
Learning rate - Những điều có thể bạn đã bỏ qua
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Ngồi chơi lượn lờ Facebook một hồi tự dưng đập vào mắt 1 bài viết về Learning rate của page DataScience khiến mình tò mò đọc thử. Thử kiểu gì mà đọc hết sạch, lại thấy tương đối hay và muốn chia sẻ cho mọi người cũng như lưu giữ lại cho cá nhân. Bài viết của mình dựa trên các kiến thức của các tác giả và một chút kinh nghiệm cá nhân, mong các bạn đón đọc và đừng hiểu lầm, trách mình đi copy paste, tội mình lắm 
Không dài dòng nữa, chúng ta cùng đi sâu vào tìm hiểu về Learning rate, tầm quan trọng và một vài cách điều chỉnh của nó ở thời điểm hiện tại nhé!
Hyperparameters
Model hyperparameter (siêu tham số mô hình) là một cấu hình nằm ngoài mô hình và giá trị của nó không thể được ước tính từ dữ liệu (không phụ thuộc vào tập dữ liệu huấn luyện). Nôm na dễ hiểu hơn:
- Chúng thường được sử dụng trong các quy trình để giúp ước tính các tham số của mô hình
- Chúng thường được lựa chọn thủ công bởi người tham gia vào quá trình huấn luyện mô hình
- Nó có thể được định nghĩa bởi một vài chiến lược heuristics
Các bạn có thể sẽ bị nhầm lẫn giữa 2 khái niệm Model Parameters và Model hyperparameters, vì vậy mình khuyên các bạn nên dành chút thời gian đọc qua sự khác nhau giữa 2 khái niệm này, có thể google search hoặc xem tại bài viết sau đây của anh Phạm Văn Toàn
Đối với Model hyperparameters, chúng ta không thể đoán được đâu là giá trị tốt nhất cho các bài toán cụ thể. Bởi vậy chỉ có thể sử dụng các quy tắc chung, các kỹ thuật ước lượng hoặc các thử nghiệm thực tế
Một vài ví dụ về model hyperparameter mà các bạn đã từng ít nhất 1 lần bắt gặp
- Learning rate
- Tham số k trong k-nearest neighbors
- Tham số C và sigma khi training Suport Vector Machine (SVM)
Learning rate là gì?
Learning rate là một trong số những siêu tham số quan trọng nhất của mô hình. Có thể sẽ có các siêu tham số các bạn chưa nghe bao giờ hoặc chưa dùng bao giờ, nhưng learning rate, batch size, epochs, … là các tham số các bạn bắt gặp hầu như trong hầu hết các bài toán Deep Learning trong quá trình huấn luyện.
Learning rate được hiểu là một phần tỷ lệ của một bước dịch chuyển trọng số mô hình được cập nhật theo các mini-batch truyền vào. Độ lớn của learning rate sẽ ảnh hưởng trực tiếp tới tốc độ hội tụ của hàm loss tới điểm cực trị toàn cục.
Cùng mình hiểu rõ hơn tầm ảnh hưởng của Learning rate qua hình vẽ dưới đây
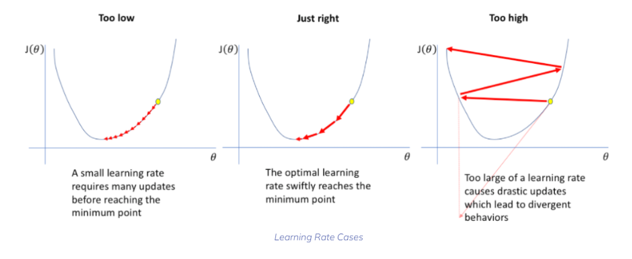
(nguồn: https://neptune.ai/blog/how-to-choose-a-learning-rate-scheduler )
- Ở hình bên trái, với trường hợp Learning rate quá nhỏ dẫn đến các cập nhật đối với trọng số là nhỏ, điều này sẽ giúp tìm tới điểm cực tiểu được chuẩn xác hơn vì bước nhảy là rất nhỏ. Tuy nhiên điều này sẽ khiến mất rất nhiều thời gian để hội tụ, hoặc nếu các bạn biết tới khái niệm cực tiểu cục bộ, thì với learning rate quá nhỏ này có thể dẫn tới việc bị kẹt trong cực tiểu cục bộ không mong muốn
- Trái với hình bên trái, hãy nhìn hình bên phải với trường hợp Learning rate quá lớn, thuật toán sẽ học nhanh, nhưng có thể thấy thuật toán bị dao động xung quanh hoặc thậm chí nhảy qua điểm cực tiểu.
- Sau cùng, hình ở giữa là việc chọn Learning rate phù hợp, nó sẽ hài hòa được giữa tốc độ hội tụ của thuật toán cũng như việc tìm ra điểm cực tiểu. Không quá nhỏ cũng không quá lớn, đúng là cái gì quá cũng không tốt =)))
Lý thuyết là thế, tuy nhiên mỗi bài toán cụ thể sẽ có các cách khác nhau để tìm ra Learning rate phù hợp
Phương pháp tìm kiếm với Learning rate
Tìm kiếm từ thô tới tinh
Ý tưởng của phương pháp này là lựa chọn ngẫu nhiên trong một không gian siêu tham số và tìm ra một miền mà tại đó tập trung các giá trị của siêu tham số khiến cho loss function thấp.
Tiếp tục lặp lại quá trình trên đối với vùng nhỏ vừa tìm được để tìm ra vùng nhỏ hơn
Tìm kiếm trên không gian scale logarithm
Khi sử dụng phân phối đều trên khoảng [0, 1] để lựa chọn ngẫu nhiên learning rate, 10% sẽ rơi vào [0, 0.1] và 90% sẽ rơi vào [0.1, 1], nhưng trên thực tế, learning rate gần như không bao giờ rơi vào [0.1, 1]. Learning rate bởi vậy thông thường không tuân theo phân bố đều.
Do đó, ý tưởng của phương pháp là lấy logarithm cơ số 10 của learning rate và thực hiện tìm kiếm trên miền không gian lúc này, chẳng hạn chọn [-5, 0], thì lúc này learning rate phân bố đều trên các miền giá trị nhỏ [0.00001, 0.0001], [0.0001, 0.001], [0.001, 0.01], [0.01, 0.1], [0.1, 1]
Tuning learning rate theo loss function
Ý tưởng của phương pháp là tăng dần learning rate theo batch iteration và theo dõi loss function trên từng batch iteration. Có 3 trường hợp xảy ra:
- Những vị trí mà learning rate nhỏ sẽ khiến cho đường biểu diễn giá loss gần như nằm ngang
- Những vị trí có learning rate phù hợp sẽ biểu thị đường biểu diễn giá trị loss đi xuống cho thấy loss function đang hội tụ dần
- Những vị trí có learning rate cao sẽ khiến cho hàm loss biến đổi thất thường, tăng, giảm hoặc dao động ngẫu nhiên như hình dưới
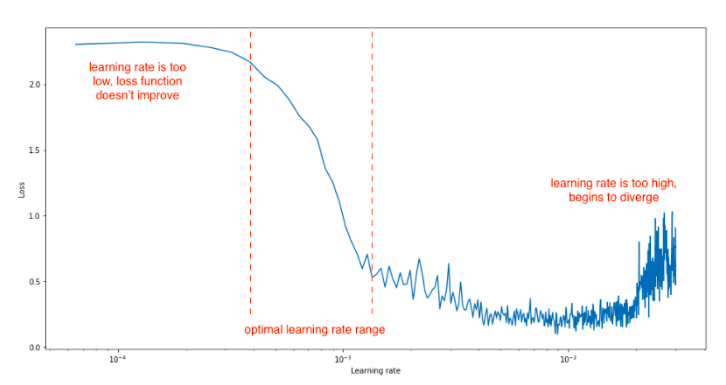
(nguồn: https://imgur.com/pWz4X6b )
Khi đó ta sẽ lấy learning rate ở điểm chính giữa đường hạ dốc của loss function (điểm màu đỏ như hình dưới)
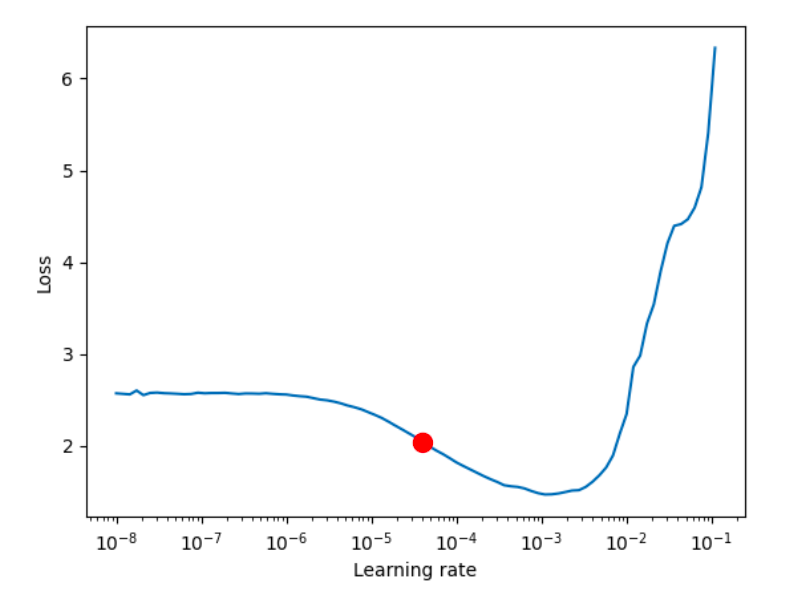
(nguồn: https://imgur.com/9uuNdp0 )
Vấn đề Plateus
Plateaus là hiện tượng miền giá trị của hàm loss function rơi vào một vùng mặt phẳng có đạo hàm gần bằng 0 và đồ thị của loss function đường như nằm trên một mặt phẳng nằm ngang có độ lớn không đổi.
Một trong những nguyên nhân quen thuộc đó chính là mô hình bị nghẽn ở điểm cực tiểu cục bộ (chấm đỏ ở hình dưới). Mặc dù là điểm cực tiểu nhưng không phải là vị trí ta mong muốn cho mô hình tốt nhất (cực tiểu toàn cục)
Đối với vấn đề này có thể sử dụng những thuật toán như momentum hay adam để vượt qua vùng Plateus dễ dàng. Momentum có thể hiểu như bạn truyền cho con lắc một vận tốc ban đầu, từ đó nó có thêm động lực để vượt qua được cực tiểu cục bộ
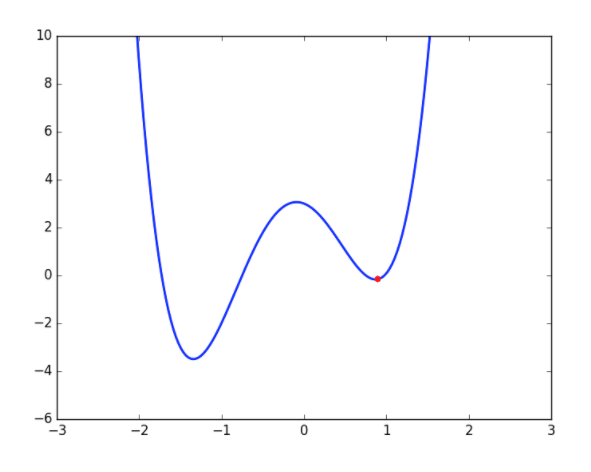
(nguồn: https://analyticsindiamag.com/what-is-the-plateau-problem-in-neural-networks-and-how-to-fix-it/ )
Sử dụng Learning rate decay
Learning rate decay là hệ số giúp triệt tiêu độ lớn của learning rate theo thời gian huấn luyện nhằm tránh giá trị của chúng quá cao ở những giai đoạn trọng số mô hình đã đi vào hội tụ.
Càng về các epochs sau, khi mô hình tương đối gần điểm cực tiểu, bạn sẽ quan sát thấy giá trị loss function gần như không đổi hoặc thay đổi rất nhỏ, lúc này việc sử dụng learning rate decay là rất cần thiết, 1 mặt tránh cho việc bị nhảy qua điểm cực trị, 1 mặt khi giảm learning rate, loss function sẽ hội tụ tốt hơn.
Một số phương pháp decay:
- Linear learning rate decay: lr = lr/(1+decay_rate*epoch_num)
- Exponential learning rate decay: lr = 0.99^epoch_num*lr
- Các công thức khác:
- r = k/sqrt(epoch_num) * lr
- lr = k/sqrt(mini_batch_num)*lr
- lr = lr* (kể từ epoch thứ n) (Đây là công thức mình dùng gần nhất cho một paper môn tin sinh học)
Hiện tại learning rate decay được tích hợp kèm các module schedule learning rate như: ReduceLROnPlateau, ExponentialLR, LinearLR trên pytorch, bạn đọc có thể xem thêm tại đây
Ngoài ra trên tensorflow cũng hỗ trợ với module LearningRateScheduler, bạn đọc có thể tham khảo tại trang chủ tensorflow
Ngoài ra còn một số chiến lược huấn luyện Learning rate, tuy nhiên mình chưa có thời gian tìm hiểu kỹ nên cũng chưa chia sẻ được thêm. Thời gian tới mình sẽ cố gắng chăm chỉ hơn để có thể cùng chia sẻ với các bạn và cả với bản thân những kiến thức mới.
Mong rằng bài viết của mình sẽ giúp các bạn hiểu hơn vể Learning rate cũng như phần nào vận dụng được sức mạnh của nó trong việc huấn luyện mô hình của mình. Thật sự là trước đó mình chỉ biết fix cứng Learning rate theo paper hoặc theo số đông thôi (0.001, 0.01).
Inferences
[1] Barreto, S. (2021, November 26). Choosing a Learning Rate. Baeldung on Computer Science. https://www.baeldung.com/cs/ml-learning-rate?fbclid=IwAR1u9TqQ2_iUMMyJaHf7fYj23HCOUu6j0DiiJFltSVoLBz_hEXE1X2ME3oo
[2] Lau, S. (2018, June 20). Learning Rate Schedules and Adaptive Learning Rate Methods for Deep Learning. Medium. https://towardsdatascience.com/learning-rate-schedules-and-adaptive-learning-rate-methods-for-deep-learning-2c8f433990d1
[3] Lendave, V. (2021, September 17). What is the Plateau Problem in Neural Networks and How to Fix it? Analytics India Magazine. https://analyticsindiamag.com/what-is-the-plateau-problem-in-neural-networks-and-how-to-fix-it/
[4] Li, K. (2021, October 13). How to Choose a Learning Rate Scheduler for Neural Networks. Neptune.Ai. https://neptune.ai/blog/how-to-choose-a-learning-rate-scheduler?fbclid=IwAR33xhB_6gg2oSYnOU7R4iGniN80qYw8n7SCLkGcJROHC2vgwJXCXfgyMlI
[5] Surmenok, P. (2021, April 19). Estimating an Optimal Learning Rate For a Deep Neural Network. Medium. https://towardsdatascience.com/estimating-optimal-learning-rate-for-a-deep-neural-network-ce32f2556ce0
All rights reserved
