
SIFT ( Scale-invariant feature transform) - Huấn luyện mô hình cho các bài toán phân loại
Bài đăng này đã không được cập nhật trong 6 năm
I. SIFT là gì ?
Tiếp nối chuỗi bài viết về các phương pháp trong xử lý ảnh, hôm nay mình xin giới thiệu tới các bạn về phương pháp trích chon đặc trưng SIFT. SIFT (Scale-invariant feature transform) là một feature descriptor được sử dụng trong computer vision và xử lý hình ảnh được dùng để nhận dạng đối tượng, matching image, hay áp dụng cho các bài toán phân loại...
- Với đầu vào là một hình ảnh >>> SIFT >>> các keypoint. Mỗi đối tượng trong hình ảnh sẽ cho ra rất nhiều các keypoint khác nhau, để ta phân biệt được các keypoint này với nhau sẽ thông qua một vector 128 chiều hay còn gọi là descriptor. Các descriptor này sẽ được dùng để nhận dạng đối tượng trong ảnh, hay dùng cho các bài toán classication.
- Hình ảnh sau khi áp dụng biến đổi SIFT, ứng với mỗi keypoint ta sẽ thu được: toạ độ keypoint, scale và orientation của keypoint, descriptor. Các mũi tên trong hình dưới vẽ nhờ vào scale và orientation.
![]()
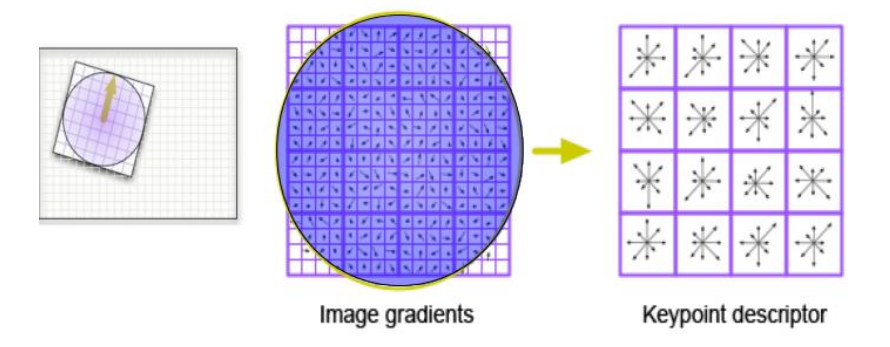
- 4x4 Gradient window
- HIstogram of 4x4 samples per window in 8 directions
- Gaussian weighting around center
- 4x4x8 = 128 dimensional feature vector
Đặc điểm :
- Các keypoint sẽ ít bị phụ thuộc bởi cường độ sáng, nhiễu, góc xoay của ảnh do các descriptor được tạo ra từ gradients do đó nó đã bất biến với các thay đổi về độ sáng (ví dụ: thêm 10 vào tất cả các pixel hình ảnh sẽ mang lại cùng một mô tả chính xác).
- Nhanh và hiệu quả, tốc độ xử lý gần như với thời gian thực (realtime)
- Có thể xử lý khi xoay ảnh
II. Áp dụng SIFT cho bài toán phân loại
Để khởi tạo đối tượng SIFT trong OpenCV ta sử dụng lệnh: sift = cv2.xfeatures2d.SIFT_create()
img = cv2.imread('path_to_image') #đọc ảnh
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # chuyển ảnh sang hệ gray
sift = cv2.xfeatures2d.SIFT_create() #khởi tạo đối tượng sift
kp, des = sift.detectAndCompute(img,None) #Đối tượng này có phương thức detectAndCompute trả về 2 outputs kp và des, kp là một list chứa các keypoints được detect bởi SIFT, des là một numpy array chứa len(kp) vectors 128 chiều.
print(des.shape)
img=cv2.drawKeypoints(gray,kp,img)
cv2.imwrite('path_to_image',img) #lưu ảnh
 Áp dụng cho bài toán phân loại:
Áp dụng cho bài toán phân loại:
def read_data(path_to_image):
X = [] #chứa image
Y = [] #chứa label
for label in os.listdir('path_to_image'):
for img_file in os.listdir(os.path.join('path_to_image', label)):
img = load_image(os.path.join('trainingset', label, img_file))
X.append(img)
Y.append(label2id[label])
return X, Y
Tiếp theo chúng ta sẽ trích xuất đặc trưng qua SIFT hoặc có thể SUFT, HOG. Trong phạm vi bài viết này thì mình sẽ sử dụng SIFT
def extract_sift_features(X):
image_descriptors = []
sift = cv2.xfeatures2d.SIFT_create()
for i in range(len(X)):
_, des = sift.detectAndCompute(X[i], None)
image_descriptors.append(des)
return image_descriptors
Hàm kmeans_bow() nhận đầu vào là một list gồm tất cả các descriptors của các ảnh trong tập X và số cụm num_clusters, sử dụng thuật toán KMeans trong scikit-learn phân cụm các vector descriptors này thành num_clusters cụm. Hàm trả về một danh sách center của các cụm. Vì thao tác này mất rất nhiều thời gian nên ta sẽ lưu danh sách trả về bởi hàm kmeans_bow() ra một file nhị phân.
import time
def kmeans_bow(image_descriptors, num_clusters):
strar = time.time()
bow_dict = []
kmeans = KMeans(n_clusters=num_clusters, n_jobs = -1, verbose = 1).fit(all_descriptors)
bow_dict = kmeans.cluster_centers_
print('process time: ', time.time() - start)
return bow_dict
num_clusters = 50
if not os.path.isfile('bow_dictionary.pkl'):
BoW = kmeans_bow(all_descriptors, num_clusters)
pickle.dump(BoW, open('bow_dictionary.pkl', 'wb'))
else:
BoW = pickle.load(open('bow_dictionary.pkl', 'rb'))
Xây dựng hàm create_features_bow() nhận đầu vào là list image_descriptors, list BoW và num_clusters ở trên, trả về list X_features, trong đó phần tử thứ p của X_vectors là vector đặc trưng theo mô hình BoW ứng với ảnh thứ p, tập keypoint descriptors thứ p. Hãy chú ý sự tương ứng các phần tử trong 4 danh sách: X, Y, image_descriptors, X_features.
def create_features_bow(image_descriptors, BoW, num_clusters):
X_features = []
for i in range(len(image_descriptors)):
features = np.array([0] * num_clusters)
if image_descriptors[i] is not None:
distance = cdist(image_descriptors[i], BoW)
argmin = np.argmin(distance, axis=1)
for j in argmin:
features[j] += 1
X_features.append(features)
return X_features
X_features = create_features_bow(image_descriptors, BoW, num_clusters)
Sau khi có X_feature chúng ta sẽ đưa vào các mô hình phân loại là xong. Các bạn có thể tham khảo các mô hình phân loại SVM.
Tài liệu tham khảo
Bài viết trên được mình tổng hợp khi mình tham gia học lớp của thầy Đinh Viết Sang - giảng viên trường Đại học Bách Khoa Hà Nội và một số tài liệu mình tham khảo dưới đây:
- Computer Vision: Algorithms and Applications, 2010 by Richard Szelisk
- Thư viện OpenCV
- https://en.wikipedia.org/wiki/Scale-invariant_feature_transform
Cảm ơn các bạn đã theo dõi bài viết của mình.
All rights reserved
