong quá trình xử lý. Batch thích hợp cho các ứng dụng xử lý dữ liệu đại trà, trong khi stream thích hợp cho các ứng dụng xử lý dữ liệu liên tục.
- Push and pull: Push và pull là hai kỹ thuật đưa dữ liệu từ nguồn vào hệ thống. Push là kỹ thuật đẩy dữ liệu từ nguồn vào hệ thống, trong khi pull là kỹ thuật lấy dữ liệu từ nguồn vào hệ thống. Push thích hợp cho các ứng dụng có dữ liệu thay đổi nhanh, trong khi pull thích hợp cho các ứng dụng có dữ liệu thay đổi chậm.
- Prallel and serial: Parallel và serial là hai kỹ thuật xử lý dữ liệu trên nhiều luồng. Parallel là kỹ thuật xử lý dữ liệu trên nhiều luồng song song, trong khi serial là kỹ thuật xử lý dữ liệu trên một luồng. Parallel thích hợp cho các ứng dụng xử lý dữ liệu lớn hoặc có tính chất phân tán, trong khi serial thích hợp cho các ứng dụng xử lý dữ liệu đơn giản.
ETL và ELT?
Trước hết thì ETL và ELT đều là kỹ thuật xử lý dữ liệu dùng để trích xuất, biến đổi và tải dữ liệu từ nhiều nguồn khác nhau vào hệ thống
Cùng mình phân tích sự khác biệt giữa 2 kỹ thuật xử lý dữ liệu này nhé
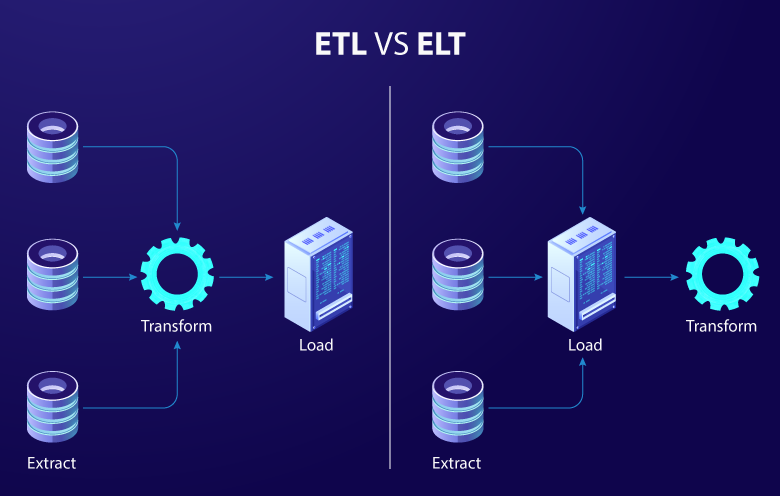
Thứ tự các bước biến đổi dữ liệu
- Trong ETL, dữ liệu được trích xuất từ nguồn, sau đó được biến đổi để phù hợp với cấu trúc và định dạng của hệ thống đích, trước khi được load vào hệ thống đích. Các bước biến đổi dữ liệu thường bao gồm lọc, sắp xếp, ghép nối, chuyển đổi kiểu dữ liệu, chuẩn hóa và gom nhóm. Sau khi dữ liệu đã được biến đổi, nó được load vào hệ thống đích.
- Trong ELT, dữ liệu được load trực tiếp vào hệ thống đích, sau đó sự biến đổi được thực hiện tại môi trường đích. Các công cụ và kỹ thuật biến đổi dữ liệu thường được tích hợp sẵn trong hệ thống đích, cho phép người dùng thực hiện các biến đổi dữ liệu một cách linh hoạt và hiệu quả.
Sự tách rời giữa quá trình load dữ liệu và sự biến đổi dữ liệu trong ELT cho phép người dùng tận dụng tối đa khả năng xử lý của hệ thống đích và giảm thiểu tải cho các hệ thống trung gian. Tuy nhiên, việc thực hiện sự biến đổi dữ liệu tại môi trường đích cũng yêu cầu các công cụ và kỹ thuật phù hợp để đảm bảo tính nhất quán và chính xác của dữ liệu.
Khả năng xử lý dữ liệu lớn
- Điểm mạnh của ETL là khả năng xử lý dữ liệu có cấu trúc, quan hệ và tính toán tại chỗ tài nguyên xử lý, vì vậy nó phù hợp cho các hệ thống dữ liệu quan hệ truyền thống.
- Tuy nhiên, điểm yếu của ETL là khó khăn trong việc mở rộng, bởi vì quá trình biến đổi dữ liệu thường xảy ra tại một điểm duy nhất, dẫn đến tình trạng tải trên máy chủ và khả năng mở rộng bị hạn chế.
- ELT cho phép xử lý bất kỳ loại dữ liệu nào, có cấu trúc và không có cấu trúc, và có khả năng mở rộng tốt hơn so với ETL. Với ELT, sự biến đổi dữ liệu được thực hiện tại môi trường đích, giúp giảm tải cho các hệ thống trung gian và tận dụng tối đa khả năng xử lý của hệ thống đích. Điều này giúp cho việc mở rộng các hệ thống ELT trở nên dễ dàng hơn.
Có thể nói ELT như 1 sự phát triển tự nhiên của ETL, một trong những yếu tố thúc đẩy sự phát triển tự nhiên đó là nhu cầu lưu trữ và xử lý dữ liệu thô trong thời đại dữ liệu khổng lồ và không ngừng phát triển đa dạng như hiện nay
Thời gian để hiểu rõ hơn trước khi triển khai
- ELT có thể đòi hỏi thời gian để hiểu rõ hơn về các công cụ và kỹ thuật biến đổi dữ liệu tại môi trường đích.
- ETL có thể đòi hỏi thời gian để thiết kế và triển khai các quy trình biến đổi dữ liệu trước khi dữ liệu được load vào hệ thống đích.
Sự xử lý dữ liệu trong quá trình biến đổi dữ liệu
- Trong quá trình ETL, dữ liệu thường bị biến đổi và chuyển đổi trước khi được load vào hệ thống đích.
- Trong quá trình ELT, dữ liệu được sao chép nguyên trạng vào hệ thống đích trước khi được biến đổi.
- Với ETL, có thể xảy ra tình trạng mất mát dữ liệu trong quá trình biến đổi, vì dữ liệu gốc đã bị biến đổi hoặc loại bỏ. Các lỗi đánh mất dữ liệu có thể xảy ra do các lỗi lập trình, lỗi cơ sở dữ liệu hoặc lỗi hệ thống trong quá trình biến đổi dữ liệu.
- Với ELT, dữ liệu được sao chép nguyên trạng vào hệ thống đích trước khi được biến đổi. Do đó, không có dữ liệu bị mất mát trong quá trình biến đổi dữ liệu, vì dữ liệu gốc được giữ nguyên.
Vì vậy, ELT có tính bảo mật và tin cậy cao hơn so với ETL.
Tuy nhiên, việc sao chép dữ liệu nguyên trạng trong quá trình ELT có thể tốn nhiều thời gian và tài nguyên hơn so với ETL. Ngoài ra, việc giữ nguyên dữ liệu gốc cũng có thể tạo ra các vấn đề về bảo mật nếu không được quản lý và kiểm soát tốt.
Thực tế thì ETL/ELT hay có thể gọi là Data Pipeline phức tạp hơn nhiều, mình có đọc được bài viết của một anh giới thiệu về thằng AirFlow, tại sao nó sinh ra là giải quyết sự phức tạp đó. Trong bài viết sau chúng ta sẽ cùng tìm hiểu về AirFlow nhé ^^

(To be continued )
Tài liệu tham khảo
All rights reserved
