Cách tạo ra ngôn ngữ con người từ hư vô - Natural Language Generation với Language Model
Bài đăng này đã không được cập nhật trong 5 năm
Natural Language Generation là gì?
Là cách mà máy tính học và tạo ra các câu và cụm từ có ý nghĩa
NLG là một subfiled của NLP ( Natural Language Processing) liên quan đến việc tạo tự động văn bản mà con người có thể đọc được bằng máy tính. NLG được sử dụng trong một loạt các nhiệm vụ như Dịch máy, Chuyển giọng nói thành văn bản, chatbot, tự động sửa văn bản hoặc tự động hoàn thành văn bản.
Language Modeling
Chúng ta có thể tạo ra model NLG bằng cách dùng laguage modeling. Hãy xem ví dụ dưới đây:

Chúng ta có thể thấy câu đầu tiên, "The cat is small" hợp lý hơn câu thứ hai là "small the is cat", bởi vì chúng ta biết câu thứ hai về mặt ngữ nghĩa và ngữ pháp là không đúng. Đây là nền tảng cho khái niệm cơ bản đằng sau language modeling. Một language model phải có thể phân biệt giữa một chuỗi các từ đúng với không đúng.
Các loại Language Models
- Statistical Language Models: Các mô hình này sử dụng các kỹ thuật thống kê truyền thống như N-gram, Hidden Markov Models và các quy tắc ngôn ngữ để tìm hiểu phân phối xác suất của các từ.
- Neural Language Models: Ta sẽ sử dụng các loại mạng DNN như RNN, LSTM,... để tạo ra một model NLG cho mình. Và thực thế các này có hiệu quả hơn các kỹ thuật truyền thống.
Tự động sinh văn bản bằng Neural Language Modeling
Tự động sinh văn bản bằng Mô hình ngôn ngữ thống kê
Trước hết, hãy xem cách ta có thể tạo văn bản với sự trợ giúp của mô hình thống kê, chẳng hạn như mô hình N-Gram. Để hiểu cách hoạt động của mô hình ngôn ngữ N-Gram hãy xem Tại đây
Ví dụ ta cần phải Gen ra tiếp từ tiếp theo cho câu dưới đây:
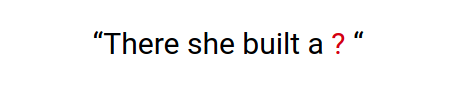
Giả sử mô hình N-Gram biết được ngữ cảnh của 3 từ trước đó để dự đoán được từ tiếp theo sau từ "a". Để làm được điều đó thì model sẽ cố gắng để maximize xác xuất P(w | “she built a”), trong đó ‘w’ đại diện cho từng từ trong văn bản. Từ nào maximizes xác suất trên sẽ được tạo thành từ tiếp theo cho câu "There she build a...".
Tuy nhiên, sẽ có những hạn chế nhất định của việc sử dụng các mô hình thống kê như sử dụng các từ ngay trước đó làm ngữ cảnh để dự đoán từ tiếp theo. hãy xem ví dụ dưới đây:
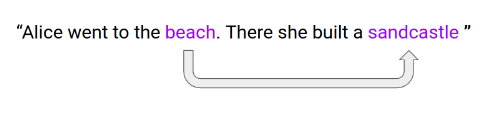
Chúng ta có thể thấy ở câu trên là chúng ta đã có các thông tin các gì sẽ diễn ra tiếp theo. Từ "sandcastle" rất có khả năng là từ tiếp theo vì nó có liên quan đến "beach" bời vì theo cách thông thường đi biển sẽ xây lâu đài cát. Vì thế từ "sandcastle" sẽ không phụ thuộc bối cảnh của 3 từ đằng sau nó là "she build a" nữa mà nó sẽ phụ thuộc hoàn toàn vào từ "beach".
Tự đông sinh văn bản bằng cách sử dụng mô hình ngôn ngữ thần kinh
Ở đây chúng ta sẽ sử dụng mô hình ngôn ngữ dựa trên RNN/LSTM:
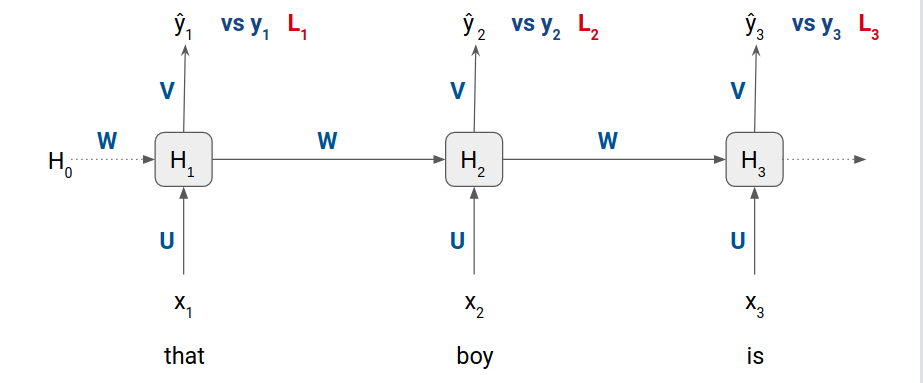
- x1, x2 và x3 lần lượt là các input words embedding vào tại bước 1, bước 2 và bước 3 tương ứng
- ŷ1, ŷ2 và ŷ3 là phân phối xác suất của tất cả các tokens khác nhau trong training dataset.
- y1, y2, y3 là giá trị ground truth
- U, V và W là weight của các ma trận
- H0, H1, H2, and H3 là các hidden states
Các bước xử lý của Neural Language Models
Chúng ta sẽ xử lý với neural language modeling với 3 bước:
- Chuẩn bị dữ liệu
- Huấn luyện mô hình
- Tạo ra văn bản
Chuẩn bị dữ liệu
Giả sử chúng ta có các câu sau trước khi cho vào training:
[ ‘alright that is perfect’, ‘that sounds great’, ‘what is the price difference’]
Câu đầu có 4 tokens, câu thứ hai có 3 tokens và câu thứ ba có 5 tokens và các từ trong mỗi tokens đều có độ dài khác nhau. Do đặc điểm của LSTM chỉ nhận đầu vào là các chuỗi có độ dài giống nhau, nên ta sẽ xử lý sao cho các câu sẽ có cùng độ dài trước khi cho vào training.
Có nhiều kỹ thuật để tạo các chuỗi có độ dài bằng nhau. Một trong số đó là padding. Tuy nhiên, nếu chúng ta sử dụng kỹ thuật này thì chúng ta sẽ phải xử lý các tokens trong quá trình tính toán loss và Gen ra text.
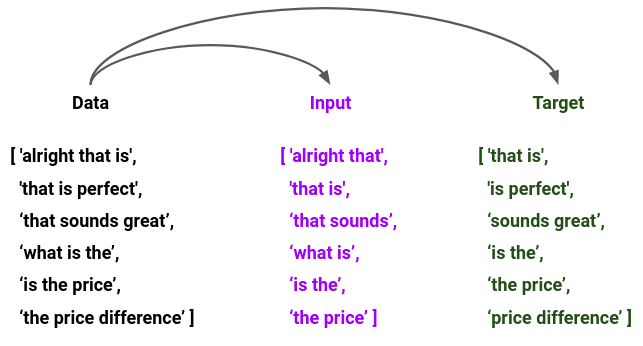
Cách xử lý là ta sẽ chia nhỏ các câu trên ra thành các chuỗi bằng nhau, câu nào càng nhiều từ thì ra cũng sẽ phải tách càng nhiều:
[ ‘alright that is’, ‘that is perfect’, ‘that sounds great’, ‘what is the’, ‘is the price’, ‘the price difference’ ]
Huấn luyện mô hình
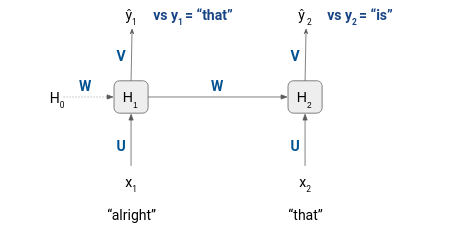
Với hình ảnh ở trên ta có thể thấy inputs đầu tiên của chúng ta là "alright" và "that" , tương ứng với nó là hai tokens "that" và "is". Do đó, trước khi bắt đầu quá trình training, ta sẽ phải tách tất cả các trình tự trong một câu thành các đầu vào và mục tiêu như hình dưới đây:
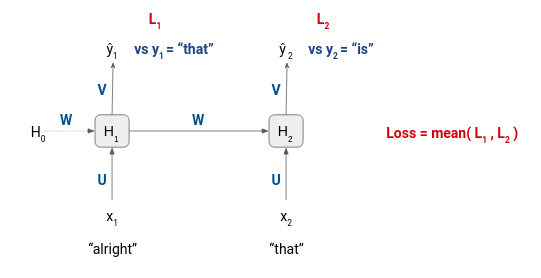
Vì thế tất cả các cặp input và target sẽ được đi qua mạng và tổng loss của quá trình training sẽ là trung bình loss của một step của mỗi cặp.
Hãy xem cách mô hình này tạo ra văn bản:
Tạo ra văn bản
Như đã nói ở trên ta có thể dùng laguage model cho NLG, Ý tưởng chính là input đầu vào sẽ là một chuỗi văn bản với các tokens mà mô hình gen ra và làm input tiếp theo. Ta sẽ xem ví dụ trực quan dưới ddaay:
Input text = "What is" n = 2
Bước 1: Token đầu tiên "what" sẽ được cho qua LSTM model. Nó sẽ tạo ra output ŷ1 cái mà chúng ta sẽ bỏ qua vì nó là token "is". Model sẽ tiếp tục tạo ra hidden state H1 và cho vào timestep tiếp theo.
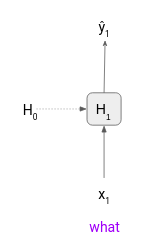
Bước 2: Sau đó token "is" sẽ được đưa qua timestep 2 cùng với H1. Output của timestep này sẽ là một phân phối xác suất với token "going" sẽ là giá trị maximum. Vì thế chúng ta sẽ xem xét và coi nó là token đã được dự đoán của model(vì nó mang phân phối xác suất lớn nhất).
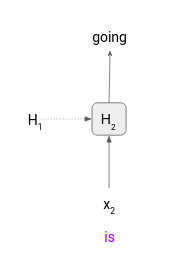
Bước 3: Để tạo ra được token tiếp theo ta cần phải pass input token của model vào tại timestep 3. Tuy nhiên, chúng ta đã hết input tokens, "is" là token cuối được tạo ra "going". Câu hỏi đặt ra là ta sẽ pass cái gì tiếp với input tiếp theo? Trong trường hợp đó ta sẽ pass token được tạo ra làm input token tiếp theo mà ở đây là "going".
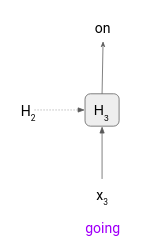
Kết quả cuối cùng sẽ là "what is going on". Đấy là một đoạn text được thực hiện bởi NLG.
Lời kết
Ở trên là những kiến thức cơ bản của NLG và các nó hoạt động, nếu bài viết có chỗ nào không hiểu hoặc không đúng mong các bạn đừng ngần ngại mà góp ý. Cảm ơn các bạn 
All rights reserved
