
Nâng cao kỹ năng prompting đi thôi!!!
Chắc hẳn những anh em làm các con dự án RAG sẽ không còn xa lạ gì với việc phải thiết kế prompt cho một số phase trong hệ thống như QuestionAnalyzer, AnswerGenerator, AnswerEvaluator, ... Vậy các anh em dùng những chiến lược nào cho nhiệm vụ prompting này nhỉ? Từ kinh nghiệm bản thân và có trao đổi với một số anh em bạn bè khác, cá nhân mình nhận ra chúng ta khá thân thuộc với 3 kỹ thuật
- Zero-shot prompting
- Few-shot prompting
- Chain-of-Thought (CoT) prompting
Tuy nhiên ngoài 3 kỹ thuật này thì cũng còn kha khá các kỹ thuật khác khá hay ho mà anh em có thể chưa đọc tới. Vì vậy, trong bài viết này mình sẽ chia sẻ một số kiến thức mình đọc được về các kỹ thuật prompting tới các bạn. À chúng ta sẽ skip về trình bày prompt, kiểu như USER_MESSAGE, SYSTEM_MESAGE cần viết thế nào nhé. Bắt đầu thôi
1. Zero-shot prompting
- Kỹ thuật mình đánh giá là sơ khai và cơ bản nhất, cũng là dễ nhất. Không đánh giá về độ chính xác nhé vì theo mình thấy thì còn tùy thuộc vào task mình làm, mỗi chiến lược sẽ cho hiệu quả khác nhau
- Đây là kỹ thuật mà prompt được sử dụng để tương các với model mà không bao gồm ví dụ minh họa trong đó. Tức là Zero shot prompt sẽ hướng dẫn mô hình một cách trực tiếp để thực hiện task yêu cầu mà không bao gồm bất kỳ ví dụ nào để chỉ đạo nó
- Instruction tuning là một kỹ thuật giúp nâng cao zero-shot learning. Các bạn có thể tìm hiểu sâu hơn tại paper này. Mình sẽ nghiên cứu và sẽ có bài viết về chủ đề Fintuning Large Language Model trong thời gian tới
- Một ý khá hay được nhắc tới trong paper mà mình sẽ note lại ở đây
GPT-3’s zero-shot performance is much worse than few-shot performance on tasks such as reading comprehension, question answering, and natural language inference. One potential reason
is that, without few-shot exemplars, it is harder for models to perform well on prompts that are not similar to the format of the pretraining data.
2. Few-shot prompting
- Khác với Zero-shot learning, Few-shot learning cung cấp ví dụ minh hoạt cho prompt để giúp hiệu năng của model tốt hơn
- One-shot prompting cũng là một kỹ thuật con của Few-shot prompting, trong đó ta sẽ chỉ cung cấp cho prompt 1 ví dụ duy nhất
- Với ví dụ đưa vào, ta sẽ thấy model cố gắng phân tích từ ví dụ để thực hiện task được yêu cầu. Đối với task phức tạp hơn, chúng ta sẽ cần thử nghiệm tăng dần số shot lên (3-shot, 5-shot, ...)
- Hiện nay một số open source đang support rất tốt những kỹ thuật prompting này, có thể kể tới Langchain, mình đã dùng thử và thấy nó khá tiện lợi, ngắn gọn và dễ hiểu. Các bạn có thể tham khảo tại đây
- Tất nhiên không phải task nào đưa ví dụ vào nó cũng hiểu. Các bạn chắc cũng đã từng thấy mấy bài viết về việc con GPT giải toán, có đưa ví dụ vào nó vẫn giải sai ầm ầm. Vì thế nên chúng ta sẽ đi sang kỹ thuật phổ biến hơn, đó là CoT
3. Chain-of-thought (CoT) prompting
- Trong kỹ thuật này, chúng ta sẽ giúp LLM có thể giải quyết những bài toán phức tạp nhờ vào việc vạch ra các bước hợp lý cho nó.
- Trong CoT chúng ta sẽ cùng xem xét tới một vài kỹ thuật khác
- Zero-shot CoT prompting: Kỹ thuật này chắc các bạn đã từng thử, nó chính là CoT "truyền thống", đơn giản là "Let's think step by step"
- Few-shot CoT prompting: kết hợp CoT với few-shot prompting để mang lại kết quả tốt hơn cho các task phức tạp. Mỗi bước sẽ có những ví dụ để bổ trợ giúp LLM hiểu rõ hơn từng step nên làm gì/ suy nghĩ thế nào
- Ngoài ra còn có Automatic CoT prompting, bạn có thể đọc kỹ hơn tại đây. Cá nhân mình chưa dùng tới kỹ thuật này nên chưa bàn tới ở đây
- Một trong những điểm quan trọng mà mình thấy khi dùng nó, đó là cần thật sự rõ ràng các bước để GPT hiểu, rõ ràng ở đây là dễ hiểu và ngắn gọn, câu từ không quá phức tạp hay ý trước đá ý sau, không thì kết quả trả ra sẽ vô cùng khó kiểm soát
4. Self-consistency
- Hiểu nôm na thì thay vì dựa vào một lần sinh kết quả duy nhất, kỹ thuật này yêu cầu mô hình tạo ra nhiều câu trả lời khác nhau cho cùng một truy vấn và sau đó tổng hợp các câu trả lời này để chọn ra câu trả lời chính xác nhất
- Chắc hẳn chúng ta sẽ có thể hình dung được các bước của nó
- Sinh nhiều lần: Mô hình được yêu cầu tạo ra nhiều câu trả lời cho cùng một truy vấn (hay nhiệm vụ) bằng cách tạo nhiều lần đầu ra khác nhau cho một câu hỏi duy nhất. Việc sinh nhiều lần này tạo ra sự đa dạng và cung cấp các kết quả khác nhau do sự ngẫu nhiên trong cách sinh văn bản của mô hình.
- Tổng hợp và chọn lựa: Các câu trả lời sinh ra sẽ được so sánh và tổng hợp lại. Một cách phổ biến là sử dụng phương pháp bỏ phiếu đa số (majority voting), nơi câu trả lời xuất hiện nhiều nhất sẽ được chọn làm câu trả lời cuối cùng. Ngoài ra, có thể có những phương pháp tổng hợp khác để đánh giá mức độ tương tự hoặc độ tin cậy của từng câu trả lời.
- Đưa ra câu trả lời cuối cùng: Sau khi phân tích, câu trả lời có tần suất xuất hiện cao nhất (hoặc được đánh giá là hợp lý nhất) sẽ là kết quả cuối cùng của hệ thống.
- Kỹ thuật này mình thấy áp dụng nhiều khi dùng Bot để xử lý các tác vụ tính toán, và có output dạng kết quả đúng sai, hoặc một số liệu thì sẽ khá hợp lý
5. Generate knowledge prompting
- Knowledge Generation là kỹ thuật khuyến khích mô hình tự động tạo hoặc nhớ lại thông tin liên quan trước khi thực hiện nhiệm vụ chính. Ví dụ, khi được hỏi một câu hỏi phức tạp đòi hỏi nhiều bước suy luận, Knowledge Generation sẽ tạo ra các dữ kiện hoặc kiến thức nền trước để mô hình có thể tiếp tục suy luận hiệu quả hơn.
- Quy trình hoạt động của Knowledge Generation gồm các bước sau:
- Tạo hoặc nhớ lại kiến thức: Trước khi trả lời câu hỏi chính, mô hình sẽ được yêu cầu tạo ra các mẩu kiến thức hoặc ngữ cảnh liên quan. Các kiến thức này có thể bao gồm định nghĩa, thông tin nền, dữ kiện hoặc mối quan hệ giữa các đối tượng.
- Sử dụng kiến thức để suy luận hoặc trả lời: Sau khi kiến thức nền đã được tạo ra, mô hình sử dụng các thông tin đó để thực hiện nhiệm vụ chính, giúp tăng độ chính xác của câu trả lời.
- Giả sử câu hỏi là: “Tại sao nước biển lại mặn?”
- Thay vì trả lời trực tiếp, Knowledge Generation có thể hoạt động như sau:
- Bước 1 - Tạo kiến thức nền: Mô hình sinh ra kiến thức như "Nước biển chứa nhiều muối hòa tan, chủ yếu là natri và clo," và "Muối trong nước biển đến từ sự bào mòn của đá và quá trình núi lửa dưới biển."
- Bước 2 - Sử dụng kiến thức để trả lời: Sau đó, mô hình có thể trả lời rằng "Nước biển mặn là do quá trình bào mòn và các khoáng chất từ đất đá, cũng như các hoạt động núi lửa dưới đáy biển hòa tan vào nước."
- Thay vì trả lời trực tiếp, Knowledge Generation có thể hoạt động như sau:
6. Prompt chaining
- Thay vì yêu cầu mô hình xử lý tất cả các phần của một nhiệm vụ phức tạp trong một prompt duy nhất, Prompt Chaining chia nhiệm vụ đó thành một chuỗi các prompt với các bước suy luận hoặc xử lý cụ thể. Kỹ thuật này đặc biệt hiệu quả khi làm việc với các bài toán yêu cầu lập luận đa bước hoặc xử lý các thông tin phức tạp.
- Prompt Chaining hoạt động dựa trên ý tưởng chia nhỏ nhiệm vụ thành nhiều prompt theo thứ tự. Kết quả của từng prompt (hoặc từng bước) sẽ cung cấp thông tin cho prompt tiếp theo, tạo thành một chuỗi logic để đi đến câu trả lời cuối cùng. Cụ thể:
- Bước 1: Xác định nhiệm vụ phức tạp cần giải quyết và chia nó thành các phần nhỏ hoặc các bước hợp lý, mỗi bước là một mục tiêu riêng.
- Bước 2: Tạo một prompt riêng biệt cho từng phần của nhiệm vụ và sắp xếp các prompt này thành chuỗi.
- Bước 3: Gửi lần lượt từng prompt vào mô hình. Kết quả từ mỗi prompt sẽ là đầu vào cho prompt tiếp theo, từ đó dần dần xây dựng các bước suy luận hoặc tạo ra câu trả lời cuối cùng.
- Có thể thấy phương pháp này sẽ "đốt tiền" kha khá đây vì giờ với mỗi nhiệm vụ cần giải quyết là mình sẽ cần prompt tới n lần, trong đó n là số bước mà chúng ta chia nhỏ ra, đồng thời chúng ta cần control output của các prompt để phù hợp với các prompt phía sau
- Giả sử chúng ta cần trả lời một câu hỏi phức tạp: "Viết một đoạn văn giải thích sự nóng lên toàn cầu và đề xuất giải pháp khắc phục." Prompt Chaining có thể chia nhiệm vụ này thành các bước như sau:
- Prompt 1: "Giải thích hiện tượng nóng lên toàn cầu, các nguyên nhân và hậu quả chính của nó."
- Kết quả: Mô hình sinh ra một đoạn văn ngắn mô tả nguyên nhân và hậu quả của hiện tượng nóng lên toàn cầu.
- Prompt 2: "Đề xuất các giải pháp để giảm thiểu tình trạng nóng lên toàn cầu."
- Kết quả: Mô hình đưa ra các giải pháp cụ thể dựa trên nguyên nhân đã được mô tả ở prompt đầu tiên.
- Prompt 3: "Tổng hợp thông tin về nguyên nhân, hậu quả và giải pháp cho hiện tượng nóng lên toàn cầu thành một đoạn văn hoàn chỉnh."
- Kết quả cuối cùng: Mô hình sẽ sử dụng thông tin từ hai prompt trước để tạo ra một đoạn văn hoàn chỉnh.
- Prompt 1: "Giải thích hiện tượng nóng lên toàn cầu, các nguyên nhân và hậu quả chính của nó."
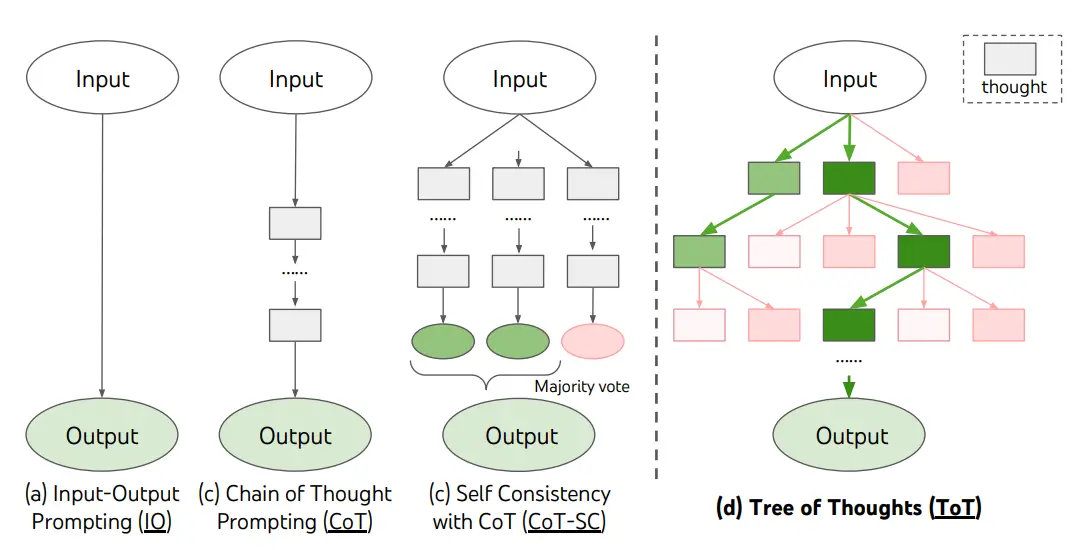
7. Tree of Thoughts (ToT)
-
Thay vì suy nghĩ và trả lời theo chuỗi tuyến tính, mô hình sẽ khám phá nhiều nhánh suy nghĩ khác nhau ( suy luận theo cấu trúc dạng cây) để tìm ra con đường hợp lý nhất dẫn đến đáp án.
![image.png]()
-
Tree of Thoughts (ToT) hoạt động dựa trên việc mở rộng các ý tưởng theo mô hình cây, trong đó:
- Mỗi "nhánh" trong cây thể hiện một hướng suy luận hoặc một giả thuyết mà mô hình có thể đưa ra.
- Mỗi "nút" đại diện cho một bước hoặc một ý tưởng trong quá trình suy luận, và các nút có thể mở rộng thành các nhánh con chứa các hướng suy luận tiếp theo.
- Đánh giá các nhánh suy luận: Mỗi nhánh sẽ được đánh giá để xem hướng đi nào là hợp lý hoặc có khả năng chính xác nhất.
- Lựa chọn nhánh tốt nhất: Cuối cùng, mô hình chọn ra chuỗi suy luận hợp lý nhất bằng cách đi qua các nút tối ưu trong cây suy luận, nhằm đạt được câu trả lời chính xác và toàn diện hơn.
-
Giả sử mô hình được hỏi một câu hỏi yêu cầu suy luận đa bước, như: “Làm thế nào để lên kế hoạch cho một chuyến đi xuyên quốc gia tiết kiệm chi phí?". Với ToT, quá trình suy luận có thể diễn ra như sau:
- Nhánh 1 (Bước đầu tiên): Xác định các yếu tố chính như phương tiện di chuyển, chỗ ở, và lịch trình.
- Nhánh con 1.1: Khám phá các phương tiện tiết kiệm chi phí (xe buýt, tàu hỏa).
- Nhánh con 1.2: Tìm các tùy chọn chỗ ở giá rẻ (ký túc xá, nhà nghỉ).
- Nhánh con 1.3: Lên lịch trình tối ưu để tiết kiệm chi phí.
- Nhánh 2 (Bước tiếp theo): Đánh giá các lựa chọn từ nhánh con và đưa ra kết luận hợp lý nhất.
- Sau khi đánh giá, mô hình chọn phương tiện xe buýt, kết hợp với việc ở tại nhà nghỉ và lịch trình được tối ưu để có chuyến đi chi phí thấp.
- Nhánh 1 (Bước đầu tiên): Xác định các yếu tố chính như phương tiện di chuyển, chỗ ở, và lịch trình.
-
Tuy nhiên đây là một kỹ thuật tương đối phức tạp về thiết kế, và cần kiểm soát chặt chẽ prompt. Bởi theo mình hiểu thì việc xác định các nhánh tại 1 thời điểm là mình sẽ dùng LLM để sinh ra, từ các nhánh đó mình lại sinh tiếp các nhánh
-
Phương pháp này mình thấy họ đang thử nghiệm cho việc giải đố như sudoku, rubik, ...
-
Cá nhân mình cũng chưa từng thử nghiệm hay dùng nên có thể còn nhiều thiếu sót, rất mong nhận sự chỉ giáo
8. Retrieval Augmented Generation (RAG)
- Quá quen thuộc rồi nhưng vẫn cần liệt kê. Đây là một xu hướng hiện mình đang thấy khá nhiều dự án về cái này
- Ngoài ra thì giờ nó còn đang mở rộng ra rất nhiều như MultimodalRAG, GraphRAG, VoiceRAG, ...
- Trong một vài bài viết sắp tới, có thể mình sẽ cùng đào sâu về RAG hơn, hi vọng anh em đón đọc
References
All rights reserved
