
[Paper Explain] Rep-Optimizer: Re-params Optimizer thay vì Re-params model của bạn
Bài đăng này đã không được cập nhật trong 3 năm
Một số khái niệm cần nắm được
- Re-parameterize: Là kĩ thuật thay đổi parameters của một layers (kernel của một lớp Conv) theo dạng biểu diễn khác. Về chi tiết hơn một chút, các bạn có thể đọc ở đây
- Convolution (Conv): Phép tích chập, là phép tính toán chủ đạo trong CNN. Với một input feature maps có chiều , nếu ta thực hiện conv với một filter với same padding thì sẽ tạo ra output feature maps có chiều . Nếu ta thực hiện conv với C2 filters cũng với same padding thì sẽ tạo ra output feature maps có chiều . Các bạn cần nắm chắc phép Conv thực sự làm gì. Hình 1 là biểu diễn của phép Conv
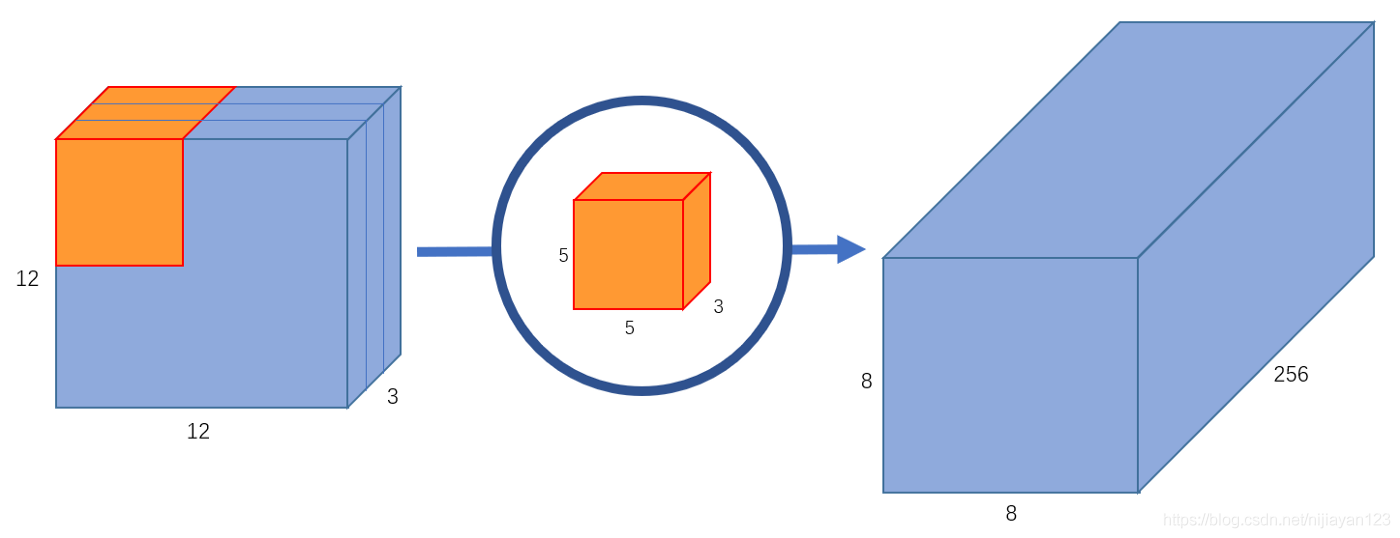
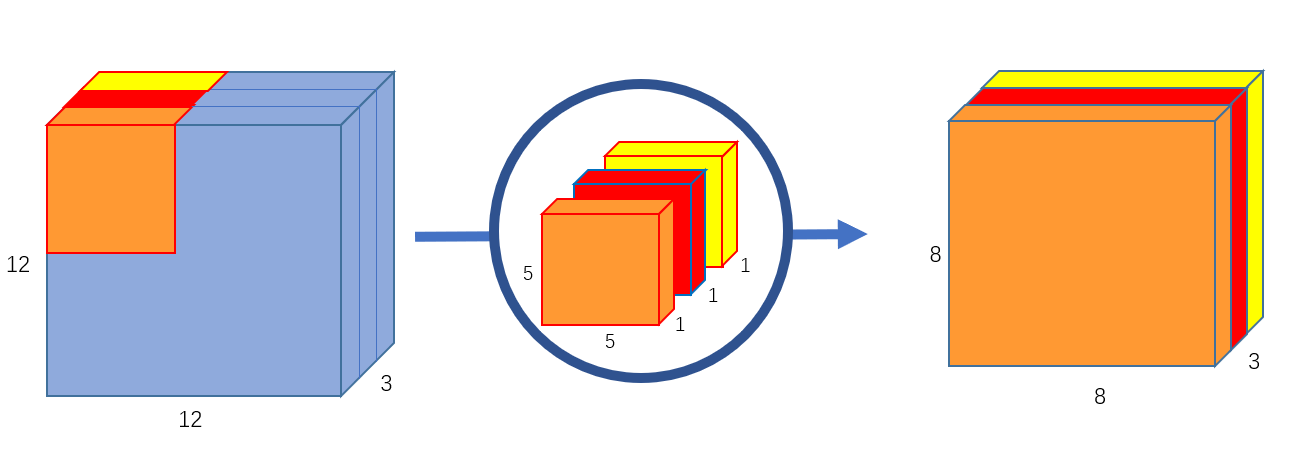
- Depthwise Conv (DWConv): Phép Conv nhưng ta sẽ thực hiện theo chiều channel. Tức là, ở channel thứ của input feature maps sẽ thực hiện conv với channel thứ của filter, tạo ra channel thứ trên output feature maps. Hình 2 biểu diễn phép DWConv
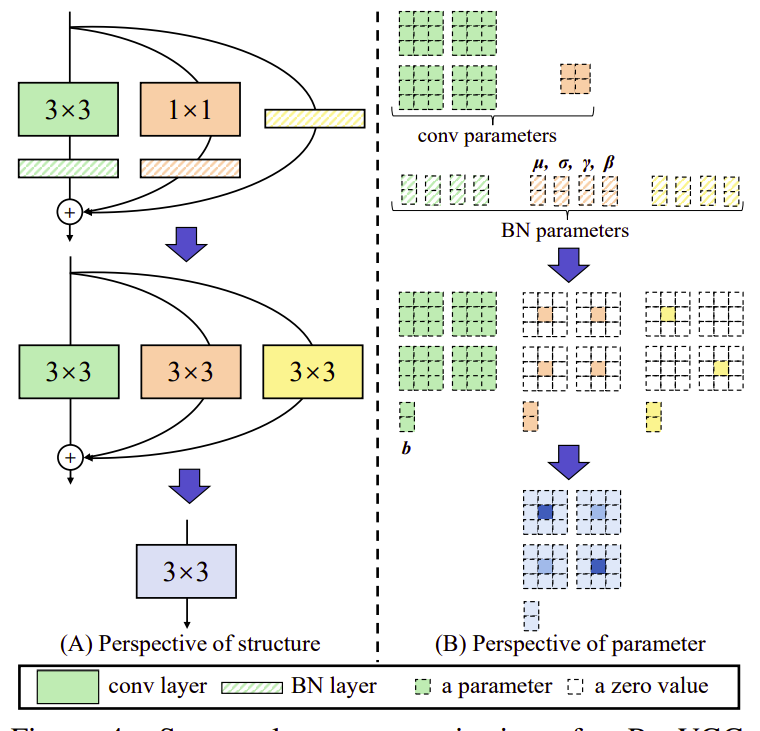
- RepVGG (optional): Khuyến khích các bạn đọc bài này đã có kiến thức về RepVGG, nếu chưa có, các bạn có thể đọc ở đây. Còn mình sẽ nói tóm tắt RepVGG đã làm gì tại bài viết này. Những gì RepVGG làm được thể hiện trong Hình 3: Gộp một khối bao gồm 2 lớp Conv ( Conv, Conv) và 3 lớp BatchNorm thành một lớp Conv duy nhất. Nó sẽ training với cái khối gồm nhiều lớp Conv, còn lúc inference (test time) sẽ hóa thân nó thành một lớp Conv thôi.
- Trainable operator (trainable ops): Là các layer, hoặc phép toán mà có thể train được, tức là thì kết quả của sẽ phụ thuộc cả vào input và weight
- Constant operator (constant ops): Là các layer, hoặc phép toán mà không train được, tức là thì kết quả của sẽ chỉ phụ thuộc vào input
Rep-Optimizer
Vấn đề của RepVGG, hay các Rep-model khác
RepVGG là một ý tưởng tuyệt vời cho thấy sự hiệu quả của kĩ thuật Re-param trong test time. Tuy nhiên, đó chỉ là trong test time. Tức là trong lúc training, bản chất ta vẫn phải train một mô hình khá là to khiến thời gian training lâu. Đối với các team, công ty đã có nguồn tài nguyên dồi dào để training thì đây không phải là vấn đề, tuy nhiên đối với các team eo hẹp trong kinh phí, hay các bạn sinh viên thì nó sẽ khá là khó chịu.
Hơn nữa, việc sử dụng kĩ thuật quantization lên các Rep-model cũng khá là khó khăn. Sau khi thực hiện INT8 quantization lên RepVGG, accuracy của nó đã tụt dốc không phanh, xuống thẳng trên ImageNet
Hướng giải quyết
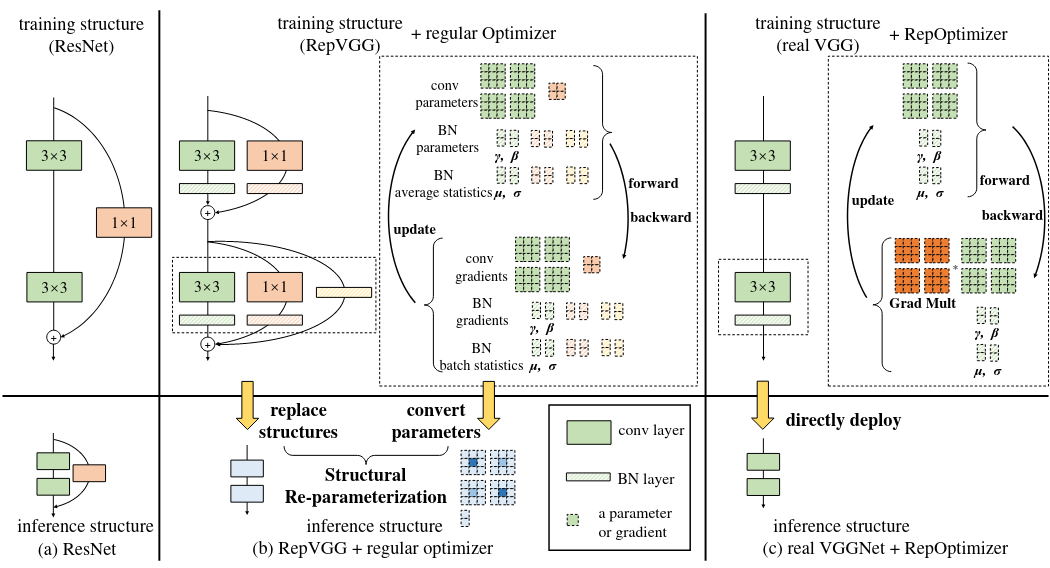
Rep-Optimizer hướng đến việc có một kiến trúc duy nhất trong training và testing. Như vậy, training cũng sẽ nhanh hơn và quantization cũng không gặp khó khăn gì. Ơ nhưng thế thì khác gì một model thông thường? Điểm khác biệt ở đây là, model sử dụng là VGG, sẽ có tốc độ training, tốc độ inference của VGG, nhưng accuracy thì của RepVGG (Hình 4).
Rep-Optimizer
Vậy làm như nào để có cái khả năng đề ra như mình nói ở phía trên? Thay vì tác động vào model, thì ta sẽ tác động vào gradient trong lúc training. Vì bản chất, khi training một model, ta sẽ sử dụng thông tin của gradient để cập nhật weight cho model đó. Ò ý tưởng thì có vẻ hiểu rồi, thế cách thực hiện thì như nào, làm thế nào để biết gradient cần phải thay đổi như nào? Để có thể hiểu được việc này, ta có quá trình 3 bước như sau: 1) Ta cần định nghĩa kiến thức ta mong muốn có được (prior knowledge) và kiến trúc mang kiến thức đó. 2) Ta cần định nghĩa kiến trúc ta hướng đến (target structure) trong quá trình test, để thay đổi gradient cho phù hợp. 3) Tính toán các hyper-params để tạo nên RepOptimizer. Vì vậy, chú ý là để có thể sử dụng được RepOptimizer, ta cần phải hiểu rõ:
- Target model: Model ta mong muốn sử dụng trong lúc inference (test time)
- Prior knowledge/Prior model: Model mà ta muốn target model của chúng ta đạt được accuracy như thế
- Cách backprop hoạt động: Mình nghĩ đây là bước khó nhất, cái này tùy thuộc vào trình độ toán học và ý chí của các bạn thôi :v
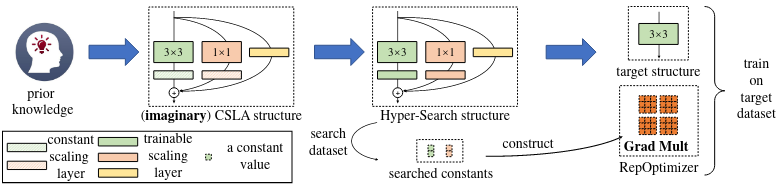
Định nghĩa Prior Knowledge
Bài này sẽ biểu diễn cách đưa kiến thức của RepVGG vào VGG. Trong RepVGG, kiến thức của nó chính là cộng inputs và outputs của các nhánh lại với nhau theo một hệ số scale. Cái kiến thức đơn giản đó đã được áp dụng trong rất nhiều model như: ResNet, sử dụng skip-connection để cộng input với output của nhánh residual. Trong trường hợp này, target model là VGG, prior model là RepVGG với block Conv-BN, Conv-BN và một nhánh mapping có BN.
Đưa prior knowledge vào Optimizer
Trước khi tìm hiểu về cách đưa prior knowledge của RepVGG vào Optimizer, ta xét tới hiện tượng sau: Ta xét một trường hợp đặc biệt khi mà toàn bộ các nhánh trong RepVGG Block chỉ bao gồm một trainable ops và có thể có thêm constant scale sau trainable ops (một hệ số nhân bất biến, dùn để nhân với output của trainable ops) thì độ chính xác của model vẫn rất cao nếu constant scale này có giá trị hợp lý. Và ta gọi block có dạng 3 nhánh, mỗi nhánh có 1 trainable ops (+ 1 constant scale) này là Constant Scale Linear Addition (CSLA) block (Hình 5). Nhóm tác giả nhận ra rằng ta có thể thay thế cái CSLA Block này bằng một trainable ops và từ đó rút ra equivalent training dynamic (mình cũng không biết dịch như nào cho hay). Equivalent training dynamic có nghĩa là: sau iteration, với input ở iteration của CSLA Block cũng giống với input ở iteration của một trainable ops, thì chúng luôn có một kết quả như nhau. Nếu văn nói của mình khó hiểu quá thì mời các bạn đọc tiếp phía dưới, có công thức toán học.
Equivalent training dynamic đạt được khi ta nhân gradient với một hệ số nhân được tìm ra từ constant scale. Ta gọi hệ số dùng để nhân với gradient đó là GradMult (Hình 5). Việc thay đổi gradients sử dụng GradMult có thể gọi là quá trình Re-params thực hiện trên gradient. Tóm lại:
Phần chứng minh cho điều vừa nói trên mình sẽ để ở phần phụ lục của bài viết này Oke bây giờ đến biểu diễn toán học một chút. Gọi là 2 hằng số. là 2 kernel của lớp Conv có cùng shape với nhau. là input và là output. là phép Conv. CSLA Block được tính như sau:
Còn khi sử dụng Optimizer được Re-params (GR), ta gọi kernel của ops đó là , do đó:
Gọi là số training iteration, ta có thể có được khi và chỉ khi ta tuân thủ 2 luật:
- Luật khởi tạo (Rule of initialize): Kernel của ops () phải được khởi tạo như sau: . Hay nói cách khác, kernel của ops phải được khởi tạo tương đương như của CSLA Block
- Luật update theo iteration: CSLA Block khi train với Optimizer thông thường thì update như thuông thường, còn khi sử dụng GR, gradient sẽ phải nhân với hệ số . Gọi là objective function, là learning rate, ta sẽ update như sau:
Đã hiểu làm thế nào để , ta sẽ thiết kế và mô tả RepOptimizer bằng việc thiết kế CSLA trước. Với việc áp dụng RepOptimizer lên VGG theo RepVGG (Gọi là RepOpt-VGG), CSLA sẽ được khởi tạo bằng việc thay thế lớp BN ở sau 2 lớp Conv và bằng một hằng số scale theo chiều channel (để hiểu rõ hơn mời các bạn đọc lại cách BN hoạt động như nào tại đây) , còn BN trong identity branch của RepVGG sẽ được thay bằng một tham số scale theo chiều channel (vì mỗi nhánh trên CSLA Block đều phải có một trainable ops). Tham số scale theo chiều channel này có thể hiểu là một lớp Depthwise Conv, lưu ý rằng đây là tham số scale theo chiều channel chứ không phải hằng số scale theo chiều channel (CSLA structure trên Hình 5)
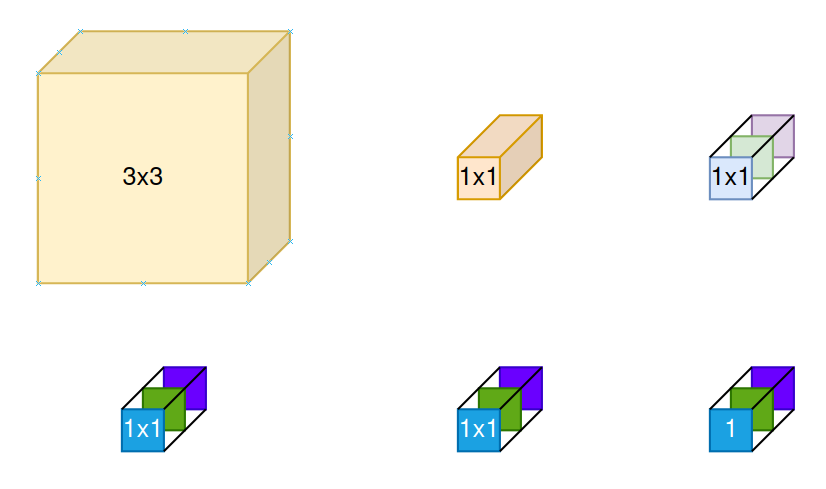
Xét một trường hợp phức tạp hơn, lớp Conv ở mỗi nhánh có kernel size khác nhau và ngay sau chúng là một hằng số scale theo chiều channel, GradMult lúc này sẽ là một tensor. Cách tính GradMult cho CSLA đại diện cho RepVGG, sẽ được sử dụng để training cho target block là Conv như sau: Gọi là số channels, là hằng số scale theo chiều channel sau lớp Conv và Conv, GradMult sẽ được tính theo công thức sau:
và có nghĩa là điểm trung tâm của cái kernel.
Oke giờ mình sẽ giải thích công thức trên rõ hơn một chút. Khuyến khích mọi người vừa đọc phần dưới đây vừa nhìn vào Hình 6
Nhìn lại khối CSLA Block đại diện cho 2 lớp Conv có cùng kernel size theo sau đó là 2 hằng số scale theo chiều channel ở tít phía trên, mình sẽ gọi là CSLA 1. GradMult của CSLA 1 . Nếu không hiểu phần này, hãy đọc ở phụ lục, còn chưa đọc phần phụ lục mà vẫn muốn hiểu cách tìm cho CSLA Block của RepVGG thì giờ hãy chấp nhận cách tìm cho CSLA 1.
Mở rộng CSLA 1 lên thành CLSA 2, là một kiến trúc có 2 nhánh, một nhánh là Conv và nhánh còn lại là Conv, theo sau mỗi lớp Conv lại là hằng số scale theo chiều channel . Lúc này, Conv sẽ được kết hợp với Conv tại điểm trung tâm của Conv. Do đó, GradMult của CSLA 2 sẽ như sau:
Thấy GradMult cho CSLA 2 có giống với 2 dòng cuối của GradMult cho CSLA RepVGG chưa nào :v
Còn vì tại sao GradMult cho CSLA RepVGG phải chia cả theo từng channel nữa là vì nguyên lý hoạt động của Depthwise Conv. CSLA RepVGG có một nhánh thứ 3 là Depthwise Conv, và hằng số scale theo chiều channel lúc này sẽ bằng 1 tại toàn bộ các channel, do đó ta chỉ cần tại
Tìm các Hyper-params cho RepOptimizer thông qua Hyper-Search
Ở đầu phần trên, đã có nhận định là "Ta xét một trường hợp đặc biệt khi mà... (yada yada yada)... nếu constant scale này có giá trị hợp lý". Giờ ta phải tìm cái giá trị hợp lý cho constant scale này như nào? Vì Neural Network (NN) vốn là một cái hộp đen, nên tìm được giá trị chính xác cho constant scale này dường như là không thể, vì vậy ta sẽ xấp xỉ giá trị này, và phương pháp sắp tới đây sẽ gọi là Hyper-Search. Cụ thể, với một RepOptimizer, ta sẽ dựng một Hyper-Search model bằng việc thay toàn bộ constant scale thành trainable scale (tức là lấy lại nguyên cái RepVGG đấy). Và ta sẽ train cái Hyper-Search model này trên một cái dataset cỡ vừa (VD: CIFAR 100). Giá trị cuối cùng của trainable scale được train với bộ dataset cỡ vừa này sẽ được chuyển thành constant scale được sử dụng trong CSLA.
Training với RepOptimizer
Sau Hyper-Search, ta sẽ dùng constant scale vừa search được để tạo GradMult cho RepOptimizer của mỗi ops (với RepOpt-VGG thì các ops ở đây là Conv). Trong lúc training, RepOptimizer sẽ thực hiện nhân gradients của từng ops với GradMult tương ứng của từng ops của mỗi lần forward/backward Luật update theo iteration
Ta cũng phải tuân thủ Luật khởi tạo. Gọi và là weight được khởi tạo của Conv và Conv của CSLA RepVGG. Do đó, weight của RepOpt-VGG được khởi tạo như sau:
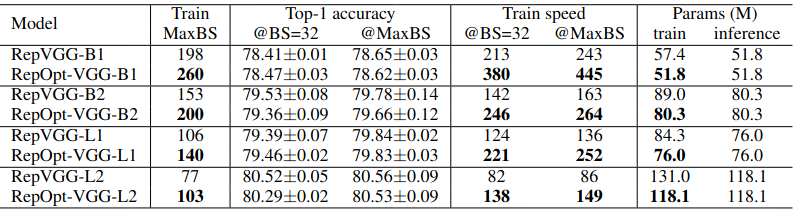
Kết quả so sánh với RepVGG trên ImageNet
Phụ lục
Chứng minh CSLA = GR
 Yêu cầu chuẩn bị sẵn kiến thức về toán cao cấp, lấy giấy bút ra, và suy ngẫm nếu bạn muốn hiểu phần này, còn nếu bạn pro không cần giấy bút thì xin chúc mừng.
Yêu cầu chuẩn bị sẵn kiến thức về toán cao cấp, lấy giấy bút ra, và suy ngẫm nếu bạn muốn hiểu phần này, còn nếu bạn pro không cần giấy bút thì xin chúc mừng.
CSLA là một block mà mỗi nhánh ở trên mỗi block đó có một trainable ops và theo sau là một constant scale. Chứng minh rằng, training một CSLA block với Optimizer thông thường sẽ như là training một trainable ops với gradient được sửa đổi
Xét trường hợp CSLA Block có 2 nhánh, mỗi nhánh có 1 lớp Conv với kernel size của lớp Conv trên các nhanh là như nhau, theo sau mỗi lớp Conv là một hằng số scale theo chiều channel. Gọi là 2 hằng số scale, là kernel của mỗi lớp Conv. Gọi là input và là output, với * là phép conv. Khi sử dụng Gradient Re-params (GR), ta sẽ train target model theo weight , với . Gọi objective function là , số training iteration là , gradient của một kernel là , là áp dụng biến đổi lên gradient của kernel của GR .
Phát biểu: Tồn tại một phép biến đổi theo và sao cho khi update theo sẽ đảm bảo được rằng:
Chứng minh: Để đúng, ta cần phải có:
Tại iteration , chỉ cần initialize đúng là đã thỏa mãn phương trình . Giả dụ là giá trị initialize của kernel trong CSLA Block, thì điều kiện ban đầu:
để:
Giờ ta sẽ chứng minh, bằng việc thay đổi gradient của , thì ta sẽ luôn có được sự tương đồng: . Gọi là learning rate, theo update rule có:
Áp dụng update rule lên CSLA Block, ta có:
Nếu ta sử dụng để update theo update rule, ta có:
Từ , ta có:
Đạo hàm từng phần , ta có:
Từ và , ta có:
Hay:
Với , ta đảm bảo được rằng nếu . Do đó, kết hợp luật khởi tạo với luật update iteration đã được chứng minh thông qua , ta có thể thấy tồn tại một hệ số nhân thay đổi gradient theo để đạt sự tương đồng trong output giữa 2 kiến trúc khác nhau: CSLA Block và Conv
Reference
Re-parameterizing Your Optimizers rather than Architectures: https://arxiv.org/abs/2205.15242
All rights reserved
