
RaLSGAN cho bài toán Motorbike Generator trong cuộc thi Zalo Challenge
Bài đăng này đã không được cập nhật trong 6 năm
Zalo đang tổ chức một cuộc thi về Ai cho toàn thể ACE trong "Ngành". Một trong ba bài toán đó là bài Motorbike Generator và tất nhiên requirement của nó y hệt như cái bài Dog Generator trên Kaggle, khác mỗi đầu ra là 128x128 còn bài Dog Generator là 64x64 :v. Và mình cũng tham gia góp vui với một tinh thần 3H - Ham học hỏi :v. Bài viết này mình đề cập tới những kinh nghiệm của mình trong việc quan sát dữ liệu, xử lý ảnh, cũng như cách training mô hình... Đây chỉ là kinh nghiệm của mình trong quá trình mình làm và học đc, nếu có chỗ nào sai sót mong mọi người gạch đá nhè nhẹ  )
)
Yêu cầu bài toán
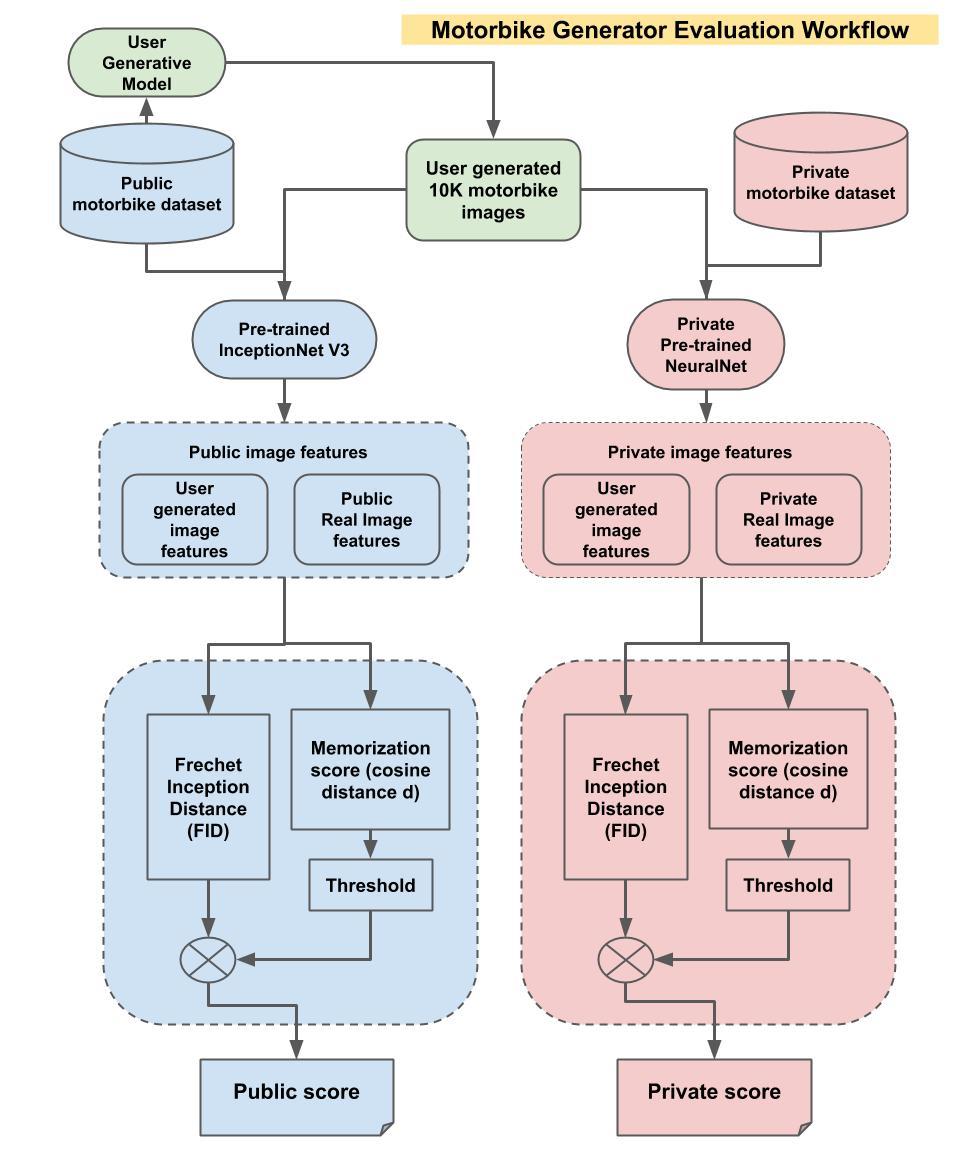
Hiểu đơn giản là sử dụng 10000 mà bên Zalo cho và sinh ra 10000 ảnh với định dạng là PNG từ bộ dữ liệu cho trước , evaluation metric là FID.
Lý thuyết
Để đọc thêm về FID evalutation mời các bạn đọc Tại đây
Mình sẽ sử dụng RaLSGAN cho bài toán này. Vậy RaLSGAN là cái vẹo gì? TL: nó chỉ là mạng GAN thông thường nhưng với một loss function tối ưu hơn
Loss Functions
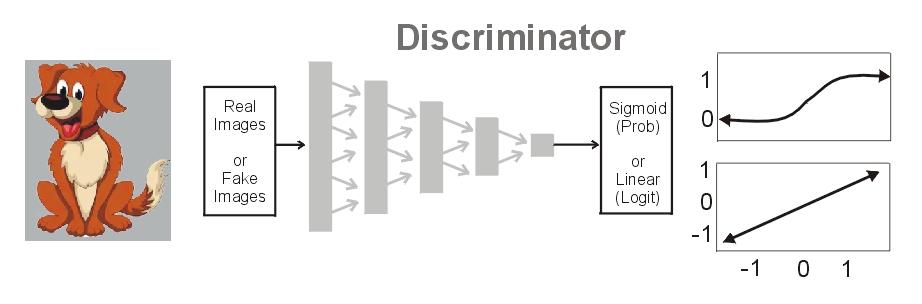
Một Discriminator đầu ra có thể là hàm kích hoạt sigmoid hoặc linear. Nếu là sigmoid chúng ta có phân bố xác xuất rời rạc của một hình ảnh là thực là Pr(real) . Còn với linear chúng ta có C(x) = logit . Xác suất nằm trong khoảng (0,1). Và logit có thể là bất cứ số nào trong khoảng (0,1) . Số dương đại diện cho ảnh real còn âm đại diện cho ảnh fake.
Simple loss
Ta gọi x_r là ảnh thật, và x_f là ảnh fake thì ta sẽ có D(x) = Pr(Real) hay C(x) = Logit sẽ trở thành 2 ouptput của một Discriminator khi input là một hình ảnh, Loss Function sẽ như sau:
# Take AVG over x_r and x_f in batch
disc_loss = (1 - D(x_r)) + (D(x_f) - 0)
gen_loss = (1 - D(x_f))
Chúng ta muốn Discriminator D(x_r) = 1 và D(x_f) = 0 tương đương với nhãn real và fake, và sau khi huấn luyện xong ta thì Generator càng gần 1 càng tốt. Nói nôm na là ta dùng ảnh thật làm bộ dữ liệu huấn luyện cho vào Discriminator để mạng có thể phân biệt được ảnh real và ảnh fake, và từ đó Discriminator sẽ phản hồi về cho Generator để nó tự hoàn thiện mình dựa vào phản hồi đó đó là lý do D(x_r) = 1 và D(x_f) = 0. Nếu các bạn muốn tìm hiểu sâu hơn về mạng GAN mời đọc Tại đây
DCGAN Loss
Ta thấy rõ Basic GAN và DCGAN sử dụng D(x):
# Take AVG over x_r and x_f in batch
disc_loss = -log (D(x_r)) - log (1-D(x_f))
gen_loss = -log (D(x_f))
RaLSGAN Loss
RaLSGAN sử dụng C(x) = logit:
# Take AVG over x_r and x_f in batch
disc_loss = (C(x_r) - AVG(C(x_f)) - 1)^2 + (C(x_f) - AVG(C(x_r)) + 1)^2
gen_loss = (C(x_r) - AVG(C(x_f)) + 1)^2 + (C(x_f) - AVG(C(x_r)) - 1)^2
Code
Ta sẽ sử dụng pytorch để code cho bài toán này, việc đầu tiên là thay đổi hàm kích hoạt từ sigmoid sang logit(có thể là tanh) ở dòng cuối:
#x = torch.sigmoid(self.conv5(x))
x = self.conv5(x)
Tiếp theo ta sẽ update loss của G và D:
############################
# (1) Update D network
###########################
netD.zero_grad()
real_images = real_images.to(device)
batch_size = real_images.size(0)
labels = torch.full((batch_size, 1), real_label, device=device)
outputR = netD(real_images)
noise = torch.randn(batch_size, nz, 1, 1, device=device)
fake = netG(noise)
outputF = netD(fake.detach())
errD = (torch.mean((outputR - torch.mean(outputF) - labels) ** 2) +
torch.mean((outputF - torch.mean(outputR) + labels) ** 2))/2
errD.backward(retain_graph=True)
optimizerD.step()
############################
# (2) Update G network
###########################
netG.zero_grad()
outputF = netD(fake)
errG = (torch.mean((outputR - torch.mean(outputF) + labels) ** 2) +
torch.mean((outputF - torch.mean(outputR) - labels) ** 2))/2
errG.backward()
optimizerG.step()
Xử lý dữ liệu
Trong tất cả các bài toán DL thì dữ liệu luôn là thứ quan trọng nhất, và việc đầu tiên ta phải làm là quan sát bộ dữ liệu và tìm ra đặc điểm để xử lý theo yêu cầu. Và như ta thấy bộ dữ liệu của ta gồm 10.000 ảnh gồm:
- Các kích cỡ và định dạng khác nhau
- Nhiều ảnh GIF đặc trưng và lỗi
- Dữ liệu không đồng đều
- Nhiều xe hoặc nhiều vật cản trong một ảnh
- Đa phần là những ảnh có chiều quay là ngang
- Nhiều xe có đặc điểm gị thường và không đồng nhất với bộ dữ liệu
Cách xử lý:
- Loại bỏ những vật thừa trong ảnh và phân loại xe bằng cách sử dụng yolov3 Ở đây.
- sau khi loại bỏ những vật thừa và phân loại xe ta sẽ lọc dữ liệu bằng tay, vì bộ dữ liệu bao gồm rất nhiều xe đa dạng và ảnh không đúng định dạng bị lỗi
- Loại bỏ những xe có chi tiết thừa thãi và có ít trong bộ dữ liệu, chung quy là những xe không đa dạng và có đặc điểm "dị"
- Loại bỏ những ảnh có background quá màu mè
Preprocessing
Sau khi xử lý xong công đoạn trên để đưa ra được tập dữ liệu tốt thì việc chúng ta cần làm tiếp theo là đưa ảnh về kích cỡ 128x128 để đưa vào mạng. Có 2 option cho việc này:
- Padding images: thêm khoảng không gian bên trong ảnh, khoảng không gian này sẽ được cộng dồn thêm vào chiều rộng hoặc chiều cao của ảnh mà không bị biến dạng ảnh
- Resize images: Đưa ảnh về kích thước 128x128 luôn và co giãn ảnh theo chiều rộng hoặc chiều cao Nhưng vấn đề ở chỗ khi mình training xong và thử cả hai trường hợp và FID evaluation thì thấy padding images cho kết quả đầu ra tốt hơn, tức là mạng học hiệu quả hơn
def padding_image(img):
im = mpimg.imread(img)
old_size = im.shape[:2] # old_size is in (height, width) format
ratio = float(desired_size)/max(old_size)
new_size = tuple([int(x*ratio) for x in old_size])
# new_size should be in (width, height) format
im = cv2.resize(im, (new_size[1], new_size[0]))
delta_w = desired_size - new_size[1]
delta_h = desired_size - new_size[0]
top, bottom = delta_h//2, delta_h-(delta_h//2)
left, right = delta_w//2, delta_w-(delta_w//2)
color = [0, 0, 0]
new_im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
new_im = (new_im - 127.5) / 127.5
return new_im
Đọc đường dẫn của ảnh:
PATH = '../dataset'
OUTPUT_PATH = '../padding_image_last'
files = []
# r=root, d=directories, f = files
for r, d, f in os.walk(PATH):
for file in f:
files.append(os.path.join(r, file))
Tạo vòng lặp và gọi hàm để padding Images:
for i in tqdm(range(0,len(files))):
img = padding_image(files[i])
matplotlib.image.imsave(os.path.join(OUTPUT_PATH , f'image_{i:05d}.jpg'), img)
Sau khi padding images xong thì chúng ta images augmentation. Mình đã xử dụng các kỹ thuật lất ảnh và quay ảnh, trước đó mình có tăng độ tương phản nhưng kết quả ra khá tệ
transform1 = transforms.Compose([transforms.Resize((128,128))])
# Data augmentation and converting to tensors
random_transforms = [transforms.RandomRotation(degrees=5)]
transform2 = transforms.Compose([transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply(random_transforms, p=0.3),
# transforms.RandomApply([transforms.ColorJitter(brightness=0.2, contrast=(0.9, 1.2), saturation=0.3, hue=0.01)], p=0.5),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
Training mô hình
Như mình đã nói ở trên RaLSGan là một mạng GAN bình thường nó có thể là DCGAN, hay SGAN ... nhưng với một hàm loss tốt hơn.
Generator sẽ như sau:
class Generator(nn.Module):
def __init__(self, nz=128, channels=3):
super(Generator, self).__init__()
self.nz = nz
self.channels = channels
def convlayer(n_input, n_output, k_size=4, stride=2, padding=0):
block = [
nn.ConvTranspose2d(n_input, n_output, kernel_size=k_size, stride=stride, padding=padding, bias=False),
nn.BatchNorm2d(n_output),
nn.ReLU(inplace=True),
]
return block
self.model = nn.Sequential(
*convlayer(self.nz, 1024, 4, 1, 0), # Fully connected layer via convolution.
*convlayer(1024, 512, 4, 2, 1),
*convlayer(512, 256, 4, 2, 1),
*convlayer(256, 128, 4, 2, 1),
*convlayer(128, 64, 4, 2, 1),
*convlayer(64, 32, 4, 2, 1),
nn.ConvTranspose2d(32, self.channels, 3, 1, 1),
nn.Tanh()
)
def forward(self, z):
z = z.view(-1, self.nz, 1, 1)
img = self.model(z)
return img
Như ta có thể thấy output đầu ra của G là 128x128 với hơn 13 triệu tham số
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ConvTranspose2d-1 [-1, 1024, 4, 4] 2,097,152
BatchNorm2d-2 [-1, 1024, 4, 4] 2,048
ReLU-3 [-1, 1024, 4, 4] 0
ConvTranspose2d-4 [-1, 512, 8, 8] 8,388,608
BatchNorm2d-5 [-1, 512, 8, 8] 1,024
ReLU-6 [-1, 512, 8, 8] 0
ConvTranspose2d-7 [-1, 256, 16, 16] 2,097,152
BatchNorm2d-8 [-1, 256, 16, 16] 512
ReLU-9 [-1, 256, 16, 16] 0
ConvTranspose2d-10 [-1, 128, 32, 32] 524,288
BatchNorm2d-11 [-1, 128, 32, 32] 256
ReLU-12 [-1, 128, 32, 32] 0
ConvTranspose2d-13 [-1, 64, 64, 64] 131,072
BatchNorm2d-14 [-1, 64, 64, 64] 128
ReLU-15 [-1, 64, 64, 64] 0
ConvTranspose2d-16 [-1, 32, 128, 128] 32,768
BatchNorm2d-17 [-1, 32, 128, 128] 64
ReLU-18 [-1, 32, 128, 128] 0
ConvTranspose2d-19 [-1, 3, 128, 128] 867
Tanh-20 [-1, 3, 128, 128] 0
================================================================
Total params: 13,275,939
Trainable params: 13,275,939
Non-trainable params: 0
----------------------------------------------------------------
Discriminator:
class Discriminator(nn.Module):
def __init__(self, channels=3):
super(Discriminator, self).__init__()
self.channels = channels
def convlayer(n_input, n_output, k_size=4, stride=2, padding=0, bn=False):
block = [nn.Conv2d(n_input, n_output, kernel_size=k_size, stride=stride, padding=padding, bias=False)]
if bn:
block.append(nn.BatchNorm2d(n_output))
block.append(nn.LeakyReLU(0.2, inplace=True))
return block
self.model = nn.Sequential(
*convlayer(self.channels, 32, 4, 2, 1),
*convlayer(32, 64, 4, 2, 1),
*convlayer(64, 128, 4, 2, 1, bn=True),
*convlayer(128, 256, 4, 2, 1, bn=True),
*convlayer(256, 512, 4, 2, 1, bn=True),
nn.Conv2d(512, 1, 4, 1, 0, bias=False), # FC with Conv.
)
def forward(self, imgs):
out = self.model(imgs)
return out.view(-1, 1)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 64, 64] 1,536
LeakyReLU-2 [-1, 32, 64, 64] 0
Conv2d-3 [-1, 64, 32, 32] 32,768
LeakyReLU-4 [-1, 64, 32, 32] 0
Conv2d-5 [-1, 128, 16, 16] 131,072
BatchNorm2d-6 [-1, 128, 16, 16] 256
LeakyReLU-7 [-1, 128, 16, 16] 0
Conv2d-8 [-1, 256, 8, 8] 524,288
BatchNorm2d-9 [-1, 256, 8, 8] 512
LeakyReLU-10 [-1, 256, 8, 8] 0
Conv2d-11 [-1, 512, 4, 4] 2,097,152
BatchNorm2d-12 [-1, 512, 4, 4] 1,024
LeakyReLU-13 [-1, 512, 4, 4] 0
Conv2d-14 [-1, 1, 1, 1] 8,192
================================================================
Total params: 2,796,800
Trainable params: 2,796,800
Non-trainable params: 0
----------------------------------------------------------------
Output
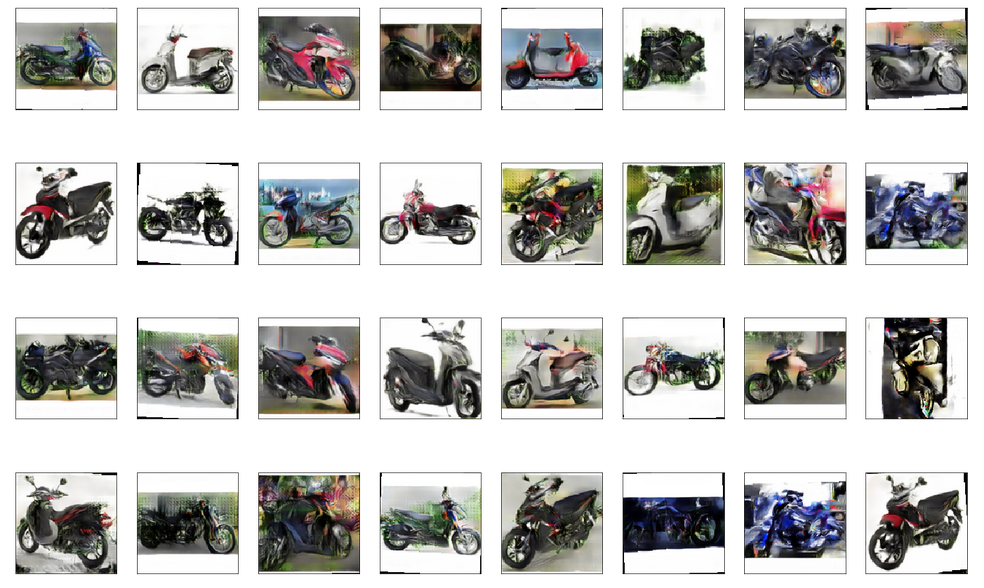
Mình đã thử rất nhiều trường hợp để ra kết quả tốt nhất thì thấy nên đặt trong khoảng 550 - 750 epochs là ra kết quả khá đẹp FID khoảng từ 80 -> 62
batch_size = 64
LR_G = 0.0008
LR_D = 0.0008
epochs = 750
real_label = 0.8
fake_label = 0
Một số kết quả:
Nguồn tham khảo
https://www.kaggle.com/c/generative-dog-images/discussion/99485
All rights reserved
