
DETR Object Detection Transformer
Bài đăng này đã không được cập nhật trong 6 năm
1. Goal of the paper
Notes: những thuật ngữ mình dùng trong bài này mà không có chú thích các bạn có thể tìm thấy trong bài A discussion of SSD của mình
Nếu các bạn còn nhớ trong bài SSD, object detection có thể được giải quyết theo bài regression và classification bình thường, cái khó ở chỗ là phần labeling . Khi đưa ảnh qua model, giả sử sẽ predict ra 4 boxes, 4 labels trong khi ảnh thật có 3 objects. Như vậy, predicted box nào sẽ dùng để match với ground true box nào và predicted catergory nào sẽ match với object nào?
Một trong những cách giải quyết vấn đề về matching này là pre-labeling sử dụng anchor boxes (như YOLO, SSD, Retina Net,…) . Cách này có một vài vấn đề như imbalance trong labels ( số lượng anchor boxes quá lớn dẫn trong khi số lượng objects trong một ảnh thì ít, điều này khiến các empty-object labels nhiều hơn rất rất nhiều object labels). Nếu các chúng ta nghĩ đơn giản là tại sao không giảm số lượng anchor boxes đi thì đây là một trade off. Giảm anchor box là giảm khả năng covering variations về scale, size, position của objects trong cả tập dữ liệu, đồng nghĩa với việc giảm độ chính xác của predictions.
Có nhiều cách được dùng để alleviate vấn đề này như hard negative mining (trong số các empty object labels (negative) , chọn những predictions sai nhất (mining) (trừng phạt mạnh nhất khi đã sai mà còn tự tin), và bỏ qua luôn (hard) các prediction ít sai hơn), nhưng Focal Loss được xem như cách hiệu quả nhất. Ngoài ra, trong quá trình inferring, sẽ có rất nhiều box cùng predict một objects, và thường được giải quyết bởi Non-maximum suppression algorithm (NMS). Nhưng nhìn chung, implementation của các model sử dụng anchor box đều không dễ dàng.
Object detection Transformer tiếp cận bài toán object detection theo hướng anchor-free, dễ dàng trong việc implement, giải quyết được vấn đề imbalance classes và trong inference không cần dùng đến NMS.
2. Key elements to achieve the goal
Phần này trả lời cho câu hỏi: làm sao để label và làm sao để inference , transformer được áp dụng như thế nào trong bài OD?
Đầu tiên , về cơ chế labeling, giả sử model output một lượng boxes (và classes tương ứng) nhất đinh, làm sao ta biết được box nào sẽ predict ground true object nào? OD transformer sử dụng Hungarian algorithm để giải quyết bài toán gán nhiệm vụ này (assignment problem): giả sử bạn cần mua 4 thứ : táo, chuối, chó và kẹp tóc. Và bạn có 4 cửa hàng gần nhà đều bán cả 4 thứ trên là A, B, C, D. Bạn biết giá của mỗi thứ ở từng cửa hàng là như bảng sau:

Vì hôm đó bạn không được minh mẫn nên quyết định mình chỉ được mua một đồ ở một cửa hàng, không hơn. Vậy bạn sẽ có 4! cách để mua đồ. Hỏi cách lựa đồ nào trong 4! cách trên giúp bạn tối thiểu hóa chi phí mua hàng. Hugarian algorithm giúp giải quyết bài toán này theo một cách mà tôi vẫn chưa hiểu được tại sao nó hoạt động, nên tôi sẽ để lại link bên dưới. Nếu các bạn đọc và hiểu được tại sao thì mong bạn hãy để lại comment giải thích.
Quay trở lại bài OD, Hungarian algorithm giúp giải quyết vấn đề labling như sau: Từ ảnh đầu vào, model sẽ output ra 100 (con số này chúng ta có thể tùy chọn) prediction (box-class pairs). Giả sử ảnh này chỉ chứa 4 objects, như vậy ta sẽ pad 96 empty objects nữa (khi implement paper, điều này sẽ không cần thiết, để tránh for loops). Matching algorithm sẽ output 100 matched pairs: predicted boxes (and classes) cho 100(có pad) ground true objects. Để algorithm hoạt động, ta cần biết 'cái giá' khi match một predicted box nào đó với một true object là bao nhiều. Paper đề xuất cách tính giá này như sau:
![]()
Nguồn : paper
First term tính classification loss , 2nd term là box loss khi một prediction bất kì với một nonempty object.
Khi match một pred-box với một empty objects, cost không được tính (coi như bằng 0). Ngoài trường hợp đó, cost sẽ bằng classification loss (giá phải trả cho việc nhìn gà hóa quốc: predict ra là quốc nhưng lại được match với gà) cộng với boxes cost. Lưu ý: classification ko dùng negative log likelihood mà chỉ dùng negative probability (tại sao thì tôi chưa biết)
Nhưng quan trọng hơn là phần boxes loss. Nếu chỉ dùng L1, smooth L1, ... để tính loss mà không dùng anchor thì sẽ không ổn. Vì model predicts ra absolute coordinates, không phải offset so với anchor box tương ứng (https://viblo.asia/p/a-discussion-of-ssd-intuition-eW65Gv3YlDO ).
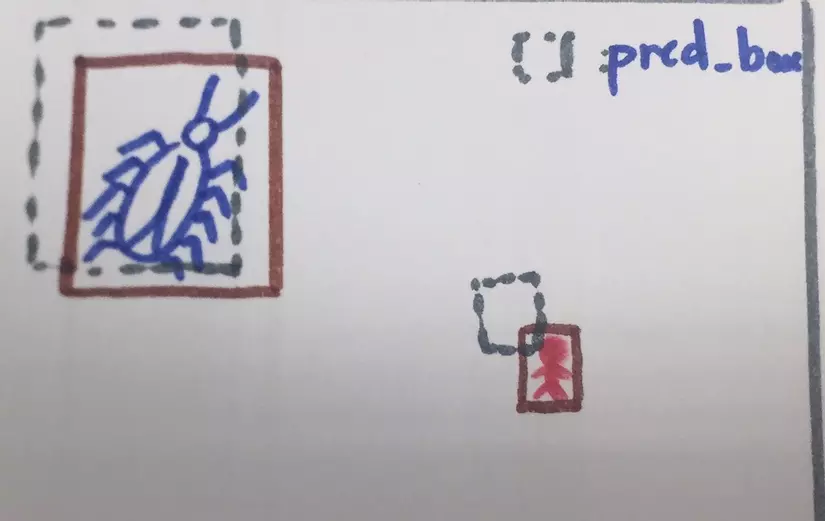
Box A khi predict con gián có loss lớn hơn box B predicting một người vì sự khác biệt về scale của hai objects. Chúng ta cần loss measure có tính scale invariant hơn. Và IOU loss comes to the rescue :3. Nếu như smooth L1 loss punishes sự khác biệt tuyệt đối giữa predicted box và true box thì IOU loss penalizes sự khác biệt mang tính tương đối hơn (Dù objects nhỏ hay to, predicted box mà càng ít giao với true box thì loss càng lớn).
Tuy nhiên, IOU không phải là "hoa tiêu" hiệu quả khi pred_box hoàn toàn không giao true_box. 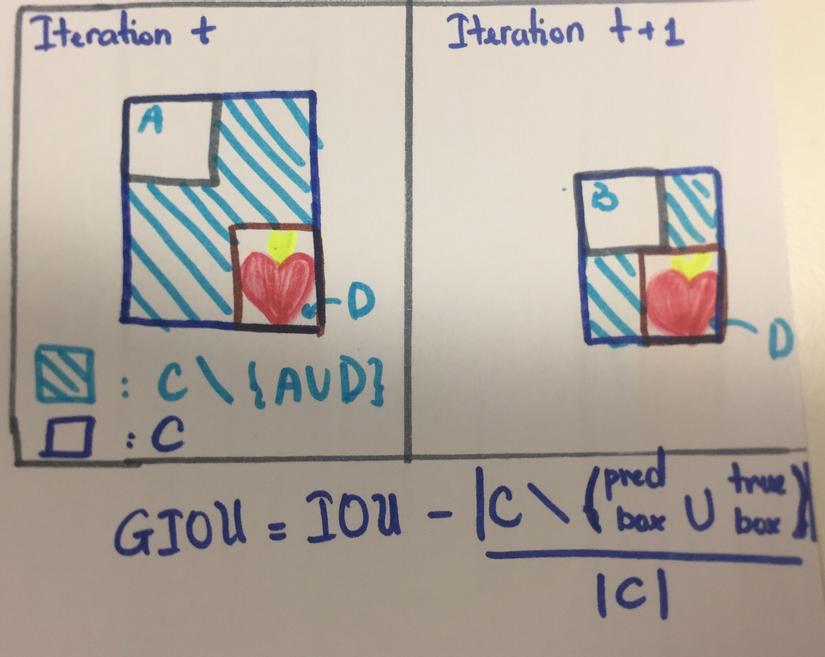
Đều là bad predictions nhưng IOU không cho thấy box A hay B (ở iteration t model predict box A, iteration t+1 model predict box B), cái nào tệ hơn. Vì IOU loss sẽ penalize hai box như nhau. Và như vậy, IOU loss không thể nói cho model biết là dù B có tệ thì đó cũng là một sự "đi đúng hướng". Tiếp tục theo đường đó đi.
Do đó thay vì ử dụng IOU, paper sử dụng GIOU (công thức trong hình trên). Một giải thích rất rõ về GIOU. Như vậy sau khi đã tìm được matching pairs, chúng ta sẽ tính loss của model dựa train các matching pairs đó. (Lưu ý có hai loại loss, một loss đế tính loss table cho Hungarian algorithm , tìm ra matching pairs, loại còn lại là total model loss. Trong paper model loss sẽ được gọi là Hungarian loss, nhưng để đỡ bị confused, trong bài này ta tạm gọi nó là model loss).
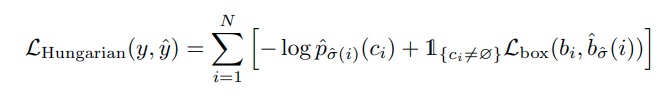
Nguồn : paper
Trên một ảnh, loss sẽ được tính như sau: box loss tính như trên cho tất cả các cặp matching pairs mà true box có chứa objects. Còn classification loss sẽ được tính theo cross entropy bình thường cho tất cả các matching pairs , kể cả không chứa objects. Tuy nhiên vì số lượng pairs có objects ít hơn pairs không có objects nên sẽ có "empty_weight" để balance lại class loss. Chi tiết hơn về loss sẽ có trong phần phụ lục của paper và code
Cách giải quyết vấn đề labeling của OD được inspired từ bài toán Set Prediction. Bạn đọc quan tâm có thể tìm hiểu thêm ở link cuối bài viết
Thứ 2, làm sao OD transformer có thể không cần dùng NMS, tức là các box A và box B hay nhiều box khác sẽ không tập trung predict cùng một objects. Điều này có nghĩa là Box A và B phải có thông tin của nhau để tránh predict trùng lặp. Các bạn nghe có quen không? Đúng rồi, tôi đang nói đến attention mechanism. And here we come to Transformer (Hình vẽ). (Đến đây nếu các bạn chưa quen với khái niệm transformer thì t suggest các bạn đọc một bài viết về Transformer khá kĩ của một bạn trong team AI chúng tôi : Transformers - "Người máy biến hình" biến đổi thế giới NLP
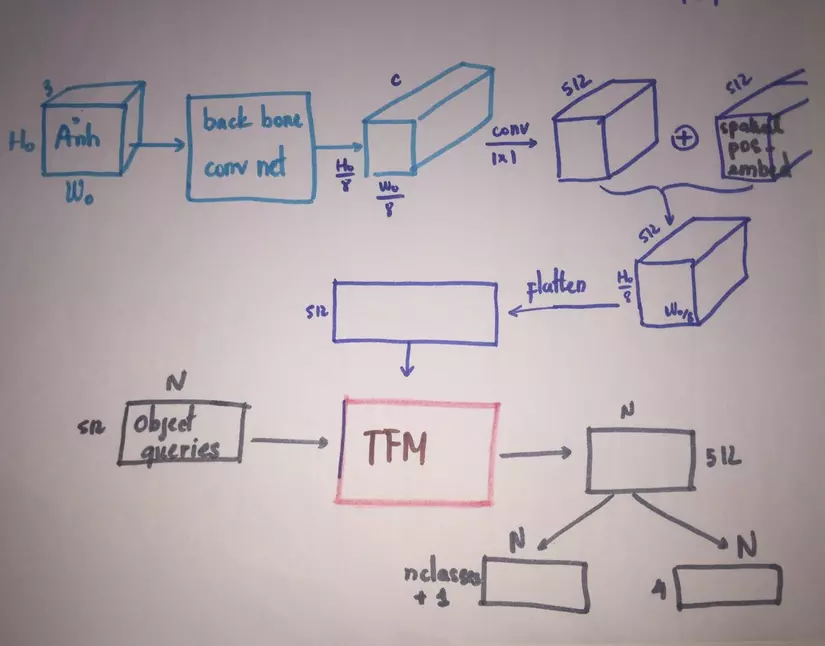
Objects queries là n predictions ( n slots ) mà model sẽ output cho mỗi ảnh đầu vào. Sau khi backbone model ( a Convnet ) extract features của ảnh, features đó sẽ được đưa qua conv 11 để đưa channel size về model_dimension (512) sau đó flatten để đưa vào encoder. Encoder này như encoder của transformer trong paper Attention is all you need, điểm khác biệt là positional embedding sẽ là spatial positional embedding (khác ở chỗ có riêng posional embeddings cho row và column position ở mỗi vị trí trên feature maps) và được add vào mỗi layer của encoder chứ không chỉ của layer thứ 1. Sau đó, output của encoder sẽ trở thành memories và cùng với spatial positional embeddings được đưa vào decoder multihead encoder-decoder attention ở mỗi layer của decoder.
Ở decoder, các slots predictions được initialize randomly. Ở mỗi decoder layer, các slots sẽ tự pay attention lẫn nhau, sau đó các slots sẽ pay attention vào encoder output, heuristically, tôi hiểu điều này là mỗi slot prediction sẽ chú ý vào region nào và features nào trên ảnh đầu vào, từ đó, đưa ra dự đoán cho objects ở region đó. Và theo như tôi hiểu, cơ chế self attention ở decoder hoạt động một phần giống như "self-regularize ", các slot có thông tin của nhau để tránh predict trùng lặp với nhau, và như vậy sẽ không cần dùng tới NMS trong lúc dự đoán. Cách hiểu này mang tính intuitive, nó hoàn toàn có thể sai, mong bạn đọc cẩn thận phán xét khi đọc tới đoạn này.
Dưới đây là một vài ảnh minh họa cho kết quả của attention ở encoder và decoder trong paper !
Nguồn : paper

Nguồn : paper
3. Một vài điểm cần chú ý về model
Về NMS: paper làm thí nhiệm và cho thấy, số lượng decoder layers có ảnh hưởng nhiều đến việc các slots có predict trùng lặp hay không. Càng nhiều decoder layer thì càng giảm sự phụ thuộc vào NMS. Tuy nhiên, khi tôi fine-tune lại model trên tập pascalvoc 2007 thì tôi vẫn phải dùng đến NMS để lúc inference dễ nhìn hơn.
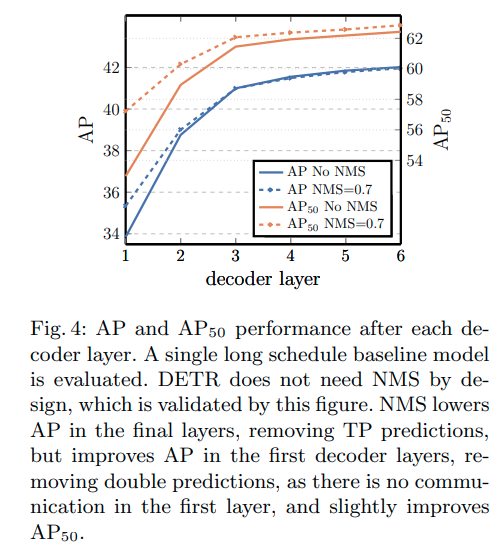
Còn một trick mà paper sử dụng là auxiliary loss nhưng tôi không hiểu phần này lắm nên sẽ không đề cập trong bài này.
Ngoài ra, paper frozen batchnorm parameters trong backbone model (không update weights). Tôi đoán rằng điều này sẽ làm giảm performance khi train model với data set có statistic khác nhiều với tập imagenet.
4. what can be improved and further discussed?
Paper claim rằng model của họ perform không hẳn tốt trong việc detect small objects và số lượng decoder layers càng nhiều càng giảm sự predict trùng lặp của các slots. Đây cũng là một trade off đối với computation.
Tôi đoán có thể dùng coverage loss punish trực tiếp khi các slots chứa nhiều thông tin quá giống nhau. Còn để predict small objects thì có thể dùng các feature maps chứa nhiều details information làm đầu vào cho encoder. Rất mong bạn đọc nếu có ý tưởng gì có thể thử improve và comment thêm.
Reference:
- End-to-End Object Detection with Transformers
- Kaggle wheat detection using transformer
- Get To The Point: Summarization with Pointer-Generator Networks
- Generalized Intersection over Union
- Paper code
- Attention is all you need
- Focal Loss
- Transformers - "Người máy biến hình" biến đổi thế giới NLP
- Hungarian Maximum Matching Algorithm
All rights reserved
