
Xây dựng hệ thống nhận dạng khuôn mặt real time - Phần 2: Xây dựng hệ thống hoàn chỉnh nhận dạng khuôn mặt với Hnswlib
Bài đăng này đã không được cập nhật trong 6 năm
Ở bài trước mình đã viết và đề cập tới việc search face bằng annoy và nó chỉ là một trong rất nhiều thư viện sử dụng thuật toán approximate nearest neighbors. Hôm nay mình sẽ nói rõ hơn và chi tiết hơn cách xây dựng một hệ thống nhận dạng khuôn mặt đơn giản from scrath từ các bước như: cách thu thập data của khuôn mặt, cách sử dụng và lấy data sao cho hợp lý nhất để search tốt nhất, ưu nhược điểm của thuật toán Approximate Nearest Neighbors... Các bạn có thể tham khảo code ở cuối bài. Cảm ơn tất cả các bạn đã đọc bài 
Lý thuyết một chút nhỉ
Ngày nay khi con người dùng càng nhiều internet thì lượng content sẽ càng phong phú hơn đông nghĩa với việc ngày càng có nhiều các cách hiệu quả để thực hiện tìm kiếm các thông tin đó. Đó là lý do mà Nearest Neighbor trở thành một chủ đề được nghiên cứu trong rất nhiều năm gần đây với mục tiêu "càng nhanh càng tốt mà vẫn đảm bảo độ chính xác tốt nhất có thể" chúng ta có một số kỹ thuật search như: exhaustive search so sánh một đối tượng với tất cả các đối tượng khác trong một dataset, the grid trick chia không gian search theo dạng lưới để search theo từng vùng.

Vấn đề của các cách tiếp cận ở trên là khi ta sử dụng nó với một bài toán có một bộ dữ liệu lớn thì thời gian query để ra được một đối tượng trong dataset sẽ cực kỳ, cực kỳ lâu, đơn giản bởi vì nó sẽ phải so sánh lần lượt với toàn bộ dữ liệu ta đang có thì mới ra được đối tượng cần tìm, chưa kể nó còn sẽ tốn bộ nhớ và độ trễ thấp => nên sử dụng với bộ dữ liệu nhỏ và vừa, không yêu cầu thời gian truy vấn nhanh.
Approximate Nearest Neighbors
Để khắc phục nhược điểm của thuật toán Nearest Neighbor truyền thống thì Approximate Nearest Neighbors (ANN) đã vào cuộc. Bằng cách trade off vài % accuracy để tăng peformance khi tìm kiếm. Vâng, ANN đã thể hiện rất rõ quan điểm "con hơn cha là nhà có phúc" rất rõ ràng.
Approximate Nearest Neighbor tăng tốc độ tìm kiếm index hiệu quả bằng cách xử lý với những phases sau:
- Vector Transformation: Áp dụng trước khi đánh index vào DB nào đó, các phương pháp transformation có thể là giảm số chiều vector hoặc vector rotation.
- Vector Encoding: Áp dụng trên tất cả các vector khi xây dựng các index để search. Sử dụng các kỹ thuật như: Trees, LSH and Quantization... để tạo data structure-based và một kỹ thuật để encode vector về nhỏ gọn hơn để tìm kiếm dễ hơn.
- None Exhaustive Search Component: Áp dụng trên các vectơ để tránh duyệt toàn diện trên dataset, trong số các kỹ thuật này có các tệp nghịch đảo(Inverted Files) và đồ thị lân cận(Neighborhood Graphs ).
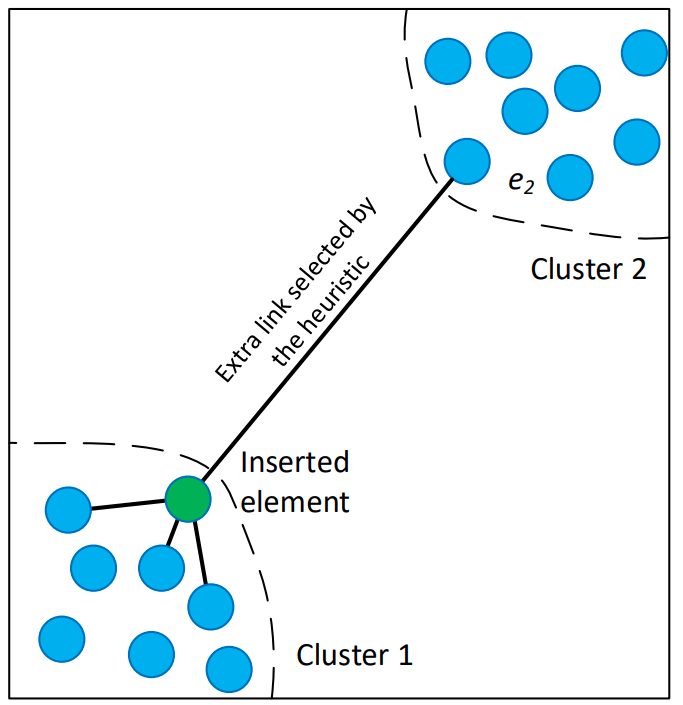
Hierarchical Navigable Small World Graphs(HNSW)

Một phương pháp tiếp cận mới để tìm kiếm K-nearest neighbor dựa trên navigable small world graphs. Để có thể tìm kiếm được một đối tượng nào đó trong dataset thì ta phải phân cấp và cấu trúc nó theo dạng graph. Rất nhiều graph trong thế giới thực có tính chất phân cụm rất cao và các node của đồ thị đó(đối tượng) có xu hướng gần nhau mà ta sẽ gọi là small-world graph. Để tìm kiếm ta sẽ bắt đầu tại một số điểm ngẫu nhiên và lặp đi lặp lại cách tìm kiếm đó ở từng small-world graph khác nhau , đi qua mỗi đồ thị thuật toán sẽ kiểm tra khoảng cách của truy vấn hàng xóm của node hiện tại và chọn node đó làm node cơ sở tiếp theo, từ đó sẽ giúp thu nhỏ khoảng cách lại. Thuật toán sẽ dừng tìm kiếm K hàng xóm tốt nhất khi gặp một số điều kiện được đáp ứng với thuật toán.
SEARCH-LAYER(q, ep, ef, lc)
Input: query element q, enter points ep, number of nearest to q elements to return ef, layer number lc
Output: ef closest neighbors to q
1 v ← ep // set of visited elements
2 C ← ep // set of candidates
3 W ← ep // dynamic list of found nearest neighbors
4 while │C│ > 0
5 c ← extract nearest element from C to q
6 f ← get furthest element from W to q
7 if distance(c, q) > distance(f, q)
8 break // all elements in W are evaluated
9 for each e ∈ neighbourhood(c) at layer lc // update C and W
10 if e ∉ v
11 v ← v ⋃ e
12 f ← get furthest element from W to q
13 if distance(e, q) < distance(f, q) or │W│ < ef
14 C ← C ⋃ e
15 W ← W ⋃ e
16 if │W│ > ef
17 remove furthest element from W to q
18 return W
Ta xây dựng thuật toán dự trên cách chèn liên tiếp các phần tử lưu trữ vào cấu trúc đồ thị đã từ ban đầu. Với mỗi phần từ được chèn vào tương ứng với một layer gọi là là một số nguyên được chọn ngẫu nhiên với phân phối xác xuất rời rạc theo cấp số nhân. Theo thuật toán ở trên thì phase đầu tiên trong quá trình bắt đầu từ top layer bằng cách sử dụng giải thuật tham lam đi qua graph theo trình tự để tìm ra láng giềng gần nhất đến phần tử được chèn là trong layer. Sau đó giải thuật tiếp tục search layer tiếp theo bằng láng giềng gần nhất vừa tìm được, và quá trình lặp đi lặp lại như vậy cho đến khi tìm được đủ số láng giềng gần nhất cần tìm.
Ưu điểm
- Ta có thể điều chỉnh tham số để trade off accuracy và tốc độ truy vấn
- Hộ trợ truy vấn với batchsize lớn
- Thuật toán có độ phức tạp thời gian đa giác và có thể vượt trội hơn thuật toán đối thủ trên nhiều bộ dữ liệu trong thế giới thực.
Nhược điểm
- Hoạt động kếm khi điểm similarity ở khoảng cách xa so với điểm cần truy vấn.
- Cần nhiều bộ nhớ (RAM)
Hnswlib
pip install hnswlib
Đây là một thư viện fast approximate nearest neighbor search dựa trên thuật toán HNSW
- Nhẹ, nhanh ít dụng lượng
- Có suport C++, python và R
- Hỗ trợ thêm và xóa phần tử mà không giải phóng bộ nhớ (annoy không làm được)
- Có thể tự định nghĩa hàm tìm kiếm khoảng cách riêng (C++)
Thực hành nào
Các thự viện cần cài đặt
Dlib - là một bộ toolkit viết bằng C++ chứa các thuật toán machine learning, deep learning xử lý rất nhiều vấn đề trong computer vision, nhưng điều chúng ta biết nhiền nhất đến dlib là sử dụng nó cho bài toán nhận dạng khuôn mặt với độ chính xác và truy vấn và độ chính xác không cần quá cao.
Cách cài đặt dlib cho Mac và Ubuntu các bạn có thể tham khảo tại đây:
OpenCV - OpenCV (Open Source Computer Vision Library) là một thư viện mã nguồn mở về lĩnh vực computer vision và machine learning. OpenCV được xây dựng để cung cấp cơ sở hạ tầng chung cho các ứng dụng thị giác máy tính và để đẩy nhanh việc sử dụng nhận thức của máy trong các sản phẩm thương mại.
Cách cài dặt opencv:
pip install opencv-python
Face_Recognition - Thư viện nhận dạng khuôn mặt được viết bằng Python cực kỳ đơn giản sử dụng deep learning.
Cách cài đặt Face_Recognition:
pip install face-recognition
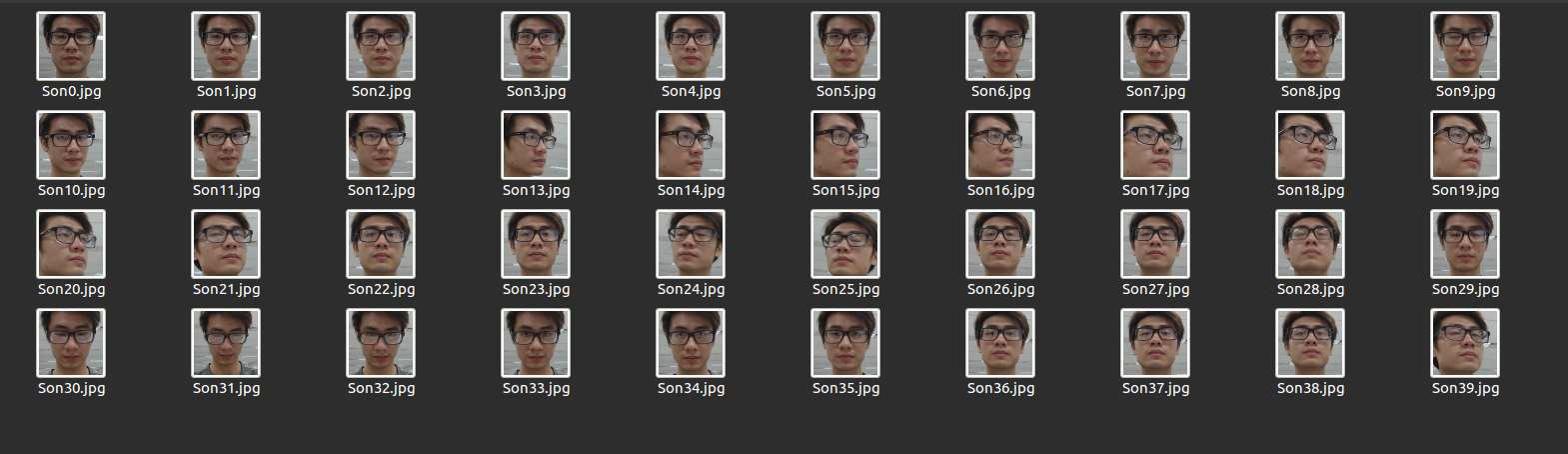
Thu thập dữ liệu
import cv2
import numpy as np
import os
import dlib
from imutils import face_utils
from imutils.face_utils import FaceAligner
Đầu tiên ta import các thư viện cần thiết
detector = dlib.get_frontal_face_detector()
shape_predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
face_aligner = FaceAligner(shape_predictor, desiredFaceWidth=IMAGE_SIZE)
video_capture = cv2.VideoCapture(0)
name = input("Enter name of person:")
Giải thích code:
- Khởi tạo face object detection với function
get_frontal_face_detector - Detect face landmarks và trả về các key points trên khuôn mặt, ở đây dlib sẽ trả về 62 points
- Align các khuôn mặt bằng cách sử dụng phép biến đổi affine bằng function
FaceAligner, các bạn có thể đọc thêm tại đây - Sau đó khởi tạo hàm
VideoCaptuređể capture video, tham số'0'là dùng cho những thiết bị camera cắm ngoài vào.
while number_of_images < MAX_NUMBER_OF_IMAGES:
ret, frame = video_capture.read()
frame = cv2.flip(frame, 1)
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#faces = face_cascade.detectMultiScale(frame, 1.3, 5)
faces = detector(frame_gray)
if len(faces) == 1:
face = faces[0]
(x, y, w, h) = face_utils.rect_to_bb(face)
face_img = frame_gray[y-50:y + h+100, x-50:x + w+100]
face_aligned = face_aligner.align(frame, frame_gray, face)
if count == 5:
cv2.imwrite(os.path.join(directory, str(name+str(number_of_images)+'.jpg')), face_aligned)
number_of_images += 1
count = 0
print(count)
count+=1
Giải thích code:
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)Chuyển kênh màu RGB sang thang đo độ xámnumber_of_images < MAX_NUMBER_OF_IMAGESMình setMAX_NUMBER_OF_IMAGES = 40, vòng sẽ lặp qua từng frame và dừng lại khi detect và cap đủ 40 images(x, y, w, h) = face_utils.rect_to_bb(face)Lấy các tọa độ của face trên frameface_img = frame_gray[y-50:y + h+100, x-50:x + w+100]Trả về face đã được cut từ các tọa độ lấy ở trên, các tham số 50, 100 chỉ là để căn chỉnh thêm cho khuôn mặt( có thể thêm vào hoặc không)face_aligned = face_aligner.align(frame, frame_gray, face)Align face với hàm FaceAligner đã nói ở trên
Results:
Đánh index
import cv2
import numpy as np
import imutils
from tqdm import tqdm
import face_recognition
from imutils import paths
import matplotlib.pyplot as plt
import os
from mtcnn.mtcnn import MTCNN
import hnswlib
Đầu tiên import thư viện
p = hnswlib.Index(space = 'l2', dim = DIM)
p.init_index(max_elements = NUM_ELEMENTS, ef_construction = EF_CONSTRUCTION, M = M)
imagePaths = list(paths.list_images('images'))
detector = MTCNN()
Giải thích code:
p = hnswlib.Index(space = 'l2', dim = DIM)Khởi tạo không gian vớiDIMlà số chiều cần khởi tạo trong không gian (không gian này sẽ là chỗ lưu trữ các index để tìm kiếm)p.init_index(max_elements = NUM_ELEMENTS, ef_construction = EF_CONSTRUCTION, M = M)khởi tạo các index rỗng vào trong space, vớimax_elementslà số lượng phần tử tối đa có thể được lưu trữ trong cấu trúc,ef_constructionlà thời gian khởi tạo/đánh đổi accuracy vs speed khi search,Mlà số lượng node kết nối với nhau để tạo nên small world graphs trong graph.detector = MTCNN()Sử dụng MTCNN để kiểm tra và trích xuất face một lần nữa trước khi đánh index
def image_encoding(coodirnate, img):
x, y, w, h = [v for v in coodirnate]
x2, y2 = x + w, y + h
face = img[y:y+h, x:x+w]
img_emb = face_recognition.face_encodings(face)
return img_emb
Ta sử dụng thư viện face_recognition để encode image ra vector 128 chiều thì mới đánh index được, function image_encoding sẽ encode face images ra thành vector 128 chiều cho chúng ta.
for i, imagePath in tqdm(enumerate(imagePaths)):
coodirnate, img = check_image_path(imagePath)
if img.shape == (IMAGE_SIZE, IMAGE_SIZE, DIMENTIONAL):
img_emb = face_recognition.face_encodings(img)
if len(img_emb) == 0:
pass
else:
p.add_items(np.expand_dims(img_emb[0], axis = 0), i)
else:
if len(coodirnate) == 0:
pass
else:
img_emb = image_encoding(tuple(coodirnate), img)
if len(img_emb) == 0:
pass
else:
p.add_items(np.expand_dims(img_emb[0], axis = 0), i)
index_path='images.bin'
print("Saving index to '%s'" % index_path)
p.save_index("images.bin")
del p
Khởi tạo vòng lặp để ecode từng images và đánh index
p.add_items(np.expand_dims(img_emb[0], axis = 0), i)expand dimension sau đó add vào spacep.save_index("images.bin")space sẽ được lưu dưới dạng file là"images.bin"có thể coi nó là một database và chúng ta search trên nó.
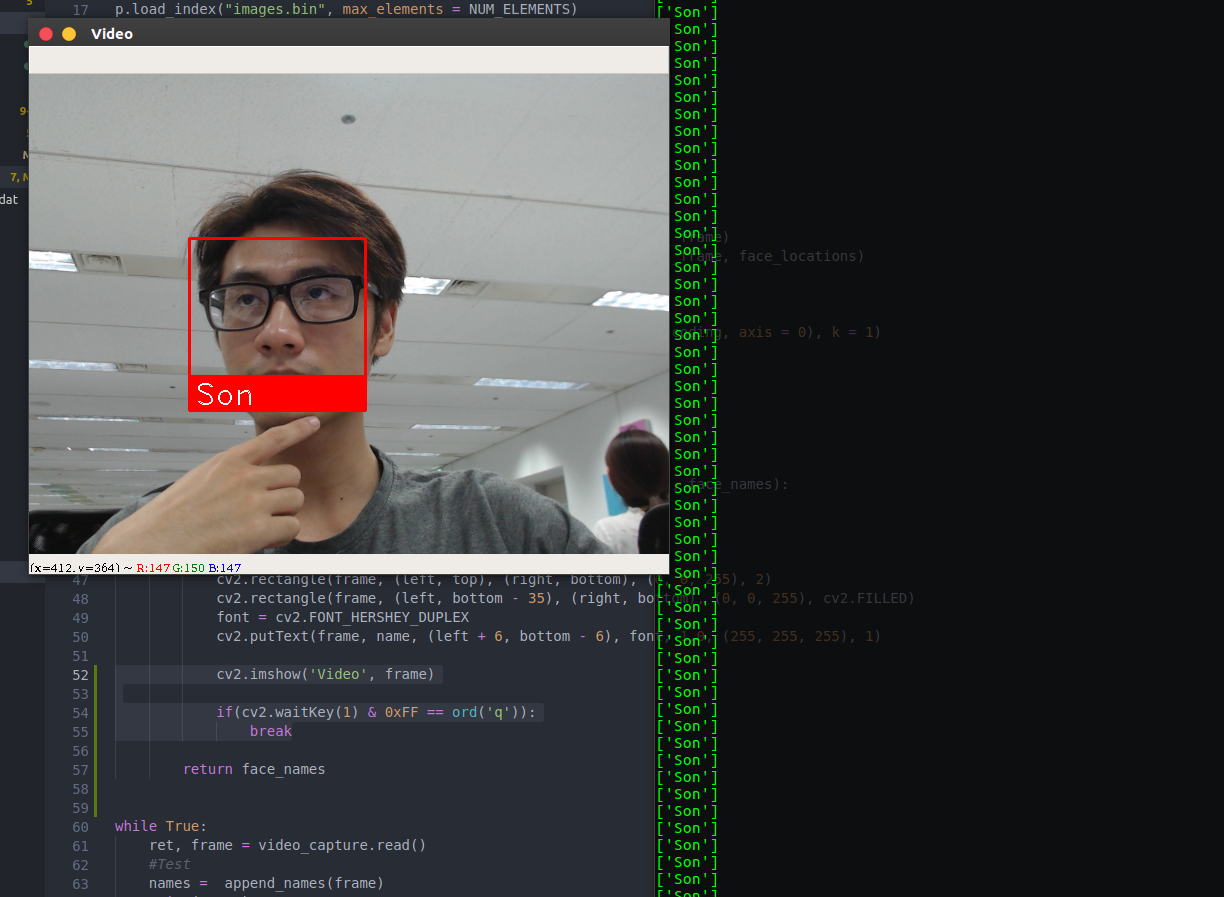
Search face với Hnswlib
import cv2
import numpy as np
import imutils
import face_recognition
from imutils import paths
import matplotlib.pyplot as plt
import os
from collections import Counter
import time
import hnswlib
import thư viện
output_name = []
known_face_names = []
video_capture = cv2.VideoCapture(0)
p = hnswlib.Index(space='l2', dim=DIM) # the space can be changed - keeps the data, alters the distance function.
p.load_index("images.bin", max_elements = NUM_ELEMENTS)
imagePaths = list(paths.list_images('images'))
p.load_index("images.bin", max_elements = NUM_ELEMENTS)Load index từ fileimages.bin,max_elementsĐặt lại số lượng phần tử tối đa trong cấu trúc file.
for i, imagePath in enumerate(imagePaths):
name = imagePath.split(os.path.sep)[-2]
known_face_names.append(name)
Lấy tên từ các thư mục đã được đánh index từ trước và append nó vào trong một mảng
def append_names(frame):
small_frame = cv2.resize(frame, (0, 0), fx=FX, fy=FY)
rgb_small_frame = small_frame[:, :, ::-1]
face_locations = face_recognition.face_locations(rgb_small_frame)
face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations)
face_names = []
for face_encoding in face_encodings:
labels, distances = p.knn_query(np.expand_dims(face_encoding, axis = 0), k = 1)
known_face_encoding = p.get_items([labels])
name = "unknown"
if distances < 0.13:
name = known_face_names[labels[0][0]]
face_names.append(name)
return face_names
rgb_small_frame = small_frame[:, :, ::-1]Chuyển về kênh màu RGBface_locations = face_recognition.face_locations(rgb_small_frame)Trả về tọa độ của face có trong frameface_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations)Kết hợp giữa cut face từ frame với tọa độ cho trước và encode nó ra thành vector 128 chiềulabels, distances = p.knn_query(np.expand_dims(face_encoding, axis = 0), k = 1)Với face_encoding vừa lấy ra được từ frame ta sẽ thực hiện query nó trong DBif distances < 0.13:Nếu euclidean distance của face vừa trích xuất ra với face trong DB mà nhỏ hơn 0.13 thì xuất ra tên đã tìm được nếu ko trả về "unknown"
Result
Trên đây là hướng dẫn về cách xây dựng một hệ thống nhận dạng khuôn mặt bằng cách sử dụng fast approximate nearest neighbor search, trong quá trình đọc nếu có chỗ nào không hiểu hoặc sai thì mong các bạn có thể góp ý ở bên dưới, cảm ơn các bạn
Code của bài viết: Tại đây
Reference
All rights reserved
