
Bài toán trích xuất thông tin từ văn bản - Phần I
Bài đăng này đã không được cập nhật trong 5 năm
Đối với bất kỳ ai đang cố gắng với nhiệm vụ phân tích văn bản, cái khó khăn nhất không phải là tìm đúng tài liệu mà là tìm những thông tin chính xác trong những tài liệu đấy. Hiểu rõ mối liên kết giữa các entities trong đoạn văn, các sự kiện trong đoạn văn mô tả diễn ra như thế nào, hoặc là tìm những thông tin quý giá từ những keywords trong đoạn văn đó,... và vì thế, việc tìm ra cách tự động trích xuất thông tin từ dữ liệu văn bảnvà trình bày nó theo cách có cấu trúc sẽ giúp chúng ta gặt hái được nhiều lợi ích, giảm đáng kể thời gian ta phải dành để đọc lướt qua các tài liệu. Đây chính là điều mà mình sẽ nói tiếp theo dưới đây. Ở trong phần này mình sẽ trình bày sâu về lý thuyết cơ bản và cách xử lý dữ liệu text trước, nào bắt đầu làm thôi, các phần tiếp theo sẽ được update sớm nhất...
Information Extraction
Information Extraction (IE) là một lĩnh vực về xử lý trích xuất thông tin có cấu trúc trong xử lý ngôn ngữ tự nhiên. Lĩnh vực này được sử dụng rất nhiều trong các bài toán NLP như: Knowledge graph, Hệ thống trả lời câu hỏi, Tóm tắt văn bản,... Chính bản thân RE cũng là một subfield của IE.
Nhiệm vụ cũng như ý nghĩa của IE là trích xuất thông tin có ý nghĩa từ dữ liệu văn bản phi cấu trúc và trình bày nó ở dạng có cấu trúc.
Sử dụng IE ta có thể trích xuất thông tin như tên của một người , một địa điểm hoặc xác định mối quan hệ giữa các thực thể và lưu thông tin này ở định dạng có cấu trúc như Database.
Parts of speech là gì (POS)?
Trong một câu hay một đoạn văn bản thì ta sẽ có động từ, danh từ ,trạng từ, đại từ,... Ta sử dụng POS để phân loại các từ trong một câu đó là loại từ nào.
VD: We are the same
POS: We/PRP is/VBZ the/IN same/NN
Phân loại từ như thế sẽ giúp cho máy biết được ý nghĩa của câu, ví dụ như một từ trong tiếng anh có thể có 2 nghĩa ví dụ như từ growing danh từ là "Sự phát triển" tính từ là "Sự bành trướng". Nếu không phân loại thì ta có thể nhầm lẫn cấu trúc của ví dụ này và từ đó câu văn của ta sẽ không còn đúng nghĩa nữa. POS có thể giúp máy phân biệt được đâu là danh từ đâu là tính từ ở trên dựa vào nội dung của câu.
Ta sẽ sử dụng thư viện spaCy để thực hiện một số ví dụ:
import spacy
# load english language model
nlp = spacy.load('en_core_web_sm',disable=['ner','textcat'])
text = "This is a sample sentence."
# create spacy
doc = nlp(text)
for token in doc:
print(token.text,'->',token.pos_)
Result:
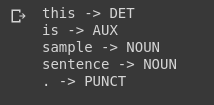
Bằng vài câu lệnh đơn giản ta đã có thể phân tích thành phần câu. Nhưng việc phân tích thành phần câu này có giúp ích gì cho việc trích xuất thông tin như thế nào? Bằng việc phân tích các cú pháp như trên ta có thể lọc ra được danh từ, và NLP danh từ thường mang nhiều thông tin rất quan trọng của câu văn
for token in doc:
# check token pos
if token.pos_=='NOUN':
# print token
print(token.text)

Ta có thể dễ dàng để trích xuất các từ dựa trên các thẻ POS của chúng. Nhưng đôi khi trích xuất thông tin hoàn toàn dựa trên các thẻ POS là không đủ. Hãy xem câu dưới đây:
text = "The children love cream biscuits"
# create spacy
doc = nlp(text)
for token in doc:
print(token.text,'->',token.pos_)
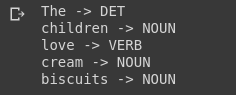
Nếu mình muốn trích xuất subject và object của một câu, mình không thể làm điều đó dựa trên thẻ POS của chúng. Vì vậy, mình cần phải xem những từ này có liên quan với nhau như thế nào. Chúng ta sẽ dùng một thứ được gọi là Dependencies.
from spacy import displacy
displacy.render(doc, style='dep',jupyter=True)
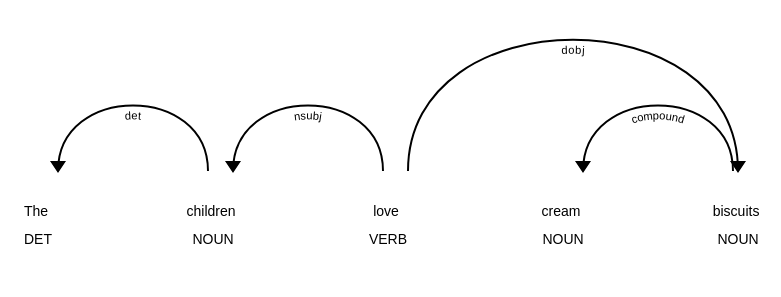
Ta sẽ sử dụng dependency graph để thể hiện quan hệ giữa các từ khác nhau của một câu.
Mỗi từ là một node trong Dependency graph. Mối quan hệ giữa các từ được thể hiện bằng các đường cong.
Các mũi tên mang rất nhiều ý nghĩa ở đây:
- Đầu mũi tên trỏ đến các từ phụ thuộc vào từ được trỏ bởi gốc của mũi tên. Và khi bị phụ thuộc thì nó sẽ là node con của từ mà trỏ đến nó.
- Từ mà không có mũi tên trỏ đến được gọi là node gốc của câu. Ta sẽ thử trích xuất Subject và Object của câu trên
for token in doc:
# extract subject
if (token.dep_=='nsubj'):
print(token.text)
# extract object
elif (token.dep_=='dobj'):
print(token.text)

Làm việc với bộ dữ liệu United Nations General Debate Corpus
Chúng ta đã tìm hiểu được về các phần cơ bản ở trên, giờ ta sẽ tập chung thực hành với một bộ dataset thực tế là United Nations General Debate Corpus . Dataset bao gồm các bài phát biểu của đại diện của tất cả các nước thành viên từ năm 1970 đến năm 2018 tại cuộc tranh luận chung của phiên họp thường niên của đại hội đồng Liên Hợp Quốc. Nhưng trong phần này ta sẽ lấy một subset nhỏ trong toàn bộ dataset để làm.
Ở đây chúng ta sẽ trích xuất ra những thứ quan trọng khi thủ tướng nói trong bài phát biểu với dataset ở trên
Đầu tiên là load các file text bằng cách sử dụng thư viện glob sau đó visualize ra bằng pandas.
# Folder path
folders = glob.glob('./UNGD/UNGDC 1970-2018/Converted sessions/Session*')
# Dataframe
df = pd.DataFrame(columns={'Country','Speech','Session','Year'})
# Read speeches by India
i = 0
for file in folders:
speech = glob.glob(file+'/IND*.txt')
with open(speech[0],encoding='utf8') as f:
# Speech
df.loc[i,'Speech'] = f.read()
# Year
df.loc[i,'Year'] = speech[0].split('_')[-1].split('.')[0]
# Session
df.loc[i,'Session'] = speech[0].split('_')[-2]
# Country
df.loc[i,'Country'] = speech[0].split('_')[0].split("\\")[-1]
# Increment counter
i += 1
df.head()

Bước tiếp theo ta sẽ tiền sử lý dữ liệu text, ở đây mình sẽ lấy một đoạn văn bản để làm ví dụ trực quan.
#Xóa các chữ số trong đoạn văn
text = re.sub('[0-9]+.\t','',str(clean))
I congratulate Mr.\nAmara Essy on his election as President of the General\nAssembly at the forty-ninth session. We are particularly\ngratified that an eminent son of Africa is leading the\nAssembly’s deliberations this year.\nWe offer our thanks to his predecessor, Ambassador\nInsanally, who presided over a year of considerable\nactivity in the General Assembly with great aplomb and\nfinesse. The Secretary-General, Mr. Boutros\nBoutros-Ghali, will be completing three years in office.\nWe wish him well as he continues to lead the United\nNations.\nWe have already welcomed the new South Africa to\nthe United Nations. South Africa today is a reminder of\nthe triumph of the principle of equality of man - a\ntriumph in which the United Nations played a major role.\nThe world community must commit itself to ensuring that\nthis principle is implemented for all time to come. All\nefforts should be made for the development of South\nAfrica.\nForty-nine years ago a world tired of war declared\n...
#Removing new line characters
text = re.sub('\n','', str(text))
text = re.sub('\n',' ', str(text))
I congratulate Mr.Amara Essy on his election as President of the GeneralAssembly at the forty-ninth session. We are particularlygratified that an eminent son of Africa is leading theAssembly’s deliberations this year.We offer our thanks to his predecessor, AmbassadorInsanally, who presided over a year of considerableactivity in the General Assembly with great aplomb andfinesse. The Secretary-General, Mr. BoutrosBoutros-Ghali, will be completing three years in office.We wish him well as he continues to lead the UnitedNations.We have already welcomed the new South Africa tothe United Nations. South Africa today is a reminder ofthe triumph of the principle of equality of man - atriumph in which the United Nations played a major role.The world community must commit itself to ensuring thatthis principle is implemented for all time to come. Allefforts should be made for the development of SouthAfrica.Forty-nine years ago a world tired of war declaredthat at this foundry of the United Nations...
#Xóa dấu nháy đơn
text = re.sub("'s", '', str(text))
I congratulate Mr.Amara Essy on his election as President of the GeneralAssembly at the forty-ninth session. We are particularlygratified that an eminent son of Africa is leading theAssembly’s deliberations this year.We offer our thanks to his predecessor, AmbassadorInsanally, who presided over a year of considerableactivity in the General Assembly with great aplomb andfinesse. The Secretary-General, Mr. BoutrosBoutros-Ghali, will be completing three years in office.We wish him well as he continues to lead the UnitedNations.We have already welcomed the new South Africa tothe United Nations. South Africa today is a reminder ofthe triumph of the principle of equality of man - atriumph in which the United Nations played a major role.The world community must commit itself to ensuring thatthis principle is implemented for all time to come. Allefforts should be made for the development of SouthAfrica.Forty-nine years ago a world tired of war declaredthat at this foundry of the United Nations
... Viết thành function:
def clean(text):
# removing paragraph numbers
text = re.sub('[0-9]+.\t','',str(text))
# removing new line characters
text = re.sub('\n ','',str(text))
text = re.sub('\n',' ',str(text))
# removing apostrophes
text = re.sub("'s",'',str(text))
# removing hyphens
text = re.sub("-",' ',str(text))
text = re.sub("— ",'',str(text))
# removing quotation marks
text = re.sub('\"','',str(text))
# removing salutations
text = re.sub("Mr\.",'Mr',str(text))
text = re.sub("Mrs\.",'Mrs',str(text))
# removing any reference to outside text
text = re.sub("[\(\[].*?[\)\]]", "", str(text))
return text
Result:
I congratulate MrAmara Essy on his election as President of the GeneralAssembly at the fortyninth session. We are particularlygratified that an eminent son of Africa is leading theAssembly’s deliberations this year.We offer our thanks to his predecessor, AmbassadorInsanally, who presided over a year of considerableactivity in the General Assembly with great aplomb andfinesse. The SecretaryGeneral, Mr BoutrosBoutrosGhali, will be completing three years in office.We wish him well as he continues to lead the UnitedNations.We have already welcomed the new South Africa tothe United Nations. South Africa today is a reminder ofthe triumph of the principle of equality of man atriumph in which the United Nations played a major role.The world community must commit itself to ensuring thatthis principle is implemented for all time to come. Allefforts should be made for the development of SouthAfrica.Fortynine years ago a world tired of war declaredthat at this foundry of the United Nations it wou...
Sau khi đã text-preprocessing rồi ta sẽ tách từng câu nói của người trong đoạn văn thành các câu khác nhau, function dưới đây sẽ tách những câu đằng sau dấu chấm thành một câu riêng
def sentences(text):
text = re.split('[.?]', text)
clean_sent = []
for sent in text:
clean_sent.append(sent)
return clean_sent
df['sent'] = df['Speech_clean'].apply(sentences)
df2 = pd.DataFrame(columns=['Sent','Year','Len'])
row_list = []
for i in range(len(df)):
for sent in df.loc[i,'sent']:
wordcount = len(sent.split())
year = df.loc[i,'Year']
dict1 = {'Year':year,'Sent':sent,'Len':wordcount}
row_list.append(dict1)
df2 = pd.DataFrame(row_list)
Và ta có kết quả sau:

Trong bài này ta đã đi qua các phần cơ bản cả về lý thuyết lẫn thực hành của information extraction, trong bài sau mình sẽ đi sâu hơn và nói nâng cao hơn về các thuật ngữ trong NLP, tìm các thực thể NER, tìm các pattern trong lời của speeches, Quy tắc về các cụm từ danh từ-động từ-danh từ, Quy tắc về cấu trúc tính từ danh từ...
Một lần cuối cảm ơn các bạn đã đọc bài 
All rights reserved
