
Trí tuệ nhân tạo đánh đánh giá độ đẹp trai, xinh gái của bạn ra sao...??? - Xây dựng Model Deep Learning cho bài toán Beauty Evaluate
Bài đăng này đã không được cập nhật trong 6 năm
Làm thế nào để bạn biết mình đẹp trai, xinh gái ra sao nếu không dựa vào người khác đánh giá???
Và câu trả lời là AI sẽ làm điều đó cho bạn, hôm nay mình sẽ giới thiệu đến các bạn cách xây dựng một bài toán rất hay và thú vị mang tên “Beaty Evaluate”. Sử dụng deep learning train với bộ dữ liệu SCUT-FBP5500 để ra được model “tối thượng” để dự đoán được độ đẹp zai xinh gái của bạn như thế nào, code mình sẽ để ở dưới cuối bài viết nhá… Còn bây giờ thì let’s begin now =))
Lý thuyết
Tản mạn về DATASET
Bộ dữ liệu SCUT-FBP5500 gồm tổng 5500 mặt của nam, nữ, châu á, người nước ngoài, già, trẻ ... và nhãn đa dạng (landmark, điểm số sắc đẹp trong 5 thang điểm, phân phối điểm số sắc đẹp) cho phép mô hình tính toán khác nhau với các mô hình dự đoán sắc đẹp khuôn mặt khác nhau. Bộ dữ liệu có thể được chia thành bốn tập hợp con với các chủng tộc và giới tính khác nhau, bao gồm 2000 phụ nữ châu Á (AF), 750 phụ nữ da trắng (CF) và 750 nam giới da trắng (CM). Hầu hết các hình ảnh của SCUT-FBP5500 được thu thập từ Internet.
Các bạn có thể đọc thêm chi tiết ở paper này tại đây và down bộ dữ liệu tại đây
Training/ Testing set split
Ở trong Dataset down về thì đã split cho chúng ta thành hai thử nghiệm:
- 5-folds cross validation, với mỗi validation 80% samples (4400 ảnh) được sử dụng cho đào tạo và phần còn lại 20% (1100 ảnh) được sử dụng để thử nghiệm.
- Thử nghiệm thứ 2 là chia thành 60% cho tập training và 40% cho tập testing.
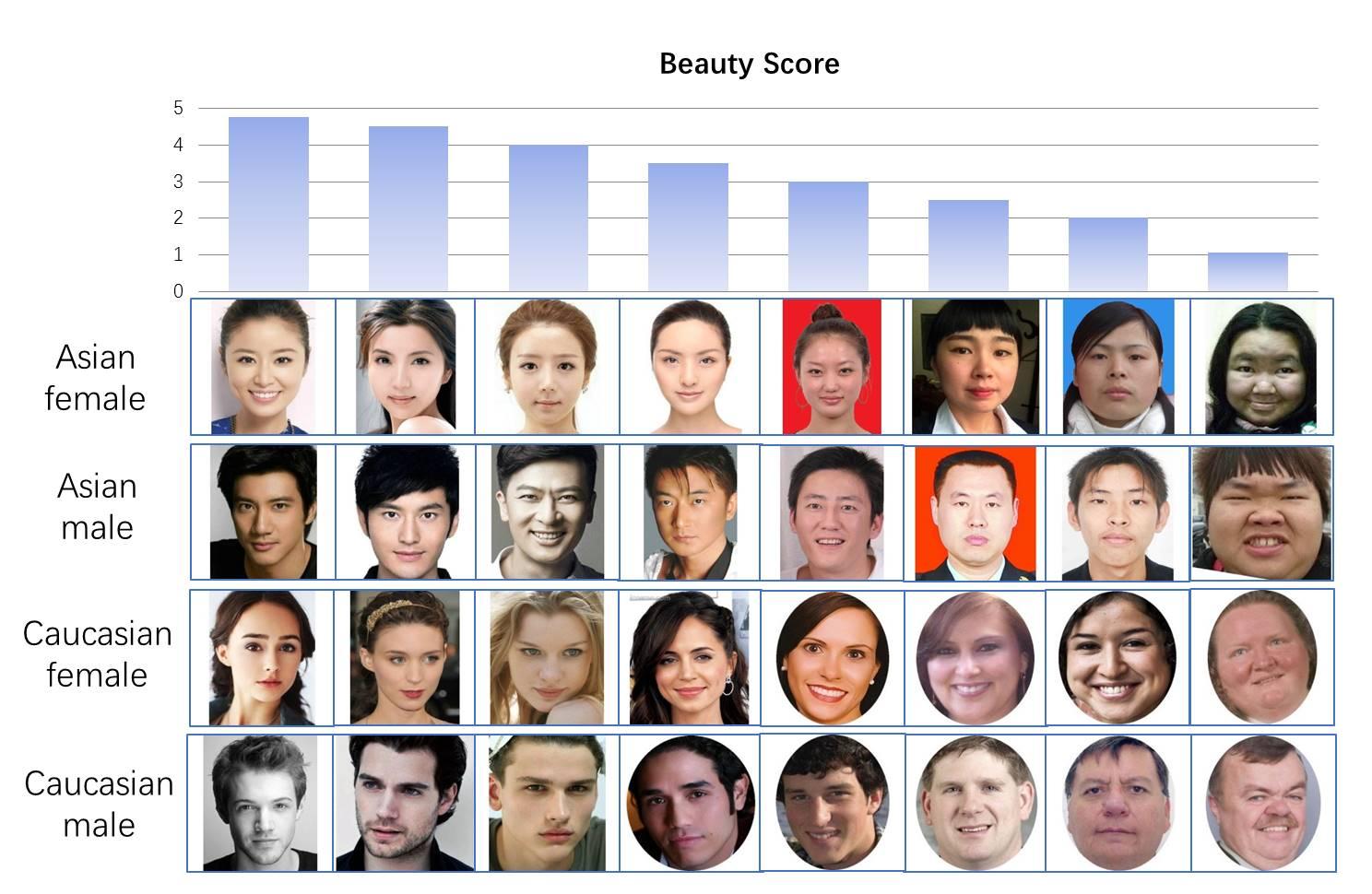
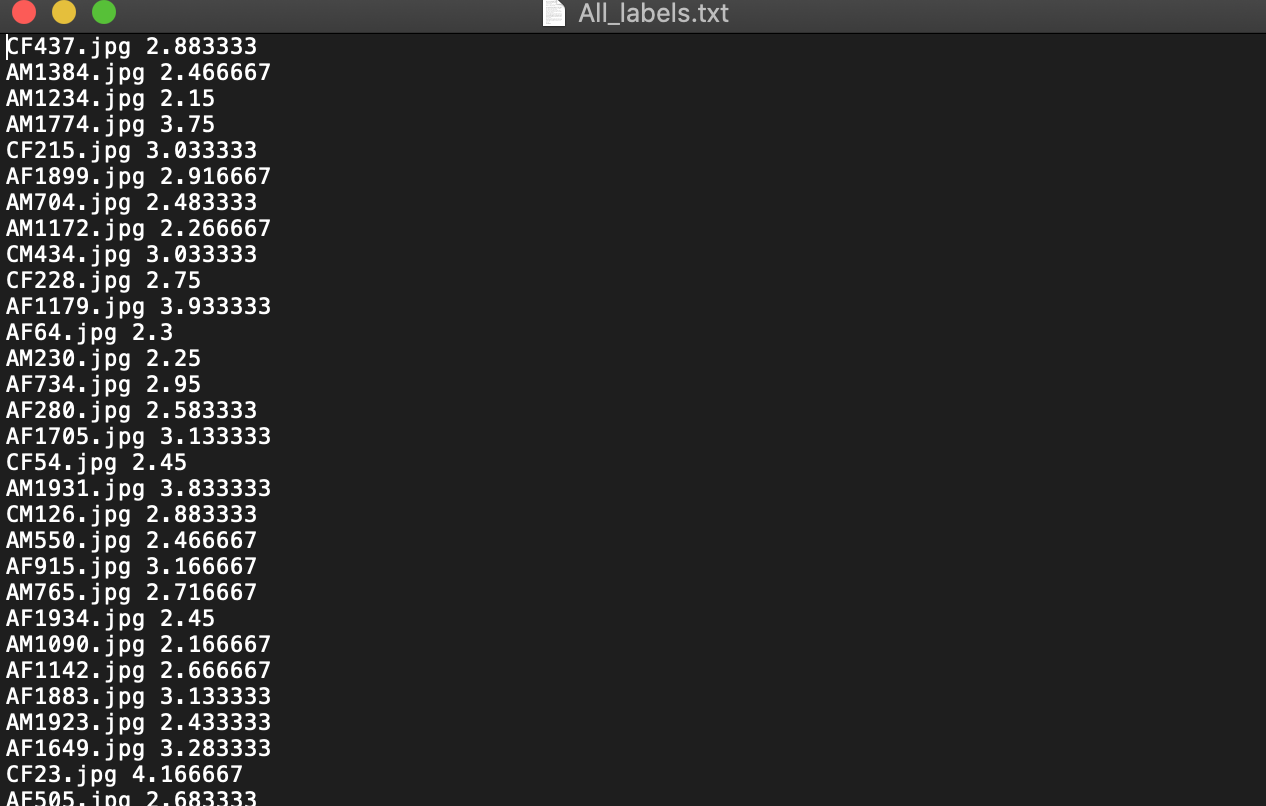
Đây là label của bộ dữ liệu train, và như bạn đã thấy nó đều được gán nhãn với từng ảnh + số điểm sắc đẹp của họ bên cạnh.
Và đây là một số hình ảnh theo từng label tương ứng:



Thực Hành
Ô khê ô khê, xong phần lý thuyết thì giờ là đến phần mình thích viết nhất nào =))
Chia dữ liệu
Sử dụng hàm này để get labels và chỉ lấy mỗi đường dẫn ảnh trong file ALL_labels.txt và bỏ phần điểm số đi.
def get_labels(file):
with open(file,'r') as f:
lines = f.readlines()
return np.array([line.strip().split() for line in lines])
Ở đây mình dùng tập đã split thành 60% training và 40% testing
PATH = './train_test_files/split_of_60%training and 40%testing'
PATH_IMAGES = './Images/'
train_labels = get_labels(PATH+'train.txt')
test_labels = get_labels(PATH+'test.txt')
Dùng cv2.imread để đọc ảnh đầu vào và lưu vào trong RAM dưới dạng array. lưu ý: Mình chỉ sử dụng cách này tạm thời vì nó tiện :v , còn mình khuyến khích các bạn nếu mà code thì nên lưu nó vào dưới dạng một file để tiện lần sau lấy ra train luôn chứ ko phải thực hiện bước này nữa, nếu mà bạn dùng gg colab bạn sẽ hiểu mình ns thôi :v .
X_pre_train = [cv2.imread(PATH_IMAGES+file,0) for file in tqdm(train_labels[:,0])]
X_train = np.array([cv2.resize(img,(224,224),interpolation=cv2.INTER_AREA) for img in X_pre_train])
X_pre_test = [cv2.imread(PATH_IMAGES+file,0) for file in tqdm(test_labels[:,0])]
X_test = np.array([cv2.resize(img,(224,224),interpolation=cv2.INTER_AREA) for img in X_pre_test])
y_train = np.array([float(flo) for flo in train_labels[:,1]])
y_test = np.array([float(flo) for flo in test_labels[:,1]])
Cuối cùng là reshape lại để cho vào mạng train với kích cớ là 224x224 và 1 chà neo:
X_train = X_train.reshape((X_train.shape[0],X_train.shape[1],X_train.shape[2],1))
X_test = X_test.reshape((X_test.shape[0],X_test.shape[1],X_test.shape[2],1))

Loss function
Ở đây mình sẽ dùng RMSE để làm loss vì nó phù hợp với bài toán .Mình đã thử với cả: MAE, MSE rồi, nhưng theo cách quan sát loss thì mình thấy RMSE ổn nhất, các bạn có thể đọc về RMSE tại đây
def root_mean_squared_error(y_true, y_pred):
return K.sqrt(K.mean(K.square(y_pred - y_true), axis=-1))
Build Model
- Model với ảnh đầu vào là 224x224 và 1 chà neo
- 7 lớp conv2D và và tối đa 1024 filters cho một lớp
- 7 2D MaxPools
- 2 FC
class Beau:
def __init__(self):
self.model = Sequential()
#1st 2dConvolutional Layer
self.model.add(Conv2D(64, (3, 3), padding='same', input_shape=(224, 224, 1)))
self.model.add(Activation('relu'))
#1st 2dMaxPool Layer
self.model.add(MaxPooling2D(pool_size=(2, 2)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.5))
#2nd 2dConvolutional Layer
self.model.add(Conv2D(64, (3, 3), padding='same'))
self.model.add(Activation('relu'))
#2nd 2dMaxPool Layer
self.model.add(MaxPooling2D(pool_size=(2, 2)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.25))
#3rd 2dConvolutional Layer
self.model.add(Conv2D(128, (5, 5), padding='same'))
self.model.add(Activation('relu'))
#3rd 2dMaxPool Layer
self.model.add(MaxPooling2D(pool_size=(2, 2)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.5))
#4th 2dConvolutional Layer
self.model.add(Conv2D(128, (5, 5), padding='same'))
self.model.add(Activation('relu'))
#3rd 2dMaxPool Layer
self.model.add(MaxPooling2D(pool_size=(2, 2)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.25))
#5th 2dConvolutional Layer
self.model.add(Conv2D(256, (3, 3), padding='same'))
self.model.add(Activation('relu'))
self.model.add(BatchNormalization())
#3rd 2dMaxPool Layer
self.model.add(MaxPooling2D(pool_size=(2, 2)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.25))
#6th 2dConvolutional Layer
self.model.add(Conv2D(512, (5, 5), padding='same'))
self.model.add(Activation('relu'))
self.model.add(BatchNormalization())
self.model.add(MaxPooling2D(pool_size=(1, 1)))
self.model.add(BatchNormalization())
self.model.add(Dropout(0.5))
self.model.add(Conv2D(1024, (5, 5), padding='same'))
self.model.add(Activation('relu'))
self.model.add(BatchNormalization())
self.model.add(Flatten())
#1st FC Layer
self.model.add(Dense(256))
self.model.add(BatchNormalization())
self.model.add(Activation('relu'))
self.model.add(Dropout(0.25))
#2nd FC Layer
self.model.add(Dense(512))
self.model.add(BatchNormalization())
self.model.add(Activation('relu'))
self.model.add(Dropout(0.25))
# Output layer
self.model.add(Dense(1))
self.model.add(Activation('relu'))
# self.model.summary()
Mạng ở đây mình dùng là của một thanh niên tung của(mình để ở phần RF cuối bài) nhưng mình đã chỉnh lại theo ý của mình bằng cách thêm một lớp Conv2D, đặt dropout và resized ảnh lên thành 224x224, mạng ban đầu của họ là 7 triệu tham số, sau khi mình chỉnh thì đã lên con số 30 triệu :v
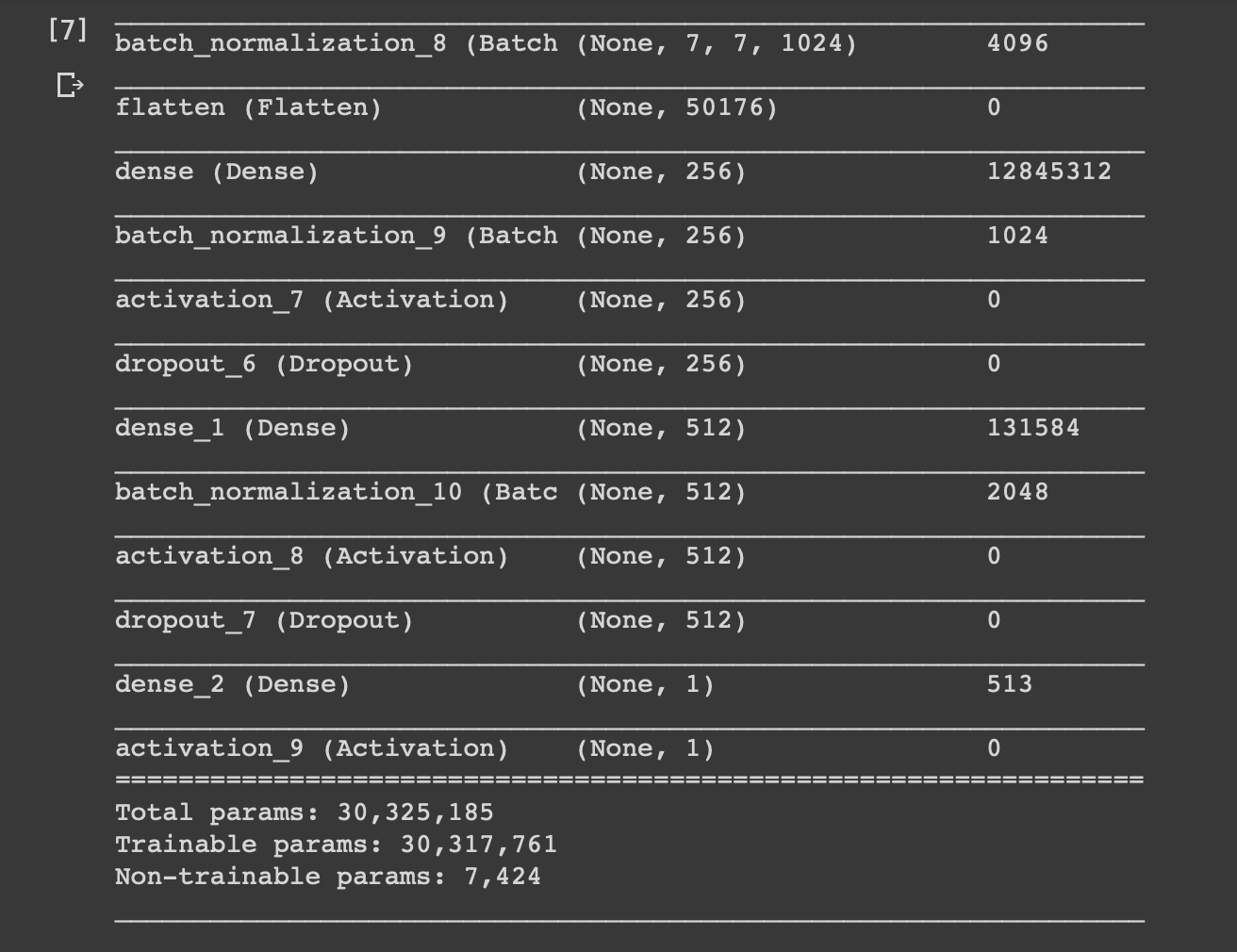
Training
Mình cũng dùng sgd thay cho adam vì tính ổn định của nó( ban đầu mình cũng đã thử dùng adam nhưng loss nó nhảy cóc quá) , đặt EarlyStopping để khi nào val_loss không tăng thì quá 10 ep thì tự nó dừng và đặt checkpoint để lưu lại model tối ưu nhất
sgd = SGD(lr=0.0001, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss=root_mean_squared_error, metrics=root_mean_squared_error)
earlyStopping = EarlyStopping(monitor='val_loss', patience=15, verbose=0, mode='min')
filepath = "{epoch:02d}-{val_loss:.2f}.h5"
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
history = model.fit(X_train, y_train, callbacks=[earlyStopping, checkpoint],
batch_size=128,
epochs=100,
verbose=1,
validation_data=(X_test, y_test))
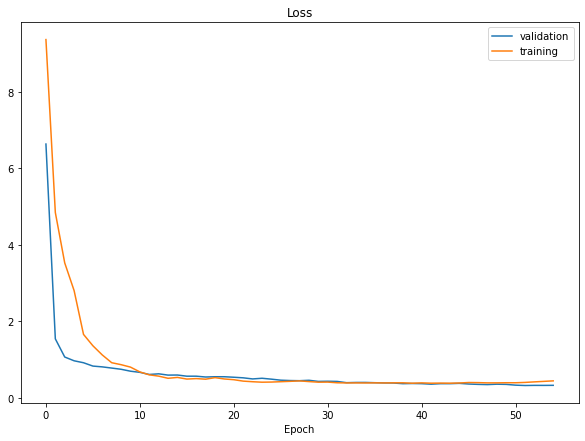
Đây là kết quả sau khi training của mình, loss ở con số khoảng 0.28 và mô hình khá là perfect fit :v
Một số bạn có thể thắc mắc tại sao không augmentation với ảnh để cho kết quả train tốt hơn, trả lời là mình đã thử rồi và nó chả tăng được là bao nhiêu  )
)
Face Detect
Sau khi có model ta sẽ xây dựng một function để detect ảnh from images mà không bị lẫn background đằng sau. Ở đây mình dùng Opencv để thực hiện công việc.
Đầu tiên là load đường dẫn ảnh và file haarcascade_frontalface_default.xml
imagepath = './images/old.jpg'
face_clf = cv2.CascadeClassifier('./haarcascade_frontalface_default.xml')
Đọc ảnh và xử lý
img = cv2.imread(imagepath)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_clf.detectMultiScale(gray, 1.3, 5)
Có một số lưu ý ở đây là:
- Việc face detect chỉ hoạt động trên hình ảnh thang độ xám. Vì vậy, điều quan trọng là chuyển đổi hình ảnh màu sang thang độ xám.
- detectMultiScale sử dụng để phát hiện nhiều mặt cùng một lúc của ảnh đầu vào,
scaleFactorchỉ định kích thước hình ảnh giảm đi bao nhiêu với mỗi tỷ lệ,minNeighbourslà số bounding box nên giữ lại(Việc tăng giảm tham số này ảnh hưởng đến việc detect khuôn mặt bạn có thể đọc thêm tại đây - faces là một list các mặt đã được detect .
Cuối cùng là cho vào vòng lặp draw rectangle vào input image
for (x, y, w, h) in faces:
fc = gray[y:y+h, x:x+w]
roi = cv2.resize(fc, (160, 160))
roi = roi.reshape((1,160,160,1))
pred = Model.model.predict(roi)[0][0]
cv2.putText(img, str(pred), (x, y), cv2.FONT_HERSHEY_SIMPLEX, 1, color[math.floor(pred)], 2)
cv2.rectangle(img,(x,y),(x+w,y+h),color[math.floor(pred)],2)
Results
Mà ở đây ảnh sẽ được tính theo thang từ 1-5 (1 là xấu/đzai nhất 5 là xinh/đzai nhất :v)
Mốt số kết quả:
Công chúa thuỷ tề Tùng Sơn :v

Tom Hiddleston với số điểm khá cao

Bà này mình chịu, gõ model trên gg xong ra :v

Web đo điểm số sắc đẹp ( Trong này đã được chuyển và tính theo thang 10): https://beauty.sun-asterisk.ai/
Link source code: Tại Đây
Bài viết của mình đến đây là hết rồi, có gì sai và không hiểu mong các bạn góp ý ở dưới cmt nhé, và hãy upvote cho mình vì một tương lai tươi đẹp nhất giữa chúng ta nhé, cảm ơn các bạn nhiều, hẹn các bạn trong bài viết tiếp theo )
Reference
All rights reserved
