
[Paper Explain][Segmentation] Tóm tắt nội dung và implement paper BiSeNet với PyTorch
Bài đăng này đã không được cập nhật trong 6 năm
Lời giới thiệu
Xin chào các bạn. Đây là series mà mình đã ấp ủ rất lâu nhưng vì cứ mải việc này việc kia mà chưa có thời gian thực hiện. Chúng ta đã biết rằng có rất nhiều người muốn tìm hiểu về lĩnh vực AI nhưng việc phải đọc các paper và tìm hiểu các lý thuyết của nó thực sự không phải là điều đơn giản. Có rất nhiều lý do cho vấn đề này nhưng mình thấy thường là có một số lý do khá cơ bản như sau:
- Thiếu background nên khi đọc các paper mới thường sẽ bị choáng ngợp bởi những kiến thức reference đến
- Không biết cách implement: Gần đầy các paper thường reference đến source code để implement nó giúp cho mọi người có thể tham khảo tuy nhiên vì nhiều lý do khiến chúng ta không implement được tư tưởng chính của paper. Có thể là do sự giới hạn về mặt ngôn ngữ lập trình, framework hoặc đơn giản là paper không cung cấp source code trong khi mô tả về các thuật toán lại quá khó hình dung
- Ngại đọc tiếng Anh đây cũng là một trong những lý do phổ biến khác bởi tiếng anh được dùng trong các paper thường chứa những từ ngữ chuyên ngành đòi hỏi phải tra cứu rất nhiều mà đôi khi không thể tìm được giải thích nào thoả đáng.
Đọc paper có thực sự quan trọng không? Mình nghĩ câu hỏi này không khó có thể trả lời. Nếu bạn muốn tiếp cận AI theo hướng của một Developer thì điều này có thể không cần thiết lắm vì các API và Documentation của các framework là đã đủ với bạn. Tuy nhiên nếu bạn muốn đi xa hơn nữa trên con đường nghiên cứu chuyên sâu thì điều này thực sự cần thiết. Nó giúp bạn hiểu hơn về hệ thống, hiểu hơn về mô hình AI mà các bạn đang làm việc chứ không phải hoàn toàn blackbox nữa. Chính vì lý do này mình muốn tạo ra series này trên Viblo để mong mỏi có sự đóng góp thật nhiều từ cộng đồng AI giúp cho những người có ý định nghiên cứu chuyên sâu về AI có một kênh tham khảo với những nguồn tri thức mới trên chính thứ tiếng mẹ đẻ của mình. Đây cũng là một kênh để mình note lại, ôn tập lại những kiến thức mà mình tìm hiểu được trong quá trình nghiên cứu và làm việc với các thuật toán AI. Rất mong có được sự ủng hộ của mọi người. OK chúng ta bắt đầu thôi nhé.
Đôi nét về paper này
Paper ngày hôm nay chúng ta tìm hiểu đó là BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation. Đây là một paper rất hay trong lĩnh vực segmentation real time. Các bạn có thể tìm thấy paper này ở đây. Trước khi tìm hiểu một paper nào đó để tránh khỏi việc dẫm phải các shit paper khiến chúng ta hoang mang, mất thời gian mà không đem lại kết quả gì thì chúng ta cần phải tìm hiểu xem paper này có đáng để đọc không đã nhé.
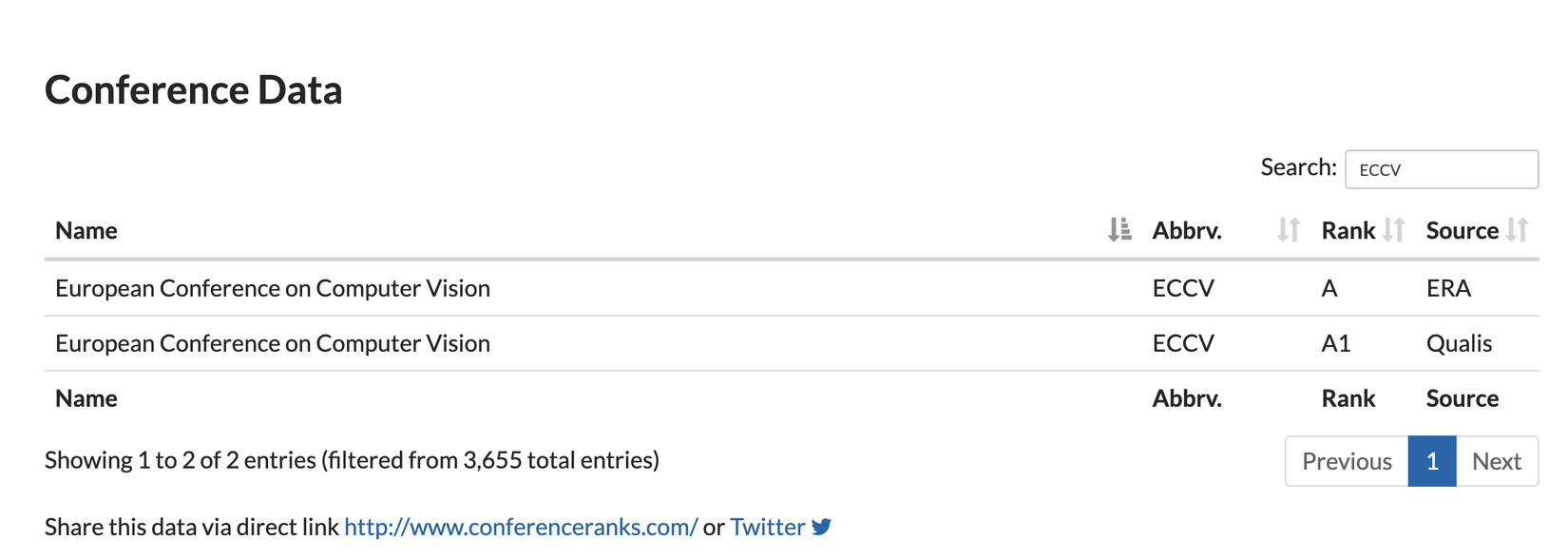
- Hội thảo publish: Đầu tiên là tìm hiểu thử về hội thảo publish paper này. Paper này được submit bởi hội thảo ECCV 2018. Đây là hội thảo hàng đầu về Computer Vision, là một trong những hội thảo đáng mơ ước của giới nghiên cứu trong lĩnh vực Computer Vision. Bạn có thể tìm hiểu thêm về hội thảo này ở Conference Rank nó xếp hạng A trong các hội thảo về AI. Một paper được publish tại hội thảo này thì chắc chắc là không thể nào không có chất lượng tốt được rồi
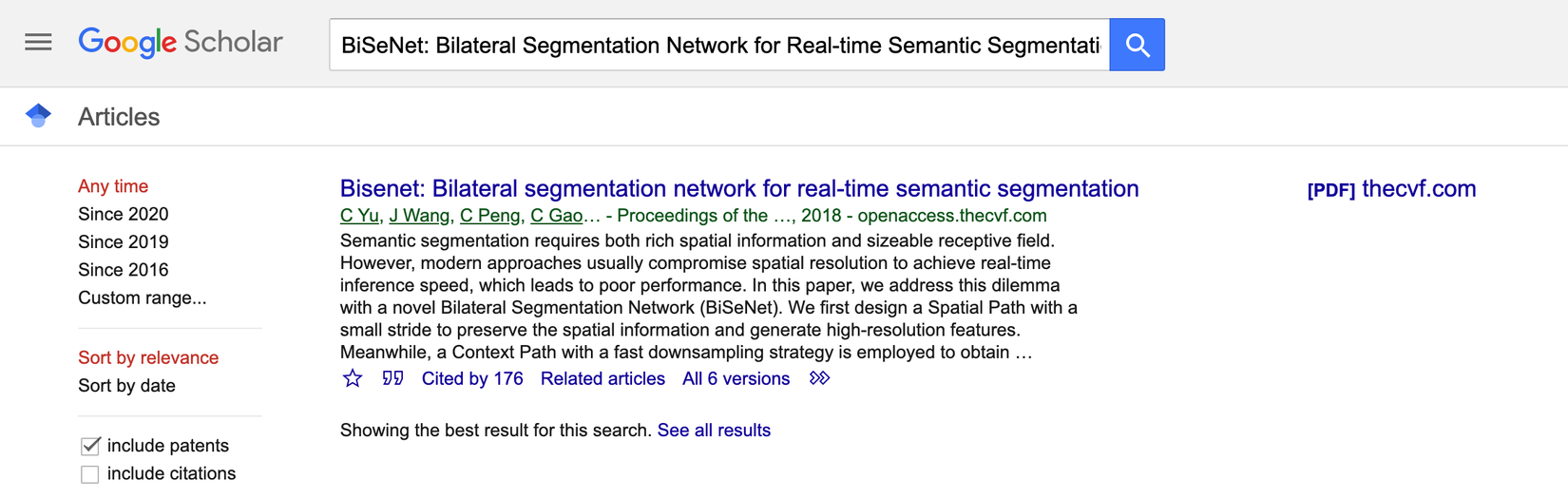
- Danh sách authors: Chúng ta lên Google Scholar tìm kiếm tên của paper này theo link này sẽ thấy số lượt citation của các author đề khá cao điều này chứng tỏ họ là các nhà khoa học uy tín. Và càng chứng minh là paper của chúng ta đáng để tham khảo
OK tìm hiểu sơ qua vậy thôi chúng ta bắt đầu vào vấn đề chính nhé
Vấn đề paper giải quyết
Sơ qua về semantic segmentation
Paper này nói đến một đề tài đã có nhiều nghiên cứu thuộc lĩnh vực Computer Vision đó chính là bài toán Sementic Segmentation. Nói qua một chút về semantic segmentation cho những ai chưa từng nghe đến khái niệm này thì đây là một bài toán trong lĩnh vực Computer Vision nhằm mục đích phân loại từng semantic class cho từng pixel trên ảnh. Ví dụ như bài toán phân loại phương tiện giao thông rất hay gặp trong các project về xe tự lái. Trong bức ảnh bên dưới, nhiệm vụ của model semantic segmentation là phân loại từng pixel và trên ảnh với các class tương ứng. Mọi người có thể tham khảo rõ hơn về bài toán này thông qua các bài viết khác trên Viblo nhé

Giải thích một số khái niệm
Có một vài khái niệm trong paper này mà bạn cần phải tìm hiểu trước khi tiến hành đọc paper này để tránh cho việc đọc một paper trở nên quá khó khăn. Các bạn nhớ đọc kĩ phần này nhé.
Spatial information
Ở paper này thì khái niệm spatial information được nói đến trong context của việc sử dụng mạng CNN. Thực ra mình cũng không biết dịch khái niệm này ra tiếng việt như thế nào (mình định dịch là thông tin không gian nhưng sợ nó hơi khó hiểu nên vẫn để nguyên từ tiếng anh). Tuy nhiên mình có thể giải thích thông qua một số đặc điểm của nó.

Như các bạn thấy nhiều giải thuật xử lý ảnh truyền thống thường không bận tâm nhiều đến việc sắp xếp vị trí của các pixels trên không gian mà chỉ quan tâm đến các đặc tính thống kê của chúng như mean, variance, standard deviation hoặc một số thuộc tính về hình học như cạnh ... Cách làm như thế được coi là không quan tâm đến spatial information. Ngược lại thông qua mạng CNN thì các thông tin này được bảo tồn bởi vì các neurons trong mạng CNN sẽ xử lý từng phần của bức ảnh thông qua filter nên nó không làm mất các đặc trưng liên quan đến sự sắp xếp vị trí cụ thể của các pixel.
Lại nói qua về mạng CNN với vấn đề spatial information thì có các đặc điểm như sau:
- CNN duy trì spatial information của dữ liệu đầu vào: Đối với các mạng multilayer perceptron chẳng hạn thì với bức ảnh thường sẽ được flatten thành một vector 1 chiều sau đó áp dụng các tổ hợp tuyến tính và phi tuyến tính trong quá trình feed forward để đưa ra được các kết quả đầu ra. Còn đối với CNN thì chúng ta giữa nguyên sự phân bố các pixel của dữ liệu đầu vào (có thể tưởng tượng như không thay đổi vị trí toạ độ trên không gian Oxy với 2D image hay đơn giản hơn nữa là một khẩu hiệu quen thuộc trong mấy ngày gần đây Pixel nào ở đâu thì giữ nguyên tại vị trí tại đó.) và áp dụng các filter lên các pixels gần nhau trong không gian để trích xuất ra đặc trưng. Điều này cho phép CNN có thể xử lý được các đối tượng trong không gian như edges, shape hay bounding box một object.
- Các spatial information cũng được thể hiện trong các bộ lọc: Tại các filters trong CNN cũng thể hiện các spatial information của partern mà chúng đang thể hiện (ví dụ các partern tai, mắt, mũi trong bức ảnh khuôn mặt). Khi xếp chồng các bộ lọc và thông qua các phép tính tích chập thì tại mỗi filter sẽ chỉ ra sự tương quan giữa các pixels trên filter tương ứng với dữ liệu đầu vào như thế nào.
- Việc pooling, down sampling, đi qua các lớp fully connected sẽ làm mất đi một vài spatial information: Việc áp dụng các thao tác pooling làm cho mạng CNN tránh được overfit với dữ liệu training đồng thời thời gian training mạng cũng được cải thiện tuy nhiên nó cũng có đặc điẻm là làm mất đi thông tin không gian hay vị trí của các pixels. Hãy tưởng tượng việc max pooling giống như việc chọn ra một người giỏi nhất trong một trường học, vậy thì dù người đó nằm ở lớp nào trong trường (tức thông tin vị trí) cũng đều không quan trọng. Nếu không có pooling (bản chất là max/average các tương quan kể trên) thì một thay đổi nhỏ ở pixel đầu vào trong dữ liệu cũng làm ảnh hưởng đến spatial information của các layer tiếp theo.
Receptive field
Đây là một khái niệm cũng được sử dụng trong khi thiết kế mạng CNN. Khi nói đến receptive field hay trường quan sát hay có thể gọi là vùng nhìn thấy tức là nói đến một unit trong một layer nhất định trong mạng CNN. Không giống như mạng fully connected, nơi mà giá trị của mỗi unit sẽ phụ thuộc vào toàn bộ các input unit của layer trước đó, mỗi unit trong CNN phụ thuộc chỉ vào một vùng nhất định region of input. Vùng này được gọi là receptive field của unit này. Có thể hình dung nó như hình dưới
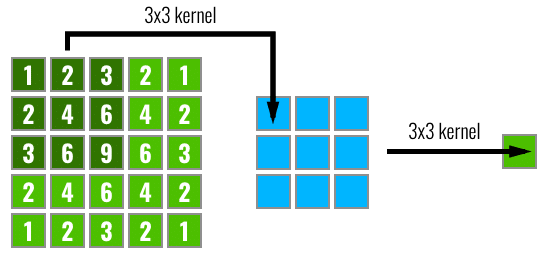
Note: Bạn có thể liên hệ một cách Receptive field với câu chuyện Ếch ngồi đáy giếng nổi tiếng. Một Unit tương ứng như một con ếch, cái đáy giếng như một filter và bầu trời rộng lớn chính là dữ liệu dầu vào. Khoảng không gian con ếch nhìn được qua cái giếng chính là Receptive field vậy. Muốn có một Receptive field lớn hơn thì có hai cách. Một là mở rộng cái đáy giếng ra (sử dụng một Kernel lớn hơn) hai là nén bầu trời lại chỉ nhỏ bằng diện tích của cái miệng giếng (lúc đó đương nhiên nó sẽ nhìn thấy cả bầu trời). Vui một chút thôi, chúng ta tiếp tục nhé
Global Average Pooling (GAP)
Global Average Pooling là một khái niệm khá phổ biến gần đây trong việc thiết kế các mạng nơ ron đặc biệt là mạng nơ ron tích chập CNN. Nó là một phương pháp giúp giảm thiếu việc overfiting bằng cách giảm số lượng tham số trong model. Tương tự như max pooling, GAP cũng sử dụng để giảm chiều của features map khi đi qua lớp đó bằng cách xấp xỉ giá trị của một features map hoặc regions của features map bằng giá trị trung bình các thành phần trong đó. Ví dụ nếu muốn chuyển một tesnor với số chiều về thì GAP sẽ thực hiện với mỗi feature map sẽ được thay bằng 1 số có giá trị trung bình của feature map đó. Có thể hình dung dễ dàng qua hình sau

Tóm tắt nội dung chính
Sau khi các bạn đã nắm được một số khái niệm kể trên chúng ta sẽ bắt đầu tìm hiểu vào nội dung chính của paper này nhé.
Tư tưởng chính
Semantic segmentation là một bài toán yêu cầu cả hai yếu tố rich spatial information tức hạn chế tối đa việc mất mát các thông tin không gian và một sizeable receptive field tức đa dạng về receptive field. Tuy nhiên đối với các phương pháp tiếp cận mới nhất cho bài toán realtime segmentation thường đánh đổi các spatial information để đạt được tốc độ xử lý real time. Điều này khiến cho độ chính xác của phương pháp có thể bị giảm sút. Trong paper này sẽ giải quyết vấn đề khó xử đó bằng cách sử dụng một kiến trúc mạng Bilateral Segmentation Network (BiSeNet): có thể dịch là mạng segmentation song phương. Tư tưởng chính của nó đó là sử dụng hai backbone cho kiến trúc. Một gọi là Spatial Path với bước nhảy nhỏ để bảo toàn spatial information giúp tìm được các đặc trưng tốt hơn. Hai đó là Context Path với chiến lược down sampling nhanh giúp thu được đa dạng receptive field. Trên top của mỗi path này, tác giả giới thiệu một module mới là Feature Fusion Module giúp tăng hiệu quả khi combine các features. Lát nữa chúng ta sẽ đi sâu tìm hiểu về module này. Kiến trúc này của tác giả đạt được sự cân bằng giữa hiệu quả segmenetation và tốc độ. Đặc biệt trên tập Cityscapes họ đạt được 64.8% Mean IOU với tốc độ 105FPS trên phần cứng NVIDIA Titan XP nhanh hơn đáng kể với các phương pháp trước đó với cùng một độ chính xác.
Các hướng giải quyết hiện tại
Cho đến thời điểm viết paper này, theo tác giả có các hướng giải quyết sau cho bài toán real time segmentation.
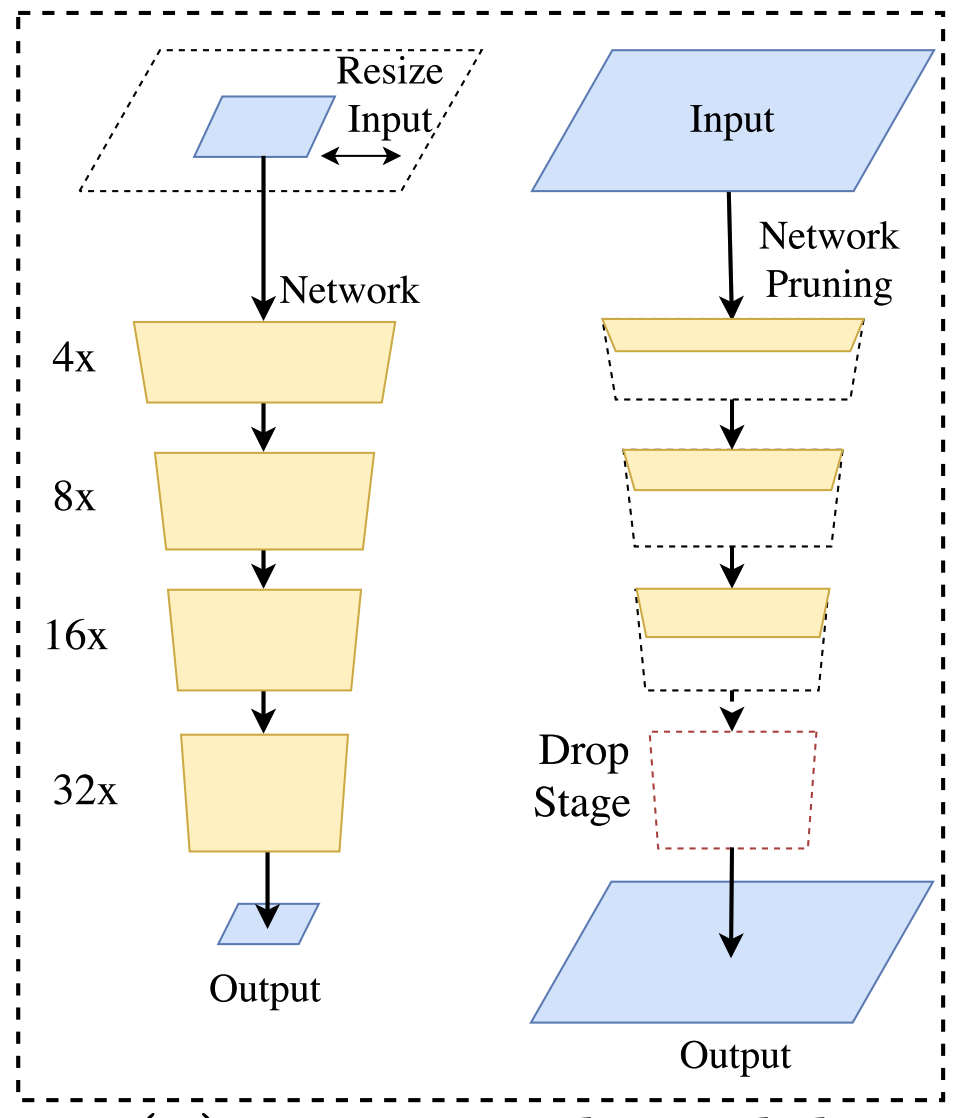
- Thứ nhất: các đơn giản nhất đó là hạn chế lại input size của ảnh đầu vào bằng cách resize hay cropping khiến cho số lượng tính toán của mô hình giảm đi đáng kể. Cách làm này khá đơn giản và hiệu quả tuy nhiên việc resize hay crop này làm cho ảnh mất đi các thông tin về spatial nên khiến cho model dự đoán các vùng segmentation bị sai đặc biệt là tại các ranh giới giữa các object. Có thể tham khảo một số paper áp dụng phương pháp này như Real- time Image Segmentation via Spatial Sparsity hay ICNet for Real-Time Semantic Segmentation on High-Resolution Images
- Thứ hai: Thay vì resize trực tiếp trên ảnh đầu vào thì chúng ta có thể cắt tỉa trong một số thành phần của mạng khiến cho số lượng tham số của mạng sẽ được giảm đi và đi theo nó đó là số lượng tính toán sẽ được giảm theo tuy nhiên việc giảm số lượng tham số trong mạng cũng là giảm theo việc chứa các thông tin liên quan dến spatial
- Thứ ba: Cuối cùng, hướng giải quyết của ENet (efficient neural network) là ngoài việc sử dụng downsampling ở những state đầu của mô hình giúp cho kích thước của feature trong mạng giảm đi nhanh chống gióng cho cải thiện tốc độ. Về kiến trúc encoder-decoder, Enet cũng không thiết kế đối xứng như các mạng thông thường mà thiết kế với một larger encoder và một smaller decoder. Để làm được điều đó, Enet chấp nhận bỏ đi một vài downsampling operator tại các last state của encoder và thay vào đó là upsapmling để thu được kích thước ban đầu. Tuy nhiên việc bỏ đi các downsampling cũng chính là hạn chế đi receptive field tại các unit ở các state cuối dẫn đến độ chính xác của kết quả phân lớp không cao, nhất là với các object kích thước lớn
Note tất cả các phương pháp kể trên đều đánh đổi độ chính xác để cải thiện tốc độ. Có thể hình dung hoạt động của các model trong figure dưới. Mạng bên trên trái thể hiện cropping và resize trên image size. Mạng bên phải thể hiện thao tác cắt tỉa mạng và drop các last stage.
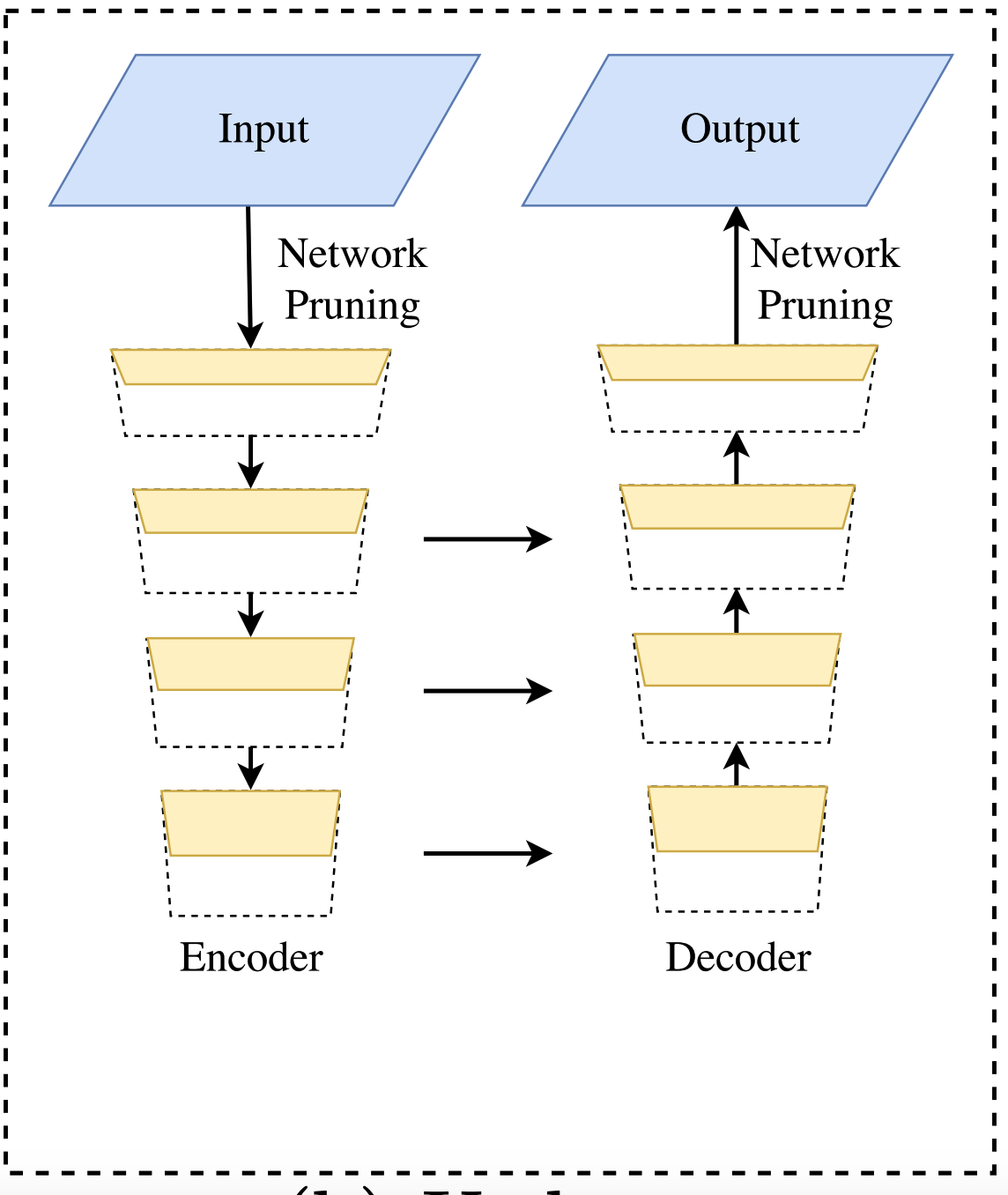
Cách giải quyết của U-shape Architecture
Để khắc phục việc mất mát statial information thì tác giả có đề cập đến kiến trúc mạng U-Shape trong đó các thông tin spatial sẽ được kế thừa lại các đặc trưng từ backbone network. Cấu trúc Unet tăng dần độ phân giải của feature và lấp đầy một số chi tiết còn thiếu. Tuy nhiên cấu trúc này tồn tại một số nhược điểm:
- Giảm tốc độ do số lượng tính toán của U-shape khá lớn với một bức ảnh có độ phân giải cao
- Mất mát một số thông tin spatial bị mất trong quá trình cắt tỉa và cropping khó có thể khổi phục lại được
Dưới đây là kiến trúc mạng của U-shape
Đóng góp chính của paper
Dựa trên những điểm trên, tác giả của paper này đề xuất một cách giải quyết mới cho bài toán semantic segmentation nhằm cân bằng giữa tốc độ và độ chính xác. Kiến trúc đề xuất có tên là Bilateral Segmentation Network(BiSeNet) bao gồm hai thành phần là Spatial Path (SP) và Context Path (CP)
Spatial Path (SP)
Spatial Path (SP) được tác giả thiết kế với stride nhỏ giúp cho việc bảo toàn spatial information và sinh ra các features với độ phân giải cao. SP chứa 3 khối. Mỗi khối chứa 1 lớp convolution với stride = 2. Tiếp theo đố là một lớp batch normalization và cuối cùng là một activation ReLU. Do đó output đầu ra của khối SP sẽ có kích thước bằng 1/8 so với kích thước của ảnh gốc. Nhiệm vụ để encode các rich spaital information thông qua các feature maps có kích thước lớn. Kiến trúc của mạng được mô tả trong hình sau
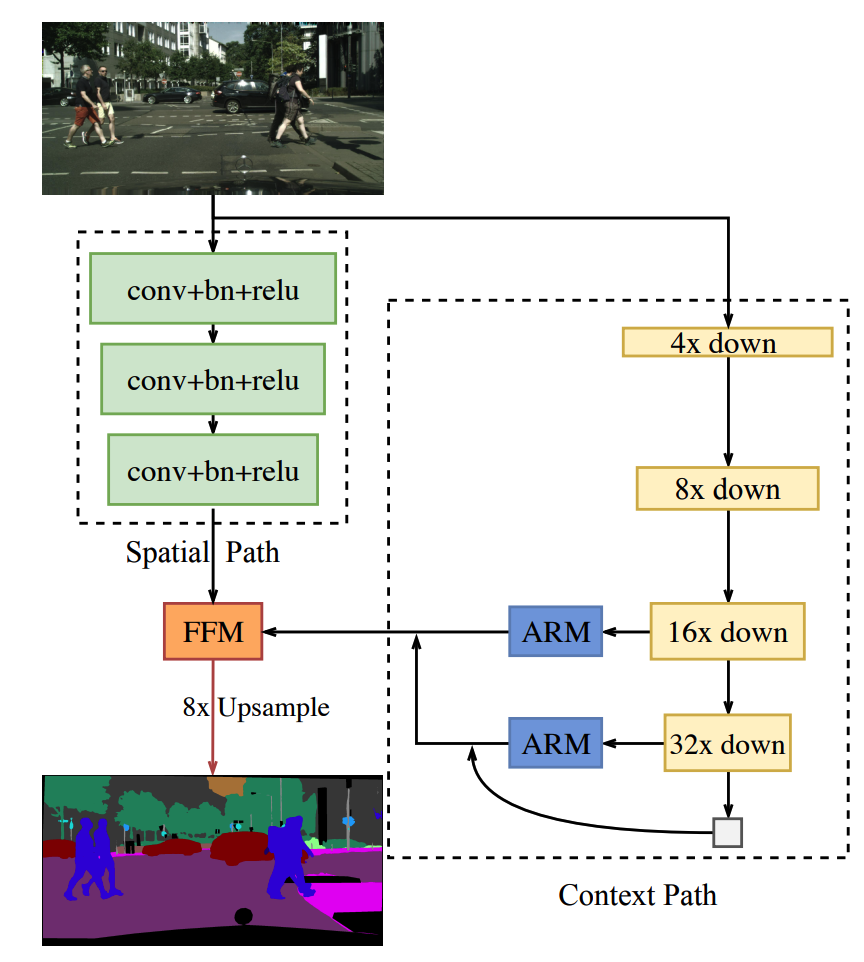
Context Path (CP)
Trong khi SP được thiết kế nhằm mục đích lưu trữ các rich statisl information thì CP được tác giả thiết kế để cung cấp đầy đủ receptive field. Đối với bài toán semantic segmentation thì các thông tin về receptive field là rất quan trọng đến độ chính xác của mô hình. Để đạt được điều này thì có một số phương pháp áp dụng như sủe dụng Pyramid pooling module hay sử dụng một kernel lớn hơn. Tuy nhiên các giải pháp phía trên đòi hỏi việc tính toán khá nhiều và làm cho tốc độ sẽ bị chậm đi. Để khắc phục điểm đó thì tác giả đã tận dụng lightweight model (là các pretrained model có số lượngt tham số nhỏ như Xception hay các họ Resnet) sau đó kết hợp với global average pooling để tạo ra một receptive field đa dạng hơn. Một số model như Xception có thể downsampling feature map rất nhanh giúp tạo ra các receptive field đa dạng. Khi add thêm global averange pooling vào cuối của lightweight model sẽ giúp cho các receptive field sẽ chứa được global context information nhiều nhất có thể.
Attention refinement module (ARM)
Trong Context Path có chưa một module gọi là Attention refinement module với mục đích tinh lọc các features sau mỗi state.
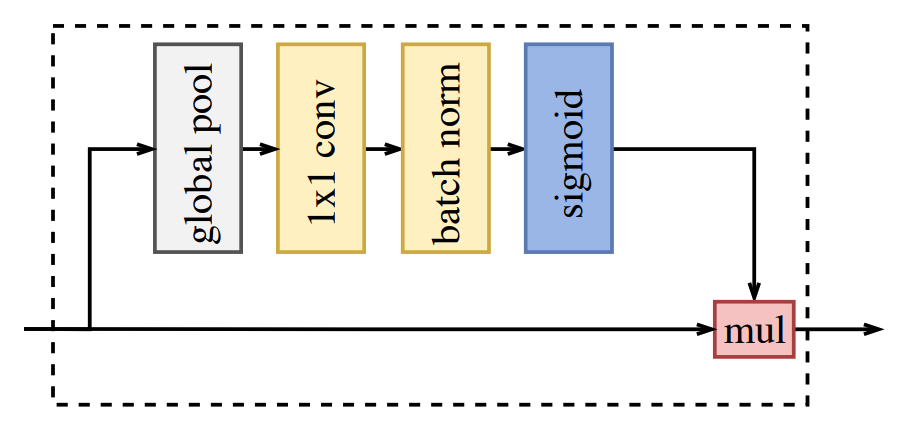
Giống như trên sơ đồ phía trên thì ARM sẽ sử dụng GAP để capture các thông tin về ngữ cảnh và tính toán một attention vector sử dụng cho việc học features. Với mỗi state của context path thì feature đều được tinh chỉnh lại thông qua ARM và các thông tin về context sẽ được tích luỹ dễ dàng hơn mà không cần đến việc up-smapling khiến cho chi phí tính toán không đáng kể.
Kiến trúc mạng
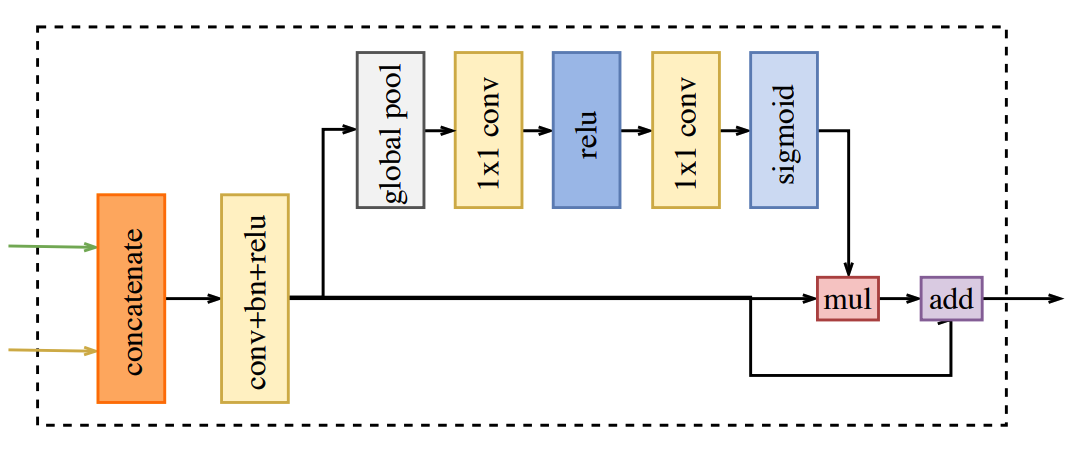
Feature Fusion Module
Trong paper, tác giả đề xuất sử dụng mô hình pre-trained của Xception làm backbone cho Context Path và 3 lớp tích chập với stride = 2 trong Spatial Path. Các output feature của hai path này sẽ được kết hợp lại để đưa ra kết quả dự án cuối cùng. Kết quả của Spatial Path thể hiện mức độ chi tiết ở mức low level (ví dụ như đường biên của các object, các góc cạnh ...) còn đầu ra của Context Path ở mức high-level tức thể hiện thông tin ngữ cảnh của bức ảnh. Để kết hợp hai output feature này thì tác giả sử dụng một module gọi là Feature Fusion Module. FFM thực hiện các việc sau:
- Concatenate để kết hợp hai output feature của 2 path việc đầu tiên của FFM đó là concate chúng lại với nhau
- Batch Normalization áp dụng trên vector vừa concate với mục đích cân bằng và chuyển scales của các features.
- Đưa qua pooling và convolution sau đó features được đưa qua các lớp pooling và convolution để thu được weight cuôi cùng.
Module này được mô tả trong hình sau:
Loss function
Trong paper tác giả sử dụng một hàm loss chính cho toàn mạng BiSeNet và hai hàm loss phụ trợ để điều chỉnh tham số trong quá trình tối ưu. Tất cả các hàm loss đều là hàm Softmax như công thức bên đưới
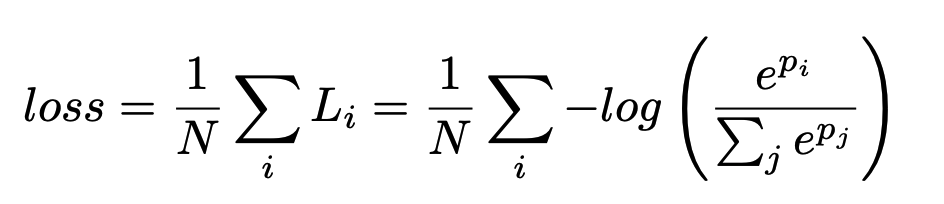
Có một hệ số được sử dụng để thể hiện mức độ kết hợp của hàm loss chính và các hàm loss phụ trợ như công thức trình hình sau
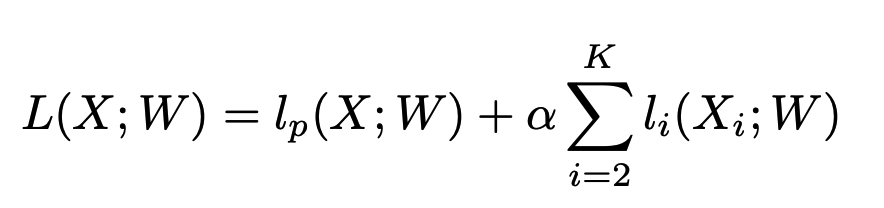
trong đó là hàm loss chính và là các hàm loss phụ trợ tương ứng với state thứ trong Context Path. Trong paper này thì tác giả chọn tức là có hai hàm loss phụ trợ
Các kết quả thí nghiệm
Đây là một số hình ảnh minh hoa kết quả của paper.
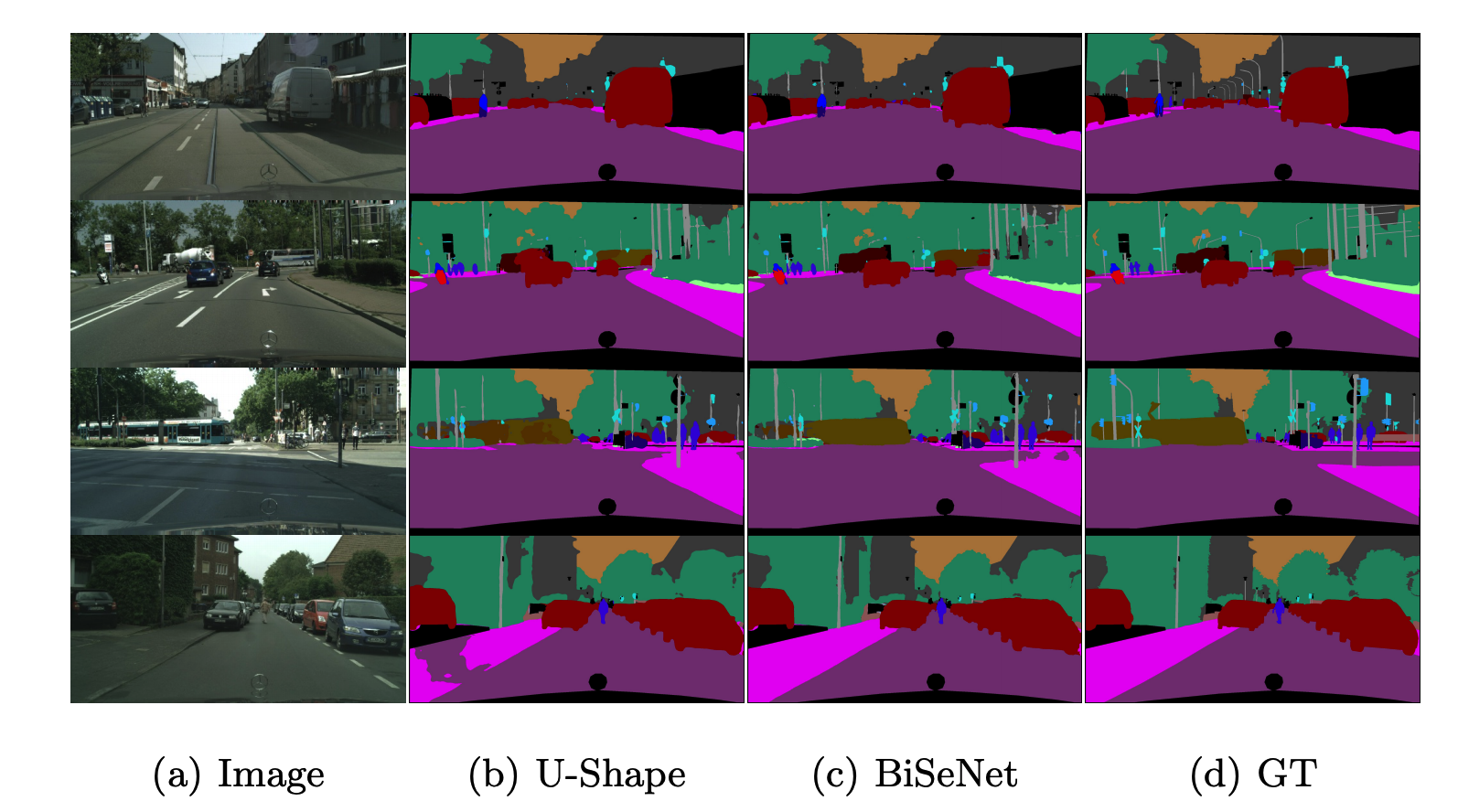
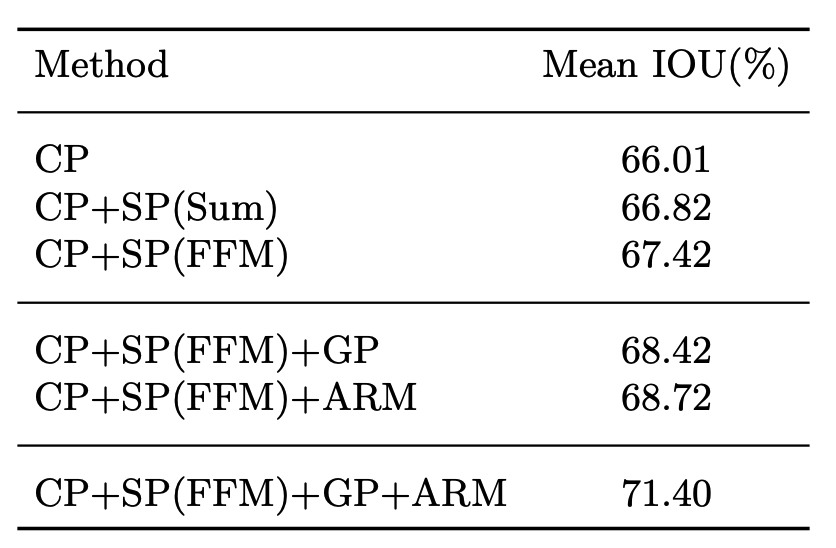
Có thể thấy chất lượng của mô hình BiSeNet cũng cho kết quả tương đương với cấu trúc Unet. Sau đây là mức độ ảnh hưởng của các thành phần trong mạng. Có thể thấy khi kết hợp đủ các thành phần trong mạng thì cho kết quả mIOU tốt nhất là 71.4%
Tốc độ của phương pháp này đạt được cũng khá đáng nể với cùng một kích thước ảnh đầu vào thì tốc độ của phương pháp này đều vượt trội hơn các phương pháp khác kể cả Enet
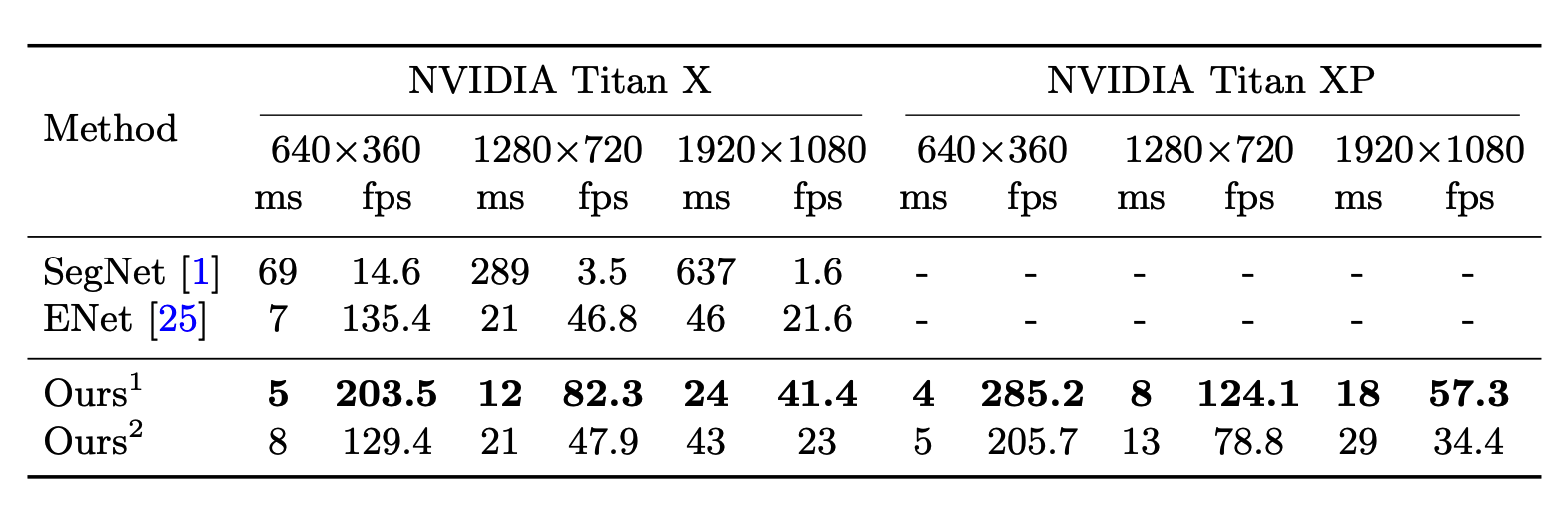
Trong đó 2 base model lần lượt là Xception19 và Resnet18. Tác giả có rất nhiều các so sánh khác đã viết chi tiết trong paper nhưng mình không đề cập ở đây vì nó hơi nhiều và sẽ làm cho bài viết quá dài. Bây giờ chúng ta sẽ bắt đầu sang phần được mong chờ nhất của bài viết này đó là implement thử thuật toán thôi.
Implement thử
Mình dám chắc là có nhiều bạn đã bỏ qua phần bên trên và đi xuống đọc luôn phần này nhưng nếu các bạn đã đọc rồi thì xin cảm ơn bạn vì bạn thực sự kiên nhẫn. Có ai đó từng nói rằng Talk is cheap, show me your code thì cũng đúng thôi, đọc paper mà không implement lại được thì cũng chẳng có tác dụng gì phải không .Vậy bây giờ chúng ta bắt đầu tiến hành implement BiSeNet thôi nào
Build Spatial Path
Như tiêu đề của bài viết thì mình sẽ sử dụng Pytorch để implement mạng này. Đây cũng có thể coi là một trong như mạng khá hay và phức tạp trong cách implement nó nên chúng ta sẽ tách nhỏ thành từng module cho dễ dàng control nhé. Đầu tiên là implement Spatial Path. Chúng ta hay xem lại khối này trên hình minh hoạ trong paper
 Có thể thấy nó bao gồm 3 khối màu xanh lặp lại nên chúng ta sẽ code khối nhỏ này trước.
Có thể thấy nó bao gồm 3 khối màu xanh lặp lại nên chúng ta sẽ code khối nhỏ này trước.
Implement khối Convulution + Batch normalize + Relu
Trước tiên là import các thư viện cần thiết
import os
import torch
import numpy as np
from torch import nn
from PIL import Image
from glob import glob
from torchvision import models
import torch.nn.functional as F
# Build data loader
from tqdm import tqdm
from torchvision import transforms
from collections import OrderedDict
from torch.utils.data import DataLoader, Dataset
Sau đó là implement khối màu xanh
# Define the base Convolution block
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=2, padding=1):
super().__init__()
# Head of block is a convulution layer
self.conv1 = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding
)
# After conv layer is the batch noarmalization layer
self.batch_norm = nn.BatchNorm2d(out_channels)
# Tail of this block is the ReLU function
self.relu = nn.ReLU()
def forward(self, x):
# Main forward of this block
x = self.conv1(x)
x = self.batch_norm(x)
return self.relu(x)
Nhìn vào hàm forward() các bạn có thể đoạn được luồng hoạt động của hàm này rồi chứ. Rất đơn giản đúng không. Dữ liệu sẽ đi qua lớp convolution sau đó đi qua batch normalization và cuối cùng là qua activation ReLU. Không có gì khó khăn cả phải không. Chúng ta đi tiếp nhé
Implement Spatial Path
Như đã nói ở trên rồi, Spatial Path sẽ thông qua 3 khối màu xanh. Do đó chúng ta chỉ cần ghép chúng lại là xong
# Define the Spatial Path with 3 layers of ConvBlock
class SpatialPath(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = ConvBlock(in_channels=3, out_channels=64)
self.conv2 = ConvBlock(in_channels=64, out_channels=128)
self.conv3 = ConvBlock(in_channels=128, out_channels=256)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return self.conv3(x)
Nhìn vào hàm forward() có thể dễ dàng thấy luồng đi của dữ liệu. Các bạn muốn xem thử dữ liệu sẽ đi qua Spatial Path như thế nào thì có thể summary riêng module này để xem thử. Đầu tiên là khai báo biến
spatial_path = SpatialPath()
spatial_path = spatial_path.cuda()
Sau đó là summary
from torchsummary import summary
summary(spatial_path, (3, 256, 256))
Két quả thu được như sau
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 128, 128] 1,792
BatchNorm2d-2 [-1, 64, 128, 128] 128
ReLU-3 [-1, 64, 128, 128] 0
ConvBlock-4 [-1, 64, 128, 128] 0
Conv2d-5 [-1, 128, 64, 64] 73,856
BatchNorm2d-6 [-1, 128, 64, 64] 256
ReLU-7 [-1, 128, 64, 64] 0
ConvBlock-8 [-1, 128, 64, 64] 0
Conv2d-9 [-1, 256, 32, 32] 295,168
BatchNorm2d-10 [-1, 256, 32, 32] 512
ReLU-11 [-1, 256, 32, 32] 0
ConvBlock-12 [-1, 256, 32, 32] 0
================================================================
Total params: 371,712
Trainable params: 371,712
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 56.00
Params size (MB): 1.42
Estimated Total Size (MB): 58.17
----------------------------------------------------------------
Có thể thấy qua Spatial Path kích thước của Feature giảm đi 1/8 so với ban đầu giống như trong mô tả của paper. Với các module sau các bạn cũng có thể tự summary để thấy rõ. Còn mình sẽ chỉ giải thích ý nghĩa thôi chứ không summary nhiều thì bài viết sẽ dài quá mất. OK tiếp tục thôi nào.
Build Context Path
Phần tiếp theo chúng ta cần xây dựng đó chính là Context Path. Nó được mô tả trong paper là một khối giúp down sample rất nhanh (tới 32X kích thước lúc đầu) sử dụng các pretrained model light weight làm bộ feature extractor sau đó kết hợp với GAP. Hình dung kĩ hơn về thành phần này như hình sau
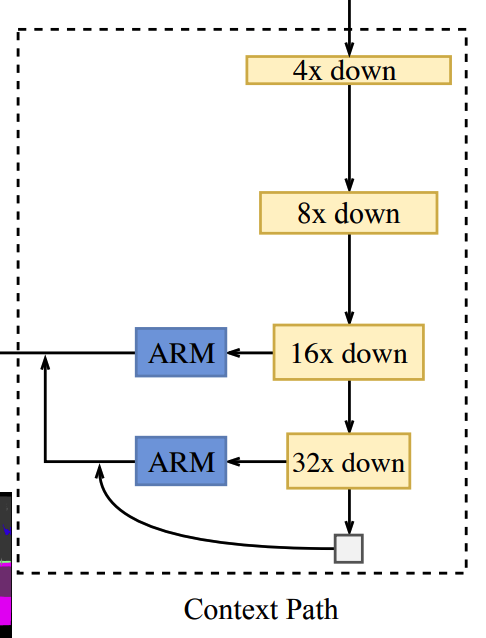
Và đây là implement của nó
# Build context path
class ContextPath(nn.Module):
def __init__(self, pretrained=True):
super().__init__()
self.features = models.resnet18(pretrained=pretrained)
self.conv1 = self.features.conv1
self.bn1 = self.features.bn1
self.relu = self.features.relu
self.max_pool = self.features.maxpool
self.layer1 = self.features.layer1
self.layer2 = self.features.layer2
self.layer3 = self.features.layer3
self.layer4 = self.features.layer4
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
def forward(self, x_input):
# Get feature from lightweight backbone network
x = self.conv1(x_input)
x = self.relu(self.bn1(x))
x = self.max_pool(x)
# Downsample 1/4
feature1 = self.layer1(x)
# Downsample 1/8
feature2 = self.layer2(feature1)
# Downsample 1/16
feature3 = self.layer3(feature2)
# Downsample 1/32
feature4 = self.layer4(feature3)
# Build tail with global averange pooling
tail = self.avg_pool(feature4)
return feature3, feature4, tail
Nhìn vào phần trên chúng ta có các thành phần sau:
- Feature extractor: theo như trong paper thì tác giả sử dụng XCeption để implement tuy nhiên do trong Pytorch không có sẵn pretrained model này nên mình sử dụng
resnet18để thay thế nó. Các bạn có thể thấy việc sử dụng này đơn giản như sau
self.features = models.resnet18(pretrained=pretrained)
self.conv1 = self.features.conv1
self.bn1 = self.features.bn1
self.relu = self.features.relu
self.max_pool = self.features.maxpool
self.layer1 = self.features.layer1
self.layer2 = self.features.layer2
self.layer3 = self.features.layer3
self.layer4 = self.features.layer4
Tất cả các layer, các lớp batch normaliztion, maxpool đều được lấy trực tiếp từ mạng cơ sở này.
- Feature 3 và Feature 4: Đây là hai lớp tương ứng với đầu ra của khối 16X và 32X trong hình vẽ. Khối này sẽ được đưa và ARM như trên hình.
- Xây dựng tail: Tail của Contexxt Path sẽ được xây dựng bằng cách lấy Global Average Pooling của Feature 4.
- Đầu ra của mạng: đầu ra sẽ bao gồm 3 thành phần giống như 3 đường mũi tên trên thành vẽ. Bao gồm Feature3, Feature 4 sẽ đi qua ARM và Tail (hình vuông nhỏ màu xám). Ba đại lượng này sẽ được kết hợp với đầu ra của Spatial Path thông qua FFM.
Build các module phụ
Như đã mô tả kĩ trong paper thì các module phụ này đảm nhận các chức năng riêng biệt như mô tả phía trên. Chúng ta sẽ tiến hành implement chúng nhé.
Attention Refinement Module (ARM)
Cho bạn nào lười cuộn lại bên trên thì module này được mô tả như hình sau :
Nó bao gồm 2 nhánh:
- Nhánh 1 chính là dữ nguyên dữ liệu đầu vào
- Nhánh 2 là đường phía trên đi qua 4 khối lần lượt là Global Pooling => Convolution => Batch Normalization và cuối cùng là hàm kích hoạt sigmoid
Ta implement nó như sau:
# Attention Refinement Module
class AttentionRefinementModule(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1)
self.bn = nn.BatchNorm2d(out_channels)
self.sigmoid = nn.Sigmoid()
self.in_channels = in_channels
def forward(self, x_input):
# Apply Global Average Pooling
x = self.avg_pool(x_input)
assert self.in_channels == x.size(1), 'in_channels and out_channels should all be {}'.format(x.size(1))
x = self.conv(x)
x = self.bn(x)
x = self.sigmoid(x)
# Channel of x_input and x must be same
return torch.mul(x_input, x)
Cũng chưa có gì khó khăn lắm. Module tiếp theo chúng ta cần phải implement đó chính là Feature Fusion Module
Feature Fusion Module (FFM)
Theo như kiến trúc mạng tổng thể chúng ta thấy ở các phần trên thì module này sẽ làm nhiệm vụ tổng hợp lại Feature của Spatial Path và Context Path sau đó Upsample để thu được ảnh output như hình bên dưới.
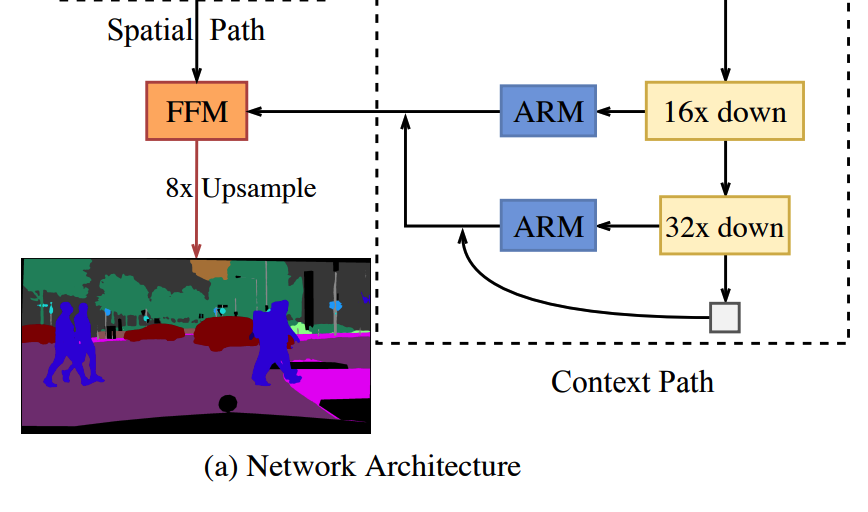
Kiến trúc chi tiết của Module này được mô tả như hình bên dưới
Theo đố 2 feature đầu vào sẽ được concate thành 1 ma trận duy nhất (khối màu da cam). Tiếp theo đó nó được đưa qua khối Convolution để extract đặc trưng. Sau đó dữ liệu được chia thành 2 nhánh, phía dưới và phía trên. Đầu ra của hai nhánh được tổng hợp với nhau bằng phép nhân ma trận (ô vuông nhỏ màu hồng) và cuối cùng là phép cộng ma trận (ô vuông nhỏ màu tím). Chúng ta có thể implement nó như sau:
# Define Feature Fusion Module
class FeatureFusionModule(nn.Module):
def __init__(self, num_classes, in_channels):
super().__init__()
self.in_channels = in_channels
self.conv_block = ConvBlock(in_channels=in_channels, out_channels=num_classes, stride=1)
self.conv1 = nn.Conv2d(in_channels=num_classes, out_channels=num_classes, kernel_size=1)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=num_classes, out_channels=num_classes, kernel_size=1)
self.sigmoid = nn.Sigmoid()
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
def forward(self, x_input_1, x_input_2):
x = torch.cat((x_input_1, x_input_2), dim=1)
assert self.in_channels == x.size(1), 'in_channels of ConvBlock should be {}'.format(x.size(1))
feature = self.conv_block(x)
# Apply above branch in feature
x = self.avg_pool(feature)
x = self.relu(self.conv1(x))
x = self.sigmoid(self.conv2(x))
# Multipy feature and x
x = torch.mul(feature, x)
# Combine feature and x
return torch.add(feature, x)
Build BiSeNet
Việc còn lại cuối cúng đó là ghép tất cả các module lại thành 1 kiến trúc mạng tổng thể. Việc này thực ra cũng không khó lắm nếu như các bạn đã chia nhỏ thành các module như phía trên. Tuy nhiên sẽ rất khó khăn nếu như các bạn implement nó ngay từ đầu vì nó sẽ trở nên hỗn độn rất khó kiểm soát. Đầu tiên chúng ta cần định nghĩa các khối cần thiết trong hàm __init__()
# Define BiSeNet
class BiSeNet(nn.Module):
def __init__(self, num_classes, training=True):
super().__init__()
self.training = training
self.spatial_path = SpatialPath()
self.context_path = ContextPath()
self.arm1 = AttentionRefinementModule(in_channels=256, out_channels=256)
self.arm2 = AttentionRefinementModule(in_channels=512, out_channels=512)
# Supervision for calculate loss
self.supervision1 = nn.Conv2d(in_channels=256, out_channels=num_classes, kernel_size=1)
self.supervision2 = nn.Conv2d(in_channels=512, out_channels=num_classes, kernel_size=1)
# Feature fusion module
self.ffm = FeatureFusionModule(num_classes=num_classes, in_channels=1024)
# Final convolution
self.conv = nn.Conv2d(in_channels=num_classes, out_channels=num_classes, kernel_size=1)
Chúng ta thấy có các module như SpatialPath, ContextPath, 2 ARM, 1 FFM ngoài ra còn có thêm 3 mạng Convolution để nhằm mục đích đưa ra output cho các hàm loss. Cần nhớ rằng chúng ta có 3 hàm loss tương ứng với đầu ra của 2 ARM trong ContextPath và đầu ra của lớp Upsample sau khi FFM. Các thể hiện này sẽ rõ ràng hơn trong hàm forward()
def forward(self, x_input):
# Spatial path output
sp_out = self.spatial_path(x_input)
# Context path output
feature1, feature2, tail = self.context_path(x_input)
# apply attention refinement module
feature1, feature2 = self.arm1(feature1), self.arm2(feature2)
# Combine output of lightweight model with tail
feature2 = torch.mul(feature2, tail)
# Up sampling
size2d_out = sp_out.size()[-2:]
feature1 = F.interpolate(feature1, size=size2d_out, mode='bilinear')
feature2 = F.interpolate(feature2, size=size2d_out, mode='bilinear')
context_out = torch.cat((feature1, feature2), dim=1)
# Apply Feature Fusion Module
combine_feature = self.ffm(sp_out, context_out)
# Up sampling
bisenet_out = F.interpolate(combine_feature, scale_factor=8, mode='bilinear')
bisenet_out = self.conv(bisenet_out)
# When training model
if self.training is True:
feature1_sup = self.supervision1(feature1)
feature2_sup = self.supervision2(feature2)
feature1_sup = F.interpolate(feature1_sup, size=x_input.size()[-2:], mode='bilinear')
feature2_sup = F.interpolate(feature2_sup, size=x_input.size()[-2:], mode='bilinear')
return bisenet_out, feature1_sup, feature2_sup
return bisenet_out
Mình đã comment khá đầu đủ trong code rồi nên hi vọng các bạn có thể hiểu được. Riêng việc tính toán các feature1_sup và feature2_sup chỉ cần thiết trong quá trình training thôi nhé. Bây giờ sẽ bước sang phần training của mạng
Train model với CamVid Dataset
Xây dựng DataLoader
Đây là dataset được mô tả trong paper gốc nên mình sẽ không mô tả chi tiết về nó ở đây. Các bạn tải nó về và giải nén trong cùng thư mục. Link tải dataset tại đây. Nó gồm các thư mục ảnh gốc, label và file mapping các class
Trong đó cũng giống như các tập dữ liệu segmentation khác thì ground truth là các mask với các màu khác nhau tương ứng với các class khác nhau
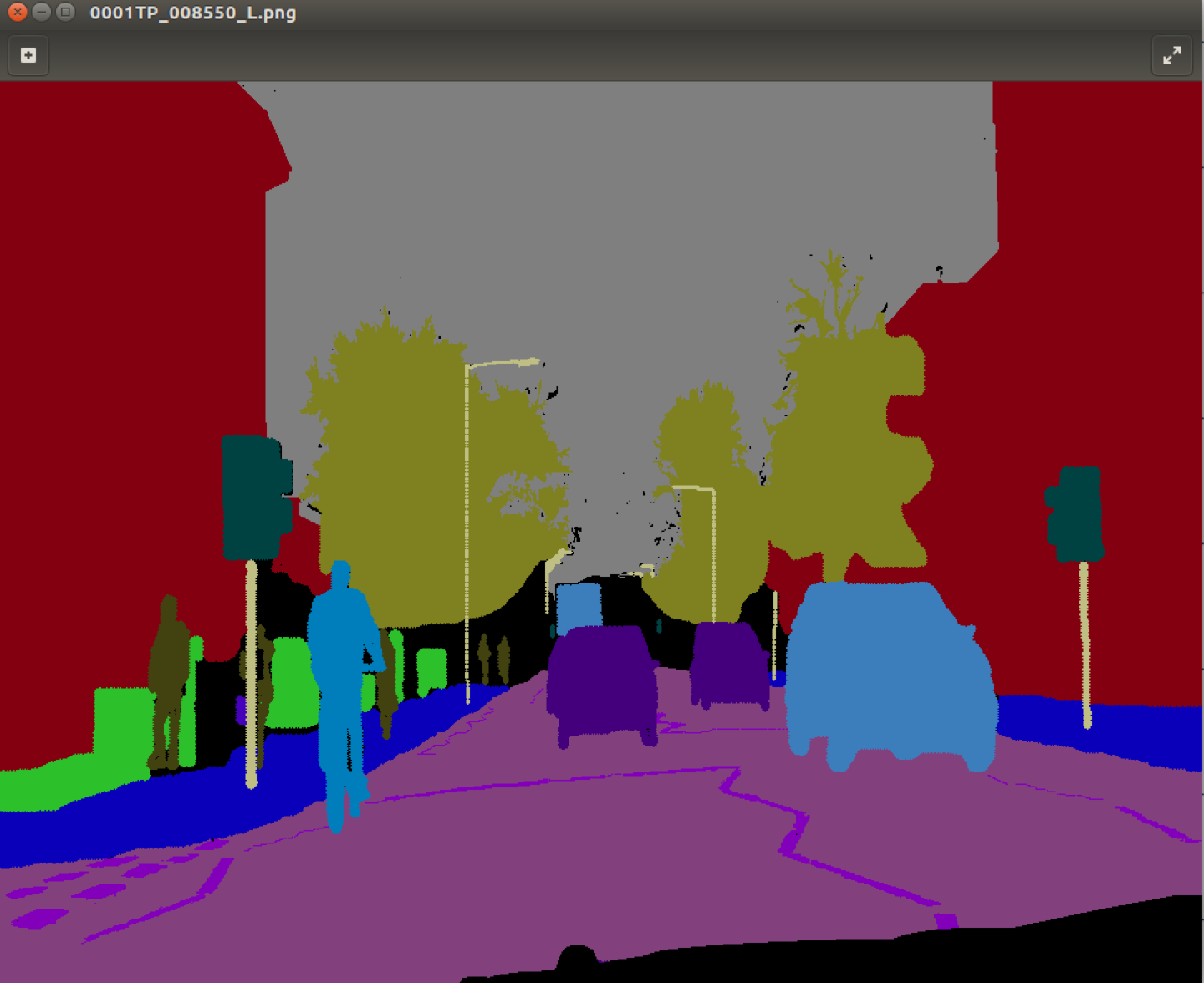
Chúng ta xây dựng dataloader bao gồm các thành phần sau
- Color Mapping: Thành phần này để mapping từ mã màu ra class tương ứng. Đúng ra các bạn sẽ phải đọc từ file CSV trong dataset ra nhưng ở tại đây mình sẽ làm luôn cho các bạn. Chúng ta khởi tạo class
CamVidDatasetnhư sau
class CamVidDataset(Dataset):
# Default encoding for pixel value, class name, and class color
color_encoding = [
('sky', (128, 128, 128)),
('building', (128, 0, 0)),
('pole', (192, 192, 128)),
('road_marking', (255, 69, 0)),
('road', (128, 64, 128)),
('pavement', (60, 40, 222)),
('tree', (128, 128, 0)),
('sign_symbol', (192, 128, 128)),
('fence', (64, 64, 128)),
('car', (64, 0, 128)),
('pedestrian', (64, 64, 0)),
('bicyclist', (0, 128, 192)),
('unlabeled', (0, 0, 0))
]
- Các đường dẫn cho data tiếp theo đó là cái fđặt các đường dẫn cho dữ liệu tương ứng với từng mode
train,valhay `test
def __init__(self, mode='train', num_classes=14):
self.mode = mode
self.num_classes = num_classes
# Normailization
self.normalize = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
self.DATA_PATH = os.path.join(os.getcwd(), 'CamVid/')
self.train_path, self.val_path, self.test_path = [os.path.join(self.DATA_PATH, x) for x in ['train', 'val', 'test']]
if self.mode == 'train':
self.data_files = self.get_files(self.train_path)
self.label_files = [self.get_label_file(f, 'train', 'train_labels') for f in self.data_files]
elif self.mode == 'val':
self.data_files = self.get_files(self.val_path)
self.label_files = [self.get_label_file(f, 'val', 'val_labels') for f in self.data_files]
elif self.mode == 'test':
self.data_files = self.get_files(self.test_path)
self.label_files = [self.get_label_file(f, 'test', 'test_labels') for f in self.data_files]
else:
raise RuntimeError("Unexpected dataset mode. "
"Supported modes are: train, val and test")
- Các hàm xử lý thư mục và load ảnh: Đây là các hàm sử dụng trong việc lấy các files trong dataset và sử dụng PIL Image để load dữ liệu
def get_files(self, data_folder):
"""
Return all files in folder with extension
"""
return glob("{}/*.{}".format(data_folder, 'png'))
def get_label_file(self, data_path, data_dir, label_dir):
"""
Return label path for data_path file
"""
data_path = data_path.replace(data_dir, label_dir)
fname, ext = data_path.split('.')
return "{}_L.{}".format(fname, ext)
def image_loader(self, data_path, label_path):
data = Image.open(data_path)
label = Image.open(label_path)
return data, label
- Mã hoá label: Việc mã hoá label nhằm mục đích chuyển các pixel có chung mã màu về 1 class duy nhất giúp cho việc tính toán crossentropy loss trở nên khả thi.
def label_for_cross_entropy(self, label):
"""
Convert label image to matrix classes for apply cross entropy loss.
Return semantic index, label in enumemap of H x W x class
"""
semantic_map = np.zeros(label.shape[:-1])
# Fill all value with class 13 - default for all pixels
semantic_map.fill(self.num_classes - 1)
# Fill the pixel with correct class
for class_index, color_info in enumerate(self.color_encoding):
color = color_info[1]
equality = np.equal(label, color)
class_map = np.all(equality, axis=-1)
semantic_map[class_map] = class_index
return semantic_map
- Hàm
__getitem__(): Hàm này là hàm bắt buộc phải có khi xây dựng Dataset trong PyTorch mục đích để trả về data và dữ liệu tương ứng
def __getitem__(self, index):
"""
Args:
- index (``int``): index of the item in the dataset
Returns:
A tuple of ``PIL.Image`` (image, label) where label is the ground-truth
of the image.
"""
data_path, label_path = self.data_files[index], self.label_files[index]
img, label = self.image_loader(data_path, label_path)
# Apply normalization in img
img = self.normalize(img)
# Convert label for cross entropy
label = np.array(label)
label = self.label_for_cross_entropy(label)
label = torch.from_numpy(label).long()
return img, label
Xây dựng các hàm helpers
Đây là các hàm được sử dụng trong quá trình training và testing mô hình. Bao gồm các hàm như sau
- Reverse onehot: đây là hàm decode lại ma trận onehot đầu ra của mô hình về ma trận các class tương ứng
def reverse_one_hot(image):
# Convert output of model to predicted class
image = image.permute(1, 2, 0)
x = torch.argmax(image, dim=-1)
return x
- Tính toán accuracy: Hàm này tính toán độ chính xác tổng thể trên tất cả các class giữa output của mô hình và ground truth
def compute_accuracy(pred, label):
pred = pred.flatten()
label = label.flatten()
total = len(label)
count = 0.0
for i in range(total):
if pred[i] == label[i]:
count = count + 1.0
return float(count) / float(total)
- Tính toán IoU: Hàm này tính toán IoU của hai ma trận số class tương ứng
def fast_hist(a, b, n):
k = (a >= 0) & (a < n)
return np.bincount(n * a[k].astype(int) + b[k], minlength=n ** 2).reshape(n, n)
def per_class_iu(hist):
epsilon = 1e-5
return (np.diag(hist) + epsilon) / (hist.sum(1) + hist.sum(0) - np.diag(hist) + epsilon)
Từ các hàm trên chúng ta xây dựng hàm validate nhận đầu vào là model và dataloader trên tập validate
def val(model, dataloader):
accuracy_arr = []
hist = np.zeros((NUM_CLASSES, NUM_CLASSES))
with torch.no_grad():
model.eval()
print('Starting validate')
for i, (val_data, val_label) in enumerate(dataloader):
val_data = val_data.cuda()
# The output of model is (1, num_classes, W, H) => (num_classes, W, H)
val_output = model(val_data).squeeze()
# Convert the (num_classes, W, H) => (W, H) with one hot decoder
val_output = reverse_one_hot(val_output)
val_output = np.array(val_output.cpu())
# Process label. Convert to (W, H) image
val_label = val_label.squeeze()
val_label = np.array(val_label.cpu())
# Compute accuracy and iou
accuracy = compute_accuracy(val_output, val_label)
hist += fast_hist(val_label.flatten(), val_output.flatten(), NUM_CLASSES)
# Append for calculate
accuracy_arr.append(accuracy)
miou_list = per_class_iu(hist)[:-1]
mean_accuracy, mean_iou = np.mean(accuracy_arr), np.mean(miou_list)
print('Mean accuracy: {} Mean IoU: {}'.format(mean_accuracy, mean_iou))
return mean_accuracy, mean_iou
Training mô hình
Các hằng số cần thiết
Để bước vào huấn luyện một mô hình thì cần phải định nghĩa rõ các hằng số cũng như khai báo các dataloader cho việc training. Chúng ta tiến hành khai báo nó như sau
# Training
EPOCHS = 200
LEARNING_RATE = 0.0001
BATCH_SIZE = 8
CHECKPOINT_STEP = 2
VALIDATE_STEP = 1
NUM_CLASSES = 14
model = BiSeNet(num_classes=NUM_CLASSES, training=True)
model = model.cuda()
# Dataloader for train
dataset_train = CamVidDataset(mode='train')
dataloader_train = DataLoader(
dataset_train,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True
)
# Dataloader for validate
dataset_val = CamVidDataset(mode='val')
dataloader_val = DataLoader(
dataset_val,
batch_size=1,
shuffle=True
)
# Optimizer
optimizer = torch.optim.Adam(model.parameters(), LEARNING_RATE)
loss_func = torch.nn.CrossEntropyLoss()
Code training
Sau khi khai báo các phần trên chúng ta bắt đầu training mô hình. Không có gì khó khăn cả. Chúng ta sử dụng một vòng lặp for để duyệt qua tất cả các epochs.
# Loop for training
torch.cuda.empty_cache()
for epoch in range(EPOCHS):
model.train()
tq = tqdm(total=len(dataloader_train) * BATCH_SIZE)
tq.set_description('Epoch {}/{}'.format(epoch, EPOCHS))
loss_record = []
max_miou = 0
for i, (data, label) in enumerate(dataloader_train):
data = data.cuda()
label = label.cuda()
output, output_sup1, output_sup2 = model(data)
loss1 = loss_func(output, label)
loss2 = loss_func(output_sup1, label)
loss3 = loss_func(output_sup2, label)
# Combine 3 loss
loss = loss1 + loss2 + loss3
tq.update(BATCH_SIZE)
tq.set_postfix(loss='%.6f' % loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_record.append(loss.item())
tq.close()
loss_train_mean = np.mean(loss_record)
print('loss for train : %f' % (loss_train_mean))
# Save checkpoint
if epoch % CHECKPOINT_STEP == 0:
torch.save(model.state_dict(), 'checkpoints/lastest_model.pth')
# Validate save best model
# Save checkpoint
if epoch % VALIDATE_STEP == 0:
_, mean_iou = val(model, dataloader_val)
if mean_iou > max_miou:
max_miou = mean_iou
print('Save best model with mIoU = {}'.format(mean_iou))
torch.save(model.state_dict(), 'checkpoints/best_model.pth')
Cần lưu ý rằng trong quá trình training thì output của model sẽ bao gồm 3 Tensor để tính toán thêm 2 hàm loss phụ trợ. Các bạn có thể thấy mình implement chúng ở đoạn
output, output_sup1, output_sup2 = model(data)
loss1 = loss_func(output, label)
loss2 = loss_func(output_sup1, label)
loss3 = loss_func(output_sup2, label)
Việc tiếp theo là đợi nó training xong thôi. Mình training mất khoảng 3h cho 83/200 Epochs với BATCH_SIZE = 8 trên GPU GTX-1080 Ti thì thu được kết quả như sau:
Mean accuracy: 0.9188461593555188 Mean IoU: 0.6721747276912956
Epoch 83/200: 64%|██████▍ | 232/360 [01:15<00:41, 3.10it/s, loss=0.271397]IOPub message rate exceeded.
Các bạn có thể thấy được chỉ số mean IoU trên tập val đang là 0.67. Lưu lại model và chúng ta sẽ bước sang phần cuối cùng đó là đánh giá trên tập test.
Đánh giá mô hình
Đánh giá trên tập testing
Các bạn load lại checkpoint mới nhất
model.load_state_dict(torch.load('checkpoints/best_model.pth'))
Sau đó chạy lại hàm validate với dataloader trên tập test
# Dataloader for testing
dataset_test = CamVidDataset(mode='test')
dataloader_test = DataLoader(
dataset_test,
batch_size=1,
shuffle=True
)
val(model, dataloader_test)
Sau khi validate xong thu được kết quả
Mean accuracy: 0.8588461593555188 Mean IoU: 0.5721747276912956
Epoch 83/200: 64%|██████▍ | 232/360 [01:15<00:41, 3.10it/s, loss=0.271397]IOPub message rate exceeded.
Đây là weigtht lúc mình dừng lại ở epoch 83. Các bạn có tthể training thêm để có kết quả tốt hơn.
Một vài kết quả mẫu
Chúng ta sẽ code một vài hàm để đánh giá kết quả mô hình một cách trực quan hơn. Phần này gồm các hàm như sau
- Chuyển từ ma trận class thành RGB:
def colour_code_segmentation(image, label_values):
w = image.shape[0]
h = image.shape[1]
x = np.zeros([w,h,3], dtype=np.uint8)
colour_codes = label_values
for i in range(0, w):
for j in range(0, h):
x[i, j, :] = colour_codes[int(image[i, j])]
return x
- Get labels value: Hàm này phục vụ cho việc chuyển đổi ma trận class thành RGB phía trên. Trong dataloader chúng ta đã có biến
encoding_colornên có thể tái sử dụng lại nó
def get_label_values(dataset):
# Input is dataset instance define above
return [v[1] for v in dataset_test.color_encoding]
- Các hàm xử lý image và show image: Các hàm này cũng khá đơn giản nên không phải bàn cãi gì nhiều
from matplotlib import pyplot as plt
def img_show(img):
plt.imshow(img, interpolation='nearest')
plt.show()
def to_rgb(image):
test_label_vis = colour_code_segmentation(test_label, label_values)
img = Image.fromarray(test_label_vis, 'RGB')
return img
- Test cho single image trong dataset: Hàm này sẽ predict kết quả của một image cụ thể trong dataset của chúng ta. Phục vụ cho quá trình visualization
def test_single_image(model, dataset_test, index):
test_image, test_label = dataset_test.__getitem__(index)
test_image, test_label = test_image.cuda(), test_label.cuda()
model.eval()
test_output = model(test_image.unsqueeze(0))
# Convert the (num_classes, W, H) => (W, H) with one hot decoder
test_output = reverse_one_hot(test_output.squeeze(0))
test_output = np.array(test_output.cpu())
# Process label. Convert to (W, H) image
test_label = test_label.squeeze()
test_label = np.array(test_label.cpu())
return test_label, test_output
Kết quả test trên một số ảnh
Các bạn chạy thử các hàm trên để ra kết quả. Các ảnh phía trên là Test Label còn phía dưới là kết quả của mô hình
test_label, test_output = test_single_image(model, dataset_test, 14)
img_show(to_rgb(test_label))
img_show(to_rgb(test_output))
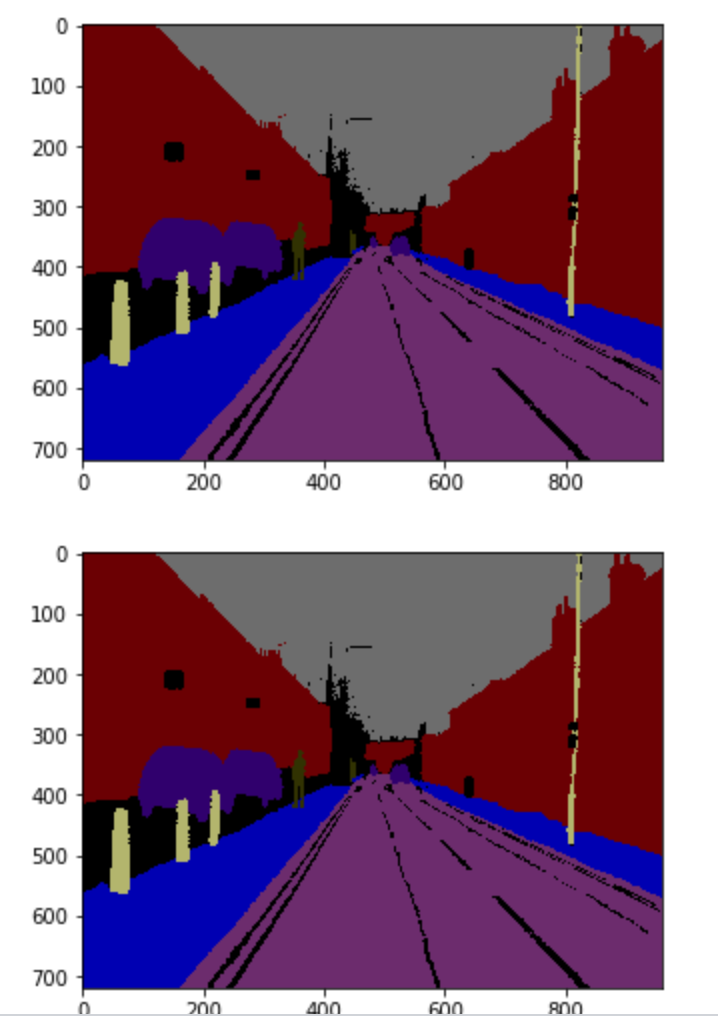
Các bạn có thể thử thêm một vài mẫu nữa. Ví dụ như index=15
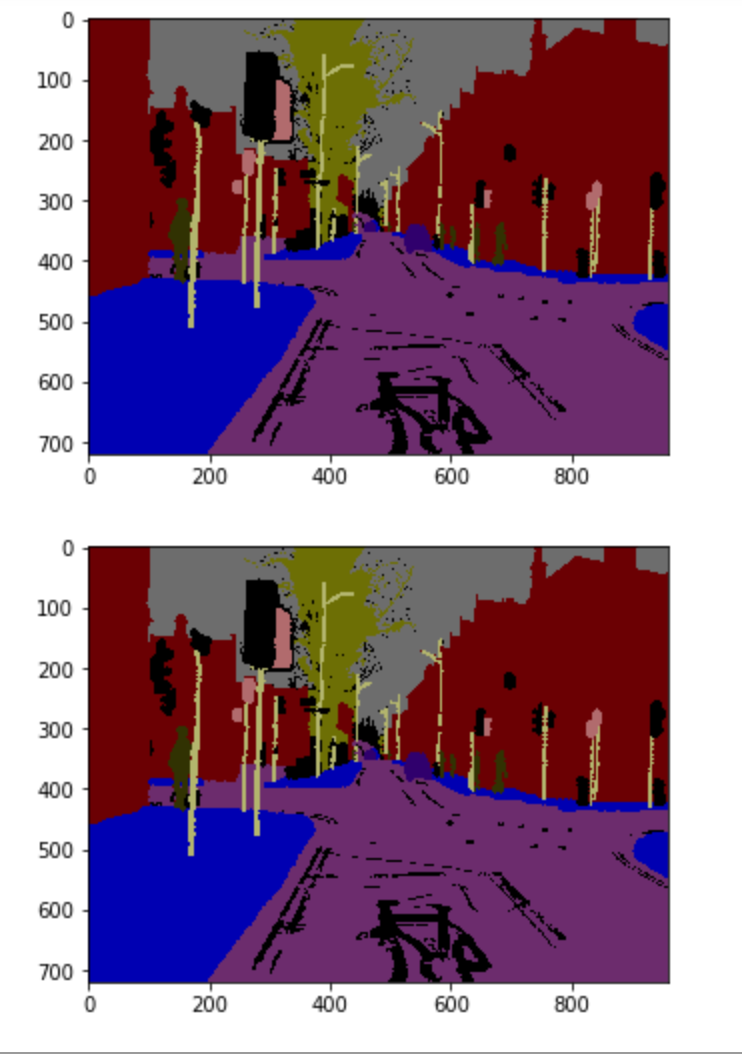
Hay khi index=50
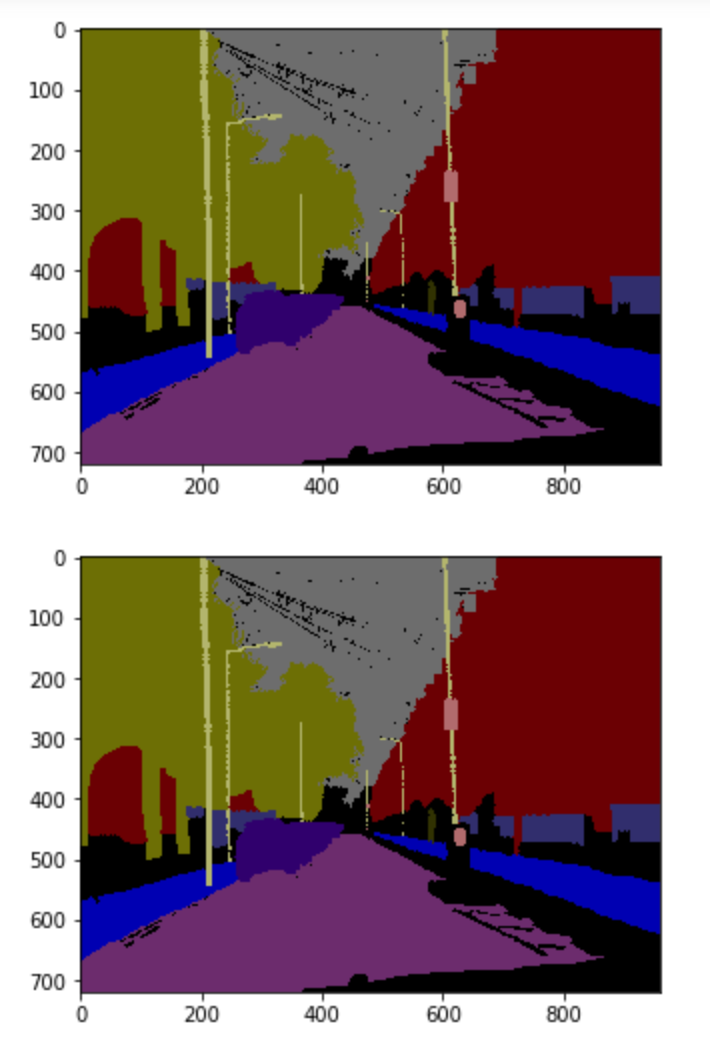
Nhận xét và đánh giá
BISeNet là một kiến trúc mạng điển hình cho việc stacking các module lại với nhau giúp tăng hiệu quả của mạng cuối cùng. Ở đây tác giả đã sử dụng hai mạng để tính toán song song giúp bảo tồn được cả hai thông tin về Spatial Information và Rich Receptive Field. Hai module đó là Spatial Path và Context Path. Việc implement hai module này thực ra không khó nếu như chúng ta chịu khó đọc thật kĩ model tuy nhiên mình cũng đã phải mất đến 2 đêm để debug những lỗi lặt vặt rồi mới training ra được kết quả như các bạn thấy trên đây. Đây là một bài viết mình dành khá nhiều tâm sức cho nó nên hi vọng được các bạn ủng hộ và đón nhận.
Source code
Toàn bộ source code các bạn có thể tham khảo tại đây
Kinh nghiệm rút ra
Qua bài viết này mình muốn chia sẻ với các bạn 4 điều:
- Đừng sợ đọc paper, hãy cố gắng đọc thật nhiều và tập thói quen note lại các ý chính
- Nếu đọc mà vẫn không hiểu thì hãy chịu khó nhìn các figure mô tả kiến trúc mạng. Các paper xịn đều có các figure này.
- Hãy học cách implement lại thuật toán từng module một. Mọi thứ phức tạp đều bắt nguồn từ những điều đơn giản
- Phải tìm một bài toán nào đó hứng thú để áp dụng paper vừa học được không thì sẽ rất nhanh chán. Và đó là lý do các bạn nên chờ đọc bài tiếp theo sắp ra của mình.
Còn bây giờ thì xin chào và hẹn gặp lại các bạn trong bài viết tiếp theo sẽ ra mắt nhanh thôi.
All rights reserved
