
PySpark với một project Machine Learning nho nhỏ
Bài đăng này đã không được cập nhật trong 3 năm
Trong không khi người người MayFest, nhà nhà MayFest, tiếp nối series tự học và khám phá về Data Sience, trong bài viết hôm nay mình sẽ chia sẻ cùng mọi người kiến thức cơ bản cũng như thực hành về Spark với một project Machine Learning nho nhỏ.
Là một người đã hoặc đang làm việc với dữ liệu, chắc hẳn các bạn đã quá quen với việc lưu trữ dữ liệu trên máy local cá nhân hoặc server cá nhân, công ty và xử lý dữ liệu đó, như mình là để đào tạo các mô hình học máy. Tuy nhiên với việc có một lượng vô cùng lớn dữ liệu sẽ như thế nào? Đó chính là lí do xuất hiện các hệ thống xử lý phân tán như Apache Spark. Thay vì cố gắng xử lý các tập dữ liệu lớn trên một máy tính, nhiệm vụ có thể được phân chia giữa nhiều thiết bị giao tiếp với nhau.
Spark là gì đã nào?
Có lẽ trước hết mình nghĩ các bạn nên đọc qua về Hadoop, mình có một bài viết về Hadoop tại đây Hadoop và Spark đều là các dự án phần mềm mã nguồn mở được phát triển trên nền tảng của Apache
- Hadoop là một framework xử lý phân tán được phát triển trên nền tảng Apache để xử lý và quản lý dữ liệu lớn.
- Spark là một framework xử lý phân tán và tính toán lớn được phát triển trên nền tảng Apache Hadoop.
- Spark được thiết kế để hoạt động cùng với Hadoop và sử dụng Hadoop Distributed File System (HDFS) để lưu trữ dữ liệu. Nó cũng tích hợp với Hadoop YARN để quản lý tài nguyên và phân phối các tác vụ tính toán trên các nodes trong cụm Hadoop.
- Spark được thiết kế để giải quyết các hạn chế của MapReduce và cung cấp một cách tiếp cận hiệu quả hơn để xử lý các tác vụ phức tạp.
Hình ảnh dưới mô tả những nhược điểm của Hadoop mà Spark đã cải thiện được

PySpark liên quan gì?
PySpark là một giao diện cho Apache Spark bằng Python. Với PySpark, bạn có thể viết các lệnh giống "sự lai ghép" giữa Python và SQL để truy vấn và phân tích dữ liệu trong môi trường xử lý phân tán.
Các bạn có thể đọc chi tiết hơn về PySpark qua trang chủ của Spark tại đây
Spark hỗ trợ thư viện cho một vài ngôn ngữ lập trình như R, Scala, Java, Python. Vậy tại sao lại là PySpark? Do mình quen làm việc với Python nên mình giới thiệu và thực hành với PySpark cho tiện thui chứ mình cũng không rõ là ngôn ngữ nào nó hỗ trợ đầy đủ hơn. Nói rộng hơn chút thì đa số các nhà khoa học dữ liệu đều làm việc quen thuộc với Python, từ phân tích, xử lý đến triển khai các mô hình học máy. Vì vậy PySpark mình nghĩ sẽ được sử dụng đông đảo hơn
Chuẩn bị để thực hành thôi
- Python: Window, Linux, MacOS
- Java: Window, Linux, MacOS
- Apache Spark: Window, Linux, MacOS
- PySpark:
$pip install pyspark - Dữ liệu để thực hành: Các bạn có thể tải xuống tại đây. Tập dữ liệu này bao gồm các đơn đặt hàng được thực hiện ở các quốc gia khác nhau từ tháng 12 năm 2010 đến tháng 12 năm 2011. Cụ thể về thông tin dữ liệu cũng như mục đích sử dụng dữ liệu mình sẽ nói ở phần tiếp
Mini Machine Learning project với PySpark nào
Bài toán
Như mình đã giới thiệu, tập dữ liệu bao gồm các đơn đặt hàng được thực hiện ở các quốc gia khác nhau từ tháng 12 năm 2010 đến tháng 12 năm 2011.
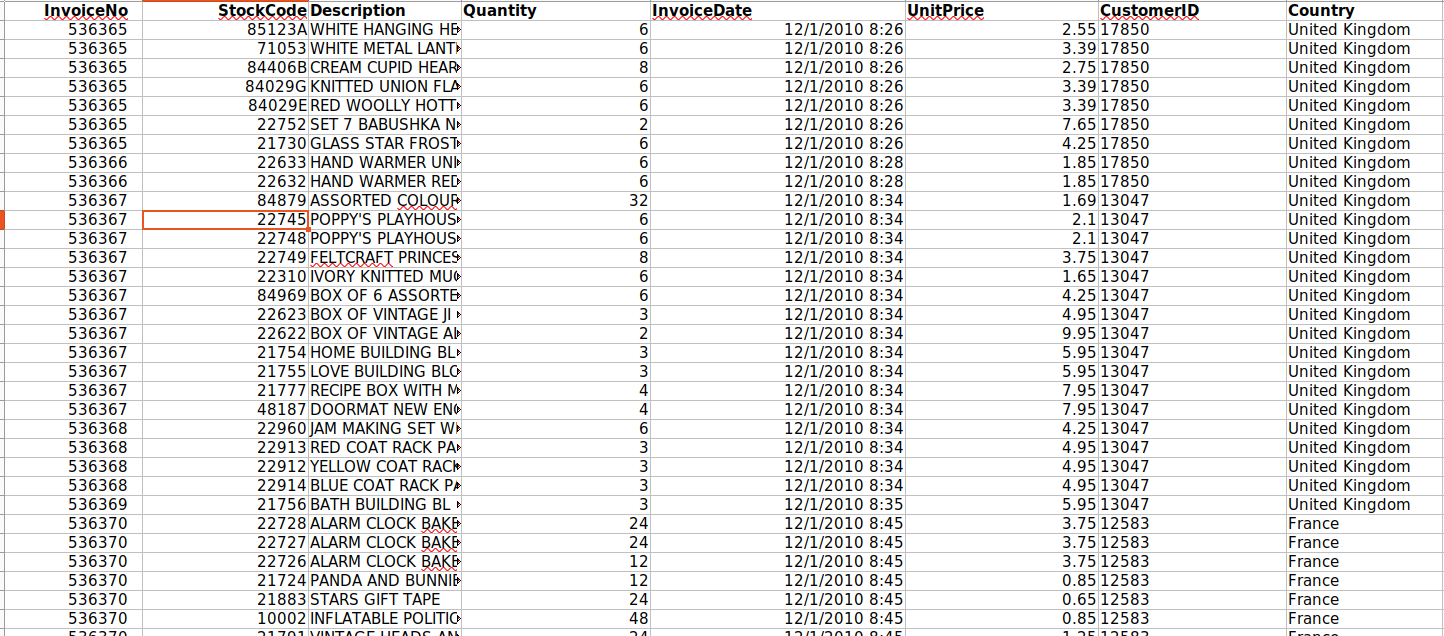
Cùng xem xét ý nghĩa các trường dữ liệu trong file
- InvoiceNo: ID của đơn hàng, nếu ID bắt đầu bằng chữ "c" thể hiện đơn hàng đó bị hủy (Cancel)
- StockCode: Mã sản phẩm
- Description: Tên sản phẩm
- Quantity: Số lượng sản phẩm trên đơn đặt hàng
- InvoiceDate: Ngày và giờ khi đơn hàng được tạo
- UnitPrice: Giá sản phẩm trên mỗi đơn vị, tính bằng pound
- CustomerID: ID của khách hàng
- Country: Quốc gia nơi khách hàng cư trú
Bài toán đặt ra: Phân khúc khách hàng là một cụm từ chắc hẳn bạn đã từng nghe khi ai đó nói về chủ đề kinh doanh hay marketing. Đay là một trong những chiến lược quan trọng mà các công ty sử dụng để phân nhóm khách hàng của mình, từ đó có những chiến lược quảng cáo, chăm sóc khách hàng phù hợp. Nếu bạn ghé vào cửa hàng quần áo X vào mỗi dịp đầu tháng, có thể bạn được xếp vào nhóm những người tiêu tiền đầu tháng, nghèo cuối tháng, hay lương được trả vào cuối tháng, thích mua sắm hàng tháng, thích mua quần âu,... Và khi đó, công ty X sẽ có những quảng cáo với mác "Chỉ dành riêng cho bạn" hay "Duy nhất trong ngày hôm nay" và những quảng cáo này sẽ xuất hiện cho những người cùng nhóm với bạn, xuất hiện vào đầu tháng, các mặt hàng sale chủ yếu là quần âu, ...
Nhắc đến phân nhóm, phân cụm thì chắc các bạn - những người quan tâm đến dữ liệu, học máy - chắc sẽ nghĩ ngay tới K-means. Đúng vậy, trong bài viết này, mình sẽ thực hiện phân khúc khách hàng dựa trên K-means với tập dữ liệu trên
Phân tích dữ liệu tổng quan
Convert dữ liệu sang csv
Vì dữ liệu chúng ta tải về là excel, mà việc phân tích dữ liệu sẽ thuật tiện hơn khi dạng csv, vì vậy mình sẽ convert nó sang csv bằng python thông qua pandas package
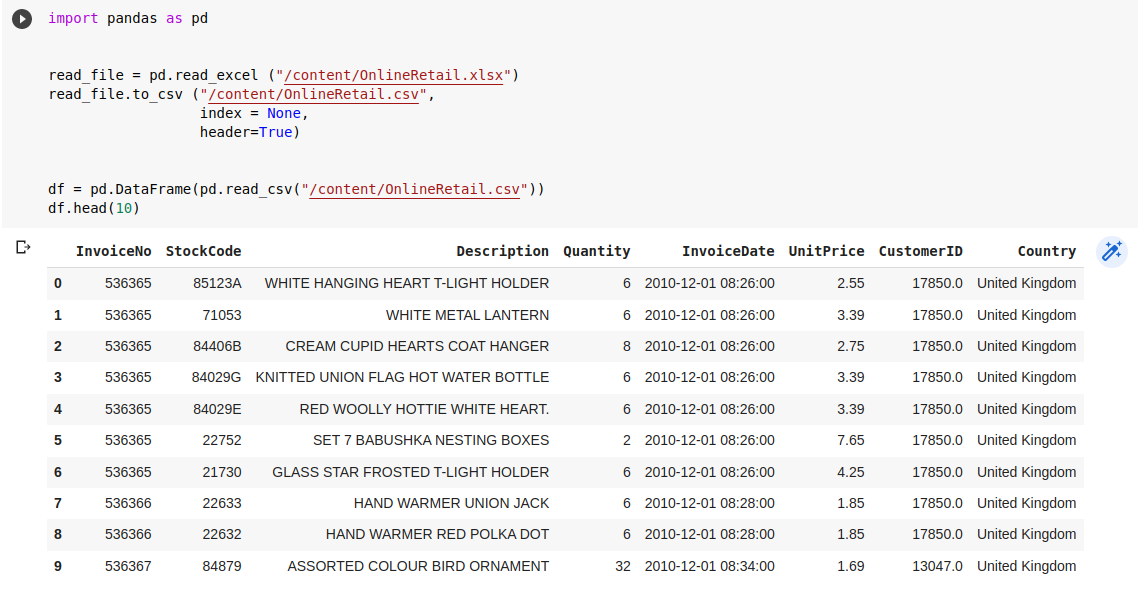
Phân tích dữ liệu cơ bản
- Để bắt đầu các thao tác dữ liệu với PySpark, chúng ta cần khởi tạo session với SparkSession. Nó xây dựng một khung dữ liệu trong PysPark để chúng ta có thể sử dụng các chức năng của PysPark lên dữ liệu của mình
# Init SparkSession
spark = SparkSession.builder.appName("Pyspark Tutorial").config("spark.memory.offHeap.enabled","true").config("spark.memory.offHeap.size","10g").getOrCreate()
-
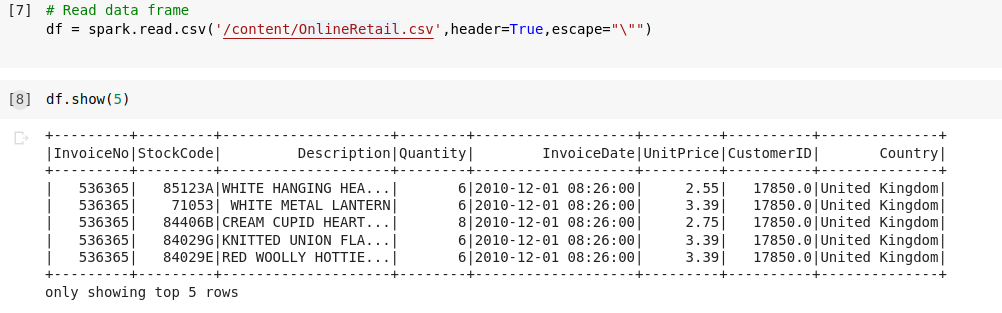
Cùng đọc dữ liệu trong file CSV vừa convert bằng PySpark
![image.png]()
-
Một số truy vấn cơ bản: Các bạn có thể thấy dưới đây việc truy vấn bằng PySpark tương đối dễ hiểu vì đúng là "con lai" python và SQL
# Đếm xem có bao nhiêu dòng dữ liệu df.count()# Có bao nhiêu khách hàng df.select('CustomerID').distinct().count()# Quốc gia nào có số lượng khách hàng thế nào df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()agg(): (aggregate values) tính toán các giá trị tổng hợpalias(): đổi tên một cột# Định dạng lại trường dữ liệu ngày tháng thành timestamp để có thể sort, tìm min hoặc max spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY") df = df.withColumn('date',to_timestamp("InvoiceDate", 'yy-MM-dd HH:mm:ss'))# Ngày có đơn hàng gần đây nhất df.select(max("date")).show()# Ngày đầu tiên có đơn hàng df.select(min("date")).show()
Tiền xử lý dữ liệu
Quay lại bài toán phân cụm, có thể thấy trong file dữ liệu có tới 7 trường dữ liệu, không phải trường dữ liệu nào cũng có ích cho phân cụm, và cũng không phải sẽ dùng được dữ liệu luôn.
RFM (bao gồm Recency (Tần suất mua hàng gần đây), Frequency (Tần suất mua hàng), và Monetary (Giá trị đặt hàng)) là một phương pháp phân tích khách hàng được sử dụng rộng rãi trong lĩnh vực tiếp thị để đánh giá giá trị của khách hàng dựa trên hành vi mua hàng của họ.
- Recency: đo thời điểm mà khách hàng đã mua hàng lần cuối. Khách hàng mới mua hàng gần đây được xem là có giá trị cao hơn so với khách hàng mua hàng lâu đến không mua hàng nữa.
- Frequency: đo tần suất mà khách hàng mua hàng trong một khoảng thời gian nhất định. Khách hàng mua hàng thường xuyên được xem là có giá trị hơn so với những khách hàng mua hàng ít lần.
- Monetary: đo giá trị đặt hàng của khách hàng. Khách hàng đặt hàng có giá trị cao hơn được xem là có giá trị cao hơn so với những khách hàng đặt hàng có giá trị thấp.
Recency
Trong phần này, mình sẽ có mục tiêu tính toán ra một giá trị đại diện cho việc thời điểm khách hàng mua lần cuối so với 1 mốc 0 nhất định (ở đây mình chọn mốc 0 là thời gian đầu tiên có đơn hàng đã tính ra bên trên). Sau đó chỉ cần lấy thời gian gần nhất khách hàng đặt đơn trừ đi mốc thời gian đó, ta sẽ có 1 giá trị đại diện cho Recency. Rõ ràng giá trị này càng lớn chứng tỏ khách hàng càng mua gần đây. Việc tính toán này sẽ thông qua 1 số bước như sau
- Tạo 1 cột mới, đặt giá trị của tất cả cột đó là ngày đầu tiên có đơn hàng. Cột này có tên "from_date"
df = df.withColumn("from_date", lit("2010-12-01 08:26:00")) - Lấy giá trị thời gian mua của từng đơn hàng trừ đi from_date, ta sẽ biết đơn hàng đo được đặt cách mốc thời gian 0 là bao nhiêu (theo đơn vị timestamp), giá trị sẽ được lưu tại cột 'recency'
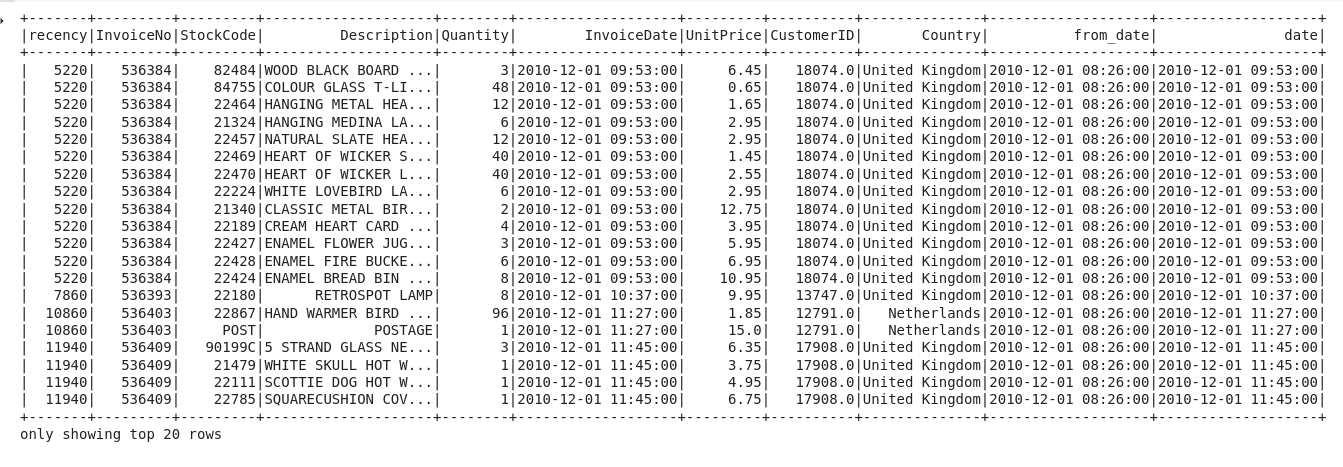
df = df.withColumn('from_date',to_timestamp("from_date", 'yy-MM-dd HH:mm')) df2 = df.withColumn('from_date',to_timestamp(col('from_date'))).withColumn('recency',col("date").cast("long") - col('from_date').cast("long")) - Mỗi khách hàng có thể mua nhiều lần vào nhiều mốc thời gian khác nhau, chúng ta chỉ quan tâm lần cuối cùng họ mua, vì vậy cần xử lý lại cột 'recency'
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')![image.png]()
Frequency
Phần này thì chúng ta sẽ tính tần suất một khách hàng mua một đồ gì đó. Chúng ta chỉ cần nhóm theo từng ID khách hàng và đếm số mặt hàng họ đã mua
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceNo').alias('frequency'))
 Lúc này frequency dataframe của chúng ta chỉ có 2 cột đứng riêng lẻ, chúng ta sẽ nối nó vào dataframe chúng ta đang làm việc để thống nhất, cũng như check xem mình truy xuất có đúng không
Lúc này frequency dataframe của chúng ta chỉ có 2 cột đứng riêng lẻ, chúng ta sẽ nối nó vào dataframe chúng ta đang làm việc để thống nhất, cũng như check xem mình truy xuất có đúng không
df3 = df2.join(df_freq,on='CustomerID',how='inner')
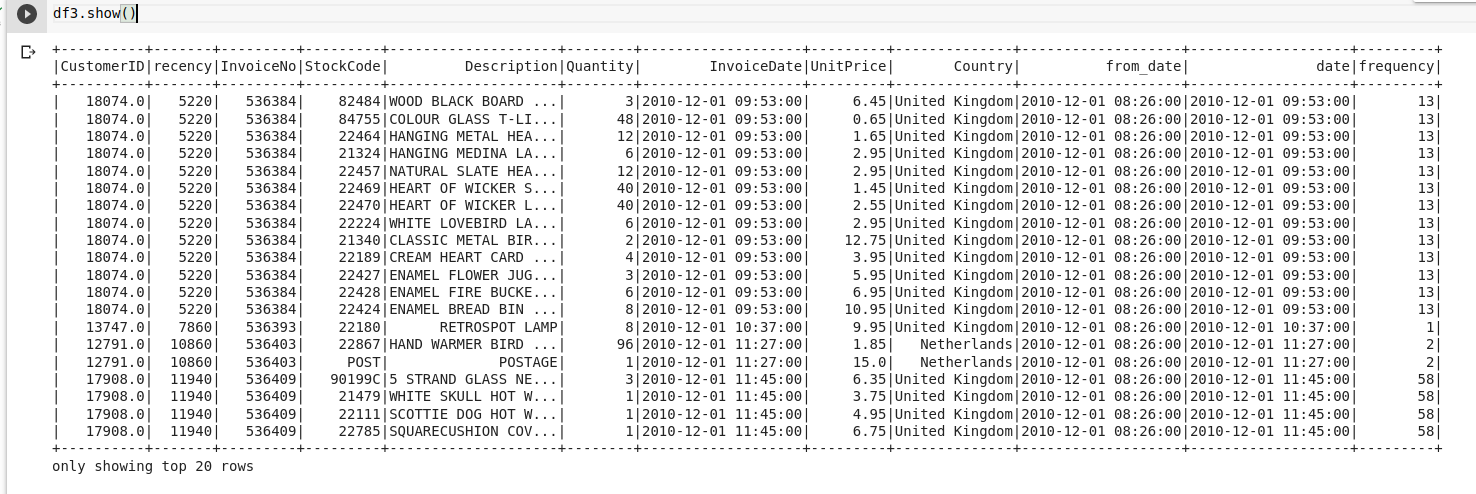
Monetary
Phần này tính xem mỗi khách hàng đã chi bao nhiêu tiền để mua sắm, phần này sẽ chia làm 2 bước
- Tính số lượng và đơn giá của một lần mua hàng
m_val = df3.withColumn('TotalAmount',col("Quantity") * col("UnitPrice"))
- Tính tổng số tiền mà khách hàng đã chi
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))

- Join dữ liệu vào dataframe đang tổng hợp
final_df = m_val.join(df3,on='CustomerID',how='inner')
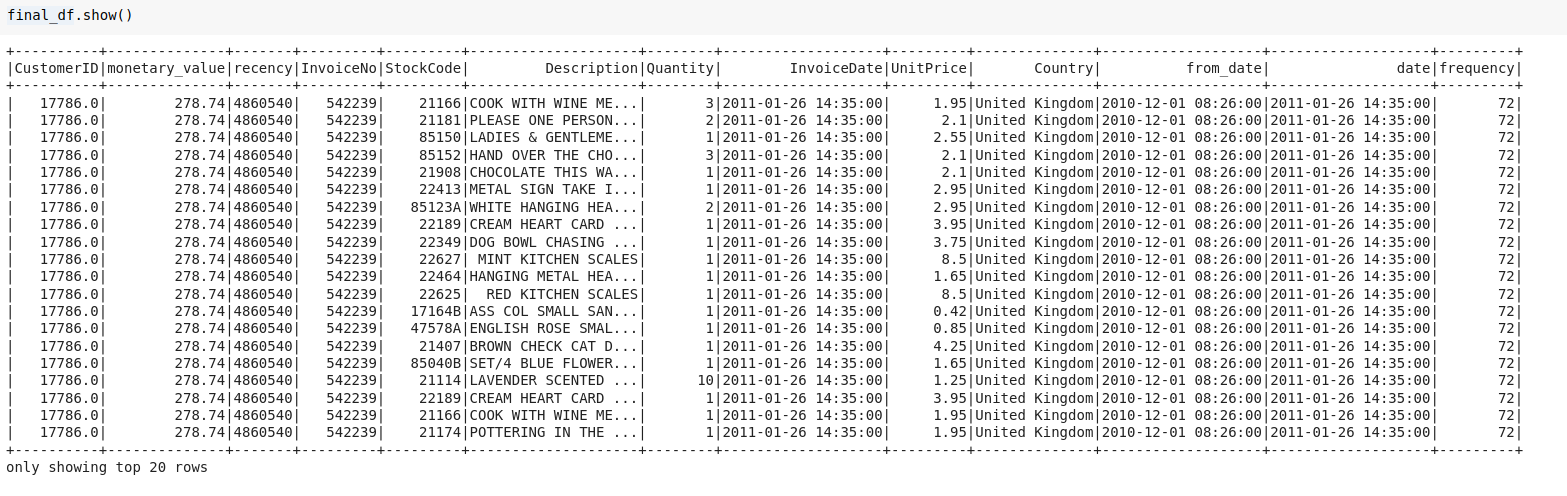
Kiểm tra những dữ liệu cần thiết cho phần sau đã đủ và đúng hay chưa thôi nào. Từ đây chúng ta cũng chỉ cần quan tâm 4 trường dữ liệu này
final_df = final_df.select(['recency','frequency','monetary_value','CustomerID']).distinct()
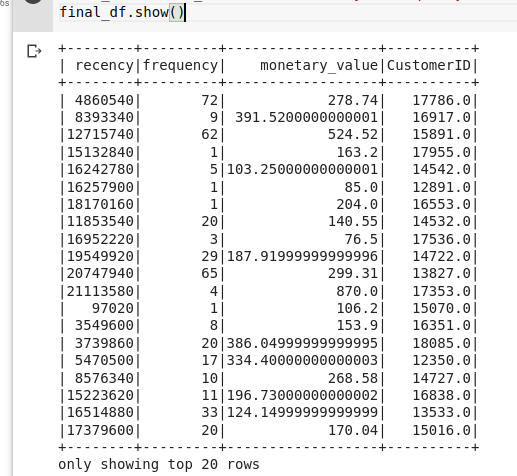
Chuẩn hóa dữ liệu
Đây là một phần vô cùng quan trọng và không thể thiếu trong các bài toán về dữ liệu. Mỗi trường dữ liệu có một đơn vị khác nhau, nếu không chuẩn hóa thì chắc chắn sẽ nảy sinh nhiều vấn đề về sau. PySpark hỗ trợ việc chuẩn hóa này với package pyspark.ml (nhìn chữ ml là biết Machine Learning rồi :v)
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import StandardScaler
assemble=VectorAssembler(inputCols=[
'recency','frequency','monetary_value'
], outputCol='features')
assembled_data=assemble.transform(final_df)
scale=StandardScaler(inputCol='features',outputCol='standardized')
data_scale=scale.fit(assembled_data)
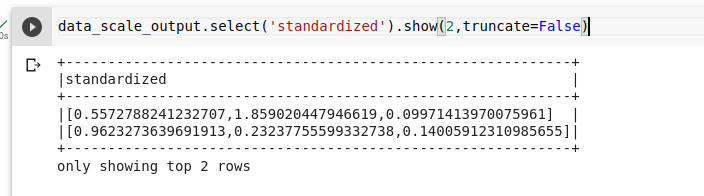
data_scale_output=data_scale.transform(assembled_data)
Thử xem dữ liếu sau khi chuẩn hóa của chúng ta sẽ trông thế nào
Triển khai học máy
Tìm số cụm k
Một trong những chiến lược đơn giản nhất để quyết định số cụm trong K-means đó là phương pháp khủy tay (elbow-method). Tức ta sẻ thử chạy K-means với nhiều cụm và trực quan hóa kết quả, tìm ra điểm uốn giống như khủy tay và lựa chọn điểm này
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='standardized',metricName='silhouette', distanceMeasure='squaredEuclidean')
for i in range(2,10):
KMeans_algo=KMeans(featuresCol='standardized', k=i)
KMeans_fit=KMeans_algo.fit(data_scale_output)
output=KMeans_fit.transform(data_scale_output)
cost[i] = KMeans_fit.summary.trainingCost
Lúc này các giá trị cost đã được lưu lại thành 1 mảng, plot lên chúng ta sẽ thấy được điểm k cần tìm (ở đây là 3, ưu tiên k càng nhỏ càng tốt)
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost[2:])
df_cost.columns = ["cost"]
new_col = range(2,10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()
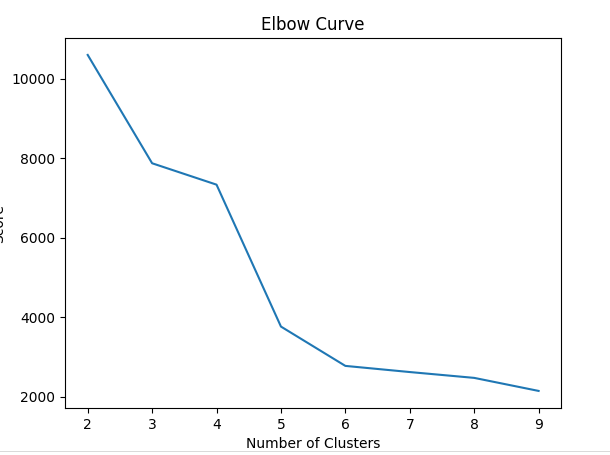
Triển khai số cụm với k=3
- Training K-means
kmeans_algo=KMeans(featuresCol='standardized', k=3)
kmeans_fit=kmeans_algo.fit(data_scale_output)
- Dự đoán
preds=kmeans_fit.transform(data_scale_output)
preds.show(5)
Xem kết quả trực quan nào
Phần này chúng ta sẽ sử dụng matplotlib để trực quan hóa phân khúc khách hàng
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
list1 = ['recency','frequency','monetary_value']
for i in list1:
sns.barplot(x='prediction',y=str(i),data=avg_df)
plt.show()
Cùng xem biểu đồ kết quả nào
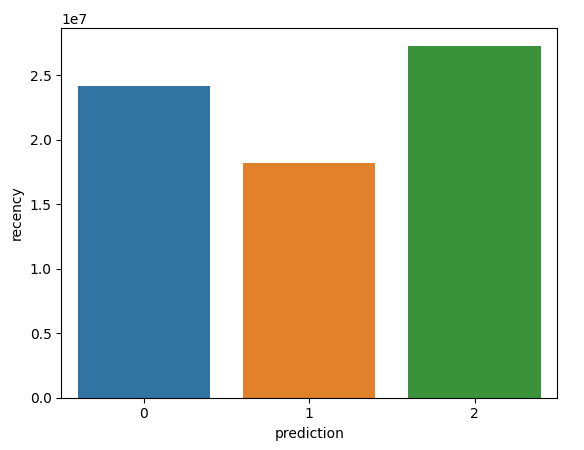
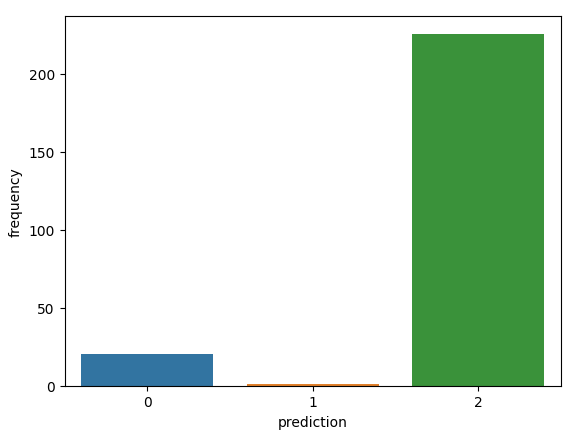
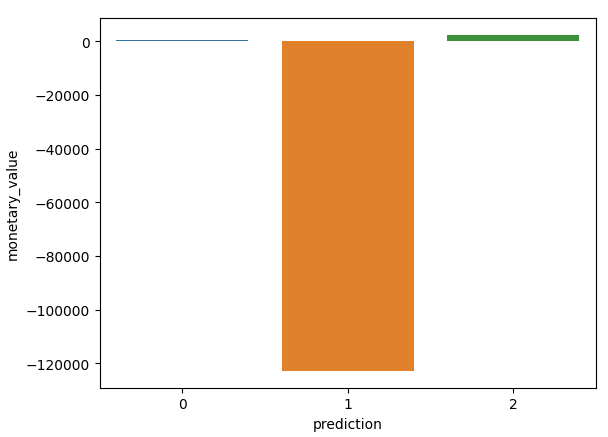
Oops, tại sao Monetary value lại âm nhỉ??? À chắc các bạn còn nhớ trường dữ liệu 'InvoiceNo', nếu có chữ 'c' ở đầu tức đơn bị hủy, khả năng tại đây giá trị của cột 'quantity' sẽ mang giá trị âm dẫn tới Monetary value có thể âm. Chúng ta có thể không xử lý vấn đề này, thì có thể thấy nhóm 1 (Có tần suất mua hàng ít) thì khả năng hủy đơn là rất cao
Trong trường hợp chúng ta không quan tâm các đơn hàng bị hủy, chúng ta cần một bước lọc ngay từ đầu trước khi đưa dữ liệu vào
df_filter = df.select("*").filter(~col("InvoiceNo").startswith("C"))
# check xem số lượng dữ liệu còn bao nhiêu
df_filter.count() # 532621
df_filter.select('CustomerID').distinct().count() # 4340
Như vậy sau khi lọc thì dữ liệu giảm đi đáng kể, số khách hàng giảm đi 33 người
Chạy lại chương trình với việc đã lọc dữ liệu, kết quả biểu đồ sau cùng cho ta như sau
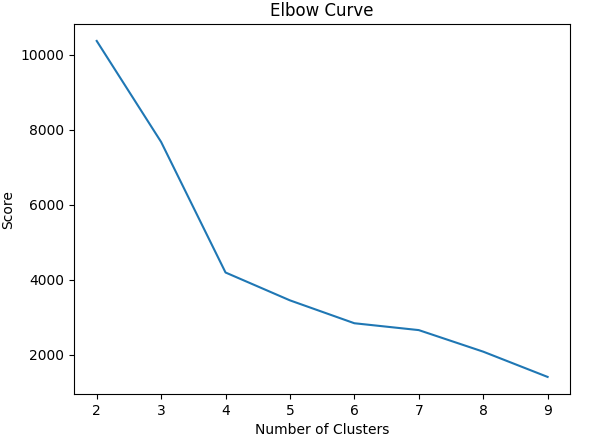
(K=4 là hợp lý đối với dữ liệu đã filter)
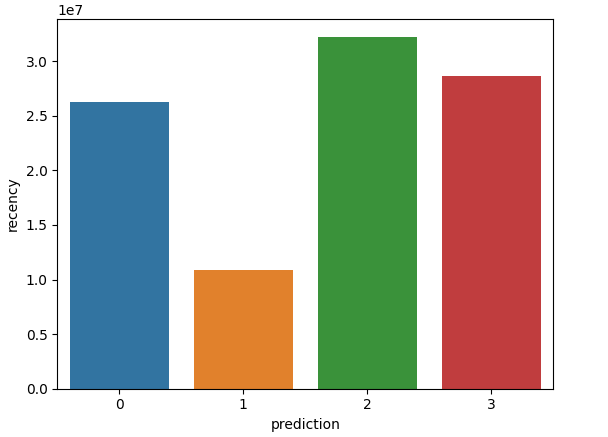
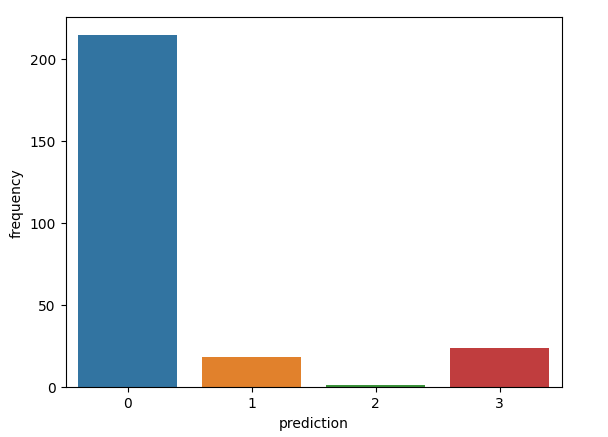
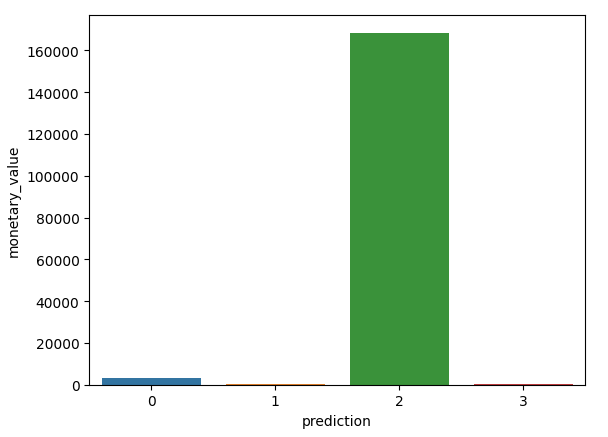
Hình vẽ tương đối rõ ràng về các đặc trưng, chúng ta có thể rút ra được một số nhận xét tổng quan như sau:
- Nhóm 0: Nhóm này có tần suất mua hàng tương đối cao, cao trội hơn 3 nhóm còn lại, lần truy cập gần nhất cũng tương đối cao, giá trị tiền mua hàng tương đối nhỏ, cho thấy là một đối tượng đa số là cá nhân, hướng tới các sản phẩm giá rẻ
- Nhóm 1: Nhóm này có cả 3 chỉ số lần truy cập gần nhất, tấn suất mua hàng và tổng tiền mua hàng rất thấp, không có quá nhiều hi vọng là khách hàng tiềm năng, khả năng cao sẽ ngừng mua hàng trong thời gian tới
- Nhóm 2: Tần suất đặt hàng rất ít, tuy nhiên gần đây lại đặt phổ biến, lượng tiền mua hàng cao vượt trội nhiều lần so với các nhóm khác. Nhóm này khả năng là các doanh nghiệp có xu hướng mua các loại hàng có giá trị cao hoặc mua có số lượng lớn
- Nhóm 3: Nhóm này có tổng tiền mua hàng rất thấp, tần suất mua hàng không quá nhiều, và truy cập gần đây tương đối cao. Nhóm này có khả năng mua theo đợt, hoặc là những người mới tham gia sàn thương mại.
Tổng kết
Source code mình demo có tại đây, các bạn có thể tham khảo. Như vậy bài viết trên mình đã giới thiệu sơ qua về PySpark - một thư viện đắc lực cho chúng ta triển khai Spark bằng Python. Tuy nhiên đây mới chỉ là bài thực hành nhỏ để chúng ta làm quen với cú pháp của PySpark, chúng ta cũng chưa động chạm gì tới cái gọi là dữ liệu phân tán. Mình sẽ học hỏi thêm và ra thêm các bài viết về PySpark, các bạn cùng đón đọc nhé.
Sau cùng cảm ơn mọi người đã đọc bài viết. Mọi ý kiến mình xin tiếp nhận và trao đổi dưới comment nhé ạ. Chần chừ gì mà không cho mình một Upvote ạ 
Tài liệu tham khảo
All rights reserved
